991 files added
1 files modified
| New file |
| | |
|---|
| | | BasedOnStyle: Chromium |
|---|
| | | UseTab: Never |
|---|
| | | IndentWidth: 4 |
|---|
| | | TabWidth: 4 |
|---|
| | | AllowShortIfStatementsOnASingleLine: false |
|---|
| | | ColumnLimit: 0 |
|---|
| | | AccessModifierOffset: -4 |
|---|
| | | NamespaceIndentation: All |
|---|
| | | FixNamespaceComments: false |
|---|
| | | AlignAfterOpenBracket: true |
|---|
| | | AlignConsecutiveAssignments: true |
|---|
| | | IndentCaseLabels: true |
|---|
| New file |
| | |
|---|
| | | build*/ |
|---|
| | | test/ |
|---|
| | | |
|---|
| | | .cache/ |
|---|
| | | *.swp |
|---|
| | | models/ |
|---|
| New file |
| | |
|---|
| | | name: CI |
|---|
| | | |
|---|
| | | on: |
|---|
| | | workflow_dispatch: # allows manual triggering |
|---|
| | | inputs: |
|---|
| | | create_release: |
|---|
| | | description: 'Create new release' |
|---|
| | | required: true |
|---|
| | | type: boolean |
|---|
| | | push: |
|---|
| | | branches: |
|---|
| | | - master |
|---|
| | | - ci |
|---|
| | | paths: ['.github/workflows/**', '**/CMakeLists.txt', '**/Makefile', '**/*.h', '**/*.hpp', '**/*.c', '**/*.cpp', '**/*.cu'] |
|---|
| | | pull_request: |
|---|
| | | types: [opened, synchronize, reopened] |
|---|
| | | paths: ['**/CMakeLists.txt', '**/Makefile', '**/*.h', '**/*.hpp', '**/*.c', '**/*.cpp', '**/*.cu'] |
|---|
| | | |
|---|
| | | env: |
|---|
| | | BRANCH_NAME: ${{ github.head_ref || github.ref_name }} |
|---|
| | | |
|---|
| | | jobs: |
|---|
| | | ubuntu-latest-cmake: |
|---|
| | | runs-on: ubuntu-latest |
|---|
| | | |
|---|
| | | steps: |
|---|
| | | - name: Clone |
|---|
| | | id: checkout |
|---|
| | | uses: actions/checkout@v3 |
|---|
| | | with: |
|---|
| | | submodules: recursive |
|---|
| | | |
|---|
| | | |
|---|
| | | - name: Dependencies |
|---|
| | | id: depends |
|---|
| | | run: | |
|---|
| | | sudo apt-get update |
|---|
| | | sudo apt-get install build-essential |
|---|
| | | |
|---|
| | | - name: Build |
|---|
| | | id: cmake_build |
|---|
| | | run: | |
|---|
| | | mkdir build |
|---|
| | | cd build |
|---|
| | | cmake .. |
|---|
| | | cmake --build . --config Release |
|---|
| | | |
|---|
| | | #- name: Test |
|---|
| | | #id: cmake_test |
|---|
| | | #run: | |
|---|
| | | #cd build |
|---|
| | | #ctest --verbose --timeout 900 |
|---|
| | | |
|---|
| | | macOS-latest-cmake: |
|---|
| | | runs-on: macos-latest |
|---|
| | | |
|---|
| | | steps: |
|---|
| | | - name: Clone |
|---|
| | | id: checkout |
|---|
| | | uses: actions/checkout@v3 |
|---|
| | | with: |
|---|
| | | submodules: recursive |
|---|
| | | |
|---|
| | | - name: Dependencies |
|---|
| | | id: depends |
|---|
| | | continue-on-error: true |
|---|
| | | run: | |
|---|
| | | brew update |
|---|
| | | |
|---|
| | | - name: Build |
|---|
| | | id: cmake_build |
|---|
| | | run: | |
|---|
| | | sysctl -a |
|---|
| | | mkdir build |
|---|
| | | cd build |
|---|
| | | cmake .. |
|---|
| | | cmake --build . --config Release |
|---|
| | | |
|---|
| | | #- name: Test |
|---|
| | | #id: cmake_test |
|---|
| | | #run: | |
|---|
| | | #cd build |
|---|
| | | #ctest --verbose --timeout 900 |
|---|
| | | |
|---|
| | | windows-latest-cmake: |
|---|
| | | runs-on: windows-latest |
|---|
| | | |
|---|
| | | strategy: |
|---|
| | | matrix: |
|---|
| | | include: |
|---|
| | | - build: 'noavx' |
|---|
| | | defines: '-DGGML_AVX=OFF -DGGML_AVX2=OFF -DGGML_FMA=OFF' |
|---|
| | | - build: 'avx2' |
|---|
| | | defines: '-DGGML_AVX2=ON' |
|---|
| | | - build: 'avx' |
|---|
| | | defines: '-DGGML_AVX2=OFF' |
|---|
| | | - build: 'avx512' |
|---|
| | | defines: '-DGGML_AVX512=ON' |
|---|
| | | |
|---|
| | | steps: |
|---|
| | | - name: Clone |
|---|
| | | id: checkout |
|---|
| | | uses: actions/checkout@v3 |
|---|
| | | with: |
|---|
| | | submodules: recursive |
|---|
| | | |
|---|
| | | - name: Build |
|---|
| | | id: cmake_build |
|---|
| | | run: | |
|---|
| | | mkdir build |
|---|
| | | cd build |
|---|
| | | cmake .. ${{ matrix.defines }} |
|---|
| | | cmake --build . --config Release |
|---|
| | | |
|---|
| | | - name: Check AVX512F support |
|---|
| | | id: check_avx512f |
|---|
| | | if: ${{ matrix.build == 'avx512' }} |
|---|
| | | continue-on-error: true |
|---|
| | | run: | |
|---|
| | | cd build |
|---|
| | | $vcdir = $(vswhere -latest -products * -requires Microsoft.VisualStudio.Component.VC.Tools.x86.x64 -property installationPath) |
|---|
| | | $msvc = $(join-path $vcdir $('VC\Tools\MSVC\'+$(gc -raw $(join-path $vcdir 'VC\Auxiliary\Build\Microsoft.VCToolsVersion.default.txt')).Trim())) |
|---|
| | | $cl = $(join-path $msvc 'bin\Hostx64\x64\cl.exe') |
|---|
| | | echo 'int main(void){unsigned int a[4];__cpuid(a,7);return !(a[1]&65536);}' >> avx512f.c |
|---|
| | | & $cl /O2 /GS- /kernel avx512f.c /link /nodefaultlib /entry:main |
|---|
| | | .\avx512f.exe && echo "AVX512F: YES" && ( echo HAS_AVX512F=1 >> $env:GITHUB_ENV ) || echo "AVX512F: NO" |
|---|
| | | |
|---|
| | | #- name: Test |
|---|
| | | #id: cmake_test |
|---|
| | | #run: | |
|---|
| | | #cd build |
|---|
| | | #ctest -C Release --verbose --timeout 900 |
|---|
| | | |
|---|
| | | - name: Get commit hash |
|---|
| | | id: commit |
|---|
| | | if: ${{ ( github.event_name == 'push' && github.ref == 'refs/heads/master' ) || github.event.inputs.create_release == 'true' }} |
|---|
| | | uses: pr-mpt/actions-commit-hash@v2 |
|---|
| | | |
|---|
| | | - name: Pack artifacts |
|---|
| | | id: pack_artifacts |
|---|
| | | if: ${{ ( github.event_name == 'push' && github.ref == 'refs/heads/master' ) || github.event.inputs.create_release == 'true' }} |
|---|
| | | run: | |
|---|
| | | Copy-Item ggml/LICENSE .\build\bin\Release\ggml.txt |
|---|
| | | Copy-Item LICENSE .\build\bin\Release\stable-diffusion.cpp.txt |
|---|
| | | 7z a sd-${{ env.BRANCH_NAME }}-${{ steps.commit.outputs.short }}-bin-win-${{ matrix.build }}-x64.zip .\build\bin\Release\* |
|---|
| | | |
|---|
| | | - name: Upload artifacts |
|---|
| | | if: ${{ ( github.event_name == 'push' && github.ref == 'refs/heads/master' ) || github.event.inputs.create_release == 'true' }} |
|---|
| | | uses: actions/upload-artifact@v3 |
|---|
| | | with: |
|---|
| | | path: | |
|---|
| | | sd-${{ env.BRANCH_NAME }}-${{ steps.commit.outputs.short }}-bin-win-${{ matrix.build }}-x64.zip |
|---|
| | | |
|---|
| | | release: |
|---|
| | | if: ${{ ( github.event_name == 'push' && github.ref == 'refs/heads/master' ) || github.event.inputs.create_release == 'true' }} |
|---|
| | | |
|---|
| | | runs-on: ubuntu-latest |
|---|
| | | |
|---|
| | | needs: |
|---|
| | | - ubuntu-latest-cmake |
|---|
| | | - macOS-latest-cmake |
|---|
| | | - windows-latest-cmake |
|---|
| | | |
|---|
| | | steps: |
|---|
| | | - name: Download artifacts |
|---|
| | | id: download-artifact |
|---|
| | | uses: actions/download-artifact@v3 |
|---|
| | | |
|---|
| | | - name: Get commit hash |
|---|
| | | id: commit |
|---|
| | | uses: pr-mpt/actions-commit-hash@v2 |
|---|
| | | |
|---|
| | | - name: Create release |
|---|
| | | id: create_release |
|---|
| | | uses: anzz1/action-create-release@v1 |
|---|
| | | env: |
|---|
| | | GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} |
|---|
| | | with: |
|---|
| | | tag_name: ${{ env.BRANCH_NAME }}-${{ steps.commit.outputs.short }} |
|---|
| | | |
|---|
| | | - name: Upload release |
|---|
| | | id: upload_release |
|---|
| | | uses: actions/github-script@v3 |
|---|
| | | with: |
|---|
| | | github-token: ${{secrets.GITHUB_TOKEN}} |
|---|
| | | script: | |
|---|
| | | const path = require('path'); |
|---|
| | | const fs = require('fs'); |
|---|
| | | const release_id = '${{ steps.create_release.outputs.id }}'; |
|---|
| | | for (let file of await fs.readdirSync('./artifact')) { |
|---|
| | | if (path.extname(file) === '.zip') { |
|---|
| | | console.log('uploadReleaseAsset', file); |
|---|
| | | await github.repos.uploadReleaseAsset({ |
|---|
| | | owner: context.repo.owner, |
|---|
| | | repo: context.repo.repo, |
|---|
| | | release_id: release_id, |
|---|
| | | name: file, |
|---|
| | | data: await fs.readFileSync(`./artifact/${file}`) |
|---|
| | | }); |
|---|
| | | } |
|---|
| | | } |
|---|
| | |
|---|
| | | # Compiled Object files |
|---|
| | | *.slo |
|---|
| | | *.lo |
|---|
| | | *.o |
|---|
| | | *.obj |
|---|
| | | |
|---|
| | | # Compiled Dynamic libraries |
|---|
| | | *.so |
|---|
| | | *.dylib |
|---|
| | | *.dll |
|---|
| | | |
|---|
| | | # Compiled Static libraries |
|---|
| | | *.lai |
|---|
| | | *.la |
|---|
| | | *.a |
|---|
| | | *.lib |
|---|
| | | |
|---|
| | | # Executables |
|---|
| | | build*/ |
|---|
| | | test/ |
|---|
| | | .vscode/ |
|---|
| | | .cache/ |
|---|
| | | *.swp |
|---|
| | | .vscode/ |
|---|
| | | *.bat |
|---|
| | | *.bin |
|---|
| | | *.exe |
|---|
| | | *.out |
|---|
| | | *.app |
|---|
| | | *.gguf |
|---|
| | | output*.png |
|---|
| | | models* |
|---|
| | | *.log |
|---|
| New file |
| | |
|---|
| | | [submodule "ggml"] |
|---|
| | | path = ggml |
|---|
| | | url = https://github.com/ggerganov/ggml.git |
|---|
| New file |
| | |
|---|
| | | cmake_minimum_required(VERSION 3.12) |
|---|
| | | project("stable-diffusion") |
|---|
| | | |
|---|
| | | set(CMAKE_EXPORT_COMPILE_COMMANDS ON) |
|---|
| | | |
|---|
| | | if (NOT XCODE AND NOT MSVC AND NOT CMAKE_BUILD_TYPE) |
|---|
| | | set(CMAKE_BUILD_TYPE Release CACHE STRING "Build type" FORCE) |
|---|
| | | set_property(CACHE CMAKE_BUILD_TYPE PROPERTY STRINGS "Debug" "Release" "MinSizeRel" "RelWithDebInfo") |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | set(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/bin) |
|---|
| | | set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/bin) |
|---|
| | | |
|---|
| | | if(CMAKE_SOURCE_DIR STREQUAL CMAKE_CURRENT_SOURCE_DIR) |
|---|
| | | set(SD_STANDALONE ON) |
|---|
| | | else() |
|---|
| | | set(SD_STANDALONE OFF) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | # |
|---|
| | | # Option list |
|---|
| | | # |
|---|
| | | |
|---|
| | | # general |
|---|
| | | #option(SD_BUILD_TESTS "sd: build tests" ${SD_STANDALONE}) |
|---|
| | | option(SD_BUILD_EXAMPLES "sd: build examples" ${SD_STANDALONE}) |
|---|
| | | option(SD_CUBLAS "sd: cuda backend" OFF) |
|---|
| | | option(SD_HIPBLAS "sd: rocm backend" OFF) |
|---|
| | | option(SD_METAL "sd: metal backend" OFF) |
|---|
| | | option(SD_FLASH_ATTN "sd: use flash attention for x4 less memory usage" OFF) |
|---|
| | | option(BUILD_SHARED_LIBS "sd: build shared libs" OFF) |
|---|
| | | #option(SD_BUILD_SERVER "sd: build server example" ON) |
|---|
| | | |
|---|
| | | if(SD_CUBLAS) |
|---|
| | | message("Use CUBLAS as backend stable-diffusion") |
|---|
| | | set(GGML_CUBLAS ON) |
|---|
| | | add_definitions(-DSD_USE_CUBLAS) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | if(SD_METAL) |
|---|
| | | message("Use Metal as backend stable-diffusion") |
|---|
| | | set(GGML_METAL ON) |
|---|
| | | add_definitions(-DSD_USE_METAL) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | if (SD_HIPBLAS) |
|---|
| | | message("Use HIPBLAS as backend stable-diffusion") |
|---|
| | | set(GGML_HIPBLAS ON) |
|---|
| | | add_definitions(-DSD_USE_CUBLAS) |
|---|
| | | if(SD_FAST_SOFTMAX) |
|---|
| | | set(GGML_CUDA_FAST_SOFTMAX ON) |
|---|
| | | endif() |
|---|
| | | endif () |
|---|
| | | |
|---|
| | | if(SD_FLASH_ATTN) |
|---|
| | | message("Use Flash Attention for memory optimization") |
|---|
| | | add_definitions(-DSD_USE_FLASH_ATTENTION) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | set(SD_LIB stable-diffusion) |
|---|
| | | |
|---|
| | | add_library(${SD_LIB} stable-diffusion.h stable-diffusion.cpp model.h model.cpp util.h util.cpp upscaler.cpp |
|---|
| | | ggml_extend.hpp clip.hpp common.hpp unet.hpp tae.hpp esrgan.hpp lora.hpp denoiser.hpp rng.hpp rng_philox.hpp |
|---|
| | | control.hpp preprocessing.hpp) |
|---|
| | | |
|---|
| | | if(BUILD_SHARED_LIBS) |
|---|
| | | message("Build shared library") |
|---|
| | | add_definitions(-DSD_BUILD_SHARED_LIB) |
|---|
| | | target_compile_definitions(${SD_LIB} PRIVATE -DSD_BUILD_DLL) |
|---|
| | | set(CMAKE_POSITION_INDEPENDENT_CODE ON) |
|---|
| | | else() |
|---|
| | | message("Build static library") |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | |
|---|
| | | set(CMAKE_POLICY_DEFAULT_CMP0077 NEW) |
|---|
| | | |
|---|
| | | # see https://github.com/ggerganov/ggml/pull/682 |
|---|
| | | add_definitions(-DGGML_MAX_NAME=128) |
|---|
| | | |
|---|
| | | # deps |
|---|
| | | add_subdirectory(ggml) |
|---|
| | | |
|---|
| | | add_subdirectory(thirdparty) |
|---|
| | | |
|---|
| | | target_link_libraries(${SD_LIB} PUBLIC ggml zip) |
|---|
| | | target_include_directories(${SD_LIB} PUBLIC . thirdparty) |
|---|
| | | target_compile_features(${SD_LIB} PUBLIC cxx_std_11) |
|---|
| | | |
|---|
| | | |
|---|
| | | if (SD_BUILD_EXAMPLES) |
|---|
| | | add_subdirectory(examples) |
|---|
| | | endif() |
|---|
| | | |
|---|
| New file |
| | |
|---|
| | | ARG UBUNTU_VERSION=22.04 |
|---|
| | | |
|---|
| | | FROM ubuntu:$UBUNTU_VERSION as build |
|---|
| | | |
|---|
| | | RUN apt-get update && apt-get install -y build-essential git cmake |
|---|
| | | |
|---|
| | | WORKDIR /sd.cpp |
|---|
| | | |
|---|
| | | COPY . . |
|---|
| | | |
|---|
| | | RUN mkdir build && cd build && cmake .. && cmake --build . --config Release |
|---|
| | | |
|---|
| | | FROM ubuntu:$UBUNTU_VERSION as runtime |
|---|
| | | |
|---|
| | | COPY --from=build /sd.cpp/build/bin/sd /sd |
|---|
| | | |
|---|
| | | ENTRYPOINT [ "/sd" ] |
|---|
| New file |
| | |
|---|
| | | MIT License |
|---|
| | | |
|---|
| | | Copyright (c) 2023 leejet |
|---|
| | | |
|---|
| | | Permission is hereby granted, free of charge, to any person obtaining a copy |
|---|
| | | of this software and associated documentation files (the "Software"), to deal |
|---|
| | | in the Software without restriction, including without limitation the rights |
|---|
| | | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell |
|---|
| | | copies of the Software, and to permit persons to whom the Software is |
|---|
| | | furnished to do so, subject to the following conditions: |
|---|
| | | |
|---|
| | | The above copyright notice and this permission notice shall be included in all |
|---|
| | | copies or substantial portions of the Software. |
|---|
| | | |
|---|
| | | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR |
|---|
| | | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, |
|---|
| | | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE |
|---|
| | | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER |
|---|
| | | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, |
|---|
| | | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE |
|---|
| | | SOFTWARE. |
|---|
| New file |
| | |
|---|
| | | <p align="center"> |
|---|
| | | <img src="./assets/a%20lovely%20cat.png" width="256x"> |
|---|
| | | </p> |
|---|
| | | |
|---|
| | | # stable-diffusion.cpp |
|---|
| | | |
|---|
| | | Inference of [Stable Diffusion](https://github.com/CompVis/stable-diffusion) in pure C/C++ |
|---|
| | | |
|---|
| | | ## Features |
|---|
| | | |
|---|
| | | - Plain C/C++ implementation based on [ggml](https://github.com/ggerganov/ggml), working in the same way as [llama.cpp](https://github.com/ggerganov/llama.cpp) |
|---|
| | | - Super lightweight and without external dependencies |
|---|
| | | - SD1.x, SD2.x and SDXL support |
|---|
| | | - !!!The VAE in SDXL encounters NaN issues under FP16, but unfortunately, the ggml_conv_2d only operates under FP16. Hence, a parameter is needed to specify the VAE that has fixed the FP16 NaN issue. You can find it here: [SDXL VAE FP16 Fix](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/blob/main/sdxl_vae.safetensors). |
|---|
| | | |
|---|
| | | - [SD-Turbo](https://huggingface.co/stabilityai/sd-turbo) and [SDXL-Turbo](https://huggingface.co/stabilityai/sdxl-turbo) support |
|---|
| | | - 16-bit, 32-bit float support |
|---|
| | | - 4-bit, 5-bit and 8-bit integer quantization support |
|---|
| | | - Accelerated memory-efficient CPU inference |
|---|
| | | - Only requires ~2.3GB when using txt2img with fp16 precision to generate a 512x512 image, enabling Flash Attention just requires ~1.8GB. |
|---|
| | | - AVX, AVX2 and AVX512 support for x86 architectures |
|---|
| | | - Full CUDA and Metal backend for GPU acceleration. |
|---|
| | | - Can load ckpt, safetensors and diffusers models/checkpoints. Standalone VAEs models |
|---|
| | | - No need to convert to `.ggml` or `.gguf` anymore! |
|---|
| | | - Flash Attention for memory usage optimization (only cpu for now) |
|---|
| | | - Original `txt2img` and `img2img` mode |
|---|
| | | - Negative prompt |
|---|
| | | - [stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) style tokenizer (not all the features, only token weighting for now) |
|---|
| | | - LoRA support, same as [stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#lora) |
|---|
| | | - Latent Consistency Models support (LCM/LCM-LoRA) |
|---|
| | | - Faster and memory efficient latent decoding with [TAESD](https://github.com/madebyollin/taesd) |
|---|
| | | - Upscale images generated with [ESRGAN](https://github.com/xinntao/Real-ESRGAN) |
|---|
| | | - VAE tiling processing for reduce memory usage |
|---|
| | | - Control Net support with SD 1.5 |
|---|
| | | - Sampling method |
|---|
| | | - `Euler A` |
|---|
| | | - `Euler` |
|---|
| | | - `Heun` |
|---|
| | | - `DPM2` |
|---|
| | | - `DPM++ 2M` |
|---|
| | | - [`DPM++ 2M v2`](https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/8457) |
|---|
| | | - `DPM++ 2S a` |
|---|
| | | - [`LCM`](https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/13952) |
|---|
| | | - Cross-platform reproducibility (`--rng cuda`, consistent with the `stable-diffusion-webui GPU RNG`) |
|---|
| | | - Embedds generation parameters into png output as webui-compatible text string |
|---|
| | | - Supported platforms |
|---|
| | | - Linux |
|---|
| | | - Mac OS |
|---|
| | | - Windows |
|---|
| | | - Android (via Termux) |
|---|
| | | |
|---|
| | | ### TODO |
|---|
| | | |
|---|
| | | - [ ] More sampling methods |
|---|
| | | - [ ] Make inference faster |
|---|
| | | - The current implementation of ggml_conv_2d is slow and has high memory usage |
|---|
| | | - [ ] Continuing to reduce memory usage (quantizing the weights of ggml_conv_2d) |
|---|
| | | - [ ] Implement Inpainting support |
|---|
| | | - [ ] k-quants support |
|---|
| | | |
|---|
| | | ## Usage |
|---|
| | | |
|---|
| | | ### Get the Code |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | git clone --recursive https://github.com/leejet/stable-diffusion.cpp |
|---|
| | | cd stable-diffusion.cpp |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | - If you have already cloned the repository, you can use the following command to update the repository to the latest code. |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | cd stable-diffusion.cpp |
|---|
| | | git pull origin master |
|---|
| | | git submodule init |
|---|
| | | git submodule update |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ### Download weights |
|---|
| | | |
|---|
| | | - download original weights(.ckpt or .safetensors). For example |
|---|
| | | - Stable Diffusion v1.4 from https://huggingface.co/CompVis/stable-diffusion-v-1-4-original |
|---|
| | | - Stable Diffusion v1.5 from https://huggingface.co/runwayml/stable-diffusion-v1-5 |
|---|
| | | - Stable Diffuison v2.1 from https://huggingface.co/stabilityai/stable-diffusion-2-1 |
|---|
| | | |
|---|
| | | ```shell |
|---|
| | | curl -L -O https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt |
|---|
| | | # curl -L -O https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors |
|---|
| | | # curl -L -O https://huggingface.co/stabilityai/stable-diffusion-2-1/resolve/main/v2-1_768-nonema-pruned.safetensors |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ### Build |
|---|
| | | |
|---|
| | | #### Build from scratch |
|---|
| | | |
|---|
| | | ```shell |
|---|
| | | mkdir build |
|---|
| | | cd build |
|---|
| | | cmake .. |
|---|
| | | cmake --build . --config Release |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ##### Using OpenBLAS |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | cmake .. -DGGML_OPENBLAS=ON |
|---|
| | | cmake --build . --config Release |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ##### Using CUBLAS |
|---|
| | | |
|---|
| | | This provides BLAS acceleration using the CUDA cores of your Nvidia GPU. Make sure to have the CUDA toolkit installed. You can download it from your Linux distro's package manager (e.g. `apt install nvidia-cuda-toolkit`) or from here: [CUDA Toolkit](https://developer.nvidia.com/cuda-downloads). Recommended to have at least 4 GB of VRAM. |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | cmake .. -DSD_CUBLAS=ON |
|---|
| | | cmake --build . --config Release |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ##### Using HipBLAS |
|---|
| | | This provides BLAS acceleration using the ROCm cores of your AMD GPU. Make sure to have the ROCm toolkit installed. |
|---|
| | | |
|---|
| | | Windows User Refer to [docs/hipBLAS_on_Windows.md](docs%2FhipBLAS_on_Windows.md) for a comprehensive guide. |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | cmake .. -G "Ninja" -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DSD_HIPBLAS=ON -DCMAKE_BUILD_TYPE=Release -DAMDGPU_TARGETS=gfx1100 |
|---|
| | | cmake --build . --config Release |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | |
|---|
| | | ##### Using Metal |
|---|
| | | |
|---|
| | | Using Metal makes the computation run on the GPU. Currently, there are some issues with Metal when performing operations on very large matrices, making it highly inefficient at the moment. Performance improvements are expected in the near future. |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | cmake .. -DSD_METAL=ON |
|---|
| | | cmake --build . --config Release |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ##### Using Flash Attention |
|---|
| | | |
|---|
| | | Enabling flash attention reduces memory usage by at least 400 MB. At the moment, it is not supported when CUBLAS is enabled because the kernel implementation is missing. |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | cmake .. -DSD_FLASH_ATTN=ON |
|---|
| | | cmake --build . --config Release |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ### Run |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | usage: ./bin/sd [arguments] |
|---|
| | | |
|---|
| | | arguments: |
|---|
| | | -h, --help show this help message and exit |
|---|
| | | -M, --mode [MODEL] run mode (txt2img or img2img or convert, default: txt2img) |
|---|
| | | -t, --threads N number of threads to use during computation (default: -1). |
|---|
| | | If threads <= 0, then threads will be set to the number of CPU physical cores |
|---|
| | | -m, --model [MODEL] path to model |
|---|
| | | --vae [VAE] path to vae |
|---|
| | | --taesd [TAESD_PATH] path to taesd. Using Tiny AutoEncoder for fast decoding (low quality) |
|---|
| | | --control-net [CONTROL_PATH] path to control net model |
|---|
| | | --embd-dir [EMBEDDING_PATH] path to embeddings. |
|---|
| | | --upscale-model [ESRGAN_PATH] path to esrgan model. Upscale images after generate, just RealESRGAN_x4plus_anime_6B supported by now. |
|---|
| | | --type [TYPE] weight type (f32, f16, q4_0, q4_1, q5_0, q5_1, q8_0) |
|---|
| | | If not specified, the default is the type of the weight file. |
|---|
| | | --lora-model-dir [DIR] lora model directory |
|---|
| | | -i, --init-img [IMAGE] path to the input image, required by img2img |
|---|
| | | --control-image [IMAGE] path to image condition, control net |
|---|
| | | -o, --output OUTPUT path to write result image to (default: ./output.png) |
|---|
| | | -p, --prompt [PROMPT] the prompt to render |
|---|
| | | -n, --negative-prompt PROMPT the negative prompt (default: "") |
|---|
| | | --cfg-scale SCALE unconditional guidance scale: (default: 7.0) |
|---|
| | | --strength STRENGTH strength for noising/unnoising (default: 0.75) |
|---|
| | | --control-strength STRENGTH strength to apply Control Net (default: 0.9) |
|---|
| | | 1.0 corresponds to full destruction of information in init image |
|---|
| | | -H, --height H image height, in pixel space (default: 512) |
|---|
| | | -W, --width W image width, in pixel space (default: 512) |
|---|
| | | --sampling-method {euler, euler_a, heun, dpm2, dpm++2s_a, dpm++2m, dpm++2mv2, lcm} |
|---|
| | | sampling method (default: "euler_a") |
|---|
| | | --steps STEPS number of sample steps (default: 20) |
|---|
| | | --rng {std_default, cuda} RNG (default: cuda) |
|---|
| | | -s SEED, --seed SEED RNG seed (default: 42, use random seed for < 0) |
|---|
| | | -b, --batch-count COUNT number of images to generate. |
|---|
| | | --schedule {discrete, karras} Denoiser sigma schedule (default: discrete) |
|---|
| | | --clip-skip N ignore last layers of CLIP network; 1 ignores none, 2 ignores one layer (default: -1) |
|---|
| | | <= 0 represents unspecified, will be 1 for SD1.x, 2 for SD2.x |
|---|
| | | --vae-tiling process vae in tiles to reduce memory usage |
|---|
| | | --control-net-cpu keep controlnet in cpu (for low vram) |
|---|
| | | -v, --verbose print extra info |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | #### Quantization |
|---|
| | | |
|---|
| | | You can specify the model weight type using the `--type` parameter. The weights are automatically converted when loading the model. |
|---|
| | | |
|---|
| | | - `f16` for 16-bit floating-point |
|---|
| | | - `f32` for 32-bit floating-point |
|---|
| | | - `q8_0` for 8-bit integer quantization |
|---|
| | | - `q5_0` or `q5_1` for 5-bit integer quantization |
|---|
| | | - `q4_0` or `q4_1` for 4-bit integer quantization |
|---|
| | | |
|---|
| | | #### Convert to GGUF |
|---|
| | | |
|---|
| | | You can also convert weights in the formats `ckpt/safetensors/diffusers` to gguf and perform quantization in advance, avoiding the need for quantization every time you load them. |
|---|
| | | |
|---|
| | | For example: |
|---|
| | | |
|---|
| | | ```sh |
|---|
| | | ./bin/sd -M convert -m ../models/v1-5-pruned-emaonly.safetensors -o ../models/v1-5-pruned-emaonly.q8_0.gguf -v --type q8_0 |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | #### txt2img example |
|---|
| | | |
|---|
| | | ```sh |
|---|
| | | ./bin/sd -m ../models/sd-v1-4.ckpt -p "a lovely cat" |
|---|
| | | # ./bin/sd -m ../models/v1-5-pruned-emaonly.safetensors -p "a lovely cat" |
|---|
| | | # ./bin/sd -m ../models/sd_xl_base_1.0.safetensors --vae ../models/sdxl_vae-fp16-fix.safetensors -H 1024 -W 1024 -p "a lovely cat" -v |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | Using formats of different precisions will yield results of varying quality. |
|---|
| | | |
|---|
| | | | f32 | f16 |q8_0 |q5_0 |q5_1 |q4_0 |q4_1 | |
|---|
| | | | ---- |---- |---- |---- |---- |---- |---- | |
|---|
| | | |  | | | | | | | |
|---|
| | | |
|---|
| | | #### img2img example |
|---|
| | | |
|---|
| | | - `./output.png` is the image generated from the above txt2img pipeline |
|---|
| | | |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | ./bin/sd --mode img2img -m ../models/sd-v1-4.ckpt -p "cat with blue eyes" -i ./output.png -o ./img2img_output.png --strength 0.4 |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | <p align="center"> |
|---|
| | | <img src="./assets/img2img_output.png" width="256x"> |
|---|
| | | </p> |
|---|
| | | |
|---|
| | | #### with LoRA |
|---|
| | | |
|---|
| | | - You can specify the directory where the lora weights are stored via `--lora-model-dir`. If not specified, the default is the current working directory. |
|---|
| | | |
|---|
| | | - LoRA is specified via prompt, just like [stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#lora). |
|---|
| | | |
|---|
| | | Here's a simple example: |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | ./bin/sd -m ../models/v1-5-pruned-emaonly.safetensors -p "a lovely cat<lora:marblesh:1>" --lora-model-dir ../models |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | `../models/marblesh.safetensors` or `../models/marblesh.ckpt` will be applied to the model |
|---|
| | | |
|---|
| | | #### LCM/LCM-LoRA |
|---|
| | | |
|---|
| | | - Download LCM-LoRA form https://huggingface.co/latent-consistency/lcm-lora-sdv1-5 |
|---|
| | | - Specify LCM-LoRA by adding `<lora:lcm-lora-sdv1-5:1>` to prompt |
|---|
| | | - It's advisable to set `--cfg-scale` to `1.0` instead of the default `7.0`. For `--steps`, a range of `2-8` steps is recommended. For `--sampling-method`, `lcm`/`euler_a` is recommended. |
|---|
| | | |
|---|
| | | Here's a simple example: |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | ./bin/sd -m ../models/v1-5-pruned-emaonly.safetensors -p "a lovely cat<lora:lcm-lora-sdv1-5:1>" --steps 4 --lora-model-dir ../models -v --cfg-scale 1 |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | | without LCM-LoRA (--cfg-scale 7) | with LCM-LoRA (--cfg-scale 1) | |
|---|
| | | | ---- |---- | |
|---|
| | | |  | | |
|---|
| | | |
|---|
| | | #### Using TAESD to faster decoding |
|---|
| | | |
|---|
| | | You can use TAESD to accelerate the decoding of latent images by following these steps: |
|---|
| | | |
|---|
| | | - Download the model [weights](https://huggingface.co/madebyollin/taesd/blob/main/diffusion_pytorch_model.safetensors). |
|---|
| | | |
|---|
| | | Or curl |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | curl -L -O https://huggingface.co/madebyollin/taesd/blob/main/diffusion_pytorch_model.safetensors |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | - Specify the model path using the `--taesd PATH` parameter. example: |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | sd -m ../models/v1-5-pruned-emaonly.safetensors -p "a lovely cat" --taesd ../models/diffusion_pytorch_model.safetensors |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | #### Using ESRGAN to upscale results |
|---|
| | | |
|---|
| | | You can use ESRGAN to upscale the generated images. At the moment, only the [RealESRGAN_x4plus_anime_6B.pth](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth) model is supported. Support for more models of this architecture will be added soon. |
|---|
| | | |
|---|
| | | - Specify the model path using the `--upscale-model PATH` parameter. example: |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | sd -m ../models/v1-5-pruned-emaonly.safetensors -p "a lovely cat" --upscale-model ../models/RealESRGAN_x4plus_anime_6B.pth |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ### Docker |
|---|
| | | |
|---|
| | | #### Building using Docker |
|---|
| | | |
|---|
| | | ```shell |
|---|
| | | docker build -t sd . |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | #### Run |
|---|
| | | |
|---|
| | | ```shell |
|---|
| | | docker run -v /path/to/models:/models -v /path/to/output/:/output sd [args...] |
|---|
| | | # For example |
|---|
| | | # docker run -v ./models:/models -v ./build:/output sd -m /models/sd-v1-4.ckpt -p "a lovely cat" -v -o /output/output.png |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Memory Requirements |
|---|
| | | |
|---|
| | | | precision | f32 | f16 |q8_0 |q5_0 |q5_1 |q4_0 |q4_1 | |
|---|
| | | | ---- | ---- |---- |---- |---- |---- |---- |---- | |
|---|
| | | | **Memory** (txt2img - 512 x 512) | ~2.8G | ~2.3G | ~2.1G | ~2.0G | ~2.0G | ~2.0G | ~2.0G | |
|---|
| | | | **Memory** (txt2img - 512 x 512) *with Flash Attention* | ~2.4G | ~1.9G | ~1.6G | ~1.5G | ~1.5G | ~1.5G | ~1.5G | |
|---|
| | | |
|---|
| | | ## Contributors |
|---|
| | | |
|---|
| | | Thank you to all the people who have already contributed to stable-diffusion.cpp! |
|---|
| | | |
|---|
| | | [](https://github.com/leejet/stable-diffusion.cpp/graphs/contributors) |
|---|
| | | |
|---|
| | | ## References |
|---|
| | | |
|---|
| | | - [ggml](https://github.com/ggerganov/ggml) |
|---|
| | | - [stable-diffusion](https://github.com/CompVis/stable-diffusion) |
|---|
| | | - [stable-diffusion-stability-ai](https://github.com/Stability-AI/stablediffusion) |
|---|
| | | - [stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) |
|---|
| | | - [ComfyUI](https://github.com/comfyanonymous/ComfyUI) |
|---|
| | | - [k-diffusion](https://github.com/crowsonkb/k-diffusion) |
|---|
| | | - [latent-consistency-model](https://github.com/luosiallen/latent-consistency-model) |
|---|
| | | - [generative-models](https://github.com/Stability-AI/generative-models/) |
|---|
| New file |
| | |
|---|
| | | #ifndef __CLIP_HPP__ |
|---|
| | | #define __CLIP_HPP__ |
|---|
| | | |
|---|
| | | #include "ggml_extend.hpp" |
|---|
| | | #include "model.h" |
|---|
| | | |
|---|
| | | /*================================================== CLIPTokenizer ===================================================*/ |
|---|
| | | |
|---|
| | | std::pair<std::unordered_map<std::string, float>, std::string> extract_and_remove_lora(std::string text) { |
|---|
| | | std::regex re("<lora:([^:]+):([^>]+)>"); |
|---|
| | | std::smatch matches; |
|---|
| | | std::unordered_map<std::string, float> filename2multiplier; |
|---|
| | | |
|---|
| | | while (std::regex_search(text, matches, re)) { |
|---|
| | | std::string filename = matches[1].str(); |
|---|
| | | float multiplier = std::stof(matches[2].str()); |
|---|
| | | |
|---|
| | | text = std::regex_replace(text, re, "", std::regex_constants::format_first_only); |
|---|
| | | |
|---|
| | | if (multiplier == 0.f) { |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (filename2multiplier.find(filename) == filename2multiplier.end()) { |
|---|
| | | filename2multiplier[filename] = multiplier; |
|---|
| | | } else { |
|---|
| | | filename2multiplier[filename] += multiplier; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | return std::make_pair(filename2multiplier, text); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const std::string UNK_TOKEN = "<|endoftext|>"; |
|---|
| | | const std::string BOS_TOKEN = "<|startoftext|>"; |
|---|
| | | const std::string EOS_TOKEN = "<|endoftext|>"; |
|---|
| | | const std::string PAD_TOEKN = "<|endoftext|>"; |
|---|
| | | |
|---|
| | | const int UNK_TOKEN_ID = 49407; |
|---|
| | | const int BOS_TOKEN_ID = 49406; |
|---|
| | | const int EOS_TOKEN_ID = 49407; |
|---|
| | | const int PAD_TOKEN_ID = 49407; |
|---|
| | | |
|---|
| | | std::vector<std::pair<int, std::u32string>> bytes_to_unicode() { |
|---|
| | | std::vector<std::pair<int, std::u32string>> byte_unicode_pairs; |
|---|
| | | std::set<int> byte_set; |
|---|
| | | for (int b = static_cast<int>('!'); b <= static_cast<int>('~'); ++b) { |
|---|
| | | byte_set.insert(b); |
|---|
| | | byte_unicode_pairs.push_back(std::pair<int, std::u32string>(b, unicode_value_to_utf32(b))); |
|---|
| | | } |
|---|
| | | for (int b = 161; b <= 172; ++b) { |
|---|
| | | byte_set.insert(b); |
|---|
| | | byte_unicode_pairs.push_back(std::pair<int, std::u32string>(b, unicode_value_to_utf32(b))); |
|---|
| | | } |
|---|
| | | for (int b = 174; b <= 255; ++b) { |
|---|
| | | byte_set.insert(b); |
|---|
| | | byte_unicode_pairs.push_back(std::pair<int, std::u32string>(b, unicode_value_to_utf32(b))); |
|---|
| | | } |
|---|
| | | int n = 0; |
|---|
| | | for (int b = 0; b < 256; ++b) { |
|---|
| | | if (byte_set.find(b) == byte_set.end()) { |
|---|
| | | byte_unicode_pairs.push_back(std::pair<int, std::u32string>(b, unicode_value_to_utf32(n + 256))); |
|---|
| | | ++n; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | // LOG_DEBUG("byte_unicode_pairs %d", byte_unicode_pairs.size()); |
|---|
| | | return byte_unicode_pairs; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Ref: https://github.com/openai/CLIP/blob/main/clip/simple_tokenizer.py |
|---|
| | | |
|---|
| | | typedef std::function<bool(std::string&, std::vector<int32_t>&)> on_new_token_cb_t; |
|---|
| | | |
|---|
| | | class CLIPTokenizer { |
|---|
| | | private: |
|---|
| | | SDVersion version = VERSION_1_x; |
|---|
| | | std::map<int, std::u32string> byte_encoder; |
|---|
| | | std::map<std::u32string, int> encoder; |
|---|
| | | std::map<std::pair<std::u32string, std::u32string>, int> bpe_ranks; |
|---|
| | | std::regex pat; |
|---|
| | | |
|---|
| | | static std::string strip(const std::string& str) { |
|---|
| | | std::string::size_type start = str.find_first_not_of(" \t\n\r\v\f"); |
|---|
| | | std::string::size_type end = str.find_last_not_of(" \t\n\r\v\f"); |
|---|
| | | |
|---|
| | | if (start == std::string::npos) { |
|---|
| | | // String contains only whitespace characters |
|---|
| | | return ""; |
|---|
| | | } |
|---|
| | | |
|---|
| | | return str.substr(start, end - start + 1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | static std::string whitespace_clean(std::string text) { |
|---|
| | | text = std::regex_replace(text, std::regex(R"(\s+)"), " "); |
|---|
| | | text = strip(text); |
|---|
| | | return text; |
|---|
| | | } |
|---|
| | | |
|---|
| | | static std::set<std::pair<std::u32string, std::u32string>> get_pairs(const std::vector<std::u32string>& subwords) { |
|---|
| | | std::set<std::pair<std::u32string, std::u32string>> pairs; |
|---|
| | | if (subwords.size() == 0) { |
|---|
| | | return pairs; |
|---|
| | | } |
|---|
| | | std::u32string prev_subword = subwords[0]; |
|---|
| | | for (int i = 1; i < subwords.size(); i++) { |
|---|
| | | std::u32string subword = subwords[i]; |
|---|
| | | std::pair<std::u32string, std::u32string> pair(prev_subword, subword); |
|---|
| | | pairs.insert(pair); |
|---|
| | | prev_subword = subword; |
|---|
| | | } |
|---|
| | | return pairs; |
|---|
| | | } |
|---|
| | | |
|---|
| | | public: |
|---|
| | | CLIPTokenizer(SDVersion version = VERSION_1_x) |
|---|
| | | : version(version) {} |
|---|
| | | |
|---|
| | | void load_from_merges(const std::string& merges_utf8_str) { |
|---|
| | | auto byte_unicode_pairs = bytes_to_unicode(); |
|---|
| | | byte_encoder = std::map<int, std::u32string>(byte_unicode_pairs.begin(), byte_unicode_pairs.end()); |
|---|
| | | // for (auto & pair: byte_unicode_pairs) { |
|---|
| | | // std::cout << pair.first << ": " << pair.second << std::endl; |
|---|
| | | // } |
|---|
| | | std::vector<std::u32string> merges; |
|---|
| | | size_t start = 0; |
|---|
| | | size_t pos; |
|---|
| | | std::u32string merges_utf32_str = utf8_to_utf32(merges_utf8_str); |
|---|
| | | while ((pos = merges_utf32_str.find('\n', start)) != std::string::npos) { |
|---|
| | | merges.push_back(merges_utf32_str.substr(start, pos - start)); |
|---|
| | | start = pos + 1; |
|---|
| | | } |
|---|
| | | // LOG_DEBUG("merges size %llu", merges.size()); |
|---|
| | | GGML_ASSERT(merges.size() == 48895); |
|---|
| | | merges = std::vector<std::u32string>(merges.begin() + 1, merges.end()); |
|---|
| | | std::vector<std::pair<std::u32string, std::u32string>> merge_pairs; |
|---|
| | | for (const auto& merge : merges) { |
|---|
| | | size_t space_pos = merge.find(' '); |
|---|
| | | merge_pairs.emplace_back(merge.substr(0, space_pos), merge.substr(space_pos + 1)); |
|---|
| | | // LOG_DEBUG("%s", utf32_to_utf8(merge.substr(space_pos + 1)).c_str()); |
|---|
| | | } |
|---|
| | | std::vector<std::u32string> vocab; |
|---|
| | | for (const auto& pair : byte_unicode_pairs) { |
|---|
| | | vocab.push_back(pair.second); |
|---|
| | | } |
|---|
| | | for (const auto& pair : byte_unicode_pairs) { |
|---|
| | | vocab.push_back(pair.second + utf8_to_utf32("</w>")); |
|---|
| | | } |
|---|
| | | for (const auto& merge : merge_pairs) { |
|---|
| | | vocab.push_back(merge.first + merge.second); |
|---|
| | | } |
|---|
| | | vocab.push_back(utf8_to_utf32("<|startoftext|>")); |
|---|
| | | vocab.push_back(utf8_to_utf32("<|endoftext|>")); |
|---|
| | | LOG_DEBUG("vocab size: %llu", vocab.size()); |
|---|
| | | int i = 0; |
|---|
| | | for (const auto& token : vocab) { |
|---|
| | | encoder[token] = i++; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int rank = 0; |
|---|
| | | for (const auto& merge : merge_pairs) { |
|---|
| | | bpe_ranks[merge] = rank++; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | std::u32string bpe(const std::u32string& token) { |
|---|
| | | std::vector<std::u32string> word; |
|---|
| | | |
|---|
| | | for (int i = 0; i < token.size() - 1; i++) { |
|---|
| | | word.emplace_back(1, token[i]); |
|---|
| | | } |
|---|
| | | word.push_back(token.substr(token.size() - 1) + utf8_to_utf32("</w>")); |
|---|
| | | |
|---|
| | | std::set<std::pair<std::u32string, std::u32string>> pairs = get_pairs(word); |
|---|
| | | |
|---|
| | | if (pairs.empty()) { |
|---|
| | | return token + utf8_to_utf32("</w>"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | while (true) { |
|---|
| | | auto min_pair_iter = std::min_element(pairs.begin(), |
|---|
| | | pairs.end(), |
|---|
| | | [&](const std::pair<std::u32string, std::u32string>& a, |
|---|
| | | const std::pair<std::u32string, std::u32string>& b) { |
|---|
| | | if (bpe_ranks.find(a) == bpe_ranks.end()) { |
|---|
| | | return false; |
|---|
| | | } else if (bpe_ranks.find(b) == bpe_ranks.end()) { |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | return bpe_ranks.at(a) < bpe_ranks.at(b); |
|---|
| | | }); |
|---|
| | | |
|---|
| | | const std::pair<std::u32string, std::u32string>& bigram = *min_pair_iter; |
|---|
| | | |
|---|
| | | if (bpe_ranks.find(bigram) == bpe_ranks.end()) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::u32string first = bigram.first; |
|---|
| | | std::u32string second = bigram.second; |
|---|
| | | std::vector<std::u32string> new_word; |
|---|
| | | int32_t i = 0; |
|---|
| | | |
|---|
| | | while (i < word.size()) { |
|---|
| | | auto it = std::find(word.begin() + i, word.end(), first); |
|---|
| | | if (it == word.end()) { |
|---|
| | | new_word.insert(new_word.end(), word.begin() + i, word.end()); |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | new_word.insert(new_word.end(), word.begin() + i, it); |
|---|
| | | i = static_cast<int32_t>(std::distance(word.begin(), it)); |
|---|
| | | |
|---|
| | | if (word[i] == first && i < static_cast<int32_t>(word.size()) - 1 && word[i + 1] == second) { |
|---|
| | | new_word.push_back(first + second); |
|---|
| | | i += 2; |
|---|
| | | } else { |
|---|
| | | new_word.push_back(word[i]); |
|---|
| | | i += 1; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | word = new_word; |
|---|
| | | |
|---|
| | | if (word.size() == 1) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | pairs = get_pairs(word); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::u32string result; |
|---|
| | | for (int i = 0; i < word.size(); i++) { |
|---|
| | | result += word[i]; |
|---|
| | | if (i != word.size() - 1) { |
|---|
| | | result += utf8_to_utf32(" "); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | return result; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::vector<int> tokenize(std::string text, |
|---|
| | | on_new_token_cb_t on_new_token_cb, |
|---|
| | | size_t max_length = 0, |
|---|
| | | bool padding = false) { |
|---|
| | | std::vector<int32_t> tokens = encode(text, on_new_token_cb); |
|---|
| | | tokens.insert(tokens.begin(), BOS_TOKEN_ID); |
|---|
| | | if (max_length > 0) { |
|---|
| | | if (tokens.size() > max_length - 1) { |
|---|
| | | tokens.resize(max_length - 1); |
|---|
| | | tokens.push_back(EOS_TOKEN_ID); |
|---|
| | | } else { |
|---|
| | | tokens.push_back(EOS_TOKEN_ID); |
|---|
| | | if (padding) { |
|---|
| | | int pad_token_id = PAD_TOKEN_ID; |
|---|
| | | if (version == VERSION_2_x) { |
|---|
| | | pad_token_id = 0; |
|---|
| | | } |
|---|
| | | tokens.insert(tokens.end(), max_length - tokens.size(), pad_token_id); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | return tokens; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::vector<int> encode(std::string text, on_new_token_cb_t on_new_token_cb) { |
|---|
| | | std::string original_text = text; |
|---|
| | | std::vector<int32_t> bpe_tokens; |
|---|
| | | text = whitespace_clean(text); |
|---|
| | | std::transform(text.begin(), text.end(), text.begin(), [](unsigned char c) { return std::tolower(c); }); |
|---|
| | | |
|---|
| | | std::regex pat(R"(<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[[:alpha:]]+|[[:digit:]]|[^[:space:][:alpha:][:digit:]]+)", |
|---|
| | | std::regex::icase); |
|---|
| | | |
|---|
| | | std::smatch matches; |
|---|
| | | std::string str = text; |
|---|
| | | std::vector<std::string> token_strs; |
|---|
| | | while (std::regex_search(str, matches, pat)) { |
|---|
| | | bool skip = on_new_token_cb(str, bpe_tokens); |
|---|
| | | if (skip) { |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | for (auto& token : matches) { |
|---|
| | | std::string token_str = token.str(); |
|---|
| | | std::u32string utf32_token; |
|---|
| | | for (int i = 0; i < token_str.length(); i++) { |
|---|
| | | char b = token_str[i]; |
|---|
| | | utf32_token += byte_encoder[b]; |
|---|
| | | } |
|---|
| | | auto bpe_strs = bpe(utf32_token); |
|---|
| | | size_t start = 0; |
|---|
| | | size_t pos; |
|---|
| | | while ((pos = bpe_strs.find(' ', start)) != std::u32string::npos) { |
|---|
| | | auto bpe_str = bpe_strs.substr(start, pos - start); |
|---|
| | | bpe_tokens.push_back(encoder[bpe_str]); |
|---|
| | | token_strs.push_back(utf32_to_utf8(bpe_str)); |
|---|
| | | |
|---|
| | | start = pos + 1; |
|---|
| | | } |
|---|
| | | auto bpe_str = bpe_strs.substr(start, bpe_strs.size() - start); |
|---|
| | | bpe_tokens.push_back(encoder[bpe_str]); |
|---|
| | | token_strs.push_back(utf32_to_utf8(bpe_str)); |
|---|
| | | } |
|---|
| | | str = matches.suffix(); |
|---|
| | | } |
|---|
| | | std::stringstream ss; |
|---|
| | | ss << "["; |
|---|
| | | for (auto token : token_strs) { |
|---|
| | | ss << "\"" << token << "\", "; |
|---|
| | | } |
|---|
| | | ss << "]"; |
|---|
| | | LOG_DEBUG("split prompt \"%s\" to tokens %s", original_text.c_str(), ss.str().c_str()); |
|---|
| | | return bpe_tokens; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // Ref: https://github.com/AUTOMATIC1111/stable-diffusion-webui/blob/cad87bf4e3e0b0a759afa94e933527c3123d59bc/modules/prompt_parser.py#L345 |
|---|
| | | // |
|---|
| | | // Parses a string with attention tokens and returns a list of pairs: text and its associated weight. |
|---|
| | | // Accepted tokens are: |
|---|
| | | // (abc) - increases attention to abc by a multiplier of 1.1 |
|---|
| | | // (abc:3.12) - increases attention to abc by a multiplier of 3.12 |
|---|
| | | // [abc] - decreases attention to abc by a multiplier of 1.1 |
|---|
| | | // \( - literal character '(' |
|---|
| | | // \[ - literal character '[' |
|---|
| | | // \) - literal character ')' |
|---|
| | | // \] - literal character ']' |
|---|
| | | // \\ - literal character '\' |
|---|
| | | // anything else - just text |
|---|
| | | // |
|---|
| | | // >>> parse_prompt_attention('normal text') |
|---|
| | | // [['normal text', 1.0]] |
|---|
| | | // >>> parse_prompt_attention('an (important) word') |
|---|
| | | // [['an ', 1.0], ['important', 1.1], [' word', 1.0]] |
|---|
| | | // >>> parse_prompt_attention('(unbalanced') |
|---|
| | | // [['unbalanced', 1.1]] |
|---|
| | | // >>> parse_prompt_attention('\(literal\]') |
|---|
| | | // [['(literal]', 1.0]] |
|---|
| | | // >>> parse_prompt_attention('(unnecessary)(parens)') |
|---|
| | | // [['unnecessaryparens', 1.1]] |
|---|
| | | // >>> parse_prompt_attention('a (((house:1.3)) [on] a (hill:0.5), sun, (((sky))).') |
|---|
| | | // [['a ', 1.0], |
|---|
| | | // ['house', 1.5730000000000004], |
|---|
| | | // [' ', 1.1], |
|---|
| | | // ['on', 1.0], |
|---|
| | | // [' a ', 1.1], |
|---|
| | | // ['hill', 0.55], |
|---|
| | | // [', sun, ', 1.1], |
|---|
| | | // ['sky', 1.4641000000000006], |
|---|
| | | // ['.', 1.1]] |
|---|
| | | std::vector<std::pair<std::string, float>> parse_prompt_attention(const std::string& text) { |
|---|
| | | std::vector<std::pair<std::string, float>> res; |
|---|
| | | std::vector<int> round_brackets; |
|---|
| | | std::vector<int> square_brackets; |
|---|
| | | |
|---|
| | | float round_bracket_multiplier = 1.1f; |
|---|
| | | float square_bracket_multiplier = 1 / 1.1f; |
|---|
| | | |
|---|
| | | std::regex re_attention(R"(\\\(|\\\)|\\\[|\\\]|\\\\|\\|\(|\[|:([+-]?[.\d]+)\)|\)|\]|[^\\()\[\]:]+|:)"); |
|---|
| | | std::regex re_break(R"(\s*\bBREAK\b\s*)"); |
|---|
| | | |
|---|
| | | auto multiply_range = [&](int start_position, float multiplier) { |
|---|
| | | for (int p = start_position; p < res.size(); ++p) { |
|---|
| | | res[p].second *= multiplier; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | std::smatch m; |
|---|
| | | std::string remaining_text = text; |
|---|
| | | |
|---|
| | | while (std::regex_search(remaining_text, m, re_attention)) { |
|---|
| | | std::string text = m[0]; |
|---|
| | | std::string weight = m[1]; |
|---|
| | | |
|---|
| | | if (text == "(") { |
|---|
| | | round_brackets.push_back((int)res.size()); |
|---|
| | | } else if (text == "[") { |
|---|
| | | square_brackets.push_back((int)res.size()); |
|---|
| | | } else if (!weight.empty()) { |
|---|
| | | if (!round_brackets.empty()) { |
|---|
| | | multiply_range(round_brackets.back(), std::stof(weight)); |
|---|
| | | round_brackets.pop_back(); |
|---|
| | | } |
|---|
| | | } else if (text == ")" && !round_brackets.empty()) { |
|---|
| | | multiply_range(round_brackets.back(), round_bracket_multiplier); |
|---|
| | | round_brackets.pop_back(); |
|---|
| | | } else if (text == "]" && !square_brackets.empty()) { |
|---|
| | | multiply_range(square_brackets.back(), square_bracket_multiplier); |
|---|
| | | square_brackets.pop_back(); |
|---|
| | | } else if (text == "\\(") { |
|---|
| | | res.push_back({text.substr(1), 1.0f}); |
|---|
| | | } else { |
|---|
| | | res.push_back({text, 1.0f}); |
|---|
| | | } |
|---|
| | | |
|---|
| | | remaining_text = m.suffix(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | for (int pos : round_brackets) { |
|---|
| | | multiply_range(pos, round_bracket_multiplier); |
|---|
| | | } |
|---|
| | | |
|---|
| | | for (int pos : square_brackets) { |
|---|
| | | multiply_range(pos, square_bracket_multiplier); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (res.empty()) { |
|---|
| | | res.push_back({"", 1.0f}); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int i = 0; |
|---|
| | | while (i + 1 < res.size()) { |
|---|
| | | if (res[i].second == res[i + 1].second) { |
|---|
| | | res[i].first += res[i + 1].first; |
|---|
| | | res.erase(res.begin() + i + 1); |
|---|
| | | } else { |
|---|
| | | ++i; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | return res; |
|---|
| | | } |
|---|
| | | |
|---|
| | | /*================================================ FrozenCLIPEmbedder ================================================*/ |
|---|
| | | |
|---|
| | | // Ref: https://github.com/huggingface/transformers/blob/main/src/transformers/models/clip/modeling_clip.py |
|---|
| | | |
|---|
| | | struct CLIPMLP : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | bool use_gelu; |
|---|
| | | |
|---|
| | | public: |
|---|
| | | CLIPMLP(int64_t d_model, int64_t intermediate_size) { |
|---|
| | | blocks["fc1"] = std::shared_ptr<GGMLBlock>(new Linear(d_model, intermediate_size)); |
|---|
| | | blocks["fc2"] = std::shared_ptr<GGMLBlock>(new Linear(intermediate_size, d_model)); |
|---|
| | | |
|---|
| | | if (d_model == 1024 || d_model == 1280) { // SD 2.x |
|---|
| | | use_gelu = true; |
|---|
| | | } else { // SD 1.x |
|---|
| | | use_gelu = false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x) { |
|---|
| | | // x: [N, n_token, d_model] |
|---|
| | | auto fc1 = std::dynamic_pointer_cast<Linear>(blocks["fc1"]); |
|---|
| | | auto fc2 = std::dynamic_pointer_cast<Linear>(blocks["fc2"]); |
|---|
| | | |
|---|
| | | x = fc1->forward(ctx, x); |
|---|
| | | if (use_gelu) { |
|---|
| | | x = ggml_gelu_inplace(ctx, x); |
|---|
| | | } else { |
|---|
| | | x = ggml_gelu_quick_inplace(ctx, x); |
|---|
| | | } |
|---|
| | | x = fc2->forward(ctx, x); |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct CLIPLayer : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int64_t d_model; // hidden_size/embed_dim |
|---|
| | | int64_t n_head; |
|---|
| | | int64_t intermediate_size; |
|---|
| | | |
|---|
| | | public: |
|---|
| | | CLIPLayer(int64_t d_model, |
|---|
| | | int64_t n_head, |
|---|
| | | int64_t intermediate_size) |
|---|
| | | : d_model(d_model), |
|---|
| | | n_head(n_head), |
|---|
| | | intermediate_size(intermediate_size) { |
|---|
| | | blocks["self_attn"] = std::shared_ptr<GGMLBlock>(new MultiheadAttention(d_model, n_head)); |
|---|
| | | blocks["layer_norm1"] = std::shared_ptr<GGMLBlock>(new LayerNorm(d_model)); |
|---|
| | | blocks["layer_norm2"] = std::shared_ptr<GGMLBlock>(new LayerNorm(d_model)); |
|---|
| | | |
|---|
| | | blocks["mlp"] = std::shared_ptr<GGMLBlock>(new CLIPMLP(d_model, intermediate_size)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x, bool mask = true) { |
|---|
| | | // x: [N, n_token, d_model] |
|---|
| | | auto self_attn = std::dynamic_pointer_cast<MultiheadAttention>(blocks["self_attn"]); |
|---|
| | | auto layer_norm1 = std::dynamic_pointer_cast<LayerNorm>(blocks["layer_norm1"]); |
|---|
| | | auto layer_norm2 = std::dynamic_pointer_cast<LayerNorm>(blocks["layer_norm2"]); |
|---|
| | | auto mlp = std::dynamic_pointer_cast<CLIPMLP>(blocks["mlp"]); |
|---|
| | | |
|---|
| | | x = ggml_add(ctx, x, self_attn->forward(ctx, layer_norm1->forward(ctx, x), mask)); |
|---|
| | | x = ggml_add(ctx, x, mlp->forward(ctx, layer_norm2->forward(ctx, x))); |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct CLIPEncoder : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int64_t n_layer; |
|---|
| | | |
|---|
| | | public: |
|---|
| | | CLIPEncoder(int64_t n_layer, |
|---|
| | | int64_t d_model, |
|---|
| | | int64_t n_head, |
|---|
| | | int64_t intermediate_size) |
|---|
| | | : n_layer(n_layer) { |
|---|
| | | for (int i = 0; i < n_layer; i++) { |
|---|
| | | std::string name = "layers." + std::to_string(i); |
|---|
| | | blocks[name] = std::shared_ptr<GGMLBlock>(new CLIPLayer(d_model, n_head, intermediate_size)); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x, int clip_skip = -1, bool mask = true) { |
|---|
| | | // x: [N, n_token, d_model] |
|---|
| | | int layer_idx = n_layer - 1; |
|---|
| | | LOG_DEBUG("clip_skip %d", clip_skip); |
|---|
| | | if (clip_skip > 0) { |
|---|
| | | layer_idx = n_layer - clip_skip; |
|---|
| | | } |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_layer; i++) { |
|---|
| | | // LOG_DEBUG("layer %d", i); |
|---|
| | | if (i == layer_idx + 1) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | std::string name = "layers." + std::to_string(i); |
|---|
| | | auto layer = std::dynamic_pointer_cast<CLIPLayer>(blocks[name]); |
|---|
| | | x = layer->forward(ctx, x); // [N, n_token, d_model] |
|---|
| | | // LOG_DEBUG("layer %d", i); |
|---|
| | | } |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class CLIPEmbeddings : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int64_t embed_dim; |
|---|
| | | int64_t vocab_size; |
|---|
| | | int64_t num_positions; |
|---|
| | | |
|---|
| | | void init_params(struct ggml_context* ctx, ggml_type wtype) { |
|---|
| | | params["token_embedding.weight"] = ggml_new_tensor_2d(ctx, wtype, embed_dim, vocab_size); |
|---|
| | | params["position_embedding.weight"] = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, embed_dim, num_positions); |
|---|
| | | } |
|---|
| | | |
|---|
| | | public: |
|---|
| | | CLIPEmbeddings(int64_t embed_dim, |
|---|
| | | int64_t vocab_size = 49408, |
|---|
| | | int64_t num_positions = 77) |
|---|
| | | : embed_dim(embed_dim), |
|---|
| | | vocab_size(vocab_size), |
|---|
| | | num_positions(num_positions) { |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* get_token_embed_weight() { |
|---|
| | | return params["token_embedding.weight"]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, |
|---|
| | | struct ggml_tensor* input_ids, |
|---|
| | | struct ggml_tensor* custom_embed_weight) { |
|---|
| | | // input_ids: [N, n_token] |
|---|
| | | auto token_embed_weight = params["token_embedding.weight"]; |
|---|
| | | auto position_embed_weight = params["position_embedding.weight"]; |
|---|
| | | |
|---|
| | | GGML_ASSERT(input_ids->ne[0] <= position_embed_weight->ne[0]); |
|---|
| | | |
|---|
| | | // token_embedding + position_embedding |
|---|
| | | auto x = ggml_add(ctx, |
|---|
| | | ggml_get_rows(ctx, custom_embed_weight != NULL ? custom_embed_weight : token_embed_weight, input_ids), |
|---|
| | | position_embed_weight); // [N, n_token, embed_dim] |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class CLIPVisionEmbeddings : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int64_t embed_dim; |
|---|
| | | int64_t num_channels; |
|---|
| | | int64_t patch_size; |
|---|
| | | int64_t image_size; |
|---|
| | | int64_t num_patches; |
|---|
| | | int64_t num_positions; |
|---|
| | | |
|---|
| | | void init_params(struct ggml_context* ctx, ggml_type wtype) { |
|---|
| | | params["patch_embedding.weight"] = ggml_new_tensor_4d(ctx, GGML_TYPE_F16, patch_size, patch_size, num_channels, embed_dim); |
|---|
| | | params["class_embedding"] = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, embed_dim); |
|---|
| | | params["position_embedding.weight"] = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, embed_dim, num_positions); |
|---|
| | | } |
|---|
| | | |
|---|
| | | public: |
|---|
| | | CLIPVisionEmbeddings(int64_t embed_dim, |
|---|
| | | int64_t num_channels = 3, |
|---|
| | | int64_t patch_size = 14, |
|---|
| | | int64_t image_size = 224) |
|---|
| | | : embed_dim(embed_dim), |
|---|
| | | num_channels(num_channels), |
|---|
| | | patch_size(patch_size), |
|---|
| | | image_size(image_size) { |
|---|
| | | num_patches = (image_size / patch_size) * (image_size / patch_size); |
|---|
| | | num_positions = num_patches + 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* pixel_values) { |
|---|
| | | // pixel_values: [N, num_channels, image_size, image_size] |
|---|
| | | // return: [N, num_positions, embed_dim] |
|---|
| | | GGML_ASSERT(pixel_values->ne[0] == image_size && pixel_values->ne[1] == image_size && pixel_values->ne[2] == num_channels); |
|---|
| | | |
|---|
| | | auto patch_embed_weight = params["patch_embedding.weight"]; |
|---|
| | | auto class_embed_weight = params["class_embedding"]; |
|---|
| | | auto position_embed_weight = params["position_embedding.weight"]; |
|---|
| | | |
|---|
| | | // concat(patch_embedding, class_embedding) + position_embedding |
|---|
| | | struct ggml_tensor* patch_embedding; |
|---|
| | | int64_t N = pixel_values->ne[3]; |
|---|
| | | patch_embedding = ggml_nn_conv_2d(ctx, pixel_values, patch_embed_weight, NULL, patch_size, patch_size); // [N, embed_dim, image_size // pacht_size, image_size // pacht_size] |
|---|
| | | patch_embedding = ggml_reshape_3d(ctx, patch_embedding, num_patches, embed_dim, N); // [N, embed_dim, num_patches] |
|---|
| | | patch_embedding = ggml_cont(ctx, ggml_permute(ctx, patch_embedding, 1, 0, 2, 3)); // [N, num_patches, embed_dim] |
|---|
| | | patch_embedding = ggml_reshape_4d(ctx, patch_embedding, 1, embed_dim, num_patches, N); // [N, num_patches, embed_dim, 1] |
|---|
| | | |
|---|
| | | struct ggml_tensor* class_embedding = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, embed_dim, N); |
|---|
| | | class_embedding = ggml_repeat(ctx, class_embed_weight, class_embedding); // [N, embed_dim] |
|---|
| | | class_embedding = ggml_reshape_4d(ctx, class_embedding, 1, embed_dim, 1, N); // [N, 1, embed_dim, 1] |
|---|
| | | |
|---|
| | | struct ggml_tensor* x = ggml_concat(ctx, class_embedding, patch_embedding); // [N, num_positions, embed_dim, 1] |
|---|
| | | x = ggml_reshape_3d(ctx, x, embed_dim, num_positions, N); // [N, num_positions, embed_dim] |
|---|
| | | x = ggml_add(ctx, x, position_embed_weight); |
|---|
| | | return x; // [N, num_positions, embed_dim] |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // OPENAI_CLIP_VIT_L_14: https://huggingface.co/openai/clip-vit-large-patch14/blob/main/config.json |
|---|
| | | // OPEN_CLIP_VIT_H_14: https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K/blob/main/config.json |
|---|
| | | // OPEN_CLIP_VIT_BIGG_14: https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/blob/main/config.json (CLIPTextModelWithProjection) |
|---|
| | | |
|---|
| | | enum CLIPVersion { |
|---|
| | | OPENAI_CLIP_VIT_L_14, // SD 1.x and SDXL |
|---|
| | | OPEN_CLIP_VIT_H_14, // SD 2.x |
|---|
| | | OPEN_CLIP_VIT_BIGG_14, // SDXL |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class CLIPTextModel : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | void init_params(struct ggml_context* ctx, ggml_type wtype) { |
|---|
| | | if (version == OPEN_CLIP_VIT_BIGG_14) { |
|---|
| | | params["text_projection"] = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, projection_dim, hidden_size); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | public: |
|---|
| | | CLIPVersion version = OPENAI_CLIP_VIT_L_14; |
|---|
| | | // network hparams |
|---|
| | | int32_t vocab_size = 49408; |
|---|
| | | int32_t n_token = 77; // max_position_embeddings |
|---|
| | | int32_t hidden_size = 768; |
|---|
| | | int32_t intermediate_size = 3072; |
|---|
| | | int32_t n_head = 12; |
|---|
| | | int32_t n_layer = 12; // num_hidden_layers |
|---|
| | | int32_t projection_dim = 1280; // only for OPEN_CLIP_VIT_BIGG_14 |
|---|
| | | int32_t clip_skip = -1; |
|---|
| | | bool with_final_ln = true; |
|---|
| | | |
|---|
| | | CLIPTextModel(CLIPVersion version = OPENAI_CLIP_VIT_L_14, |
|---|
| | | int clip_skip_value = -1, |
|---|
| | | bool with_final_ln = true) |
|---|
| | | : version(version), with_final_ln(with_final_ln) { |
|---|
| | | if (version == OPEN_CLIP_VIT_H_14) { |
|---|
| | | hidden_size = 1024; |
|---|
| | | intermediate_size = 4096; |
|---|
| | | n_head = 16; |
|---|
| | | n_layer = 24; |
|---|
| | | } else if (version == OPEN_CLIP_VIT_BIGG_14) { // CLIPTextModelWithProjection |
|---|
| | | hidden_size = 1280; |
|---|
| | | intermediate_size = 5120; |
|---|
| | | n_head = 20; |
|---|
| | | n_layer = 32; |
|---|
| | | } |
|---|
| | | set_clip_skip(clip_skip_value); |
|---|
| | | |
|---|
| | | blocks["embeddings"] = std::shared_ptr<GGMLBlock>(new CLIPEmbeddings(hidden_size, vocab_size, n_token)); |
|---|
| | | blocks["encoder"] = std::shared_ptr<GGMLBlock>(new CLIPEncoder(n_layer, hidden_size, n_head, intermediate_size)); |
|---|
| | | blocks["final_layer_norm"] = std::shared_ptr<GGMLBlock>(new LayerNorm(hidden_size)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | void set_clip_skip(int skip) { |
|---|
| | | if (skip <= 0) { |
|---|
| | | return; |
|---|
| | | } |
|---|
| | | clip_skip = skip; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* get_token_embed_weight() { |
|---|
| | | auto embeddings = std::dynamic_pointer_cast<CLIPEmbeddings>(blocks["embeddings"]); |
|---|
| | | return embeddings->get_token_embed_weight(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, |
|---|
| | | struct ggml_tensor* input_ids, |
|---|
| | | struct ggml_tensor* tkn_embeddings, |
|---|
| | | size_t max_token_idx = 0, |
|---|
| | | bool return_pooled = false) { |
|---|
| | | // input_ids: [N, n_token] |
|---|
| | | auto embeddings = std::dynamic_pointer_cast<CLIPEmbeddings>(blocks["embeddings"]); |
|---|
| | | auto encoder = std::dynamic_pointer_cast<CLIPEncoder>(blocks["encoder"]); |
|---|
| | | auto final_layer_norm = std::dynamic_pointer_cast<LayerNorm>(blocks["final_layer_norm"]); |
|---|
| | | |
|---|
| | | auto x = embeddings->forward(ctx, input_ids, tkn_embeddings); // [N, n_token, hidden_size] |
|---|
| | | x = encoder->forward(ctx, x, return_pooled ? -1 : clip_skip, true); |
|---|
| | | if (return_pooled || with_final_ln) { |
|---|
| | | x = final_layer_norm->forward(ctx, x); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (return_pooled) { |
|---|
| | | auto text_projection = params["text_projection"]; |
|---|
| | | ggml_tensor* pooled = ggml_view_1d(ctx, x, hidden_size, x->nb[1] * max_token_idx); |
|---|
| | | pooled = ggml_mul_mat(ctx, ggml_cont(ctx, ggml_transpose(ctx, text_projection)), pooled); |
|---|
| | | return pooled; |
|---|
| | | } |
|---|
| | | |
|---|
| | | return x; // [N, n_token, hidden_size] |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class CLIPVisionModel : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | void init_params(struct ggml_context* ctx, ggml_type wtype) { |
|---|
| | | params["visual_projection"] = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, projection_dim, hidden_size); |
|---|
| | | } |
|---|
| | | |
|---|
| | | public: |
|---|
| | | // network hparams |
|---|
| | | int32_t num_channels = 3; |
|---|
| | | int32_t patch_size = 14; |
|---|
| | | int32_t image_size = 224; |
|---|
| | | int32_t num_positions = 257; // (image_size / patch_size)^2 + 1 |
|---|
| | | int32_t hidden_size = 1024; |
|---|
| | | int32_t intermediate_size = 4096; |
|---|
| | | int32_t n_head = 16; |
|---|
| | | int32_t n_layer = 24; |
|---|
| | | int32_t projection_dim = 768; |
|---|
| | | |
|---|
| | | public: |
|---|
| | | CLIPVisionModel(CLIPVersion version = OPEN_CLIP_VIT_H_14) { |
|---|
| | | if (version == OPEN_CLIP_VIT_H_14) { |
|---|
| | | hidden_size = 1280; |
|---|
| | | intermediate_size = 5120; |
|---|
| | | n_head = 16; |
|---|
| | | n_layer = 32; |
|---|
| | | projection_dim = 1024; |
|---|
| | | } else if (version == OPEN_CLIP_VIT_BIGG_14) { |
|---|
| | | hidden_size = 1664; |
|---|
| | | intermediate_size = 8192; |
|---|
| | | n_head = 16; |
|---|
| | | n_layer = 48; |
|---|
| | | } |
|---|
| | | |
|---|
| | | blocks["embeddings"] = std::shared_ptr<GGMLBlock>(new CLIPVisionEmbeddings(hidden_size, num_channels, patch_size, image_size)); |
|---|
| | | blocks["pre_layernorm"] = std::shared_ptr<GGMLBlock>(new LayerNorm(hidden_size)); |
|---|
| | | blocks["encoder"] = std::shared_ptr<GGMLBlock>(new CLIPEncoder(n_layer, hidden_size, n_head, intermediate_size)); |
|---|
| | | blocks["post_layernorm"] = std::shared_ptr<GGMLBlock>(new LayerNorm(hidden_size)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* pixel_values) { |
|---|
| | | // pixel_values: [N, num_channels, image_size, image_size] |
|---|
| | | // return: // [N, projection_dim] |
|---|
| | | auto embeddings = std::dynamic_pointer_cast<CLIPVisionEmbeddings>(blocks["embeddings"]); |
|---|
| | | auto pre_layernorm = std::dynamic_pointer_cast<LayerNorm>(blocks["pre_layernorm"]); |
|---|
| | | auto encoder = std::dynamic_pointer_cast<CLIPEncoder>(blocks["encoder"]); |
|---|
| | | auto post_layernorm = std::dynamic_pointer_cast<LayerNorm>(blocks["post_layernorm"]); |
|---|
| | | |
|---|
| | | auto x = embeddings->forward(ctx, pixel_values); // [N, num_positions, embed_dim] |
|---|
| | | x = pre_layernorm->forward(ctx, x); |
|---|
| | | x = encoder->forward(ctx, x, -1, true); |
|---|
| | | x = post_layernorm->forward(ctx, x); // [N, n_token, hidden_size] |
|---|
| | | |
|---|
| | | GGML_ASSERT(x->ne[2] == 1); |
|---|
| | | int64_t max_token_idx = 0; |
|---|
| | | ggml_tensor* pooled = ggml_view_1d(ctx, x, x->ne[0], x->nb[1] * max_token_idx); // assert N == 1 |
|---|
| | | auto visual_projection = params["visual_projection"]; |
|---|
| | | pooled = ggml_mul_mat(ctx, ggml_cont(ctx, ggml_transpose(ctx, visual_projection)), pooled); |
|---|
| | | return pooled; // [N, projection_dim] |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class CLIPVisionModelProjection : public GGMLBlock { |
|---|
| | | public: |
|---|
| | | int32_t hidden_size = 1024; |
|---|
| | | int32_t projection_dim = 1024; |
|---|
| | | int32_t image_size = 224; |
|---|
| | | |
|---|
| | | public: |
|---|
| | | CLIPVisionModelProjection(CLIPVersion version = OPEN_CLIP_VIT_H_14) { |
|---|
| | | if (version == OPEN_CLIP_VIT_H_14) { |
|---|
| | | hidden_size = 1280; |
|---|
| | | projection_dim = 1024; |
|---|
| | | } else if (version == OPEN_CLIP_VIT_BIGG_14) { |
|---|
| | | hidden_size = 1664; |
|---|
| | | } |
|---|
| | | |
|---|
| | | blocks["visual_model"] = std::shared_ptr<GGMLBlock>(new CLIPVisionModel(version)); |
|---|
| | | blocks["visual_projection"] = std::shared_ptr<GGMLBlock>(new Linear(hidden_size, projection_dim, false)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* pixel_values) { |
|---|
| | | // pixel_values: [N, num_channels, image_size, image_size] |
|---|
| | | // return: [N, num_positions, projection_dim] |
|---|
| | | auto visual_model = std::dynamic_pointer_cast<CLIPVisionModel>(blocks["visual_model"]); |
|---|
| | | auto visual_projection = std::dynamic_pointer_cast<Linear>(blocks["visual_projection"]); |
|---|
| | | |
|---|
| | | auto x = visual_model->forward(ctx, pixel_values); // [N, embed_dim] |
|---|
| | | x = visual_projection->forward(ctx, x); // [N, projection_dim] |
|---|
| | | |
|---|
| | | return x; // [N, projection_dim] |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // ldm.modules.encoders.modules.FrozenCLIPEmbedder |
|---|
| | | // Ref: https://github.com/AUTOMATIC1111/stable-diffusion-webui/blob/cad87bf4e3e0b0a759afa94e933527c3123d59bc/modules/sd_hijack_clip.py#L283 |
|---|
| | | struct FrozenCLIPEmbedderWithCustomWords : public GGMLModule { |
|---|
| | | SDVersion version = VERSION_1_x; |
|---|
| | | CLIPTokenizer tokenizer; |
|---|
| | | CLIPTextModel text_model; |
|---|
| | | CLIPTextModel text_model2; |
|---|
| | | |
|---|
| | | std::string embd_dir; |
|---|
| | | int32_t num_custom_embeddings = 0; |
|---|
| | | std::vector<uint8_t> token_embed_custom; |
|---|
| | | std::vector<std::string> readed_embeddings; |
|---|
| | | |
|---|
| | | FrozenCLIPEmbedderWithCustomWords(ggml_backend_t backend, |
|---|
| | | ggml_type wtype, |
|---|
| | | SDVersion version = VERSION_1_x, |
|---|
| | | int clip_skip = -1) |
|---|
| | | : GGMLModule(backend, wtype), version(version), tokenizer(version) { |
|---|
| | | if (clip_skip <= 0) { |
|---|
| | | clip_skip = 1; |
|---|
| | | if (version == VERSION_2_x || version == VERSION_XL) { |
|---|
| | | clip_skip = 2; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | if (version == VERSION_1_x) { |
|---|
| | | text_model = CLIPTextModel(OPENAI_CLIP_VIT_L_14, clip_skip); |
|---|
| | | text_model.init(params_ctx, wtype); |
|---|
| | | } else if (version == VERSION_2_x) { |
|---|
| | | text_model = CLIPTextModel(OPEN_CLIP_VIT_H_14, clip_skip); |
|---|
| | | text_model.init(params_ctx, wtype); |
|---|
| | | } else if (version == VERSION_XL) { |
|---|
| | | text_model = CLIPTextModel(OPENAI_CLIP_VIT_L_14, clip_skip, false); |
|---|
| | | text_model2 = CLIPTextModel(OPEN_CLIP_VIT_BIGG_14, clip_skip, false); |
|---|
| | | text_model.init(params_ctx, wtype); |
|---|
| | | text_model2.init(params_ctx, wtype); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string get_desc() { |
|---|
| | | return "clip"; |
|---|
| | | } |
|---|
| | | |
|---|
| | | size_t get_params_mem_size() { |
|---|
| | | size_t params_mem_size = text_model.get_params_mem_size(); |
|---|
| | | if (version == VERSION_XL) { |
|---|
| | | params_mem_size += text_model2.get_params_mem_size(); |
|---|
| | | } |
|---|
| | | return params_mem_size; |
|---|
| | | } |
|---|
| | | |
|---|
| | | size_t get_params_num() { |
|---|
| | | size_t params_num = text_model.get_params_num(); |
|---|
| | | if (version == VERSION_XL) { |
|---|
| | | params_num += text_model2.get_params_num(); |
|---|
| | | } |
|---|
| | | return params_num; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void set_clip_skip(int clip_skip) { |
|---|
| | | text_model.set_clip_skip(clip_skip); |
|---|
| | | if (version == VERSION_XL) { |
|---|
| | | text_model2.set_clip_skip(clip_skip); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | void get_param_tensors(std::map<std::string, struct ggml_tensor*>& tensors, const std::string prefix) { |
|---|
| | | text_model.get_param_tensors(tensors, prefix + "transformer.text_model"); |
|---|
| | | if (version == VERSION_XL) { |
|---|
| | | text_model2.get_param_tensors(tensors, prefix + "1.transformer.text_model"); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool load_embedding(std::string embd_name, std::string embd_path, std::vector<int32_t>& bpe_tokens) { |
|---|
| | | // the order matters |
|---|
| | | ModelLoader model_loader; |
|---|
| | | if (!model_loader.init_from_file(embd_path)) { |
|---|
| | | LOG_ERROR("embedding '%s' failed", embd_name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | struct ggml_init_params params; |
|---|
| | | params.mem_size = 32 * 1024; // max for custom embeddings 32 KB |
|---|
| | | params.mem_buffer = NULL; |
|---|
| | | params.no_alloc = false; |
|---|
| | | struct ggml_context* embd_ctx = ggml_init(params); |
|---|
| | | struct ggml_tensor* embd = NULL; |
|---|
| | | auto on_load = [&](const TensorStorage& tensor_storage, ggml_tensor** dst_tensor) { |
|---|
| | | if (tensor_storage.ne[0] != text_model.hidden_size) { |
|---|
| | | LOG_DEBUG("embedding wrong hidden size, got %i, expected %i", tensor_storage.ne[0], text_model.hidden_size); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | embd = ggml_new_tensor_2d(embd_ctx, wtype, text_model.hidden_size, tensor_storage.n_dims > 1 ? tensor_storage.ne[1] : 1); |
|---|
| | | *dst_tensor = embd; |
|---|
| | | return true; |
|---|
| | | }; |
|---|
| | | model_loader.load_tensors(on_load, NULL); |
|---|
| | | readed_embeddings.push_back(embd_name); |
|---|
| | | token_embed_custom.resize(token_embed_custom.size() + ggml_nbytes(embd)); |
|---|
| | | memcpy((void*)(token_embed_custom.data() + num_custom_embeddings * text_model.hidden_size * ggml_type_size(wtype)), |
|---|
| | | embd->data, |
|---|
| | | ggml_nbytes(embd)); |
|---|
| | | for (int i = 0; i < embd->ne[1]; i++) { |
|---|
| | | bpe_tokens.push_back(text_model.vocab_size + num_custom_embeddings); |
|---|
| | | // LOG_DEBUG("new custom token: %i", text_model.vocab_size + num_custom_embeddings); |
|---|
| | | num_custom_embeddings++; |
|---|
| | | } |
|---|
| | | LOG_DEBUG("embedding '%s' applied, custom embeddings: %i", embd_name.c_str(), num_custom_embeddings); |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, |
|---|
| | | struct ggml_tensor* input_ids, |
|---|
| | | struct ggml_tensor* input_ids2, |
|---|
| | | struct ggml_tensor* embeddings, |
|---|
| | | size_t max_token_idx = 0, |
|---|
| | | bool return_pooled = false) { |
|---|
| | | if (return_pooled) { |
|---|
| | | return text_model2.forward(ctx, input_ids2, NULL, max_token_idx, return_pooled); |
|---|
| | | } |
|---|
| | | auto hidden_states = text_model.forward(ctx, input_ids, embeddings); // [N, n_token, hidden_size] |
|---|
| | | // LOG_DEBUG("hidden_states: %d %d %d %d", hidden_states->ne[0], hidden_states->ne[1], hidden_states->ne[2], hidden_states->ne[3]); |
|---|
| | | if (version == VERSION_XL) { |
|---|
| | | hidden_states = ggml_reshape_4d(ctx, |
|---|
| | | hidden_states, |
|---|
| | | hidden_states->ne[0], |
|---|
| | | hidden_states->ne[1], |
|---|
| | | hidden_states->ne[2], |
|---|
| | | hidden_states->ne[3]); |
|---|
| | | hidden_states = ggml_cont(ctx, ggml_permute(ctx, hidden_states, 2, 0, 1, 3)); |
|---|
| | | |
|---|
| | | auto hidden_states2 = text_model2.forward(ctx, input_ids2, NULL); // [N, n_token, hidden_size2] |
|---|
| | | // LOG_DEBUG("hidden_states: %d %d %d %d", hidden_states->ne[0], hidden_states->ne[1], hidden_states->ne[2], hidden_states->ne[3]); |
|---|
| | | hidden_states2 = ggml_reshape_4d(ctx, |
|---|
| | | hidden_states2, |
|---|
| | | hidden_states2->ne[0], |
|---|
| | | hidden_states2->ne[1], |
|---|
| | | hidden_states2->ne[2], |
|---|
| | | hidden_states2->ne[3]); |
|---|
| | | hidden_states2 = ggml_cont(ctx, ggml_permute(ctx, hidden_states2, 2, 0, 1, 3)); |
|---|
| | | |
|---|
| | | hidden_states = ggml_concat(ctx, hidden_states, hidden_states2); // [N, n_token, hidden_size + hidden_size2] |
|---|
| | | |
|---|
| | | hidden_states = ggml_cont(ctx, ggml_permute(ctx, hidden_states, 1, 2, 0, 3)); |
|---|
| | | } |
|---|
| | | // LOG_DEBUG("hidden_states: %d %d %d %d", hidden_states->ne[0], hidden_states->ne[1], hidden_states->ne[2], hidden_states->ne[3]); |
|---|
| | | return hidden_states; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_cgraph* build_graph(struct ggml_allocr* allocr, std::vector<int> tokens, bool return_pooled = false) { |
|---|
| | | struct ggml_cgraph* gf = ggml_new_graph(compute_ctx); |
|---|
| | | |
|---|
| | | struct ggml_tensor* input_ids = ggml_new_tensor_1d(compute_ctx, GGML_TYPE_I32, tokens.size()); |
|---|
| | | ggml_allocr_alloc(allocr, input_ids); |
|---|
| | | |
|---|
| | | if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | ggml_backend_tensor_set(input_ids, tokens.data(), 0, tokens.size() * ggml_element_size(input_ids)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* input_ids2 = NULL; |
|---|
| | | size_t max_token_idx = 0; |
|---|
| | | if (version == VERSION_XL) { |
|---|
| | | input_ids2 = ggml_new_tensor_1d(compute_ctx, GGML_TYPE_I32, tokens.size()); |
|---|
| | | ggml_allocr_alloc(allocr, input_ids2); |
|---|
| | | |
|---|
| | | auto it = std::find(tokens.begin(), tokens.end(), EOS_TOKEN_ID); |
|---|
| | | if (it != tokens.end()) { |
|---|
| | | std::fill(std::next(it), tokens.end(), 0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | max_token_idx = std::min<size_t>(std::distance(tokens.begin(), it), tokens.size() - 1); |
|---|
| | | |
|---|
| | | // for (int i = 0; i < tokens.size(); i++) { |
|---|
| | | // printf("%d ", tokens[i]); |
|---|
| | | // } |
|---|
| | | // printf("\n"); |
|---|
| | | |
|---|
| | | if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | ggml_backend_tensor_set(input_ids2, tokens.data(), 0, tokens.size() * ggml_element_size(input_ids2)); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* embeddings = NULL; |
|---|
| | | |
|---|
| | | if (num_custom_embeddings > 0 && version != VERSION_XL) { |
|---|
| | | embeddings = ggml_new_tensor_2d(compute_ctx, |
|---|
| | | wtype, |
|---|
| | | text_model.hidden_size, |
|---|
| | | text_model.vocab_size + num_custom_embeddings /* custom placeholder */); |
|---|
| | | ggml_allocr_alloc(allocr, embeddings); |
|---|
| | | if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | // really bad, there is memory inflexibility (this is for host<->device memory conflicts) |
|---|
| | | auto token_embed_weight = text_model.get_token_embed_weight(); |
|---|
| | | void* freeze_data = malloc(ggml_nbytes(token_embed_weight)); |
|---|
| | | ggml_backend_tensor_get_and_sync(backend, |
|---|
| | | token_embed_weight, |
|---|
| | | freeze_data, |
|---|
| | | 0, |
|---|
| | | ggml_nbytes(token_embed_weight)); |
|---|
| | | ggml_backend_tensor_set(embeddings, freeze_data, 0, ggml_nbytes(token_embed_weight)); |
|---|
| | | free(freeze_data); |
|---|
| | | // concatenate custom embeddings |
|---|
| | | ggml_backend_tensor_set(embeddings, |
|---|
| | | (const void*)token_embed_custom.data(), |
|---|
| | | ggml_nbytes(token_embed_weight), |
|---|
| | | num_custom_embeddings * text_model.hidden_size * ggml_type_size(wtype)); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* hidden_states = forward(compute_ctx, input_ids, input_ids2, embeddings, max_token_idx, return_pooled); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, hidden_states); |
|---|
| | | |
|---|
| | | return gf; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void compute(const int n_threads, |
|---|
| | | std::vector<int> tokens, |
|---|
| | | bool return_pooled, |
|---|
| | | ggml_tensor** output, |
|---|
| | | ggml_context* output_ctx = NULL) { |
|---|
| | | auto get_graph = [&]() -> struct ggml_cgraph* { |
|---|
| | | return build_graph(compute_allocr, tokens, return_pooled); |
|---|
| | | }; |
|---|
| | | GGMLModule::compute(get_graph, n_threads, true, output, output_ctx); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::pair<std::vector<int>, std::vector<float>> tokenize(std::string text, |
|---|
| | | bool padding = false) { |
|---|
| | | return tokenize(text, text_model.n_token, padding); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::pair<std::vector<int>, std::vector<float>> tokenize(std::string text, |
|---|
| | | size_t max_length = 0, |
|---|
| | | bool padding = false) { |
|---|
| | | auto parsed_attention = parse_prompt_attention(text); |
|---|
| | | |
|---|
| | | { |
|---|
| | | std::stringstream ss; |
|---|
| | | ss << "["; |
|---|
| | | for (const auto& item : parsed_attention) { |
|---|
| | | ss << "['" << item.first << "', " << item.second << "], "; |
|---|
| | | } |
|---|
| | | ss << "]"; |
|---|
| | | LOG_DEBUG("parse '%s' to %s", text.c_str(), ss.str().c_str()); |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto on_new_token_cb = [&](std::string& str, std::vector<int32_t>& bpe_tokens) -> bool { |
|---|
| | | size_t word_end = str.find(","); |
|---|
| | | std::string embd_name = word_end == std::string::npos ? str : str.substr(0, word_end); |
|---|
| | | embd_name = trim(embd_name); |
|---|
| | | std::string embd_path = get_full_path(embd_dir, embd_name + ".pt"); |
|---|
| | | if (embd_path.size() == 0) { |
|---|
| | | embd_path = get_full_path(embd_dir, embd_name + ".ckpt"); |
|---|
| | | } |
|---|
| | | if (embd_path.size() == 0) { |
|---|
| | | embd_path = get_full_path(embd_dir, embd_name + ".safetensors"); |
|---|
| | | } |
|---|
| | | if (embd_path.size() > 0) { |
|---|
| | | if (load_embedding(embd_name, embd_path, bpe_tokens)) { |
|---|
| | | if (word_end != std::string::npos) { |
|---|
| | | str = str.substr(word_end); |
|---|
| | | } else { |
|---|
| | | str = ""; |
|---|
| | | } |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | return false; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | std::vector<int> tokens; |
|---|
| | | std::vector<float> weights; |
|---|
| | | for (const auto& item : parsed_attention) { |
|---|
| | | const std::string& curr_text = item.first; |
|---|
| | | float curr_weight = item.second; |
|---|
| | | std::vector<int> curr_tokens = tokenizer.encode(curr_text, on_new_token_cb); |
|---|
| | | tokens.insert(tokens.end(), curr_tokens.begin(), curr_tokens.end()); |
|---|
| | | weights.insert(weights.end(), curr_tokens.size(), curr_weight); |
|---|
| | | } |
|---|
| | | tokens.insert(tokens.begin(), BOS_TOKEN_ID); |
|---|
| | | weights.insert(weights.begin(), 1.0); |
|---|
| | | |
|---|
| | | if (max_length > 0) { |
|---|
| | | if (tokens.size() > max_length - 1) { |
|---|
| | | tokens.resize(max_length - 1); |
|---|
| | | weights.resize(max_length - 1); |
|---|
| | | tokens.push_back(EOS_TOKEN_ID); |
|---|
| | | weights.push_back(1.0); |
|---|
| | | } else { |
|---|
| | | tokens.push_back(EOS_TOKEN_ID); |
|---|
| | | weights.push_back(1.0); |
|---|
| | | if (padding) { |
|---|
| | | int pad_token_id = PAD_TOKEN_ID; |
|---|
| | | if (version == VERSION_2_x) { |
|---|
| | | pad_token_id = 0; |
|---|
| | | } |
|---|
| | | tokens.insert(tokens.end(), max_length - tokens.size(), pad_token_id); |
|---|
| | | weights.insert(weights.end(), max_length - weights.size(), 1.0); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for (int i = 0; i < tokens.size(); i++) { |
|---|
| | | // std::cout << tokens[i] << ":" << weights[i] << ", "; |
|---|
| | | // } |
|---|
| | | // std::cout << std::endl; |
|---|
| | | |
|---|
| | | return {tokens, weights}; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct FrozenCLIPVisionEmbedder : public GGMLModule { |
|---|
| | | CLIPVisionModel vision_model; |
|---|
| | | |
|---|
| | | FrozenCLIPVisionEmbedder(ggml_backend_t backend, ggml_type wtype) |
|---|
| | | : GGMLModule(backend, wtype) { |
|---|
| | | vision_model.init(params_ctx, wtype); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string get_desc() { |
|---|
| | | return "clip_vision"; |
|---|
| | | } |
|---|
| | | |
|---|
| | | size_t get_params_mem_size() { |
|---|
| | | return vision_model.get_params_mem_size(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | size_t get_params_num() { |
|---|
| | | return vision_model.get_params_num(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | void get_param_tensors(std::map<std::string, struct ggml_tensor*>& tensors, const std::string prefix) { |
|---|
| | | vision_model.get_param_tensors(tensors, prefix + "transformer.visual_model"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_cgraph* build_graph(struct ggml_allocr* allocr, |
|---|
| | | struct ggml_tensor* pixel_values) { |
|---|
| | | struct ggml_cgraph* gf = ggml_new_graph(compute_ctx); |
|---|
| | | |
|---|
| | | pixel_values = to_backend(pixel_values); |
|---|
| | | |
|---|
| | | struct ggml_tensor* hidden_states = vision_model.forward(compute_ctx, pixel_values); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, hidden_states); |
|---|
| | | |
|---|
| | | return gf; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void alloc_compute_buffer(ggml_context* work_ctx, ggml_tensor* pixel_values) { |
|---|
| | | auto get_graph = [&]() -> struct ggml_cgraph* { |
|---|
| | | return build_graph(compute_allocr, pixel_values); |
|---|
| | | }; |
|---|
| | | GGMLModule::alloc_compute_buffer(get_graph); |
|---|
| | | } |
|---|
| | | |
|---|
| | | void compute(const int n_threads, |
|---|
| | | ggml_tensor* pixel_values, |
|---|
| | | ggml_tensor** output, |
|---|
| | | ggml_context* output_ctx) { |
|---|
| | | auto get_graph = [&]() -> struct ggml_cgraph* { |
|---|
| | | return build_graph(compute_allocr, pixel_values); |
|---|
| | | }; |
|---|
| | | GGMLModule::compute(get_graph, n_threads, true, output, output_ctx); |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | #endif // __CLIP_HPP__ |
|---|
| New file |
| | |
|---|
| | | #ifndef __COMMON_HPP__ |
|---|
| | | #define __COMMON_HPP__ |
|---|
| | | |
|---|
| | | #include "ggml_extend.hpp" |
|---|
| | | |
|---|
| | | class DownSampleBlock : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int channels; |
|---|
| | | int out_channels; |
|---|
| | | bool vae_downsample; |
|---|
| | | |
|---|
| | | public: |
|---|
| | | DownSampleBlock(int channels, |
|---|
| | | int out_channels, |
|---|
| | | bool vae_downsample = false) |
|---|
| | | : channels(channels), |
|---|
| | | out_channels(out_channels), |
|---|
| | | vae_downsample(vae_downsample) { |
|---|
| | | if (vae_downsample) { |
|---|
| | | blocks["conv"] = std::shared_ptr<GGMLBlock>(new Conv2d(channels, out_channels, {3, 3}, {2, 2}, {0, 0})); |
|---|
| | | } else { |
|---|
| | | blocks["op"] = std::shared_ptr<GGMLBlock>(new Conv2d(channels, out_channels, {3, 3}, {2, 2}, {1, 1})); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x) { |
|---|
| | | // x: [N, channels, h, w] |
|---|
| | | if (vae_downsample) { |
|---|
| | | auto conv = std::dynamic_pointer_cast<Conv2d>(blocks["conv"]); |
|---|
| | | |
|---|
| | | x = ggml_pad(ctx, x, 1, 1, 0, 0); |
|---|
| | | x = conv->forward(ctx, x); |
|---|
| | | } else { |
|---|
| | | auto conv = std::dynamic_pointer_cast<Conv2d>(blocks["op"]); |
|---|
| | | |
|---|
| | | x = conv->forward(ctx, x); |
|---|
| | | } |
|---|
| | | return x; // [N, out_channels, h/2, w/2] |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class UpSampleBlock : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int channels; |
|---|
| | | int out_channels; |
|---|
| | | |
|---|
| | | public: |
|---|
| | | UpSampleBlock(int channels, |
|---|
| | | int out_channels) |
|---|
| | | : channels(channels), |
|---|
| | | out_channels(out_channels) { |
|---|
| | | blocks["conv"] = std::shared_ptr<GGMLBlock>(new Conv2d(channels, out_channels, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x) { |
|---|
| | | // x: [N, channels, h, w] |
|---|
| | | auto conv = std::dynamic_pointer_cast<Conv2d>(blocks["conv"]); |
|---|
| | | |
|---|
| | | x = ggml_upscale(ctx, x, 2); // [N, channels, h*2, w*2] |
|---|
| | | x = conv->forward(ctx, x); // [N, out_channels, h*2, w*2] |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class ResBlock : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | // network hparams |
|---|
| | | int64_t channels; // model_channels * (1, 1, 1, 2, 2, 4, 4, 4) |
|---|
| | | int64_t emb_channels; // time_embed_dim |
|---|
| | | int64_t out_channels; // mult * model_channels |
|---|
| | | std::pair<int, int> kernel_size; |
|---|
| | | int dims; |
|---|
| | | bool skip_t_emb; |
|---|
| | | bool exchange_temb_dims; |
|---|
| | | |
|---|
| | | std::shared_ptr<GGMLBlock> conv_nd(int dims, |
|---|
| | | int64_t in_channels, |
|---|
| | | int64_t out_channels, |
|---|
| | | std::pair<int, int> kernel_size, |
|---|
| | | std::pair<int, int> padding) { |
|---|
| | | GGML_ASSERT(dims == 2 || dims == 3); |
|---|
| | | if (dims == 3) { |
|---|
| | | return std::shared_ptr<GGMLBlock>(new Conv3dnx1x1(in_channels, out_channels, kernel_size.first, 1, padding.first)); |
|---|
| | | } else { |
|---|
| | | return std::shared_ptr<GGMLBlock>(new Conv2d(in_channels, out_channels, kernel_size, {1, 1}, padding)); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | public: |
|---|
| | | ResBlock(int64_t channels, |
|---|
| | | int64_t emb_channels, |
|---|
| | | int64_t out_channels, |
|---|
| | | std::pair<int, int> kernel_size = {3, 3}, |
|---|
| | | int dims = 2, |
|---|
| | | bool exchange_temb_dims = false, |
|---|
| | | bool skip_t_emb = false) |
|---|
| | | : channels(channels), |
|---|
| | | emb_channels(emb_channels), |
|---|
| | | out_channels(out_channels), |
|---|
| | | kernel_size(kernel_size), |
|---|
| | | dims(dims), |
|---|
| | | skip_t_emb(skip_t_emb), |
|---|
| | | exchange_temb_dims(exchange_temb_dims) { |
|---|
| | | std::pair<int, int> padding = {kernel_size.first / 2, kernel_size.second / 2}; |
|---|
| | | blocks["in_layers.0"] = std::shared_ptr<GGMLBlock>(new GroupNorm32(channels)); |
|---|
| | | // in_layer_1 is nn.SILU() |
|---|
| | | blocks["in_layers.2"] = conv_nd(dims, channels, out_channels, kernel_size, padding); |
|---|
| | | |
|---|
| | | if (!skip_t_emb) { |
|---|
| | | // emb_layer_0 is nn.SILU() |
|---|
| | | blocks["emb_layers.1"] = std::shared_ptr<GGMLBlock>(new Linear(emb_channels, out_channels)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | blocks["out_layers.0"] = std::shared_ptr<GGMLBlock>(new GroupNorm32(out_channels)); |
|---|
| | | // out_layer_1 is nn.SILU() |
|---|
| | | // out_layer_2 is nn.Dropout(), skip for inference |
|---|
| | | blocks["out_layers.3"] = conv_nd(dims, out_channels, out_channels, kernel_size, padding); |
|---|
| | | |
|---|
| | | if (out_channels != channels) { |
|---|
| | | blocks["skip_connection"] = conv_nd(dims, channels, out_channels, {1, 1}, {0, 0}); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | virtual struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x, struct ggml_tensor* emb = NULL) { |
|---|
| | | // For dims==3, we reduce dimension from 5d to 4d by merging h and w, in order not to change ggml |
|---|
| | | // [N, c, t, h, w] => [N, c, t, h * w] |
|---|
| | | // x: [N, channels, h, w] if dims == 2 else [N, channels, t, h, w] |
|---|
| | | // emb: [N, emb_channels] if dims == 2 else [N, t, emb_channels] |
|---|
| | | auto in_layers_0 = std::dynamic_pointer_cast<GroupNorm32>(blocks["in_layers.0"]); |
|---|
| | | auto in_layers_2 = std::dynamic_pointer_cast<UnaryBlock>(blocks["in_layers.2"]); |
|---|
| | | auto out_layers_0 = std::dynamic_pointer_cast<GroupNorm32>(blocks["out_layers.0"]); |
|---|
| | | auto out_layers_3 = std::dynamic_pointer_cast<UnaryBlock>(blocks["out_layers.3"]); |
|---|
| | | |
|---|
| | | if (emb == NULL) { |
|---|
| | | GGML_ASSERT(skip_t_emb); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // in_layers |
|---|
| | | auto h = in_layers_0->forward(ctx, x); |
|---|
| | | h = ggml_silu_inplace(ctx, h); |
|---|
| | | h = in_layers_2->forward(ctx, h); // [N, out_channels, h, w] if dims == 2 else [N, out_channels, t, h, w] |
|---|
| | | |
|---|
| | | // emb_layers |
|---|
| | | if (!skip_t_emb) { |
|---|
| | | auto emb_layer_1 = std::dynamic_pointer_cast<Linear>(blocks["emb_layers.1"]); |
|---|
| | | |
|---|
| | | auto emb_out = ggml_silu(ctx, emb); |
|---|
| | | emb_out = emb_layer_1->forward(ctx, emb_out); // [N, out_channels] if dims == 2 else [N, t, out_channels] |
|---|
| | | |
|---|
| | | if (dims == 2) { |
|---|
| | | emb_out = ggml_reshape_4d(ctx, emb_out, 1, 1, emb_out->ne[0], emb_out->ne[1]); // [N, out_channels, 1, 1] |
|---|
| | | } else { |
|---|
| | | emb_out = ggml_reshape_4d(ctx, emb_out, 1, emb_out->ne[0], emb_out->ne[1], emb_out->ne[2]); // [N, t, out_channels, 1] |
|---|
| | | if (exchange_temb_dims) { |
|---|
| | | // emb_out = rearrange(emb_out, "b t c ... -> b c t ...") |
|---|
| | | emb_out = ggml_cont(ctx, ggml_permute(ctx, emb_out, 0, 2, 1, 3)); // [N, out_channels, t, 1] |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | h = ggml_add(ctx, h, emb_out); // [N, out_channels, h, w] if dims == 2 else [N, out_channels, t, h, w] |
|---|
| | | } |
|---|
| | | |
|---|
| | | // out_layers |
|---|
| | | h = out_layers_0->forward(ctx, h); |
|---|
| | | h = ggml_silu_inplace(ctx, h); |
|---|
| | | // dropout, skip for inference |
|---|
| | | h = out_layers_3->forward(ctx, h); |
|---|
| | | |
|---|
| | | // skip connection |
|---|
| | | if (out_channels != channels) { |
|---|
| | | auto skip_connection = std::dynamic_pointer_cast<UnaryBlock>(blocks["skip_connection"]); |
|---|
| | | x = skip_connection->forward(ctx, x); // [N, out_channels, h, w] if dims == 2 else [N, out_channels, t, h, w] |
|---|
| | | } |
|---|
| | | |
|---|
| | | h = ggml_add(ctx, h, x); |
|---|
| | | return h; // [N, out_channels, h, w] if dims == 2 else [N, out_channels, t, h, w] |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class GEGLU : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int64_t dim_in; |
|---|
| | | int64_t dim_out; |
|---|
| | | |
|---|
| | | void init_params(struct ggml_context* ctx, ggml_type wtype) { |
|---|
| | | params["proj.weight"] = ggml_new_tensor_2d(ctx, wtype, dim_in, dim_out * 2); |
|---|
| | | params["proj.bias"] = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, dim_out * 2); |
|---|
| | | } |
|---|
| | | |
|---|
| | | public: |
|---|
| | | GEGLU(int64_t dim_in, int64_t dim_out) |
|---|
| | | : dim_in(dim_in), dim_out(dim_out) {} |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x) { |
|---|
| | | // x: [ne3, ne2, ne1, dim_in] |
|---|
| | | // return: [ne3, ne2, ne1, dim_out] |
|---|
| | | struct ggml_tensor* w = params["proj.weight"]; |
|---|
| | | struct ggml_tensor* b = params["proj.bias"]; |
|---|
| | | |
|---|
| | | auto x_w = ggml_view_2d(ctx, w, w->ne[0], w->ne[1] / 2, w->nb[1], 0); // [dim_out, dim_in] |
|---|
| | | auto x_b = ggml_view_1d(ctx, b, b->ne[0] / 2, 0); // [dim_out, dim_in] |
|---|
| | | auto gate_w = ggml_view_2d(ctx, w, w->ne[0], w->ne[1] / 2, w->nb[1], w->nb[1] * w->ne[1] / 2); // [dim_out, ] |
|---|
| | | auto gate_b = ggml_view_1d(ctx, b, b->ne[0] / 2, b->nb[0] * b->ne[0] / 2); // [dim_out, ] |
|---|
| | | |
|---|
| | | auto x_in = x; |
|---|
| | | x = ggml_nn_linear(ctx, x_in, x_w, x_b); // [ne3, ne2, ne1, dim_out] |
|---|
| | | auto gate = ggml_nn_linear(ctx, x_in, gate_w, gate_b); // [ne3, ne2, ne1, dim_out] |
|---|
| | | |
|---|
| | | gate = ggml_gelu_inplace(ctx, gate); |
|---|
| | | |
|---|
| | | x = ggml_mul(ctx, x, gate); // [ne3, ne2, ne1, dim_out] |
|---|
| | | |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class FeedForward : public GGMLBlock { |
|---|
| | | public: |
|---|
| | | FeedForward(int64_t dim, |
|---|
| | | int64_t dim_out, |
|---|
| | | int64_t mult = 4) { |
|---|
| | | int64_t inner_dim = dim * mult; |
|---|
| | | |
|---|
| | | blocks["net.0"] = std::shared_ptr<GGMLBlock>(new GEGLU(dim, inner_dim)); |
|---|
| | | // net_1 is nn.Dropout(), skip for inference |
|---|
| | | blocks["net.2"] = std::shared_ptr<GGMLBlock>(new Linear(inner_dim, dim_out)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x) { |
|---|
| | | // x: [ne3, ne2, ne1, dim] |
|---|
| | | // return: [ne3, ne2, ne1, dim_out] |
|---|
| | | |
|---|
| | | auto net_0 = std::dynamic_pointer_cast<GEGLU>(blocks["net.0"]); |
|---|
| | | auto net_2 = std::dynamic_pointer_cast<Linear>(blocks["net.2"]); |
|---|
| | | |
|---|
| | | x = net_0->forward(ctx, x); // [ne3, ne2, ne1, inner_dim] |
|---|
| | | x = net_2->forward(ctx, x); // [ne3, ne2, ne1, dim_out] |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class CrossAttention : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int64_t query_dim; |
|---|
| | | int64_t context_dim; |
|---|
| | | int64_t n_head; |
|---|
| | | int64_t d_head; |
|---|
| | | |
|---|
| | | public: |
|---|
| | | CrossAttention(int64_t query_dim, |
|---|
| | | int64_t context_dim, |
|---|
| | | int64_t n_head, |
|---|
| | | int64_t d_head) |
|---|
| | | : n_head(n_head), |
|---|
| | | d_head(d_head), |
|---|
| | | query_dim(query_dim), |
|---|
| | | context_dim(context_dim) { |
|---|
| | | int64_t inner_dim = d_head * n_head; |
|---|
| | | |
|---|
| | | blocks["to_q"] = std::shared_ptr<GGMLBlock>(new Linear(query_dim, inner_dim, false)); |
|---|
| | | blocks["to_k"] = std::shared_ptr<GGMLBlock>(new Linear(context_dim, inner_dim, false)); |
|---|
| | | blocks["to_v"] = std::shared_ptr<GGMLBlock>(new Linear(context_dim, inner_dim, false)); |
|---|
| | | |
|---|
| | | blocks["to_out.0"] = std::shared_ptr<GGMLBlock>(new Linear(inner_dim, query_dim)); |
|---|
| | | // to_out_1 is nn.Dropout(), skip for inference |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x, struct ggml_tensor* context) { |
|---|
| | | // x: [N, n_token, query_dim] |
|---|
| | | // context: [N, n_context, context_dim] |
|---|
| | | // return: [N, n_token, query_dim] |
|---|
| | | auto to_q = std::dynamic_pointer_cast<Linear>(blocks["to_q"]); |
|---|
| | | auto to_k = std::dynamic_pointer_cast<Linear>(blocks["to_k"]); |
|---|
| | | auto to_v = std::dynamic_pointer_cast<Linear>(blocks["to_v"]); |
|---|
| | | auto to_out_0 = std::dynamic_pointer_cast<Linear>(blocks["to_out.0"]); |
|---|
| | | |
|---|
| | | int64_t n = x->ne[2]; |
|---|
| | | int64_t n_token = x->ne[1]; |
|---|
| | | int64_t n_context = context->ne[1]; |
|---|
| | | int64_t inner_dim = d_head * n_head; |
|---|
| | | |
|---|
| | | auto q = to_q->forward(ctx, x); // [N, n_token, inner_dim] |
|---|
| | | q = ggml_reshape_4d(ctx, q, d_head, n_head, n_token, n); // [N, n_token, n_head, d_head] |
|---|
| | | q = ggml_cont(ctx, ggml_permute(ctx, q, 0, 2, 1, 3)); // [N, n_head, n_token, d_head] |
|---|
| | | q = ggml_reshape_3d(ctx, q, d_head, n_token, n_head * n); // [N * n_head, n_token, d_head] |
|---|
| | | |
|---|
| | | auto k = to_k->forward(ctx, context); // [N, n_context, inner_dim] |
|---|
| | | k = ggml_reshape_4d(ctx, k, d_head, n_head, n_context, n); // [N, n_context, n_head, d_head] |
|---|
| | | k = ggml_cont(ctx, ggml_permute(ctx, k, 0, 2, 1, 3)); // [N, n_head, n_context, d_head] |
|---|
| | | k = ggml_reshape_3d(ctx, k, d_head, n_context, n_head * n); // [N * n_head, n_context, d_head] |
|---|
| | | |
|---|
| | | auto v = to_v->forward(ctx, context); // [N, n_context, inner_dim] |
|---|
| | | v = ggml_reshape_4d(ctx, v, d_head, n_head, n_context, n); // [N, n_context, n_head, d_head] |
|---|
| | | v = ggml_cont(ctx, ggml_permute(ctx, v, 1, 2, 0, 3)); // [N, n_head, d_head, n_context] |
|---|
| | | v = ggml_reshape_3d(ctx, v, n_context, d_head, n_head * n); // [N * n_head, d_head, n_context] |
|---|
| | | |
|---|
| | | auto kqv = ggml_nn_attention(ctx, q, k, v, false); // [N * n_head, n_token, d_head] |
|---|
| | | kqv = ggml_reshape_4d(ctx, kqv, d_head, n_token, n_head, n); |
|---|
| | | kqv = ggml_cont(ctx, ggml_permute(ctx, kqv, 0, 2, 1, 3)); // [N, n_token, n_head, d_head] |
|---|
| | | |
|---|
| | | x = ggml_reshape_3d(ctx, kqv, d_head * n_head, n_token, n); // [N, n_token, inner_dim] |
|---|
| | | |
|---|
| | | x = to_out_0->forward(ctx, x); // [N, n_token, query_dim] |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class BasicTransformerBlock : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int64_t n_head; |
|---|
| | | int64_t d_head; |
|---|
| | | bool ff_in; |
|---|
| | | |
|---|
| | | public: |
|---|
| | | BasicTransformerBlock(int64_t dim, |
|---|
| | | int64_t n_head, |
|---|
| | | int64_t d_head, |
|---|
| | | int64_t context_dim, |
|---|
| | | bool ff_in = false) |
|---|
| | | : n_head(n_head), d_head(d_head), ff_in(ff_in) { |
|---|
| | | // disable_self_attn is always False |
|---|
| | | // disable_temporal_crossattention is always False |
|---|
| | | // switch_temporal_ca_to_sa is always False |
|---|
| | | // inner_dim is always None or equal to dim |
|---|
| | | // gated_ff is always True |
|---|
| | | blocks["attn1"] = std::shared_ptr<GGMLBlock>(new CrossAttention(dim, dim, n_head, d_head)); |
|---|
| | | blocks["attn2"] = std::shared_ptr<GGMLBlock>(new CrossAttention(dim, context_dim, n_head, d_head)); |
|---|
| | | blocks["ff"] = std::shared_ptr<GGMLBlock>(new FeedForward(dim, dim)); |
|---|
| | | blocks["norm1"] = std::shared_ptr<GGMLBlock>(new LayerNorm(dim)); |
|---|
| | | blocks["norm2"] = std::shared_ptr<GGMLBlock>(new LayerNorm(dim)); |
|---|
| | | blocks["norm3"] = std::shared_ptr<GGMLBlock>(new LayerNorm(dim)); |
|---|
| | | |
|---|
| | | if (ff_in) { |
|---|
| | | blocks["norm_in"] = std::shared_ptr<GGMLBlock>(new LayerNorm(dim)); |
|---|
| | | blocks["ff_in"] = std::shared_ptr<GGMLBlock>(new FeedForward(dim, dim)); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x, struct ggml_tensor* context) { |
|---|
| | | // x: [N, n_token, query_dim] |
|---|
| | | // context: [N, n_context, context_dim] |
|---|
| | | // return: [N, n_token, query_dim] |
|---|
| | | |
|---|
| | | auto attn1 = std::dynamic_pointer_cast<CrossAttention>(blocks["attn1"]); |
|---|
| | | auto attn2 = std::dynamic_pointer_cast<CrossAttention>(blocks["attn2"]); |
|---|
| | | auto ff = std::dynamic_pointer_cast<FeedForward>(blocks["ff"]); |
|---|
| | | auto norm1 = std::dynamic_pointer_cast<LayerNorm>(blocks["norm1"]); |
|---|
| | | auto norm2 = std::dynamic_pointer_cast<LayerNorm>(blocks["norm2"]); |
|---|
| | | auto norm3 = std::dynamic_pointer_cast<LayerNorm>(blocks["norm3"]); |
|---|
| | | |
|---|
| | | if (ff_in) { |
|---|
| | | auto norm_in = std::dynamic_pointer_cast<LayerNorm>(blocks["norm_in"]); |
|---|
| | | auto ff_in = std::dynamic_pointer_cast<FeedForward>(blocks["ff_in"]); |
|---|
| | | |
|---|
| | | auto x_skip = x; |
|---|
| | | x = norm_in->forward(ctx, x); |
|---|
| | | x = ff_in->forward(ctx, x); |
|---|
| | | // self.is_res is always True |
|---|
| | | x = ggml_add(ctx, x, x_skip); |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto r = x; |
|---|
| | | x = norm1->forward(ctx, x); |
|---|
| | | x = attn1->forward(ctx, x, x); // self-attention |
|---|
| | | x = ggml_add(ctx, x, r); |
|---|
| | | r = x; |
|---|
| | | x = norm2->forward(ctx, x); |
|---|
| | | x = attn2->forward(ctx, x, context); // cross-attention |
|---|
| | | x = ggml_add(ctx, x, r); |
|---|
| | | r = x; |
|---|
| | | x = norm3->forward(ctx, x); |
|---|
| | | x = ff->forward(ctx, x); |
|---|
| | | x = ggml_add(ctx, x, r); |
|---|
| | | |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class SpatialTransformer : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int64_t in_channels; // mult * model_channels |
|---|
| | | int64_t n_head; |
|---|
| | | int64_t d_head; |
|---|
| | | int64_t depth = 1; // 1 |
|---|
| | | int64_t context_dim = 768; // hidden_size, 1024 for VERSION_2_x |
|---|
| | | |
|---|
| | | public: |
|---|
| | | SpatialTransformer(int64_t in_channels, |
|---|
| | | int64_t n_head, |
|---|
| | | int64_t d_head, |
|---|
| | | int64_t depth, |
|---|
| | | int64_t context_dim) |
|---|
| | | : in_channels(in_channels), |
|---|
| | | n_head(n_head), |
|---|
| | | d_head(d_head), |
|---|
| | | depth(depth), |
|---|
| | | context_dim(context_dim) { |
|---|
| | | // We will convert unet transformer linear to conv2d 1x1 when loading the weights, so use_linear is always False |
|---|
| | | // disable_self_attn is always False |
|---|
| | | int64_t inner_dim = n_head * d_head; // in_channels |
|---|
| | | blocks["norm"] = std::shared_ptr<GGMLBlock>(new GroupNorm32(in_channels)); |
|---|
| | | blocks["proj_in"] = std::shared_ptr<GGMLBlock>(new Conv2d(in_channels, inner_dim, {1, 1})); |
|---|
| | | |
|---|
| | | for (int i = 0; i < depth; i++) { |
|---|
| | | std::string name = "transformer_blocks." + std::to_string(i); |
|---|
| | | blocks[name] = std::shared_ptr<GGMLBlock>(new BasicTransformerBlock(inner_dim, n_head, d_head, context_dim)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | blocks["proj_out"] = std::shared_ptr<GGMLBlock>(new Conv2d(inner_dim, in_channels, {1, 1})); |
|---|
| | | } |
|---|
| | | |
|---|
| | | virtual struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x, struct ggml_tensor* context) { |
|---|
| | | // x: [N, in_channels, h, w] |
|---|
| | | // context: [N, max_position(aka n_token), hidden_size(aka context_dim)] |
|---|
| | | auto norm = std::dynamic_pointer_cast<GroupNorm32>(blocks["norm"]); |
|---|
| | | auto proj_in = std::dynamic_pointer_cast<Conv2d>(blocks["proj_in"]); |
|---|
| | | auto proj_out = std::dynamic_pointer_cast<Conv2d>(blocks["proj_out"]); |
|---|
| | | |
|---|
| | | auto x_in = x; |
|---|
| | | int64_t n = x->ne[3]; |
|---|
| | | int64_t h = x->ne[1]; |
|---|
| | | int64_t w = x->ne[0]; |
|---|
| | | int64_t inner_dim = n_head * d_head; |
|---|
| | | |
|---|
| | | x = norm->forward(ctx, x); |
|---|
| | | x = proj_in->forward(ctx, x); // [N, inner_dim, h, w] |
|---|
| | | |
|---|
| | | x = ggml_cont(ctx, ggml_permute(ctx, x, 1, 2, 0, 3)); // [N, h, w, inner_dim] |
|---|
| | | x = ggml_reshape_3d(ctx, x, inner_dim, w * h, n); // [N, h * w, inner_dim] |
|---|
| | | |
|---|
| | | for (int i = 0; i < depth; i++) { |
|---|
| | | std::string name = "transformer_blocks." + std::to_string(i); |
|---|
| | | auto transformer_block = std::dynamic_pointer_cast<BasicTransformerBlock>(blocks[name]); |
|---|
| | | |
|---|
| | | x = transformer_block->forward(ctx, x, context); |
|---|
| | | } |
|---|
| | | |
|---|
| | | x = ggml_cont(ctx, ggml_permute(ctx, x, 1, 0, 2, 3)); // [N, inner_dim, h * w] |
|---|
| | | x = ggml_reshape_4d(ctx, x, w, h, inner_dim, n); // [N, inner_dim, h, w] |
|---|
| | | |
|---|
| | | // proj_out |
|---|
| | | x = proj_out->forward(ctx, x); // [N, in_channels, h, w] |
|---|
| | | |
|---|
| | | x = ggml_add(ctx, x, x_in); |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class AlphaBlender : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | void init_params(struct ggml_context* ctx, ggml_type wtype) { |
|---|
| | | params["mix_factor"] = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | float get_alpha() { |
|---|
| | | // image_only_indicator is always tensor([0.]) and since mix_factor.shape is [1,] |
|---|
| | | // so learned_with_images is same as learned |
|---|
| | | float alpha = ggml_backend_tensor_get_f32(params["mix_factor"]); |
|---|
| | | return sigmoid(alpha); |
|---|
| | | } |
|---|
| | | |
|---|
| | | public: |
|---|
| | | AlphaBlender() { |
|---|
| | | // merge_strategy is always learned_with_images |
|---|
| | | // for inference, we don't need to set alpha |
|---|
| | | // since mix_factor.shape is [1,], we don't need rearrange using rearrange_pattern |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, |
|---|
| | | struct ggml_tensor* x_spatial, |
|---|
| | | struct ggml_tensor* x_temporal) { |
|---|
| | | // image_only_indicator is always tensor([0.]) |
|---|
| | | float alpha = get_alpha(); |
|---|
| | | auto x = ggml_add(ctx, |
|---|
| | | ggml_scale(ctx, x_spatial, alpha), |
|---|
| | | ggml_scale(ctx, x_temporal, 1.0f - alpha)); |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class VideoResBlock : public ResBlock { |
|---|
| | | public: |
|---|
| | | VideoResBlock(int channels, |
|---|
| | | int emb_channels, |
|---|
| | | int out_channels, |
|---|
| | | std::pair<int, int> kernel_size = {3, 3}, |
|---|
| | | int64_t video_kernel_size = 3, |
|---|
| | | int dims = 2) // always 2 |
|---|
| | | : ResBlock(channels, emb_channels, out_channels, kernel_size, dims) { |
|---|
| | | blocks["time_stack"] = std::shared_ptr<GGMLBlock>(new ResBlock(out_channels, emb_channels, out_channels, kernel_size, 3, true)); |
|---|
| | | blocks["time_mixer"] = std::shared_ptr<GGMLBlock>(new AlphaBlender()); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, |
|---|
| | | struct ggml_tensor* x, |
|---|
| | | struct ggml_tensor* emb, |
|---|
| | | int num_video_frames) { |
|---|
| | | // x: [N, channels, h, w] aka [b*t, channels, h, w] |
|---|
| | | // emb: [N, emb_channels] aka [b*t, emb_channels] |
|---|
| | | // image_only_indicator is always tensor([0.]) |
|---|
| | | auto time_stack = std::dynamic_pointer_cast<ResBlock>(blocks["time_stack"]); |
|---|
| | | auto time_mixer = std::dynamic_pointer_cast<AlphaBlender>(blocks["time_mixer"]); |
|---|
| | | |
|---|
| | | x = ResBlock::forward(ctx, x, emb); |
|---|
| | | |
|---|
| | | int64_t T = num_video_frames; |
|---|
| | | int64_t B = x->ne[3] / T; |
|---|
| | | int64_t C = x->ne[2]; |
|---|
| | | int64_t H = x->ne[1]; |
|---|
| | | int64_t W = x->ne[0]; |
|---|
| | | |
|---|
| | | x = ggml_reshape_4d(ctx, x, W * H, C, T, B); // (b t) c h w -> b t c (h w) |
|---|
| | | x = ggml_cont(ctx, ggml_permute(ctx, x, 0, 2, 1, 3)); // b t c (h w) -> b c t (h w) |
|---|
| | | auto x_mix = x; |
|---|
| | | |
|---|
| | | emb = ggml_reshape_4d(ctx, emb, emb->ne[0], T, B, emb->ne[3]); // (b t) ... -> b t ... |
|---|
| | | |
|---|
| | | x = time_stack->forward(ctx, x, emb); // b t c (h w) |
|---|
| | | |
|---|
| | | x = time_mixer->forward(ctx, x_mix, x); // b t c (h w) |
|---|
| | | |
|---|
| | | x = ggml_cont(ctx, ggml_permute(ctx, x, 0, 2, 1, 3)); // b c t (h w) -> b t c (h w) |
|---|
| | | x = ggml_reshape_4d(ctx, x, W, H, C, T * B); // b t c (h w) -> (b t) c h w |
|---|
| | | |
|---|
| | | return x; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | #endif // __COMMON_HPP__ |
|---|
| New file |
| | |
|---|
| | | #ifndef __CONTROL_HPP__ |
|---|
| | | #define __CONTROL_HPP__ |
|---|
| | | |
|---|
| | | #include "common.hpp" |
|---|
| | | #include "ggml_extend.hpp" |
|---|
| | | #include "model.h" |
|---|
| | | |
|---|
| | | #define CONTROL_NET_GRAPH_SIZE 1536 |
|---|
| | | |
|---|
| | | /* |
|---|
| | | =================================== ControlNet =================================== |
|---|
| | | Reference: https://github.com/comfyanonymous/ComfyUI/blob/master/comfy/cldm/cldm.py |
|---|
| | | |
|---|
| | | */ |
|---|
| | | class ControlNetBlock : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | SDVersion version = VERSION_1_x; |
|---|
| | | // network hparams |
|---|
| | | int in_channels = 4; |
|---|
| | | int out_channels = 4; |
|---|
| | | int hint_channels = 3; |
|---|
| | | int num_res_blocks = 2; |
|---|
| | | std::vector<int> attention_resolutions = {4, 2, 1}; |
|---|
| | | std::vector<int> channel_mult = {1, 2, 4, 4}; |
|---|
| | | std::vector<int> transformer_depth = {1, 1, 1, 1}; |
|---|
| | | int time_embed_dim = 1280; // model_channels*4 |
|---|
| | | int num_heads = 8; |
|---|
| | | int num_head_channels = -1; // channels // num_heads |
|---|
| | | int context_dim = 768; // 1024 for VERSION_2_x, 2048 for VERSION_XL |
|---|
| | | |
|---|
| | | public: |
|---|
| | | int model_channels = 320; |
|---|
| | | int adm_in_channels = 2816; // only for VERSION_XL |
|---|
| | | |
|---|
| | | ControlNetBlock(SDVersion version = VERSION_1_x) |
|---|
| | | : version(version) { |
|---|
| | | if (version == VERSION_2_x) { |
|---|
| | | context_dim = 1024; |
|---|
| | | num_head_channels = 64; |
|---|
| | | num_heads = -1; |
|---|
| | | } else if (version == VERSION_XL) { |
|---|
| | | context_dim = 2048; |
|---|
| | | attention_resolutions = {4, 2}; |
|---|
| | | channel_mult = {1, 2, 4}; |
|---|
| | | transformer_depth = {1, 2, 10}; |
|---|
| | | num_head_channels = 64; |
|---|
| | | num_heads = -1; |
|---|
| | | } else if (version == VERSION_SVD) { |
|---|
| | | in_channels = 8; |
|---|
| | | out_channels = 4; |
|---|
| | | context_dim = 1024; |
|---|
| | | adm_in_channels = 768; |
|---|
| | | num_head_channels = 64; |
|---|
| | | num_heads = -1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | blocks["time_embed.0"] = std::shared_ptr<GGMLBlock>(new Linear(model_channels, time_embed_dim)); |
|---|
| | | // time_embed_1 is nn.SiLU() |
|---|
| | | blocks["time_embed.2"] = std::shared_ptr<GGMLBlock>(new Linear(time_embed_dim, time_embed_dim)); |
|---|
| | | |
|---|
| | | if (version == VERSION_XL || version == VERSION_SVD) { |
|---|
| | | blocks["label_emb.0.0"] = std::shared_ptr<GGMLBlock>(new Linear(adm_in_channels, time_embed_dim)); |
|---|
| | | // label_emb_1 is nn.SiLU() |
|---|
| | | blocks["label_emb.0.2"] = std::shared_ptr<GGMLBlock>(new Linear(time_embed_dim, time_embed_dim)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // input_blocks |
|---|
| | | blocks["input_blocks.0.0"] = std::shared_ptr<GGMLBlock>(new Conv2d(in_channels, model_channels, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | |
|---|
| | | std::vector<int> input_block_chans; |
|---|
| | | input_block_chans.push_back(model_channels); |
|---|
| | | int ch = model_channels; |
|---|
| | | int input_block_idx = 0; |
|---|
| | | int ds = 1; |
|---|
| | | |
|---|
| | | auto get_resblock = [&](int64_t channels, int64_t emb_channels, int64_t out_channels) -> ResBlock* { |
|---|
| | | return new ResBlock(channels, emb_channels, out_channels); |
|---|
| | | }; |
|---|
| | | |
|---|
| | | auto get_attention_layer = [&](int64_t in_channels, |
|---|
| | | int64_t n_head, |
|---|
| | | int64_t d_head, |
|---|
| | | int64_t depth, |
|---|
| | | int64_t context_dim) -> SpatialTransformer* { |
|---|
| | | return new SpatialTransformer(in_channels, n_head, d_head, depth, context_dim); |
|---|
| | | }; |
|---|
| | | |
|---|
| | | auto make_zero_conv = [&](int64_t channels) { |
|---|
| | | return new Conv2d(channels, channels, {1, 1}); |
|---|
| | | }; |
|---|
| | | |
|---|
| | | blocks["zero_convs.0.0"] = std::shared_ptr<GGMLBlock>(make_zero_conv(model_channels)); |
|---|
| | | |
|---|
| | | blocks["input_hint_block.0"] = std::shared_ptr<GGMLBlock>(new Conv2d(hint_channels, 16, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | // nn.SiLU() |
|---|
| | | blocks["input_hint_block.2"] = std::shared_ptr<GGMLBlock>(new Conv2d(16, 16, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | // nn.SiLU() |
|---|
| | | blocks["input_hint_block.4"] = std::shared_ptr<GGMLBlock>(new Conv2d(16, 32, {3, 3}, {2, 2}, {1, 1})); |
|---|
| | | // nn.SiLU() |
|---|
| | | blocks["input_hint_block.6"] = std::shared_ptr<GGMLBlock>(new Conv2d(32, 32, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | // nn.SiLU() |
|---|
| | | blocks["input_hint_block.8"] = std::shared_ptr<GGMLBlock>(new Conv2d(32, 96, {3, 3}, {2, 2}, {1, 1})); |
|---|
| | | // nn.SiLU() |
|---|
| | | blocks["input_hint_block.10"] = std::shared_ptr<GGMLBlock>(new Conv2d(96, 96, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | // nn.SiLU() |
|---|
| | | blocks["input_hint_block.12"] = std::shared_ptr<GGMLBlock>(new Conv2d(96, 256, {3, 3}, {2, 2}, {1, 1})); |
|---|
| | | // nn.SiLU() |
|---|
| | | blocks["input_hint_block.14"] = std::shared_ptr<GGMLBlock>(new Conv2d(256, model_channels, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | |
|---|
| | | size_t len_mults = channel_mult.size(); |
|---|
| | | for (int i = 0; i < len_mults; i++) { |
|---|
| | | int mult = channel_mult[i]; |
|---|
| | | for (int j = 0; j < num_res_blocks; j++) { |
|---|
| | | input_block_idx += 1; |
|---|
| | | std::string name = "input_blocks." + std::to_string(input_block_idx) + ".0"; |
|---|
| | | blocks[name] = std::shared_ptr<GGMLBlock>(get_resblock(ch, time_embed_dim, mult * model_channels)); |
|---|
| | | |
|---|
| | | ch = mult * model_channels; |
|---|
| | | if (std::find(attention_resolutions.begin(), attention_resolutions.end(), ds) != attention_resolutions.end()) { |
|---|
| | | int n_head = num_heads; |
|---|
| | | int d_head = ch / num_heads; |
|---|
| | | if (num_head_channels != -1) { |
|---|
| | | d_head = num_head_channels; |
|---|
| | | n_head = ch / d_head; |
|---|
| | | } |
|---|
| | | std::string name = "input_blocks." + std::to_string(input_block_idx) + ".1"; |
|---|
| | | blocks[name] = std::shared_ptr<GGMLBlock>(get_attention_layer(ch, |
|---|
| | | n_head, |
|---|
| | | d_head, |
|---|
| | | transformer_depth[i], |
|---|
| | | context_dim)); |
|---|
| | | } |
|---|
| | | blocks["zero_convs." + std::to_string(input_block_idx) + ".0"] = std::shared_ptr<GGMLBlock>(make_zero_conv(ch)); |
|---|
| | | input_block_chans.push_back(ch); |
|---|
| | | } |
|---|
| | | if (i != len_mults - 1) { |
|---|
| | | input_block_idx += 1; |
|---|
| | | std::string name = "input_blocks." + std::to_string(input_block_idx) + ".0"; |
|---|
| | | blocks[name] = std::shared_ptr<GGMLBlock>(new DownSampleBlock(ch, ch)); |
|---|
| | | |
|---|
| | | blocks["zero_convs." + std::to_string(input_block_idx) + ".0"] = std::shared_ptr<GGMLBlock>(make_zero_conv(ch)); |
|---|
| | | |
|---|
| | | input_block_chans.push_back(ch); |
|---|
| | | ds *= 2; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // middle blocks |
|---|
| | | int n_head = num_heads; |
|---|
| | | int d_head = ch / num_heads; |
|---|
| | | if (num_head_channels != -1) { |
|---|
| | | d_head = num_head_channels; |
|---|
| | | n_head = ch / d_head; |
|---|
| | | } |
|---|
| | | blocks["middle_block.0"] = std::shared_ptr<GGMLBlock>(get_resblock(ch, time_embed_dim, ch)); |
|---|
| | | blocks["middle_block.1"] = std::shared_ptr<GGMLBlock>(get_attention_layer(ch, |
|---|
| | | n_head, |
|---|
| | | d_head, |
|---|
| | | transformer_depth[transformer_depth.size() - 1], |
|---|
| | | context_dim)); |
|---|
| | | blocks["middle_block.2"] = std::shared_ptr<GGMLBlock>(get_resblock(ch, time_embed_dim, ch)); |
|---|
| | | |
|---|
| | | // middle_block_out |
|---|
| | | blocks["middle_block_out.0"] = std::shared_ptr<GGMLBlock>(make_zero_conv(ch)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* resblock_forward(std::string name, |
|---|
| | | struct ggml_context* ctx, |
|---|
| | | struct ggml_allocr* allocr, |
|---|
| | | struct ggml_tensor* x, |
|---|
| | | struct ggml_tensor* emb) { |
|---|
| | | auto block = std::dynamic_pointer_cast<ResBlock>(blocks[name]); |
|---|
| | | return block->forward(ctx, x, emb); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* attention_layer_forward(std::string name, |
|---|
| | | struct ggml_context* ctx, |
|---|
| | | struct ggml_allocr* allocr, |
|---|
| | | struct ggml_tensor* x, |
|---|
| | | struct ggml_tensor* context) { |
|---|
| | | auto block = std::dynamic_pointer_cast<SpatialTransformer>(blocks[name]); |
|---|
| | | return block->forward(ctx, x, context); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* input_hint_block_forward(struct ggml_context* ctx, |
|---|
| | | struct ggml_tensor* hint, |
|---|
| | | struct ggml_tensor* emb, |
|---|
| | | struct ggml_tensor* context) { |
|---|
| | | int num_input_blocks = 15; |
|---|
| | | auto h = hint; |
|---|
| | | for (int i = 0; i < num_input_blocks; i++) { |
|---|
| | | if (i % 2 == 0) { |
|---|
| | | auto block = std::dynamic_pointer_cast<Conv2d>(blocks["input_hint_block." + std::to_string(i)]); |
|---|
| | | |
|---|
| | | h = block->forward(ctx, h); |
|---|
| | | } else { |
|---|
| | | h = ggml_silu_inplace(ctx, h); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | return h; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::vector<struct ggml_tensor*> forward(struct ggml_context* ctx, |
|---|
| | | struct ggml_allocr* allocr, |
|---|
| | | struct ggml_tensor* x, |
|---|
| | | struct ggml_tensor* hint, |
|---|
| | | struct ggml_tensor* guided_hint, |
|---|
| | | std::vector<float> timesteps, |
|---|
| | | struct ggml_tensor* context, |
|---|
| | | struct ggml_tensor* y = NULL) { |
|---|
| | | // x: [N, in_channels, h, w] or [N, in_channels/2, h, w] |
|---|
| | | // timesteps: [N,] |
|---|
| | | // context: [N, max_position, hidden_size] or [1, max_position, hidden_size]. for example, [N, 77, 768] |
|---|
| | | // y: [N, adm_in_channels] or [1, adm_in_channels] |
|---|
| | | if (context != NULL) { |
|---|
| | | if (context->ne[2] != x->ne[3]) { |
|---|
| | | context = ggml_repeat(ctx, context, ggml_new_tensor_3d(ctx, GGML_TYPE_F32, context->ne[0], context->ne[1], x->ne[3])); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (y != NULL) { |
|---|
| | | if (y->ne[1] != x->ne[3]) { |
|---|
| | | y = ggml_repeat(ctx, y, ggml_new_tensor_2d(ctx, GGML_TYPE_F32, y->ne[0], x->ne[3])); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto time_embed_0 = std::dynamic_pointer_cast<Linear>(blocks["time_embed.0"]); |
|---|
| | | auto time_embed_2 = std::dynamic_pointer_cast<Linear>(blocks["time_embed.2"]); |
|---|
| | | auto input_blocks_0_0 = std::dynamic_pointer_cast<Conv2d>(blocks["input_blocks.0.0"]); |
|---|
| | | auto zero_convs_0 = std::dynamic_pointer_cast<Conv2d>(blocks["zero_convs.0.0"]); |
|---|
| | | |
|---|
| | | auto middle_block_out = std::dynamic_pointer_cast<Conv2d>(blocks["middle_block_out.0"]); |
|---|
| | | |
|---|
| | | auto t_emb = new_timestep_embedding(ctx, allocr, timesteps, model_channels); // [N, model_channels] |
|---|
| | | |
|---|
| | | auto emb = time_embed_0->forward(ctx, t_emb); |
|---|
| | | emb = ggml_silu_inplace(ctx, emb); |
|---|
| | | emb = time_embed_2->forward(ctx, emb); // [N, time_embed_dim] |
|---|
| | | |
|---|
| | | // SDXL/SVD |
|---|
| | | if (y != NULL) { |
|---|
| | | auto label_embed_0 = std::dynamic_pointer_cast<Linear>(blocks["label_emb.0.0"]); |
|---|
| | | auto label_embed_2 = std::dynamic_pointer_cast<Linear>(blocks["label_emb.0.2"]); |
|---|
| | | |
|---|
| | | auto label_emb = label_embed_0->forward(ctx, y); |
|---|
| | | label_emb = ggml_silu_inplace(ctx, label_emb); |
|---|
| | | label_emb = label_embed_2->forward(ctx, label_emb); // [N, time_embed_dim] |
|---|
| | | |
|---|
| | | emb = ggml_add(ctx, emb, label_emb); // [N, time_embed_dim] |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::vector<struct ggml_tensor*> outs; |
|---|
| | | |
|---|
| | | if (guided_hint == NULL) { |
|---|
| | | guided_hint = input_hint_block_forward(ctx, hint, emb, context); |
|---|
| | | } |
|---|
| | | outs.push_back(guided_hint); |
|---|
| | | |
|---|
| | | // input_blocks |
|---|
| | | |
|---|
| | | // input block 0 |
|---|
| | | auto h = input_blocks_0_0->forward(ctx, x); |
|---|
| | | h = ggml_add(ctx, h, guided_hint); |
|---|
| | | outs.push_back(zero_convs_0->forward(ctx, h)); |
|---|
| | | |
|---|
| | | // input block 1-11 |
|---|
| | | size_t len_mults = channel_mult.size(); |
|---|
| | | int input_block_idx = 0; |
|---|
| | | int ds = 1; |
|---|
| | | for (int i = 0; i < len_mults; i++) { |
|---|
| | | int mult = channel_mult[i]; |
|---|
| | | for (int j = 0; j < num_res_blocks; j++) { |
|---|
| | | input_block_idx += 1; |
|---|
| | | std::string name = "input_blocks." + std::to_string(input_block_idx) + ".0"; |
|---|
| | | h = resblock_forward(name, ctx, allocr, h, emb); // [N, mult*model_channels, h, w] |
|---|
| | | if (std::find(attention_resolutions.begin(), attention_resolutions.end(), ds) != attention_resolutions.end()) { |
|---|
| | | std::string name = "input_blocks." + std::to_string(input_block_idx) + ".1"; |
|---|
| | | h = attention_layer_forward(name, ctx, allocr, h, context); // [N, mult*model_channels, h, w] |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto zero_conv = std::dynamic_pointer_cast<Conv2d>(blocks["zero_convs." + std::to_string(input_block_idx) + ".0"]); |
|---|
| | | |
|---|
| | | outs.push_back(zero_conv->forward(ctx, h)); |
|---|
| | | } |
|---|
| | | if (i != len_mults - 1) { |
|---|
| | | ds *= 2; |
|---|
| | | input_block_idx += 1; |
|---|
| | | |
|---|
| | | std::string name = "input_blocks." + std::to_string(input_block_idx) + ".0"; |
|---|
| | | auto block = std::dynamic_pointer_cast<DownSampleBlock>(blocks[name]); |
|---|
| | | |
|---|
| | | h = block->forward(ctx, h); // [N, mult*model_channels, h/(2^(i+1)), w/(2^(i+1))] |
|---|
| | | |
|---|
| | | auto zero_conv = std::dynamic_pointer_cast<Conv2d>(blocks["zero_convs." + std::to_string(input_block_idx) + ".0"]); |
|---|
| | | |
|---|
| | | outs.push_back(zero_conv->forward(ctx, h)); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | // [N, 4*model_channels, h/8, w/8] |
|---|
| | | |
|---|
| | | // middle_block |
|---|
| | | h = resblock_forward("middle_block.0", ctx, allocr, h, emb); // [N, 4*model_channels, h/8, w/8] |
|---|
| | | h = attention_layer_forward("middle_block.1", ctx, allocr, h, context); // [N, 4*model_channels, h/8, w/8] |
|---|
| | | h = resblock_forward("middle_block.2", ctx, allocr, h, emb); // [N, 4*model_channels, h/8, w/8] |
|---|
| | | |
|---|
| | | // out |
|---|
| | | outs.push_back(middle_block_out->forward(ctx, h)); |
|---|
| | | return outs; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ControlNet : public GGMLModule { |
|---|
| | | SDVersion version = VERSION_1_x; |
|---|
| | | ControlNetBlock control_net; |
|---|
| | | |
|---|
| | | ggml_backend_buffer_t control_buffer = NULL; // keep control output tensors in backend memory |
|---|
| | | ggml_context* control_ctx = NULL; |
|---|
| | | std::vector<struct ggml_tensor*> controls; // (12 input block outputs, 1 middle block output) SD 1.5 |
|---|
| | | struct ggml_tensor* guided_hint = NULL; // guided_hint cache, for faster inference |
|---|
| | | bool guided_hint_cached = false; |
|---|
| | | |
|---|
| | | ControlNet(ggml_backend_t backend, |
|---|
| | | ggml_type wtype, |
|---|
| | | SDVersion version = VERSION_1_x) |
|---|
| | | : GGMLModule(backend, wtype), control_net(version) { |
|---|
| | | control_net.init(params_ctx, wtype); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ~ControlNet() { |
|---|
| | | free_control_ctx(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | void alloc_control_ctx(std::vector<struct ggml_tensor*> outs) { |
|---|
| | | struct ggml_init_params params; |
|---|
| | | params.mem_size = static_cast<size_t>(outs.size() * ggml_tensor_overhead()) + 1024 * 1024; |
|---|
| | | params.mem_buffer = NULL; |
|---|
| | | params.no_alloc = true; |
|---|
| | | control_ctx = ggml_init(params); |
|---|
| | | |
|---|
| | | controls.resize(outs.size() - 1); |
|---|
| | | |
|---|
| | | size_t control_buffer_size = 0; |
|---|
| | | |
|---|
| | | guided_hint = ggml_dup_tensor(control_ctx, outs[0]); |
|---|
| | | control_buffer_size += ggml_nbytes(guided_hint); |
|---|
| | | |
|---|
| | | for (int i = 0; i < outs.size() - 1; i++) { |
|---|
| | | controls[i] = ggml_dup_tensor(control_ctx, outs[i + 1]); |
|---|
| | | control_buffer_size += ggml_nbytes(controls[i]); |
|---|
| | | } |
|---|
| | | |
|---|
| | | control_buffer = ggml_backend_alloc_ctx_tensors(control_ctx, backend); |
|---|
| | | |
|---|
| | | LOG_DEBUG("control buffer size %.2fMB", control_buffer_size * 1.f / 1024.f / 1024.f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | void free_control_ctx() { |
|---|
| | | if (control_buffer != NULL) { |
|---|
| | | ggml_backend_buffer_free(control_buffer); |
|---|
| | | control_buffer = NULL; |
|---|
| | | } |
|---|
| | | if (control_ctx != NULL) { |
|---|
| | | ggml_free(control_ctx); |
|---|
| | | control_ctx = NULL; |
|---|
| | | } |
|---|
| | | guided_hint = NULL; |
|---|
| | | guided_hint_cached = false; |
|---|
| | | controls.clear(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string get_desc() { |
|---|
| | | return "control_net"; |
|---|
| | | } |
|---|
| | | |
|---|
| | | size_t get_params_mem_size() { |
|---|
| | | return control_net.get_params_mem_size(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | size_t get_params_num() { |
|---|
| | | return control_net.get_params_num(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | void get_param_tensors(std::map<std::string, struct ggml_tensor*>& tensors, const std::string prefix) { |
|---|
| | | control_net.get_param_tensors(tensors, prefix); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_cgraph* build_graph(struct ggml_tensor* x, |
|---|
| | | struct ggml_tensor* hint, |
|---|
| | | std::vector<float> timesteps, |
|---|
| | | struct ggml_tensor* context, |
|---|
| | | struct ggml_tensor* y = NULL) { |
|---|
| | | struct ggml_cgraph* gf = ggml_new_graph_custom(compute_ctx, CONTROL_NET_GRAPH_SIZE, false); |
|---|
| | | |
|---|
| | | x = to_backend(x); |
|---|
| | | hint = to_backend(hint); |
|---|
| | | context = to_backend(context); |
|---|
| | | y = to_backend(y); |
|---|
| | | |
|---|
| | | auto outs = control_net.forward(compute_ctx, |
|---|
| | | compute_allocr, |
|---|
| | | x, |
|---|
| | | hint, |
|---|
| | | guided_hint_cached ? guided_hint : NULL, |
|---|
| | | timesteps, |
|---|
| | | context, |
|---|
| | | y); |
|---|
| | | |
|---|
| | | if (control_ctx == NULL) { |
|---|
| | | alloc_control_ctx(outs); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(compute_ctx, outs[0], guided_hint)); |
|---|
| | | for (int i = 0; i < outs.size() - 1; i++) { |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(compute_ctx, outs[i + 1], controls[i])); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return gf; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void compute(int n_threads, |
|---|
| | | struct ggml_tensor* x, |
|---|
| | | struct ggml_tensor* hint, |
|---|
| | | std::vector<float> timesteps, |
|---|
| | | struct ggml_tensor* context, |
|---|
| | | struct ggml_tensor* y, |
|---|
| | | struct ggml_tensor** output = NULL, |
|---|
| | | struct ggml_context* output_ctx = NULL) { |
|---|
| | | // x: [N, in_channels, h, w] |
|---|
| | | // timesteps: [N, ] |
|---|
| | | // context: [N, max_position, hidden_size]([N, 77, 768]) or [1, max_position, hidden_size] |
|---|
| | | // y: [N, adm_in_channels] or [1, adm_in_channels] |
|---|
| | | auto get_graph = [&]() -> struct ggml_cgraph* { |
|---|
| | | return build_graph(x, hint, timesteps, context, y); |
|---|
| | | }; |
|---|
| | | |
|---|
| | | GGMLModule::compute(get_graph, n_threads, false, output, output_ctx); |
|---|
| | | |
|---|
| | | guided_hint_cached = true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool load_from_file(const std::string& file_path) { |
|---|
| | | LOG_INFO("loading control net from '%s'", file_path.c_str()); |
|---|
| | | alloc_params_buffer(); |
|---|
| | | std::map<std::string, ggml_tensor*> tensors; |
|---|
| | | control_net.get_param_tensors(tensors); |
|---|
| | | std::set<std::string> ignore_tensors; |
|---|
| | | |
|---|
| | | ModelLoader model_loader; |
|---|
| | | if (!model_loader.init_from_file(file_path)) { |
|---|
| | | LOG_ERROR("init control net model loader from file failed: '%s'", file_path.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool success = model_loader.load_tensors(tensors, backend, ignore_tensors); |
|---|
| | | |
|---|
| | | if (!success) { |
|---|
| | | LOG_ERROR("load control net tensors from model loader failed"); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | LOG_INFO("control net model loaded"); |
|---|
| | | return success; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | #endif // __CONTROL_HPP__ |
|---|
| New file |
| | |
|---|
| | | #ifndef __DENOISER_HPP__ |
|---|
| | | #define __DENOISER_HPP__ |
|---|
| | | |
|---|
| | | #include "ggml_extend.hpp" |
|---|
| | | |
|---|
| | | /*================================================= CompVisDenoiser ==================================================*/ |
|---|
| | | |
|---|
| | | // Ref: https://github.com/crowsonkb/k-diffusion/blob/master/k_diffusion/external.py |
|---|
| | | |
|---|
| | | #define TIMESTEPS 1000 |
|---|
| | | |
|---|
| | | struct SigmaSchedule { |
|---|
| | | float alphas_cumprod[TIMESTEPS]; |
|---|
| | | float sigmas[TIMESTEPS]; |
|---|
| | | float log_sigmas[TIMESTEPS]; |
|---|
| | | |
|---|
| | | virtual std::vector<float> get_sigmas(uint32_t n) = 0; |
|---|
| | | |
|---|
| | | float sigma_to_t(float sigma) { |
|---|
| | | float log_sigma = std::log(sigma); |
|---|
| | | std::vector<float> dists; |
|---|
| | | dists.reserve(TIMESTEPS); |
|---|
| | | for (float log_sigma_val : log_sigmas) { |
|---|
| | | dists.push_back(log_sigma - log_sigma_val); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int low_idx = 0; |
|---|
| | | for (size_t i = 0; i < TIMESTEPS; i++) { |
|---|
| | | if (dists[i] >= 0) { |
|---|
| | | low_idx++; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | low_idx = std::min(std::max(low_idx - 1, 0), TIMESTEPS - 2); |
|---|
| | | int high_idx = low_idx + 1; |
|---|
| | | |
|---|
| | | float low = log_sigmas[low_idx]; |
|---|
| | | float high = log_sigmas[high_idx]; |
|---|
| | | float w = (low - log_sigma) / (low - high); |
|---|
| | | w = std::max(0.f, std::min(1.f, w)); |
|---|
| | | float t = (1.0f - w) * low_idx + w * high_idx; |
|---|
| | | |
|---|
| | | return t; |
|---|
| | | } |
|---|
| | | |
|---|
| | | float t_to_sigma(float t) { |
|---|
| | | int low_idx = static_cast<int>(std::floor(t)); |
|---|
| | | int high_idx = static_cast<int>(std::ceil(t)); |
|---|
| | | float w = t - static_cast<float>(low_idx); |
|---|
| | | float log_sigma = (1.0f - w) * log_sigmas[low_idx] + w * log_sigmas[high_idx]; |
|---|
| | | return std::exp(log_sigma); |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct DiscreteSchedule : SigmaSchedule { |
|---|
| | | std::vector<float> get_sigmas(uint32_t n) { |
|---|
| | | std::vector<float> result; |
|---|
| | | |
|---|
| | | int t_max = TIMESTEPS - 1; |
|---|
| | | |
|---|
| | | if (n == 0) { |
|---|
| | | return result; |
|---|
| | | } else if (n == 1) { |
|---|
| | | result.push_back(t_to_sigma((float)t_max)); |
|---|
| | | result.push_back(0); |
|---|
| | | return result; |
|---|
| | | } |
|---|
| | | |
|---|
| | | float step = static_cast<float>(t_max) / static_cast<float>(n - 1); |
|---|
| | | for (uint32_t i = 0; i < n; ++i) { |
|---|
| | | float t = t_max - step * i; |
|---|
| | | result.push_back(t_to_sigma(t)); |
|---|
| | | } |
|---|
| | | result.push_back(0); |
|---|
| | | return result; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct KarrasSchedule : SigmaSchedule { |
|---|
| | | std::vector<float> get_sigmas(uint32_t n) { |
|---|
| | | // These *COULD* be function arguments here, |
|---|
| | | // but does anybody ever bother to touch them? |
|---|
| | | float sigma_min = 0.1f; |
|---|
| | | float sigma_max = 10.f; |
|---|
| | | float rho = 7.f; |
|---|
| | | |
|---|
| | | std::vector<float> result(n + 1); |
|---|
| | | |
|---|
| | | float min_inv_rho = pow(sigma_min, (1.f / rho)); |
|---|
| | | float max_inv_rho = pow(sigma_max, (1.f / rho)); |
|---|
| | | for (uint32_t i = 0; i < n; i++) { |
|---|
| | | // Eq. (5) from Karras et al 2022 |
|---|
| | | result[i] = pow(max_inv_rho + (float)i / ((float)n - 1.f) * (min_inv_rho - max_inv_rho), rho); |
|---|
| | | } |
|---|
| | | result[n] = 0.; |
|---|
| | | return result; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct Denoiser { |
|---|
| | | std::shared_ptr<SigmaSchedule> schedule = std::make_shared<DiscreteSchedule>(); |
|---|
| | | virtual std::vector<float> get_scalings(float sigma) = 0; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct CompVisDenoiser : public Denoiser { |
|---|
| | | float sigma_data = 1.0f; |
|---|
| | | |
|---|
| | | std::vector<float> get_scalings(float sigma) { |
|---|
| | | float c_out = -sigma; |
|---|
| | | float c_in = 1.0f / std::sqrt(sigma * sigma + sigma_data * sigma_data); |
|---|
| | | return {c_out, c_in}; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct CompVisVDenoiser : public Denoiser { |
|---|
| | | float sigma_data = 1.0f; |
|---|
| | | |
|---|
| | | std::vector<float> get_scalings(float sigma) { |
|---|
| | | float c_skip = sigma_data * sigma_data / (sigma * sigma + sigma_data * sigma_data); |
|---|
| | | float c_out = -sigma * sigma_data / std::sqrt(sigma * sigma + sigma_data * sigma_data); |
|---|
| | | float c_in = 1.0f / std::sqrt(sigma * sigma + sigma_data * sigma_data); |
|---|
| | | return {c_skip, c_out, c_in}; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | #endif // __DENOISER_HPP__ |
|---|
| New file |
| | |
|---|
| | | # Using hipBLAS on Windows |
|---|
| | | |
|---|
| | | To get hipBLAS in `stable-diffusion.cpp` working on Windows, go through this guide section by section. |
|---|
| | | |
|---|
| | | ## Build Tools for Visual Studio 2022 |
|---|
| | | |
|---|
| | | Skip this step if you already have Build Tools installed. |
|---|
| | | |
|---|
| | | To install Build Tools, go to [Visual Studio Downloads](https://visualstudio.microsoft.com/vs/), download `Visual Studio 2022 and other Products` and run the installer. |
|---|
| | | |
|---|
| | | ## CMake |
|---|
| | | |
|---|
| | | Skip this step if you already have CMake installed: running `cmake --version` should output `cmake version x.y.z`. |
|---|
| | | |
|---|
| | | Download latest `Windows x64 Installer` from [Download | CMake](https://cmake.org/download/) and run it. |
|---|
| | | |
|---|
| | | ## ROCm |
|---|
| | | |
|---|
| | | Skip this step if you already have Build Tools installed. |
|---|
| | | |
|---|
| | | The [validation tools](https://rocm.docs.amd.com/en/latest/reference/validation_tools.html) not support on Windows. So you should confirm the Version of `ROCM` by yourself. |
|---|
| | | |
|---|
| | | Fortunately, `AMD` provides complete help documentation, you can use the help documentation to install [ROCM](https://rocm.docs.amd.com/en/latest/deploy/windows/quick_start.html) |
|---|
| | | |
|---|
| | | >**If you encounter an error, if it is [AMD ROCm Windows Installation Error 215](https://github.com/RadeonOpenCompute/ROCm/issues/2363), don't worry about this error. ROCM has been installed correctly, but the vs studio plugin installation failed, we can ignore it.** |
|---|
| | | |
|---|
| | | Then we must set `ROCM` as environment variables before running cmake. |
|---|
| | | |
|---|
| | | Usually if you install according to the official tutorial and do not modify the ROCM path, then there is a high probability that it is here `C:\Program Files\AMD\ROCm\5.5\bin` |
|---|
| | | |
|---|
| | | This is what I use to set the clang: |
|---|
| | | ```Commandline |
|---|
| | | set CC=C:\Program Files\AMD\ROCm\5.5\bin\clang.exe |
|---|
| | | set CXX=C:\Program Files\AMD\ROCm\5.5\bin\clang++.exe |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Ninja |
|---|
| | | |
|---|
| | | Skip this step if you already have Ninja installed: running `ninja --version` should output `1.11.1`. |
|---|
| | | |
|---|
| | | Download latest `ninja-win.zip` from [GitHub Releases Page](https://github.com/ninja-build/ninja/releases/tag/v1.11.1) and unzip. Then set as environment variables. I unzipped it in `C:\Program Files\ninja`, so I set it like this: |
|---|
| | | |
|---|
| | | ```Commandline |
|---|
| | | set ninja=C:\Program Files\ninja\ninja.exe |
|---|
| | | ``` |
|---|
| | | ## Building stable-diffusion.cpp |
|---|
| | | |
|---|
| | | The thing different from the regular CPU build is `-DSD_HIPBLAS=ON` , |
|---|
| | | `-G "Ninja"`, `-DCMAKE_C_COMPILER=clang`, `-DCMAKE_CXX_COMPILER=clang++`, `-DAMDGPU_TARGETS=gfx1100` |
|---|
| | | |
|---|
| | | >**Notice**: check the `clang` and `clang++` information: |
|---|
| | | ```Commandline |
|---|
| | | clang --version |
|---|
| | | clang++ --version |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | If you see like this, we can continue: |
|---|
| | | ``` |
|---|
| | | clang version 17.0.0 (git@github.amd.com:Compute-Mirrors/llvm-project e3201662d21c48894f2156d302276eb1cf47c7be) |
|---|
| | | Target: x86_64-pc-windows-msvc |
|---|
| | | Thread model: posix |
|---|
| | | InstalledDir: C:\Program Files\AMD\ROCm\5.5\bin |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | clang version 17.0.0 (git@github.amd.com:Compute-Mirrors/llvm-project e3201662d21c48894f2156d302276eb1cf47c7be) |
|---|
| | | Target: x86_64-pc-windows-msvc |
|---|
| | | Thread model: posix |
|---|
| | | InstalledDir: C:\Program Files\AMD\ROCm\5.5\bin |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | >**Notice** that the `gfx1100` is the GPU architecture of my GPU, you can change it to your GPU architecture. Click here to see your architecture [LLVM Target](https://rocm.docs.amd.com/en/latest/release/windows_support.html#windows-supported-gpus) |
|---|
| | | |
|---|
| | | My GPU is AMD Radeon™ RX 7900 XTX Graphics, so I set it to `gfx1100`. |
|---|
| | | |
|---|
| | | option: |
|---|
| | | |
|---|
| | | ```commandline |
|---|
| | | mkdir build |
|---|
| | | cd build |
|---|
| | | cmake .. -G "Ninja" -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DSD_HIPBLAS=ON -DCMAKE_BUILD_TYPE=Release -DAMDGPU_TARGETS=gfx1100 |
|---|
| | | cmake --build . --config Release |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | If everything went OK, `build\bin\sd.exe` file should appear. |
|---|
| New file |
| | |
|---|
| | | #ifndef __ESRGAN_HPP__ |
|---|
| | | #define __ESRGAN_HPP__ |
|---|
| | | |
|---|
| | | #include "ggml_extend.hpp" |
|---|
| | | #include "model.h" |
|---|
| | | |
|---|
| | | /* |
|---|
| | | =================================== ESRGAN =================================== |
|---|
| | | References: |
|---|
| | | https://github.com/xinntao/Real-ESRGAN/blob/master/inference_realesrgan.py |
|---|
| | | https://github.com/XPixelGroup/BasicSR/blob/v1.4.2/basicsr/archs/rrdbnet_arch.py |
|---|
| | | |
|---|
| | | */ |
|---|
| | | |
|---|
| | | class ResidualDenseBlock : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int num_feat; |
|---|
| | | int num_grow_ch; |
|---|
| | | |
|---|
| | | public: |
|---|
| | | ResidualDenseBlock(int num_feat = 64, int num_grow_ch = 32) |
|---|
| | | : num_feat(num_feat), num_grow_ch(num_grow_ch) { |
|---|
| | | blocks["conv1"] = std::shared_ptr<GGMLBlock>(new Conv2d(num_feat, num_grow_ch, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | blocks["conv2"] = std::shared_ptr<GGMLBlock>(new Conv2d(num_feat + num_grow_ch, num_grow_ch, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | blocks["conv3"] = std::shared_ptr<GGMLBlock>(new Conv2d(num_feat + 2 * num_grow_ch, num_grow_ch, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | blocks["conv4"] = std::shared_ptr<GGMLBlock>(new Conv2d(num_feat + 3 * num_grow_ch, num_grow_ch, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | blocks["conv5"] = std::shared_ptr<GGMLBlock>(new Conv2d(num_feat + 4 * num_grow_ch, num_feat, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* lrelu(struct ggml_context* ctx, struct ggml_tensor* x) { |
|---|
| | | return ggml_leaky_relu(ctx, x, 0.2f, true); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x) { |
|---|
| | | // x: [n, num_feat, h, w] |
|---|
| | | // return: [n, num_feat, h, w] |
|---|
| | | |
|---|
| | | auto conv1 = std::dynamic_pointer_cast<Conv2d>(blocks["conv1"]); |
|---|
| | | auto conv2 = std::dynamic_pointer_cast<Conv2d>(blocks["conv2"]); |
|---|
| | | auto conv3 = std::dynamic_pointer_cast<Conv2d>(blocks["conv3"]); |
|---|
| | | auto conv4 = std::dynamic_pointer_cast<Conv2d>(blocks["conv4"]); |
|---|
| | | auto conv5 = std::dynamic_pointer_cast<Conv2d>(blocks["conv5"]); |
|---|
| | | |
|---|
| | | auto x1 = lrelu(ctx, conv1->forward(ctx, x)); |
|---|
| | | auto x_cat = ggml_concat(ctx, x, x1); |
|---|
| | | auto x2 = lrelu(ctx, conv2->forward(ctx, x_cat)); |
|---|
| | | x_cat = ggml_concat(ctx, x_cat, x2); |
|---|
| | | auto x3 = lrelu(ctx, conv3->forward(ctx, x_cat)); |
|---|
| | | x_cat = ggml_concat(ctx, x_cat, x3); |
|---|
| | | auto x4 = lrelu(ctx, conv4->forward(ctx, x_cat)); |
|---|
| | | x_cat = ggml_concat(ctx, x_cat, x4); |
|---|
| | | auto x5 = conv5->forward(ctx, x_cat); |
|---|
| | | |
|---|
| | | x5 = ggml_add(ctx, ggml_scale(ctx, x5, 0.2f), x); |
|---|
| | | return x5; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class RRDB : public GGMLBlock { |
|---|
| | | public: |
|---|
| | | RRDB(int num_feat, int num_grow_ch = 32) { |
|---|
| | | blocks["rdb1"] = std::shared_ptr<GGMLBlock>(new ResidualDenseBlock(num_feat, num_grow_ch)); |
|---|
| | | blocks["rdb2"] = std::shared_ptr<GGMLBlock>(new ResidualDenseBlock(num_feat, num_grow_ch)); |
|---|
| | | blocks["rdb3"] = std::shared_ptr<GGMLBlock>(new ResidualDenseBlock(num_feat, num_grow_ch)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x) { |
|---|
| | | // x: [n, num_feat, h, w] |
|---|
| | | // return: [n, num_feat, h, w] |
|---|
| | | |
|---|
| | | auto rdb1 = std::dynamic_pointer_cast<ResidualDenseBlock>(blocks["rdb1"]); |
|---|
| | | auto rdb2 = std::dynamic_pointer_cast<ResidualDenseBlock>(blocks["rdb2"]); |
|---|
| | | auto rdb3 = std::dynamic_pointer_cast<ResidualDenseBlock>(blocks["rdb3"]); |
|---|
| | | |
|---|
| | | auto out = rdb1->forward(ctx, x); |
|---|
| | | out = rdb2->forward(ctx, out); |
|---|
| | | out = rdb3->forward(ctx, out); |
|---|
| | | |
|---|
| | | out = ggml_add(ctx, ggml_scale(ctx, out, 0.2f), x); |
|---|
| | | return out; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | class RRDBNet : public GGMLBlock { |
|---|
| | | protected: |
|---|
| | | int scale = 4; // default RealESRGAN_x4plus_anime_6B |
|---|
| | | int num_block = 6; // default RealESRGAN_x4plus_anime_6B |
|---|
| | | int num_in_ch = 3; |
|---|
| | | int num_out_ch = 3; |
|---|
| | | int num_feat = 64; // default RealESRGAN_x4plus_anime_6B |
|---|
| | | int num_grow_ch = 32; // default RealESRGAN_x4plus_anime_6B |
|---|
| | | |
|---|
| | | public: |
|---|
| | | RRDBNet() { |
|---|
| | | blocks["conv_first"] = std::shared_ptr<GGMLBlock>(new Conv2d(num_in_ch, num_feat, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | for (int i = 0; i < num_block; i++) { |
|---|
| | | std::string name = "body." + std::to_string(i); |
|---|
| | | blocks[name] = std::shared_ptr<GGMLBlock>(new RRDB(num_feat, num_grow_ch)); |
|---|
| | | } |
|---|
| | | blocks["conv_body"] = std::shared_ptr<GGMLBlock>(new Conv2d(num_feat, num_feat, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | // upsample |
|---|
| | | blocks["conv_up1"] = std::shared_ptr<GGMLBlock>(new Conv2d(num_feat, num_feat, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | blocks["conv_up2"] = std::shared_ptr<GGMLBlock>(new Conv2d(num_feat, num_feat, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | blocks["conv_hr"] = std::shared_ptr<GGMLBlock>(new Conv2d(num_feat, num_feat, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | blocks["conv_last"] = std::shared_ptr<GGMLBlock>(new Conv2d(num_feat, num_out_ch, {3, 3}, {1, 1}, {1, 1})); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* lrelu(struct ggml_context* ctx, struct ggml_tensor* x) { |
|---|
| | | return ggml_leaky_relu(ctx, x, 0.2f, true); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor* forward(struct ggml_context* ctx, struct ggml_tensor* x) { |
|---|
| | | // x: [n, num_in_ch, h, w] |
|---|
| | | // return: [n, num_out_ch, h*4, w*4] |
|---|
| | | auto conv_first = std::dynamic_pointer_cast<Conv2d>(blocks["conv_first"]); |
|---|
| | | auto conv_body = std::dynamic_pointer_cast<Conv2d>(blocks["conv_body"]); |
|---|
| | | auto conv_up1 = std::dynamic_pointer_cast<Conv2d>(blocks["conv_up1"]); |
|---|
| | | auto conv_up2 = std::dynamic_pointer_cast<Conv2d>(blocks["conv_up2"]); |
|---|
| | | auto conv_hr = std::dynamic_pointer_cast<Conv2d>(blocks["conv_hr"]); |
|---|
| | | auto conv_last = std::dynamic_pointer_cast<Conv2d>(blocks["conv_last"]); |
|---|
| | | |
|---|
| | | auto feat = conv_first->forward(ctx, x); |
|---|
| | | auto body_feat = feat; |
|---|
| | | for (int i = 0; i < num_block; i++) { |
|---|
| | | std::string name = "body." + std::to_string(i); |
|---|
| | | auto block = std::dynamic_pointer_cast<RRDB>(blocks[name]); |
|---|
| | | |
|---|
| | | body_feat = block->forward(ctx, body_feat); |
|---|
| | | } |
|---|
| | | body_feat = conv_body->forward(ctx, body_feat); |
|---|
| | | feat = ggml_add(ctx, feat, body_feat); |
|---|
| | | // upsample |
|---|
| | | feat = lrelu(ctx, conv_up1->forward(ctx, ggml_upscale(ctx, feat, 2))); |
|---|
| | | feat = lrelu(ctx, conv_up2->forward(ctx, ggml_upscale(ctx, feat, 2))); |
|---|
| | | auto out = conv_last->forward(ctx, lrelu(ctx, conv_hr->forward(ctx, feat))); |
|---|
| | | return out; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ESRGAN : public GGMLModule { |
|---|
| | | RRDBNet rrdb_net; |
|---|
| | | int scale = 4; |
|---|
| | | int tile_size = 128; // avoid cuda OOM for 4gb VRAM |
|---|
| | | |
|---|
| | | ESRGAN(ggml_backend_t backend, |
|---|
| | | ggml_type wtype) |
|---|
| | | : GGMLModule(backend, wtype) { |
|---|
| | | rrdb_net.init(params_ctx, wtype); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string get_desc() { |
|---|
| | | return "esrgan"; |
|---|
| | | } |
|---|
| | | |
|---|
| | | size_t get_params_mem_size() { |
|---|
| | | return rrdb_net.get_params_mem_size(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | size_t get_params_num() { |
|---|
| | | return rrdb_net.get_params_num(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool load_from_file(const std::string& file_path) { |
|---|
| | | LOG_INFO("loading esrgan from '%s'", file_path.c_str()); |
|---|
| | | |
|---|
| | | alloc_params_buffer(); |
|---|
| | | std::map<std::string, ggml_tensor*> esrgan_tensors; |
|---|
| | | rrdb_net.get_param_tensors(esrgan_tensors); |
|---|
| | | |
|---|
| | | ModelLoader model_loader; |
|---|
| | | if (!model_loader.init_from_file(file_path)) { |
|---|
| | | LOG_ERROR("init esrgan model loader from file failed: '%s'", file_path.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool success = model_loader.load_tensors(esrgan_tensors, backend); |
|---|
| | | |
|---|
| | | if (!success) { |
|---|
| | | LOG_ERROR("load esrgan tensors from model loader failed"); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | LOG_INFO("esrgan model loaded"); |
|---|
| | | return success; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_cgraph* build_graph(struct ggml_tensor* x) { |
|---|
| | | struct ggml_cgraph* gf = ggml_new_graph(compute_ctx); |
|---|
| | | x = to_backend(x); |
|---|
| | | struct ggml_tensor* out = rrdb_net.forward(compute_ctx, x); |
|---|
| | | ggml_build_forward_expand(gf, out); |
|---|
| | | return gf; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void compute(const int n_threads, |
|---|
| | | struct ggml_tensor* x, |
|---|
| | | ggml_tensor** output, |
|---|
| | | ggml_context* output_ctx = NULL) { |
|---|
| | | auto get_graph = [&]() -> struct ggml_cgraph* { |
|---|
| | | return build_graph(x); |
|---|
| | | }; |
|---|
| | | GGMLModule::compute(get_graph, n_threads, false, output, output_ctx); |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | #endif // __ESRGAN_HPP__ |
|---|
| New file |
| | |
|---|
| | | include_directories(${CMAKE_CURRENT_SOURCE_DIR}) |
|---|
| | | |
|---|
| | | add_subdirectory(cli) |
|---|
| New file |
| | |
|---|
| | | set(TARGET sd) |
|---|
| | | |
|---|
| | | add_executable(${TARGET} main.cpp) |
|---|
| | | install(TARGETS ${TARGET} RUNTIME) |
|---|
| | | target_link_libraries(${TARGET} PRIVATE stable-diffusion ${CMAKE_THREAD_LIBS_INIT}) |
|---|
| | | target_compile_features(${TARGET} PUBLIC cxx_std_11) |
|---|
| New file |
| | |
|---|
| | | #include <stdio.h> |
|---|
| | | #include <string.h> |
|---|
| | | #include <time.h> |
|---|
| | | #include <iostream> |
|---|
| | | #include <random> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | #include "preprocessing.hpp" |
|---|
| | | #include "stable-diffusion.h" |
|---|
| | | |
|---|
| | | #define STB_IMAGE_IMPLEMENTATION |
|---|
| | | #include "stb_image.h" |
|---|
| | | |
|---|
| | | #define STB_IMAGE_WRITE_IMPLEMENTATION |
|---|
| | | #define STB_IMAGE_WRITE_STATIC |
|---|
| | | #include "stb_image_write.h" |
|---|
| | | |
|---|
| | | const char* rng_type_to_str[] = { |
|---|
| | | "std_default", |
|---|
| | | "cuda", |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // Names of the sampler method, same order as enum sample_method in stable-diffusion.h |
|---|
| | | const char* sample_method_str[] = { |
|---|
| | | "euler_a", |
|---|
| | | "euler", |
|---|
| | | "heun", |
|---|
| | | "dpm2", |
|---|
| | | "dpm++2s_a", |
|---|
| | | "dpm++2m", |
|---|
| | | "dpm++2mv2", |
|---|
| | | "lcm", |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // Names of the sigma schedule overrides, same order as sample_schedule in stable-diffusion.h |
|---|
| | | const char* schedule_str[] = { |
|---|
| | | "default", |
|---|
| | | "discrete", |
|---|
| | | "karras", |
|---|
| | | }; |
|---|
| | | |
|---|
| | | const char* modes_str[] = { |
|---|
| | | "txt2img", |
|---|
| | | "img2img", |
|---|
| | | "img2vid", |
|---|
| | | "convert", |
|---|
| | | }; |
|---|
| | | |
|---|
| | | enum SDMode { |
|---|
| | | TXT2IMG, |
|---|
| | | IMG2IMG, |
|---|
| | | IMG2VID, |
|---|
| | | CONVERT, |
|---|
| | | MODE_COUNT |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct SDParams { |
|---|
| | | int n_threads = -1; |
|---|
| | | SDMode mode = TXT2IMG; |
|---|
| | | |
|---|
| | | std::string model_path; |
|---|
| | | std::string vae_path; |
|---|
| | | std::string taesd_path; |
|---|
| | | std::string esrgan_path; |
|---|
| | | std::string controlnet_path; |
|---|
| | | std::string embeddings_path; |
|---|
| | | sd_type_t wtype = SD_TYPE_COUNT; |
|---|
| | | std::string lora_model_dir; |
|---|
| | | std::string output_path = "output.png"; |
|---|
| | | std::string input_path; |
|---|
| | | std::string control_image_path; |
|---|
| | | |
|---|
| | | std::string prompt; |
|---|
| | | std::string negative_prompt; |
|---|
| | | float min_cfg = 1.0f; |
|---|
| | | float cfg_scale = 7.0f; |
|---|
| | | int clip_skip = -1; // <= 0 represents unspecified |
|---|
| | | int width = 512; |
|---|
| | | int height = 512; |
|---|
| | | int batch_count = 1; |
|---|
| | | |
|---|
| | | int video_frames = 6; |
|---|
| | | int motion_bucket_id = 127; |
|---|
| | | int fps = 6; |
|---|
| | | float augmentation_level = 0.f; |
|---|
| | | |
|---|
| | | sample_method_t sample_method = EULER_A; |
|---|
| | | schedule_t schedule = DEFAULT; |
|---|
| | | int sample_steps = 20; |
|---|
| | | float strength = 0.75f; |
|---|
| | | float control_strength = 0.9f; |
|---|
| | | rng_type_t rng_type = CUDA_RNG; |
|---|
| | | int64_t seed = 42; |
|---|
| | | bool verbose = false; |
|---|
| | | bool vae_tiling = false; |
|---|
| | | bool control_net_cpu = false; |
|---|
| | | bool canny_preprocess = false; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | void print_params(SDParams params) { |
|---|
| | | printf("Option: \n"); |
|---|
| | | printf(" n_threads: %d\n", params.n_threads); |
|---|
| | | printf(" mode: %s\n", modes_str[params.mode]); |
|---|
| | | printf(" model_path: %s\n", params.model_path.c_str()); |
|---|
| | | printf(" wtype: %s\n", params.wtype < SD_TYPE_COUNT ? sd_type_name(params.wtype) : "unspecified"); |
|---|
| | | printf(" vae_path: %s\n", params.vae_path.c_str()); |
|---|
| | | printf(" taesd_path: %s\n", params.taesd_path.c_str()); |
|---|
| | | printf(" esrgan_path: %s\n", params.esrgan_path.c_str()); |
|---|
| | | printf(" controlnet_path: %s\n", params.controlnet_path.c_str()); |
|---|
| | | printf(" embeddings_path: %s\n", params.embeddings_path.c_str()); |
|---|
| | | printf(" output_path: %s\n", params.output_path.c_str()); |
|---|
| | | printf(" init_img: %s\n", params.input_path.c_str()); |
|---|
| | | printf(" control_image: %s\n", params.control_image_path.c_str()); |
|---|
| | | printf(" controlnet cpu: %s\n", params.control_net_cpu ? "true" : "false"); |
|---|
| | | printf(" strength(control): %.2f\n", params.control_strength); |
|---|
| | | printf(" prompt: %s\n", params.prompt.c_str()); |
|---|
| | | printf(" negative_prompt: %s\n", params.negative_prompt.c_str()); |
|---|
| | | printf(" min_cfg: %.2f\n", params.min_cfg); |
|---|
| | | printf(" cfg_scale: %.2f\n", params.cfg_scale); |
|---|
| | | printf(" clip_skip: %d\n", params.clip_skip); |
|---|
| | | printf(" width: %d\n", params.width); |
|---|
| | | printf(" height: %d\n", params.height); |
|---|
| | | printf(" sample_method: %s\n", sample_method_str[params.sample_method]); |
|---|
| | | printf(" schedule: %s\n", schedule_str[params.schedule]); |
|---|
| | | printf(" sample_steps: %d\n", params.sample_steps); |
|---|
| | | printf(" strength(img2img): %.2f\n", params.strength); |
|---|
| | | printf(" rng: %s\n", rng_type_to_str[params.rng_type]); |
|---|
| | | printf(" seed: %ld\n", params.seed); |
|---|
| | | printf(" batch_count: %d\n", params.batch_count); |
|---|
| | | printf(" vae_tiling: %s\n", params.vae_tiling ? "true" : "false"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | void print_usage(int argc, const char* argv[]) { |
|---|
| | | printf("usage: %s [arguments]\n", argv[0]); |
|---|
| | | printf("\n"); |
|---|
| | | printf("arguments:\n"); |
|---|
| | | printf(" -h, --help show this help message and exit\n"); |
|---|
| | | printf(" -M, --mode [MODEL] run mode (txt2img or img2img or convert, default: txt2img)\n"); |
|---|
| | | printf(" -t, --threads N number of threads to use during computation (default: -1).\n"); |
|---|
| | | printf(" If threads <= 0, then threads will be set to the number of CPU physical cores\n"); |
|---|
| | | printf(" -m, --model [MODEL] path to model\n"); |
|---|
| | | printf(" --vae [VAE] path to vae\n"); |
|---|
| | | printf(" --taesd [TAESD_PATH] path to taesd. Using Tiny AutoEncoder for fast decoding (low quality)\n"); |
|---|
| | | printf(" --control-net [CONTROL_PATH] path to control net model\n"); |
|---|
| | | printf(" --embd-dir [EMBEDDING_PATH] path to embeddings.\n"); |
|---|
| | | printf(" --upscale-model [ESRGAN_PATH] path to esrgan model. Upscale images after generate, just RealESRGAN_x4plus_anime_6B supported by now.\n"); |
|---|
| | | printf(" --type [TYPE] weight type (f32, f16, q4_0, q4_1, q5_0, q5_1, q8_0)\n"); |
|---|
| | | printf(" If not specified, the default is the type of the weight file.\n"); |
|---|
| | | printf(" --lora-model-dir [DIR] lora model directory\n"); |
|---|
| | | printf(" -i, --init-img [IMAGE] path to the input image, required by img2img\n"); |
|---|
| | | printf(" --control-image [IMAGE] path to image condition, control net\n"); |
|---|
| | | printf(" -o, --output OUTPUT path to write result image to (default: ./output.png)\n"); |
|---|
| | | printf(" -p, --prompt [PROMPT] the prompt to render\n"); |
|---|
| | | printf(" -n, --negative-prompt PROMPT the negative prompt (default: \"\")\n"); |
|---|
| | | printf(" --cfg-scale SCALE unconditional guidance scale: (default: 7.0)\n"); |
|---|
| | | printf(" --strength STRENGTH strength for noising/unnoising (default: 0.75)\n"); |
|---|
| | | printf(" --control-strength STRENGTH strength to apply Control Net (default: 0.9)\n"); |
|---|
| | | printf(" 1.0 corresponds to full destruction of information in init image\n"); |
|---|
| | | printf(" -H, --height H image height, in pixel space (default: 512)\n"); |
|---|
| | | printf(" -W, --width W image width, in pixel space (default: 512)\n"); |
|---|
| | | printf(" --sampling-method {euler, euler_a, heun, dpm2, dpm++2s_a, dpm++2m, dpm++2mv2, lcm}\n"); |
|---|
| | | printf(" sampling method (default: \"euler_a\")\n"); |
|---|
| | | printf(" --steps STEPS number of sample steps (default: 20)\n"); |
|---|
| | | printf(" --rng {std_default, cuda} RNG (default: cuda)\n"); |
|---|
| | | printf(" -s SEED, --seed SEED RNG seed (default: 42, use random seed for < 0)\n"); |
|---|
| | | printf(" -b, --batch-count COUNT number of images to generate.\n"); |
|---|
| | | printf(" --schedule {discrete, karras} Denoiser sigma schedule (default: discrete)\n"); |
|---|
| | | printf(" --clip-skip N ignore last layers of CLIP network; 1 ignores none, 2 ignores one layer (default: -1)\n"); |
|---|
| | | printf(" <= 0 represents unspecified, will be 1 for SD1.x, 2 for SD2.x\n"); |
|---|
| | | printf(" --vae-tiling process vae in tiles to reduce memory usage\n"); |
|---|
| | | printf(" --control-net-cpu keep controlnet in cpu (for low vram)\n"); |
|---|
| | | printf(" --canny apply canny preprocessor (edge detection)\n"); |
|---|
| | | printf(" -v, --verbose print extra info\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | void parse_args(int argc, const char** argv, SDParams& params) { |
|---|
| | | bool invalid_arg = false; |
|---|
| | | std::string arg; |
|---|
| | | for (int i = 1; i < argc; i++) { |
|---|
| | | arg = argv[i]; |
|---|
| | | |
|---|
| | | if (arg == "-t" || arg == "--threads") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.n_threads = std::stoi(argv[i]); |
|---|
| | | } else if (arg == "-M" || arg == "--mode") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | const char* mode_selected = argv[i]; |
|---|
| | | int mode_found = -1; |
|---|
| | | for (int d = 0; d < MODE_COUNT; d++) { |
|---|
| | | if (!strcmp(mode_selected, modes_str[d])) { |
|---|
| | | mode_found = d; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | if (mode_found == -1) { |
|---|
| | | fprintf(stderr, |
|---|
| | | "error: invalid mode %s, must be one of [txt2img, img2img, img2vid, convert]\n", |
|---|
| | | mode_selected); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | params.mode = (SDMode)mode_found; |
|---|
| | | } else if (arg == "-m" || arg == "--model") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.model_path = argv[i]; |
|---|
| | | } else if (arg == "--vae") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.vae_path = argv[i]; |
|---|
| | | } else if (arg == "--taesd") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.taesd_path = argv[i]; |
|---|
| | | } else if (arg == "--control-net") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.controlnet_path = argv[i]; |
|---|
| | | } else if (arg == "--upscale-model") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.esrgan_path = argv[i]; |
|---|
| | | } else if (arg == "--embd-dir") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.embeddings_path = argv[i]; |
|---|
| | | } else if (arg == "--type") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | std::string type = argv[i]; |
|---|
| | | if (type == "f32") { |
|---|
| | | params.wtype = SD_TYPE_F32; |
|---|
| | | } else if (type == "f16") { |
|---|
| | | params.wtype = SD_TYPE_F16; |
|---|
| | | } else if (type == "q4_0") { |
|---|
| | | params.wtype = SD_TYPE_Q4_0; |
|---|
| | | } else if (type == "q4_1") { |
|---|
| | | params.wtype = SD_TYPE_Q4_1; |
|---|
| | | } else if (type == "q5_0") { |
|---|
| | | params.wtype = SD_TYPE_Q5_0; |
|---|
| | | } else if (type == "q5_1") { |
|---|
| | | params.wtype = SD_TYPE_Q5_1; |
|---|
| | | } else if (type == "q8_0") { |
|---|
| | | params.wtype = SD_TYPE_Q8_0; |
|---|
| | | } else { |
|---|
| | | fprintf(stderr, "error: invalid weight format %s, must be one of [f32, f16, q4_0, q4_1, q5_0, q5_1, q8_0]\n", |
|---|
| | | type.c_str()); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | } else if (arg == "--lora-model-dir") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.lora_model_dir = argv[i]; |
|---|
| | | } else if (arg == "-i" || arg == "--init-img") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.input_path = argv[i]; |
|---|
| | | } else if (arg == "--control-image") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.control_image_path = argv[i]; |
|---|
| | | } else if (arg == "-o" || arg == "--output") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.output_path = argv[i]; |
|---|
| | | } else if (arg == "-p" || arg == "--prompt") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.prompt = argv[i]; |
|---|
| | | } else if (arg == "-n" || arg == "--negative-prompt") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.negative_prompt = argv[i]; |
|---|
| | | } else if (arg == "--cfg-scale") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.cfg_scale = std::stof(argv[i]); |
|---|
| | | } else if (arg == "--strength") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.strength = std::stof(argv[i]); |
|---|
| | | } else if (arg == "--control-strength") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.control_strength = std::stof(argv[i]); |
|---|
| | | } else if (arg == "-H" || arg == "--height") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.height = std::stoi(argv[i]); |
|---|
| | | } else if (arg == "-W" || arg == "--width") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.width = std::stoi(argv[i]); |
|---|
| | | } else if (arg == "--steps") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.sample_steps = std::stoi(argv[i]); |
|---|
| | | } else if (arg == "--clip-skip") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.clip_skip = std::stoi(argv[i]); |
|---|
| | | } else if (arg == "--vae-tiling") { |
|---|
| | | params.vae_tiling = true; |
|---|
| | | } else if (arg == "--control-net-cpu") { |
|---|
| | | params.control_net_cpu = true; |
|---|
| | | } else if (arg == "--canny") { |
|---|
| | | params.canny_preprocess = true; |
|---|
| | | } else if (arg == "-b" || arg == "--batch-count") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.batch_count = std::stoi(argv[i]); |
|---|
| | | } else if (arg == "--rng") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | std::string rng_type_str = argv[i]; |
|---|
| | | if (rng_type_str == "std_default") { |
|---|
| | | params.rng_type = STD_DEFAULT_RNG; |
|---|
| | | } else if (rng_type_str == "cuda") { |
|---|
| | | params.rng_type = CUDA_RNG; |
|---|
| | | } else { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } else if (arg == "--schedule") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | const char* schedule_selected = argv[i]; |
|---|
| | | int schedule_found = -1; |
|---|
| | | for (int d = 0; d < N_SCHEDULES; d++) { |
|---|
| | | if (!strcmp(schedule_selected, schedule_str[d])) { |
|---|
| | | schedule_found = d; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | if (schedule_found == -1) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.schedule = (schedule_t)schedule_found; |
|---|
| | | } else if (arg == "-s" || arg == "--seed") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.seed = std::stoll(argv[i]); |
|---|
| | | } else if (arg == "--sampling-method") { |
|---|
| | | if (++i >= argc) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | const char* sample_method_selected = argv[i]; |
|---|
| | | int sample_method_found = -1; |
|---|
| | | for (int m = 0; m < N_SAMPLE_METHODS; m++) { |
|---|
| | | if (!strcmp(sample_method_selected, sample_method_str[m])) { |
|---|
| | | sample_method_found = m; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | if (sample_method_found == -1) { |
|---|
| | | invalid_arg = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.sample_method = (sample_method_t)sample_method_found; |
|---|
| | | } else if (arg == "-h" || arg == "--help") { |
|---|
| | | print_usage(argc, argv); |
|---|
| | | exit(0); |
|---|
| | | } else if (arg == "-v" || arg == "--verbose") { |
|---|
| | | params.verbose = true; |
|---|
| | | } else { |
|---|
| | | fprintf(stderr, "error: unknown argument: %s\n", arg.c_str()); |
|---|
| | | print_usage(argc, argv); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | if (invalid_arg) { |
|---|
| | | fprintf(stderr, "error: invalid parameter for argument: %s\n", arg.c_str()); |
|---|
| | | print_usage(argc, argv); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | if (params.n_threads <= 0) { |
|---|
| | | params.n_threads = get_num_physical_cores(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.mode != CONVERT && params.mode != IMG2VID && params.prompt.length() == 0) { |
|---|
| | | fprintf(stderr, "error: the following arguments are required: prompt\n"); |
|---|
| | | print_usage(argc, argv); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.model_path.length() == 0) { |
|---|
| | | fprintf(stderr, "error: the following arguments are required: model_path\n"); |
|---|
| | | print_usage(argc, argv); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if ((params.mode == IMG2IMG || params.mode == IMG2VID) && params.input_path.length() == 0) { |
|---|
| | | fprintf(stderr, "error: when using the img2img mode, the following arguments are required: init-img\n"); |
|---|
| | | print_usage(argc, argv); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.output_path.length() == 0) { |
|---|
| | | fprintf(stderr, "error: the following arguments are required: output_path\n"); |
|---|
| | | print_usage(argc, argv); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.width <= 0 || params.width % 64 != 0) { |
|---|
| | | fprintf(stderr, "error: the width must be a multiple of 64\n"); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.height <= 0 || params.height % 64 != 0) { |
|---|
| | | fprintf(stderr, "error: the height must be a multiple of 64\n"); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.sample_steps <= 0) { |
|---|
| | | fprintf(stderr, "error: the sample_steps must be greater than 0\n"); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.strength < 0.f || params.strength > 1.f) { |
|---|
| | | fprintf(stderr, "error: can only work with strength in [0.0, 1.0]\n"); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.seed < 0) { |
|---|
| | | srand((int)time(NULL)); |
|---|
| | | params.seed = rand(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.mode == CONVERT) { |
|---|
| | | if (params.output_path == "output.png") { |
|---|
| | | params.output_path = "output.gguf"; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string get_image_params(SDParams params, int64_t seed) { |
|---|
| | | std::string parameter_string = params.prompt + "\n"; |
|---|
| | | if (params.negative_prompt.size() != 0) { |
|---|
| | | parameter_string += "Negative prompt: " + params.negative_prompt + "\n"; |
|---|
| | | } |
|---|
| | | parameter_string += "Steps: " + std::to_string(params.sample_steps) + ", "; |
|---|
| | | parameter_string += "CFG scale: " + std::to_string(params.cfg_scale) + ", "; |
|---|
| | | parameter_string += "Seed: " + std::to_string(seed) + ", "; |
|---|
| | | parameter_string += "Size: " + std::to_string(params.width) + "x" + std::to_string(params.height) + ", "; |
|---|
| | | parameter_string += "Model: " + sd_basename(params.model_path) + ", "; |
|---|
| | | parameter_string += "RNG: " + std::string(rng_type_to_str[params.rng_type]) + ", "; |
|---|
| | | parameter_string += "Sampler: " + std::string(sample_method_str[params.sample_method]); |
|---|
| | | if (params.schedule == KARRAS) { |
|---|
| | | parameter_string += " karras"; |
|---|
| | | } |
|---|
| | | parameter_string += ", "; |
|---|
| | | parameter_string += "Version: stable-diffusion.cpp"; |
|---|
| | | return parameter_string; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void sd_log_cb(enum sd_log_level_t level, const char* log, void* data) { |
|---|
| | | SDParams* params = (SDParams*)data; |
|---|
| | | if (!params->verbose && level <= SD_LOG_DEBUG) { |
|---|
| | | return; |
|---|
| | | } |
|---|
| | | if (level <= SD_LOG_INFO) { |
|---|
| | | fputs(log, stdout); |
|---|
| | | fflush(stdout); |
|---|
| | | } else { |
|---|
| | | fputs(log, stderr); |
|---|
| | | fflush(stderr); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, const char* argv[]) { |
|---|
| | | SDParams params; |
|---|
| | | parse_args(argc, argv, params); |
|---|
| | | |
|---|
| | | sd_set_log_callback(sd_log_cb, (void*)¶ms); |
|---|
| | | |
|---|
| | | if (params.verbose) { |
|---|
| | | print_params(params); |
|---|
| | | printf("%s", sd_get_system_info()); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.mode == CONVERT) { |
|---|
| | | bool success = convert(params.model_path.c_str(), params.vae_path.c_str(), params.output_path.c_str(), params.wtype); |
|---|
| | | if (!success) { |
|---|
| | | fprintf(stderr, |
|---|
| | | "convert '%s'/'%s' to '%s' failed\n", |
|---|
| | | params.model_path.c_str(), |
|---|
| | | params.vae_path.c_str(), |
|---|
| | | params.output_path.c_str()); |
|---|
| | | return 1; |
|---|
| | | } else { |
|---|
| | | printf("convert '%s'/'%s' to '%s' success\n", |
|---|
| | | params.model_path.c_str(), |
|---|
| | | params.vae_path.c_str(), |
|---|
| | | params.output_path.c_str()); |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.mode == IMG2VID) { |
|---|
| | | fprintf(stderr, "SVD support is broken, do not use it!!!\n"); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool vae_decode_only = true; |
|---|
| | | uint8_t* input_image_buffer = NULL; |
|---|
| | | if (params.mode == IMG2IMG || params.mode == IMG2VID) { |
|---|
| | | vae_decode_only = false; |
|---|
| | | |
|---|
| | | int c = 0; |
|---|
| | | input_image_buffer = stbi_load(params.input_path.c_str(), ¶ms.width, ¶ms.height, &c, 3); |
|---|
| | | if (input_image_buffer == NULL) { |
|---|
| | | fprintf(stderr, "load image from '%s' failed\n", params.input_path.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | if (c != 3) { |
|---|
| | | fprintf(stderr, "input image must be a 3 channels RGB image, but got %d channels\n", c); |
|---|
| | | free(input_image_buffer); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | if (params.width <= 0 || params.width % 64 != 0) { |
|---|
| | | fprintf(stderr, "error: the width of image must be a multiple of 64\n"); |
|---|
| | | free(input_image_buffer); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | if (params.height <= 0 || params.height % 64 != 0) { |
|---|
| | | fprintf(stderr, "error: the height of image must be a multiple of 64\n"); |
|---|
| | | free(input_image_buffer); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | sd_ctx_t* sd_ctx = new_sd_ctx(params.model_path.c_str(), |
|---|
| | | params.vae_path.c_str(), |
|---|
| | | params.taesd_path.c_str(), |
|---|
| | | params.controlnet_path.c_str(), |
|---|
| | | params.lora_model_dir.c_str(), |
|---|
| | | params.embeddings_path.c_str(), |
|---|
| | | vae_decode_only, |
|---|
| | | params.vae_tiling, |
|---|
| | | true, |
|---|
| | | params.n_threads, |
|---|
| | | params.wtype, |
|---|
| | | params.rng_type, |
|---|
| | | params.schedule, |
|---|
| | | params.control_net_cpu); |
|---|
| | | |
|---|
| | | if (sd_ctx == NULL) { |
|---|
| | | printf("new_sd_ctx_t failed\n"); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | sd_image_t* results; |
|---|
| | | if (params.mode == TXT2IMG) { |
|---|
| | | sd_image_t* control_image = NULL; |
|---|
| | | if (params.controlnet_path.size() > 0 && params.control_image_path.size() > 0) { |
|---|
| | | int c = 0; |
|---|
| | | input_image_buffer = stbi_load(params.control_image_path.c_str(), ¶ms.width, ¶ms.height, &c, 3); |
|---|
| | | if (input_image_buffer == NULL) { |
|---|
| | | fprintf(stderr, "load image from '%s' failed\n", params.control_image_path.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | control_image = new sd_image_t{(uint32_t)params.width, |
|---|
| | | (uint32_t)params.height, |
|---|
| | | 3, |
|---|
| | | input_image_buffer}; |
|---|
| | | if (params.canny_preprocess) { // apply preprocessor |
|---|
| | | LOG_INFO("Applying canny preprocessor"); |
|---|
| | | control_image->data = preprocess_canny(control_image->data, control_image->width, control_image->height); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | results = txt2img(sd_ctx, |
|---|
| | | params.prompt.c_str(), |
|---|
| | | params.negative_prompt.c_str(), |
|---|
| | | params.clip_skip, |
|---|
| | | params.cfg_scale, |
|---|
| | | params.width, |
|---|
| | | params.height, |
|---|
| | | params.sample_method, |
|---|
| | | params.sample_steps, |
|---|
| | | params.seed, |
|---|
| | | params.batch_count, |
|---|
| | | control_image, |
|---|
| | | params.control_strength); |
|---|
| | | } else { |
|---|
| | | sd_image_t input_image = {(uint32_t)params.width, |
|---|
| | | (uint32_t)params.height, |
|---|
| | | 3, |
|---|
| | | input_image_buffer}; |
|---|
| | | |
|---|
| | | if (params.mode == IMG2VID) { |
|---|
| | | results = img2vid(sd_ctx, |
|---|
| | | input_image, |
|---|
| | | params.width, |
|---|
| | | params.height, |
|---|
| | | params.video_frames, |
|---|
| | | params.motion_bucket_id, |
|---|
| | | params.fps, |
|---|
| | | params.augmentation_level, |
|---|
| | | params.min_cfg, |
|---|
| | | params.cfg_scale, |
|---|
| | | params.sample_method, |
|---|
| | | params.sample_steps, |
|---|
| | | params.strength, |
|---|
| | | params.seed); |
|---|
| | | if (results == NULL) { |
|---|
| | | printf("generate failed\n"); |
|---|
| | | free_sd_ctx(sd_ctx); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | size_t last = params.output_path.find_last_of("."); |
|---|
| | | std::string dummy_name = last != std::string::npos ? params.output_path.substr(0, last) : params.output_path; |
|---|
| | | for (int i = 0; i < params.video_frames; i++) { |
|---|
| | | if (results[i].data == NULL) { |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | std::string final_image_path = i > 0 ? dummy_name + "_" + std::to_string(i + 1) + ".png" : dummy_name + ".png"; |
|---|
| | | stbi_write_png(final_image_path.c_str(), results[i].width, results[i].height, results[i].channel, |
|---|
| | | results[i].data, 0, get_image_params(params, params.seed + i).c_str()); |
|---|
| | | printf("save result image to '%s'\n", final_image_path.c_str()); |
|---|
| | | free(results[i].data); |
|---|
| | | results[i].data = NULL; |
|---|
| | | } |
|---|
| | | free(results); |
|---|
| | | free_sd_ctx(sd_ctx); |
|---|
| | | return 0; |
|---|
| | | } else { |
|---|
| | | results = img2img(sd_ctx, |
|---|
| | | input_image, |
|---|
| | | params.prompt.c_str(), |
|---|
| | | params.negative_prompt.c_str(), |
|---|
| | | params.clip_skip, |
|---|
| | | params.cfg_scale, |
|---|
| | | params.width, |
|---|
| | | params.height, |
|---|
| | | params.sample_method, |
|---|
| | | params.sample_steps, |
|---|
| | | params.strength, |
|---|
| | | params.seed, |
|---|
| | | params.batch_count); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (results == NULL) { |
|---|
| | | printf("generate failed\n"); |
|---|
| | | free_sd_ctx(sd_ctx); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int upscale_factor = 4; // unused for RealESRGAN_x4plus_anime_6B.pth |
|---|
| | | if (params.esrgan_path.size() > 0) { |
|---|
| | | upscaler_ctx_t* upscaler_ctx = new_upscaler_ctx(params.esrgan_path.c_str(), |
|---|
| | | params.n_threads, |
|---|
| | | params.wtype); |
|---|
| | | |
|---|
| | | if (upscaler_ctx == NULL) { |
|---|
| | | printf("new_upscaler_ctx failed\n"); |
|---|
| | | } else { |
|---|
| | | for (int i = 0; i < params.batch_count; i++) { |
|---|
| | | if (results[i].data == NULL) { |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | sd_image_t upscaled_image = upscale(upscaler_ctx, results[i], upscale_factor); |
|---|
| | | if (upscaled_image.data == NULL) { |
|---|
| | | printf("upscale failed\n"); |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | free(results[i].data); |
|---|
| | | results[i] = upscaled_image; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | size_t last = params.output_path.find_last_of("."); |
|---|
| | | std::string dummy_name = last != std::string::npos ? params.output_path.substr(0, last) : params.output_path; |
|---|
| | | for (int i = 0; i < params.batch_count; i++) { |
|---|
| | | if (results[i].data == NULL) { |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | std::string final_image_path = i > 0 ? dummy_name + "_" + std::to_string(i + 1) + ".png" : dummy_name + ".png"; |
|---|
| | | stbi_write_png(final_image_path.c_str(), results[i].width, results[i].height, results[i].channel, |
|---|
| | | results[i].data, 0, get_image_params(params, params.seed + i).c_str()); |
|---|
| | | printf("save result image to '%s'\n", final_image_path.c_str()); |
|---|
| | | free(results[i].data); |
|---|
| | | results[i].data = NULL; |
|---|
| | | } |
|---|
| | | free(results); |
|---|
| | | free_sd_ctx(sd_ctx); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | clang-format -style=file -i *.cpp *.h *.hpp |
|---|
| | | clang-format -style=file -i examples/cli/*.cpp |
|---|
| New file |
| | |
|---|
| | | # https://EditorConfig.org |
|---|
| | | |
|---|
| | | # Top-most EditorConfig file |
|---|
| | | root = true |
|---|
| | | |
|---|
| | | # Unix-style newlines with a newline ending every file, utf-8 charset |
|---|
| | | [*] |
|---|
| | | end_of_line = lf |
|---|
| | | insert_final_newline = true |
|---|
| | | trim_trailing_whitespace = true |
|---|
| | | charset = utf-8 |
|---|
| | | indent_style = space |
|---|
| | | indent_size = 4 |
|---|
| | | |
|---|
| | | [*.md] |
|---|
| | | indent_size = 2 |
|---|
| | | |
|---|
| | | [Makefile] |
|---|
| | | indent_style = tab |
|---|
| | | |
|---|
| | | [prompts/*.txt] |
|---|
| | | insert_final_newline = unset |
|---|
| New file |
| | |
|---|
| | | name: CI |
|---|
| | | |
|---|
| | | on: |
|---|
| | | push: |
|---|
| | | branches: [ master ] |
|---|
| | | pull_request: |
|---|
| | | branches: [ master ] |
|---|
| | | |
|---|
| | | jobs: |
|---|
| | | test-ubuntu-opencl: |
|---|
| | | if: false |
|---|
| | | runs-on: ubuntu-latest |
|---|
| | | env: |
|---|
| | | GGML_NLOOP: 3 |
|---|
| | | GGML_NITER: 1 |
|---|
| | | GGML_N_THREADS: 2 |
|---|
| | | |
|---|
| | | steps: |
|---|
| | | - uses: actions/checkout@v3 |
|---|
| | | |
|---|
| | | - name: Dependencies |
|---|
| | | run: | |
|---|
| | | wget -O- https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB | gpg --dearmor | sudo tee /usr/share/keyrings/oneapi-archive-keyring.gpg > /dev/null |
|---|
| | | echo "deb [signed-by=/usr/share/keyrings/oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main" | sudo tee /etc/apt/sources.list.d/oneAPI.list |
|---|
| | | sudo apt-get update |
|---|
| | | sudo apt-get install -y --no-install-recommends llvm intel-oneapi-runtime-opencl intel-oneapi-runtime-compilers libclblast-dev |
|---|
| | | - name: Create Build Environment |
|---|
| | | run: mkdir build |
|---|
| | | |
|---|
| | | - name: Configure CMake |
|---|
| | | working-directory: ./build |
|---|
| | | run: cmake -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DGGML_TEST_COVERAGE=ON -DGGML_CLBLAST=ON .. |
|---|
| | | |
|---|
| | | - name: Build |
|---|
| | | working-directory: ./build |
|---|
| | | run: make |
|---|
| | | |
|---|
| | | - name: Test |
|---|
| | | working-directory: ./build |
|---|
| | | run: ctest --verbose --timeout 900 |
|---|
| | | |
|---|
| | | - name: Test Coverage |
|---|
| | | working-directory: ./build |
|---|
| | | run: | |
|---|
| | | llvm-profdata merge -sparse tests/*.profraw -o ggml.profdata |
|---|
| | | llvm-cov report ./bin/test-grad0 -instr-profile=ggml.profdata |
|---|
| | | llvm-cov report ./bin/test-opt -instr-profile=ggml.profdata |
|---|
| | | |
|---|
| | | test-macos-metal: |
|---|
| | | runs-on: macos-13 |
|---|
| | | env: |
|---|
| | | GGML_NLOOP: 3 |
|---|
| | | GGML_NITER: 1 |
|---|
| | | GGML_N_THREADS: 2 |
|---|
| | | |
|---|
| | | steps: |
|---|
| | | - uses: actions/checkout@v3 |
|---|
| | | |
|---|
| | | - name: Create Build Environment |
|---|
| | | run: mkdir build |
|---|
| | | |
|---|
| | | - name: Configure CMake |
|---|
| | | working-directory: ./build |
|---|
| | | run: cmake -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DGGML_TEST_COVERAGE=ON .. |
|---|
| | | |
|---|
| | | - name: Build |
|---|
| | | working-directory: ./build |
|---|
| | | run: make |
|---|
| | | |
|---|
| | | - name: Test |
|---|
| | | working-directory: ./build |
|---|
| | | run: ctest --verbose --timeout 900 |
|---|
| | | |
|---|
| | | - name: Test Coverage |
|---|
| | | working-directory: ./build |
|---|
| | | run: | |
|---|
| | | xcrun llvm-profdata merge -sparse tests/*.profraw -o ggml.profdata |
|---|
| | | xcrun llvm-cov report ./bin/test-grad0 -instr-profile=ggml.profdata |
|---|
| | | xcrun llvm-cov report ./bin/test-opt -instr-profile=ggml.profdata |
|---|
| | | |
|---|
| | | build: |
|---|
| | | |
|---|
| | | strategy: |
|---|
| | | matrix: |
|---|
| | | os: [ubuntu-latest, macos-latest] |
|---|
| | | |
|---|
| | | runs-on: ${{ matrix.os }} |
|---|
| | | |
|---|
| | | env: |
|---|
| | | GGML_NLOOP: 3 |
|---|
| | | GGML_NITER: 1 |
|---|
| | | |
|---|
| | | steps: |
|---|
| | | - uses: actions/checkout@v3 |
|---|
| | | |
|---|
| | | - name: Dependencies for Ubuntu |
|---|
| | | if: matrix.os == 'ubuntu-latest' |
|---|
| | | run: | |
|---|
| | | sudo apt-get update |
|---|
| | | sudo apt-get install llvm |
|---|
| | | |
|---|
| | | - name: Set GGML_N_THREADS for Ubuntu |
|---|
| | | run: echo "GGML_N_THREADS=2" >> $GITHUB_ENV |
|---|
| | | if: matrix.os == 'ubuntu-latest' |
|---|
| | | |
|---|
| | | - name: Set GGML_N_THREADS for MacOS |
|---|
| | | run: echo "GGML_N_THREADS=2" >> $GITHUB_ENV |
|---|
| | | if: matrix.os == 'macos-latest' |
|---|
| | | |
|---|
| | | - name: Create Build Environment |
|---|
| | | run: mkdir build |
|---|
| | | |
|---|
| | | - name: Configure CMake |
|---|
| | | working-directory: ./build |
|---|
| | | run: cmake -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DGGML_TEST_COVERAGE=ON .. |
|---|
| | | |
|---|
| | | - name: Build |
|---|
| | | working-directory: ./build |
|---|
| | | run: make |
|---|
| | | |
|---|
| | | - name: Test |
|---|
| | | working-directory: ./build |
|---|
| | | run: ctest --verbose --timeout 900 |
|---|
| | | |
|---|
| | | - name: Test Coverage for Ubuntu |
|---|
| | | if: matrix.os == 'ubuntu-latest' |
|---|
| | | working-directory: ./build |
|---|
| | | run: | |
|---|
| | | llvm-profdata merge -sparse tests/*.profraw -o ggml.profdata |
|---|
| | | llvm-cov report ./bin/test-grad0 -instr-profile=ggml.profdata |
|---|
| | | llvm-cov report ./bin/test-opt -instr-profile=ggml.profdata |
|---|
| | | |
|---|
| | | - name: Test Coverage for MacOS |
|---|
| | | if: matrix.os == 'macos-latest' |
|---|
| | | working-directory: ./build |
|---|
| | | run: | |
|---|
| | | xcrun llvm-profdata merge -sparse tests/*.profraw -o ggml.profdata |
|---|
| | | xcrun llvm-cov report ./bin/test-grad0 -instr-profile=ggml.profdata |
|---|
| | | xcrun llvm-cov report ./bin/test-opt -instr-profile=ggml.profdata |
|---|
| New file |
| | |
|---|
| | | build/ |
|---|
| | | build-debug/ |
|---|
| | | build-release/ |
|---|
| | | build-sanitize-addr/ |
|---|
| | | build-sanitize-thread/ |
|---|
| | | build-cov/ |
|---|
| | | build-ci-debug/ |
|---|
| | | build-ci-release/ |
|---|
| | | build-cublas/ |
|---|
| | | out/ |
|---|
| | | tmp/ |
|---|
| | | models/ |
|---|
| | | models-mnt |
|---|
| | | |
|---|
| | | compile_commands.json |
|---|
| | | CMakeSettings.json |
|---|
| | | .vs/ |
|---|
| | | .vscode/ |
|---|
| | | .clangd |
|---|
| | | |
|---|
| | | .exrc |
|---|
| | | .cache |
|---|
| | | .DS_Store |
|---|
| | | .stablelm |
|---|
| | | .gpt-2 |
|---|
| | | |
|---|
| | | src/arm_neon.h |
|---|
| | | tests/arm_neon.h |
|---|
| | | |
|---|
| | | zig-out/ |
|---|
| | | zig-cache/ |
|---|
| | | |
|---|
| | | *.dot |
|---|
| | | |
|---|
| | | *.sw? |
|---|
| | | |
|---|
| | | __pycache__/ |
|---|
| | | |
|---|
| | | # Model files |
|---|
| | | ggml-model-f16.bin |
|---|
| | | *.bat |
|---|
| New file |
| | |
|---|
| | | cmake_minimum_required (VERSION 3.3) |
|---|
| | | project(ggml VERSION 0.1.0) |
|---|
| | | |
|---|
| | | set(CMAKE_EXPORT_COMPILE_COMMANDS "on") |
|---|
| | | set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/bin) |
|---|
| | | set(CMAKE_INSTALL_RPATH "${CMAKE_INSTALL_PREFIX}/lib") |
|---|
| | | |
|---|
| | | if(CMAKE_SOURCE_DIR STREQUAL CMAKE_CURRENT_SOURCE_DIR) |
|---|
| | | set(GGML_STANDALONE ON) |
|---|
| | | include(cmake/GitVars.cmake) |
|---|
| | | include(cmake/BuildTypes.cmake) |
|---|
| | | else() |
|---|
| | | set(GGML_STANDALONE OFF) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | if (EMSCRIPTEN) |
|---|
| | | set(BUILD_SHARED_LIBS_DEFAULT OFF) |
|---|
| | | else() |
|---|
| | | if (MINGW) |
|---|
| | | set(BUILD_SHARED_LIBS_DEFAULT OFF) |
|---|
| | | else() |
|---|
| | | set(BUILD_SHARED_LIBS_DEFAULT ON) |
|---|
| | | endif() |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | # options |
|---|
| | | |
|---|
| | | option(BUILD_SHARED_LIBS "ggml: build shared libs" ${BUILD_SHARED_LIBS_DEFAULT}) |
|---|
| | | |
|---|
| | | option(GGML_ALL_WARNINGS "ggml: enable all compiler warnings" ON) |
|---|
| | | option(GGML_ALL_WARNINGS_3RD_PARTY "ggml: enable all compiler warnings in 3rd party libs" OFF) |
|---|
| | | |
|---|
| | | option(GGML_SANITIZE_THREAD "ggml: enable thread sanitizer" OFF) |
|---|
| | | option(GGML_SANITIZE_ADDRESS "ggml: enable address sanitizer" OFF) |
|---|
| | | option(GGML_SANITIZE_UNDEFINED "ggml: enable undefined sanitizer" OFF) |
|---|
| | | |
|---|
| | | option(GGML_BUILD_TESTS "ggml: build tests" ${GGML_STANDALONE}) |
|---|
| | | option(GGML_BUILD_EXAMPLES "ggml: build examples" ${GGML_STANDALONE}) |
|---|
| | | |
|---|
| | | option(GGML_TEST_COVERAGE "ggml: enable test coverage" OFF) |
|---|
| | | |
|---|
| | | option(GGML_PERF "ggml: enable perf timings" OFF) |
|---|
| | | option(GGML_NO_ACCELERATE "ggml: disable Accelerate framework" OFF) |
|---|
| | | option(GGML_OPENBLAS "ggml: use OpenBLAS" OFF) |
|---|
| | | option(GGML_CLBLAST "ggml: use clBLAST" OFF) |
|---|
| | | option(GGML_HIPBLAS "ggml: use hipBLAS" OFF) |
|---|
| | | option(GGML_CUBLAS "ggml: use cuBLAS" OFF) |
|---|
| | | option(GGML_METAL "ggml: use Metal" OFF) |
|---|
| | | |
|---|
| | | option(GGML_CUDA_FORCE_DMMV "ggml: use dmmv instead of mmvq CUDA kernels" OFF) |
|---|
| | | option(GGML_CUDA_FORCE_MMQ "ggml: use mmq kernels instead of cuBLAS" OFF) |
|---|
| | | set(GGML_CUDA_DMMV_X "32" CACHE STRING "ggml: x stride for dmmv CUDA kernels") |
|---|
| | | set(GGML_CUDA_MMV_Y "1" CACHE STRING "ggml: y block size for mmv CUDA kernels") |
|---|
| | | option(GGML_CUDA_F16 "ggml: use 16 bit floats for some calculations" OFF) |
|---|
| | | set(GGML_CUDA_KQUANTS_ITER "2" CACHE STRING "ggml: iters./thread per block for Q2_K/Q6_K") |
|---|
| | | set(GGML_CUDA_PEER_MAX_BATCH_SIZE "128" CACHE STRING |
|---|
| | | "ggml: max. batch size for using peer access") |
|---|
| | | # sanitizers |
|---|
| | | |
|---|
| | | if (GGML_SANITIZE_THREAD) |
|---|
| | | set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=thread") |
|---|
| | | set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=thread") |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | if (GGML_SANITIZE_ADDRESS) |
|---|
| | | set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=address -fno-omit-frame-pointer") |
|---|
| | | set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=address -fno-omit-frame-pointer") |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | if (GGML_SANITIZE_UNDEFINED) |
|---|
| | | set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=undefined") |
|---|
| | | set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=undefined") |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | # instruction set specific |
|---|
| | | option(GGML_AVX "ggml: enable AVX" ON) |
|---|
| | | option(GGML_AVX2 "ggml: enable AVX2" ON) |
|---|
| | | option(GGML_AVX512 "ggml: enable AVX512" OFF) |
|---|
| | | option(GGML_AVX512_VBMI "ggml: enable AVX512-VBMI" OFF) |
|---|
| | | option(GGML_AVX512_VNNI "ggml: enable AVX512-VNNI" OFF) |
|---|
| | | option(GGML_FMA "ggml: enable FMA" ON) |
|---|
| | | # in MSVC F16C is implied with AVX2/AVX512 |
|---|
| | | if (NOT MSVC) |
|---|
| | | option(GGML_F16C "ggml: enable F16C" ON) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | #set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -ffast-math") |
|---|
| | | #set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -march=native") |
|---|
| | | #set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mcpu=native") |
|---|
| | | |
|---|
| | | # warning flags |
|---|
| | | |
|---|
| | | if (GGML_ALL_WARNINGS) |
|---|
| | | if (NOT MSVC) |
|---|
| | | set(c_flags -Wall -Wpedantic -Wformat=2 -Wno-unused -Wstrict-prototypes) |
|---|
| | | set(cxx_flags -Wall -Wpedantic -Wformat=2) |
|---|
| | | else() |
|---|
| | | # todo : windows |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | add_compile_options( |
|---|
| | | "$<$<COMPILE_LANGUAGE:C>:${c_flags}>" |
|---|
| | | "$<$<COMPILE_LANGUAGE:CXX>:${cxx_flags}>" |
|---|
| | | ) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | if (NOT MSVC) |
|---|
| | | add_compile_options( |
|---|
| | | "$<$<COMPILE_LANGUAGE:C>:-Werror=vla>" |
|---|
| | | "$<$<COMPILE_LANGUAGE:CXX>:-Werror=vla>" |
|---|
| | | "$<$<COMPILE_LANGUAGE:CUDA>:-Xcompiler;-Werror=vla>" |
|---|
| | | ) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | # |
|---|
| | | # POSIX conformance |
|---|
| | | # |
|---|
| | | |
|---|
| | | # clock_gettime came in POSIX.1b (1993) |
|---|
| | | # CLOCK_MONOTONIC came in POSIX.1-2001 / SUSv3 as optional |
|---|
| | | # posix_memalign came in POSIX.1-2001 / SUSv3 |
|---|
| | | # M_PI is an XSI extension since POSIX.1-2001 / SUSv3, came in XPG1 (1985) |
|---|
| | | add_compile_definitions(_XOPEN_SOURCE=600) |
|---|
| | | |
|---|
| | | # Somehow in OpenBSD whenever POSIX conformance is specified |
|---|
| | | # some string functions rely on locale_t availability, |
|---|
| | | # which was introduced in POSIX.1-2008, forcing us to go higher |
|---|
| | | if (CMAKE_SYSTEM_NAME MATCHES "OpenBSD") |
|---|
| | | remove_definitions(-D_XOPEN_SOURCE=600) |
|---|
| | | add_compile_definitions(_XOPEN_SOURCE=700) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | # Data types, macros and functions related to controlling CPU affinity |
|---|
| | | # are available on Linux through GNU extensions in libc |
|---|
| | | if (CMAKE_SYSTEM_NAME MATCHES "Linux") |
|---|
| | | add_compile_definitions(_GNU_SOURCE) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | # RLIMIT_MEMLOCK came in BSD, is not specified in POSIX.1, |
|---|
| | | # and on macOS its availability depends on enabling Darwin extensions |
|---|
| | | # similarly on DragonFly, enabling BSD extensions is necessary |
|---|
| | | if (CMAKE_SYSTEM_NAME MATCHES "Darwin") |
|---|
| | | add_compile_definitions(_DARWIN_C_SOURCE) |
|---|
| | | endif() |
|---|
| | | if (CMAKE_SYSTEM_NAME MATCHES "DragonFly") |
|---|
| | | add_compile_definitions(_DARWIN_C_SOURCE) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | # alloca is a non-standard interface that is not visible on BSDs when |
|---|
| | | # POSIX conformance is specified, but not all of them provide a clean way |
|---|
| | | # to enable it in such cases |
|---|
| | | if (CMAKE_SYSTEM_NAME MATCHES "FreeBSD") |
|---|
| | | add_compile_definitions(__BSD_VISIBLE) |
|---|
| | | endif() |
|---|
| | | if (CMAKE_SYSTEM_NAME MATCHES "NetBSD") |
|---|
| | | add_compile_definitions(_NETBSD_SOURCE) |
|---|
| | | endif() |
|---|
| | | if (CMAKE_SYSTEM_NAME MATCHES "OpenBSD") |
|---|
| | | add_compile_definitions(_BSD_SOURCE) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | if (WHISPER_PERF) |
|---|
| | | set(WHISPER_EXTRA_FLAGS ${WHISPER_EXTRA_FLAGS} -DGGML_PERF) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | # dependencies |
|---|
| | | |
|---|
| | | set(CMAKE_C_STANDARD 11) |
|---|
| | | set(CMAKE_CXX_STANDARD 11) |
|---|
| | | |
|---|
| | | find_package(Threads REQUIRED) |
|---|
| | | |
|---|
| | | # main |
|---|
| | | |
|---|
| | | if (NOT CMAKE_BUILD_TYPE AND NOT CMAKE_CONFIGURATION_TYPES) |
|---|
| | | set(CMAKE_BUILD_TYPE Release CACHE STRING "Build type" FORCE) |
|---|
| | | set_property(CACHE CMAKE_BUILD_TYPE PROPERTY STRINGS "Debug" "Release" "RelWithDebInfo") |
|---|
| | | endif () |
|---|
| | | |
|---|
| | | if (GGML_BUILD_TESTS) |
|---|
| | | if (GGML_TEST_COVERAGE) |
|---|
| | | if (CMAKE_C_COMPILER_ID MATCHES "Clang") |
|---|
| | | set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fprofile-instr-generate -fcoverage-mapping") |
|---|
| | | set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fprofile-instr-generate -fcoverage-mapping") |
|---|
| | | else() |
|---|
| | | message(WARNING "Test coverage is only supported for Clang") |
|---|
| | | endif() |
|---|
| | | endif() |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | add_subdirectory(src) |
|---|
| | | |
|---|
| | | if (GGML_BUILD_TESTS) |
|---|
| | | enable_testing() |
|---|
| | | add_subdirectory(tests) |
|---|
| | | endif () |
|---|
| | | |
|---|
| | | if (GGML_BUILD_EXAMPLES) |
|---|
| | | add_subdirectory(examples) |
|---|
| | | endif () |
|---|
| | | |
|---|
| | | configure_file(${CMAKE_CURRENT_SOURCE_DIR}/ggml.pc.in |
|---|
| | | ${CMAKE_CURRENT_BINARY_DIR}/ggml.pc |
|---|
| | | @ONLY) |
|---|
| | | install(FILES ${CMAKE_CURRENT_BINARY_DIR}/ggml.pc |
|---|
| | | DESTINATION share/pkgconfig) |
|---|
| New file |
| | |
|---|
| | | MIT License |
|---|
| | | |
|---|
| | | Copyright (c) 2022 Georgi Gerganov |
|---|
| | | |
|---|
| | | Permission is hereby granted, free of charge, to any person obtaining a copy |
|---|
| | | of this software and associated documentation files (the "Software"), to deal |
|---|
| | | in the Software without restriction, including without limitation the rights |
|---|
| | | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell |
|---|
| | | copies of the Software, and to permit persons to whom the Software is |
|---|
| | | furnished to do so, subject to the following conditions: |
|---|
| | | |
|---|
| | | The above copyright notice and this permission notice shall be included in all |
|---|
| | | copies or substantial portions of the Software. |
|---|
| | | |
|---|
| | | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR |
|---|
| | | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, |
|---|
| | | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE |
|---|
| | | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER |
|---|
| | | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, |
|---|
| | | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE |
|---|
| | | SOFTWARE. |
|---|
| New file |
| | |
|---|
| | | // swift-tools-version: 5.5 |
|---|
| | | |
|---|
| | | import PackageDescription |
|---|
| | | |
|---|
| | | let package = Package( |
|---|
| | | name: "ggml", |
|---|
| | | platforms: [ |
|---|
| | | .macOS(.v12), |
|---|
| | | .iOS(.v14), |
|---|
| | | .watchOS(.v4), |
|---|
| | | .tvOS(.v14) |
|---|
| | | ], |
|---|
| | | products: [ |
|---|
| | | .library(name: "ggml", targets: ["ggml"]), |
|---|
| | | ], |
|---|
| | | targets: [ |
|---|
| | | .target( |
|---|
| | | name: "ggml", |
|---|
| | | path: ".", |
|---|
| | | exclude: [], |
|---|
| | | sources: [ |
|---|
| | | "src/ggml.c", |
|---|
| | | "src/ggml-alloc.c", |
|---|
| | | "src/ggml-backend.c", |
|---|
| | | "src/ggml-quants.c", |
|---|
| | | "src/ggml-metal.m", |
|---|
| | | ], |
|---|
| | | resources: [ |
|---|
| | | .process("src/ggml-metal.metal") |
|---|
| | | ], |
|---|
| | | publicHeadersPath: "include/ggml", |
|---|
| | | cSettings: [ |
|---|
| | | .unsafeFlags(["-Wno-shorten-64-to-32", "-O3", "-DNDEBUG"]), |
|---|
| | | .define("GGML_USE_ACCELERATE"), |
|---|
| | | .unsafeFlags(["-fno-objc-arc"]), |
|---|
| | | .define("GGML_USE_METAL"), |
|---|
| | | // NOTE: NEW_LAPACK will required iOS version 16.4+ |
|---|
| | | // We should consider add this in the future when we drop support for iOS 14 |
|---|
| | | // (ref: ref: https://developer.apple.com/documentation/accelerate/1513264-cblas_sgemm?language=objc) |
|---|
| | | // .define("ACCELERATE_NEW_LAPACK"), |
|---|
| | | // .define("ACCELERATE_LAPACK_ILP64") |
|---|
| | | ], |
|---|
| | | linkerSettings: [ |
|---|
| | | .linkedFramework("Accelerate") |
|---|
| | | ] |
|---|
| | | ) |
|---|
| | | ], |
|---|
| | | cxxLanguageStandard: .cxx11 |
|---|
| | | ) |
|---|
| New file |
| | |
|---|
| | | # ggml |
|---|
| | | |
|---|
| | | [Roadmap](https://github.com/users/ggerganov/projects/7) / [Manifesto](https://github.com/ggerganov/llama.cpp/discussions/205) |
|---|
| | | |
|---|
| | | Tensor library for machine learning |
|---|
| | | |
|---|
| | | ***Note that this project is under active development. \ |
|---|
| | | Some of the development is currently happening in the [llama.cpp](https://github.com/ggerganov/llama.cpp) and [whisper.cpp](https://github.com/ggerganov/whisper.cpp) repos*** |
|---|
| | | |
|---|
| | | ## Features |
|---|
| | | |
|---|
| | | - Written in C |
|---|
| | | - 16-bit float support |
|---|
| | | - Integer quantization support (4-bit, 5-bit, 8-bit, etc.) |
|---|
| | | - Automatic differentiation |
|---|
| | | - ADAM and L-BFGS optimizers |
|---|
| | | - Optimized for Apple Silicon |
|---|
| | | - On x86 architectures utilizes AVX / AVX2 intrinsics |
|---|
| | | - On ppc64 architectures utilizes VSX intrinsics |
|---|
| | | - No third-party dependencies |
|---|
| | | - Zero memory allocations during runtime |
|---|
| | | |
|---|
| | | ## Updates |
|---|
| | | |
|---|
| | | - [X] Example of GPT-2 inference [examples/gpt-2](https://github.com/ggerganov/ggml/tree/master/examples/gpt-2) |
|---|
| | | - [X] Example of GPT-J inference [examples/gpt-j](https://github.com/ggerganov/ggml/tree/master/examples/gpt-j) |
|---|
| | | - [X] Example of Whisper inference [examples/whisper](https://github.com/ggerganov/ggml/tree/master/examples/whisper) |
|---|
| | | - [X] Support 4-bit integer quantization https://github.com/ggerganov/ggml/pull/27 |
|---|
| | | - [X] Example of Cerebras-GPT inference [examples/gpt-2](https://github.com/ggerganov/ggml/tree/master/examples/gpt-2) |
|---|
| | | - [ ] Example of FLAN-T5 inference https://github.com/ggerganov/ggml/pull/12 |
|---|
| | | - [X] Example of LLaMA inference [ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp) |
|---|
| | | - [X] Example of LLaMA training [ggerganov/llama.cpp/examples/baby-llama](https://github.com/ggerganov/llama.cpp/tree/master/examples/baby-llama) |
|---|
| | | - [X] Example of Falcon inference [cmp-nct/ggllm.cpp](https://github.com/cmp-nct/ggllm.cpp) |
|---|
| | | - [X] Example of BLOOM inference [NouamaneTazi/bloomz.cpp](https://github.com/NouamaneTazi/bloomz.cpp) |
|---|
| | | - [X] Example of RWKV inference [saharNooby/rwkv.cpp](https://github.com/saharNooby/rwkv.cpp) |
|---|
| | | - [X] Example of SAM inference [examples/sam](https://github.com/ggerganov/ggml/tree/master/examples/sam) |
|---|
| | | - [X] Idea for GPU support: https://github.com/ggerganov/llama.cpp/discussions/915 |
|---|
| | | - [X] Example of StableLM (GPT-NeoX) inference [examples/gpt-neox](https://github.com/ggerganov/ggml/tree/master/examples/gpt-neox) |
|---|
| | | - [X] Example of BERT inference [skeskinen/bert.cpp](https://github.com/skeskinen/bert.cpp) |
|---|
| | | - [X] Example of 💫 StarCoder inference [examples/starcoder](https://github.com/ggerganov/ggml/tree/master/examples/starcoder) |
|---|
| | | - [X] Example of MPT inference [examples/mpt](https://github.com/ggerganov/ggml/tree/master/examples/mpt) |
|---|
| | | - [X] Example of Replit inference [examples/replit](https://github.com/ggerganov/ggml/tree/master/examples/replit) |
|---|
| | | - [X] Example of BioGPT inference [PABannier/biogpt.cpp](https://github.com/PABannier/biogpt.cpp) |
|---|
| | | - [X] Example of Encodec inference [PABannier/encodec.cpp](https://github.com/PABannier/encodec.cpp) |
|---|
| | | - [X] Example of CLIP inference [monatis/clip.cpp](https://github.com/monatis/clip.cpp) |
|---|
| | | - [X] Example of MiniGPT4 inference [Maknee/minigpt4.cpp](https://github.com/Maknee/minigpt4.cpp) |
|---|
| | | - [X] Example of ChatGLM inference [li-plus/chatglm.cpp](https://github.com/li-plus/chatglm.cpp) |
|---|
| | | - [X] Example of Stable Diffusion inference [leejet/stable-diffusion.cpp](https://github.com/leejet/stable-diffusion.cpp) |
|---|
| | | - [X] Example of Qwen inference [QwenLM/qwen.cpp](https://github.com/QwenLM/qwen.cpp) |
|---|
| | | - [X] Example of YOLO inference [examples/yolo](https://github.com/ggerganov/ggml/tree/master/examples/yolo) |
|---|
| | | - [X] Example of ViT inference [staghado/vit.cpp](https://github.com/staghado/vit.cpp) |
|---|
| | | - [X] SeamlessM4T inference *(in development)* https://github.com/facebookresearch/seamless_communication/tree/main/ggml |
|---|
| | | |
|---|
| | | ## Whisper inference (example) |
|---|
| | | |
|---|
| | | With ggml you can efficiently run [Whisper](examples/whisper) inference on the CPU. |
|---|
| | | |
|---|
| | | Memory requirements: |
|---|
| | | |
|---|
| | | | Model | Disk | Mem | |
|---|
| | | | --- | --- | --- | |
|---|
| | | | tiny | 75 MB | ~280 MB | |
|---|
| | | | base | 142 MB | ~430 MB | |
|---|
| | | | small | 466 MB | ~1.0 GB | |
|---|
| | | | medium | 1.5 GB | ~2.6 GB | |
|---|
| | | | large | 2.9 GB | ~4.7 GB | |
|---|
| | | |
|---|
| | | ## GPT inference (example) |
|---|
| | | |
|---|
| | | With ggml you can efficiently run [GPT-2](examples/gpt-2) and [GPT-J](examples/gpt-j) inference on the CPU. |
|---|
| | | |
|---|
| | | Here is how to run the example programs: |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | # Build ggml + examples |
|---|
| | | git clone https://github.com/ggerganov/ggml |
|---|
| | | cd ggml |
|---|
| | | mkdir build && cd build |
|---|
| | | cmake .. |
|---|
| | | make -j4 gpt-2-backend gpt-j |
|---|
| | | |
|---|
| | | # Run the GPT-2 small 117M model |
|---|
| | | ../examples/gpt-2/download-ggml-model.sh 117M |
|---|
| | | ./bin/gpt-2-backend -m models/gpt-2-117M/ggml-model.bin -p "This is an example" |
|---|
| | | |
|---|
| | | # Run the GPT-J 6B model (requires 12GB disk space and 16GB CPU RAM) |
|---|
| | | ../examples/gpt-j/download-ggml-model.sh 6B |
|---|
| | | ./bin/gpt-j -m models/gpt-j-6B/ggml-model.bin -p "This is an example" |
|---|
| | | |
|---|
| | | # Install Python dependencies |
|---|
| | | python3 -m pip install -r ../requirements.txt |
|---|
| | | |
|---|
| | | # Run the Cerebras-GPT 111M model |
|---|
| | | # Download from: https://huggingface.co/cerebras |
|---|
| | | python3 ../examples/gpt-2/convert-cerebras-to-ggml.py /path/to/Cerebras-GPT-111M/ |
|---|
| | | ./bin/gpt-2 -m /path/to/Cerebras-GPT-111M/ggml-model-f16.bin -p "This is an example" |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | The inference speeds that I get for the different models on my 32GB MacBook M1 Pro are as follows: |
|---|
| | | |
|---|
| | | | Model | Size | Time / Token | |
|---|
| | | | --- | --- | --- | |
|---|
| | | | GPT-2 | 117M | 5 ms | |
|---|
| | | | GPT-2 | 345M | 12 ms | |
|---|
| | | | GPT-2 | 774M | 23 ms | |
|---|
| | | | GPT-2 | 1558M | 42 ms | |
|---|
| | | | --- | --- | --- | |
|---|
| | | | GPT-J | 6B | 125 ms | |
|---|
| | | |
|---|
| | | For more information, checkout the corresponding programs in the [examples](examples) folder. |
|---|
| | | |
|---|
| | | ## Using Metal (only with GPT-2) |
|---|
| | | |
|---|
| | | For GPT-2 models, offloading to GPU is possible. Note that it will not improve inference performances but will reduce power consumption and free up the CPU for other tasks. |
|---|
| | | |
|---|
| | | To enable GPU offloading on MacOS: |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | cmake -DGGML_METAL=ON -DBUILD_SHARED_LIBS=Off .. |
|---|
| | | |
|---|
| | | # add -ngl 1 |
|---|
| | | ./bin/gpt-2 -t 4 -ngl 100 -m models/gpt-2-117M/ggml-model.bin -p "This is an example" |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Using cuBLAS |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | # fix the path to point to your CUDA compiler |
|---|
| | | cmake -DGGML_CUBLAS=ON -DCMAKE_CUDA_COMPILER=/usr/local/cuda-12.1/bin/nvcc .. |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Using clBLAST |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | cmake -DGGML_CLBLAST=ON .. |
|---|
| | | ``` |
|---|
| | | ## Compiling for Android |
|---|
| | | |
|---|
| | | Download and unzip the NDK from this download [page](https://developer.android.com/ndk/downloads). Set the NDK_ROOT_PATH environment variable or provide the absolute path to the CMAKE_ANDROID_NDK in the command below. |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | cmake .. \ |
|---|
| | | -DCMAKE_SYSTEM_NAME=Android \ |
|---|
| | | -DCMAKE_SYSTEM_VERSION=33 \ |
|---|
| | | -DCMAKE_ANDROID_ARCH_ABI=arm64-v8a \ |
|---|
| | | -DCMAKE_ANDROID_NDK=$NDK_ROOT_PATH |
|---|
| | | -DCMAKE_ANDROID_STL_TYPE=c++_shared |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | # Create directories |
|---|
| | | adb shell 'mkdir /data/local/tmp/bin' |
|---|
| | | adb shell 'mkdir /data/local/tmp/models' |
|---|
| | | |
|---|
| | | # Push the compiled binaries to the folder |
|---|
| | | adb push bin/* /data/local/tmp/bin/ |
|---|
| | | |
|---|
| | | # Push the ggml library |
|---|
| | | adb push src/libggml.so /data/local/tmp/ |
|---|
| | | |
|---|
| | | # Push model files |
|---|
| | | adb push models/gpt-2-117M/ggml-model.bin /data/local/tmp/models/ |
|---|
| | | |
|---|
| | | |
|---|
| | | # Now lets do some inference ... |
|---|
| | | adb shell |
|---|
| | | |
|---|
| | | # Now we are in shell |
|---|
| | | cd /data/local/tmp |
|---|
| | | export LD_LIBRARY_PATH=/data/local/tmp |
|---|
| | | ./bin/gpt-2-backend -m models/ggml-model.bin -p "this is an example" |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Resources |
|---|
| | | |
|---|
| | | - [GGML - Large Language Models for Everyone](https://github.com/rustformers/llm/blob/main/crates/ggml/README.md): a description of the GGML format provided by the maintainers of the `llm` Rust crate, which provides Rust bindings for GGML |
|---|
| | | - [marella/ctransformers](https://github.com/marella/ctransformers): Python bindings for GGML models. |
|---|
| | | - [go-skynet/go-ggml-transformers.cpp](https://github.com/go-skynet/go-ggml-transformers.cpp): Golang bindings for GGML models |
|---|
| | | - [smspillaz/ggml-gobject](https://github.com/smspillaz/ggml-gobject): GObject-introspectable wrapper for use of GGML on the GNOME platform. |
|---|
| New file |
| | |
|---|
| | | const std = @import("std"); |
|---|
| | | const builtin = @import("builtin"); |
|---|
| | | |
|---|
| | | // Zig Version: 0.11.0 |
|---|
| | | // Zig Build Command: zig build |
|---|
| | | // Zig Run Command: zig build -h |
|---|
| | | // zig build run_dolly-v2 |
|---|
| | | // zig build run_gpt-2 |
|---|
| | | // zig build run_gpt-j |
|---|
| | | // zig build run_gpt-neox |
|---|
| | | // zig build run_mnist |
|---|
| | | // zig build run_mpt |
|---|
| | | // zig build run_replit |
|---|
| | | // zig build run_starcoder |
|---|
| | | // zig build run_test-grad0 |
|---|
| | | // zig build run_test-mul-mat0 |
|---|
| | | // zig build run_test-mul-mat2 |
|---|
| | | // zig build run_test-opt |
|---|
| | | // zig build run_test-vec1 |
|---|
| | | // zig build run_test0 |
|---|
| | | // zig build run_test1 |
|---|
| | | // zig build run_test2 |
|---|
| | | // zig build run_test3 |
|---|
| | | // zig build run_zig_test0 |
|---|
| | | // zig build run_zig_test1 |
|---|
| | | // zig build run_zig_test2 |
|---|
| | | // zig build run_zig_test3 |
|---|
| | | pub fn build(b: *std.build.Builder) void { |
|---|
| | | const target = b.standardTargetOptions(.{}); |
|---|
| | | const optimize = b.standardOptimizeOption(.{}); |
|---|
| | | const lib = b.addStaticLibrary(.{ |
|---|
| | | .name = "ggml", |
|---|
| | | .target = target, |
|---|
| | | .optimize = optimize, |
|---|
| | | }); |
|---|
| | | lib.addIncludePath(.{ .path = "./include" }); |
|---|
| | | lib.addIncludePath(.{ .path = "./include/ggml" }); |
|---|
| | | lib.addCSourceFiles(&.{ |
|---|
| | | "src/ggml.c", |
|---|
| | | }, &.{"-std=c11"}); |
|---|
| | | lib.linkLibC(); |
|---|
| | | lib.linkLibCpp(); |
|---|
| | | b.installArtifact(lib); |
|---|
| | | |
|---|
| | | // examples |
|---|
| | | const examples = .{ |
|---|
| | | "dolly-v2", |
|---|
| | | "gpt-2", |
|---|
| | | "gpt-j", |
|---|
| | | "gpt-neox", |
|---|
| | | "mnist", |
|---|
| | | "mpt", |
|---|
| | | "replit", |
|---|
| | | "starcoder", |
|---|
| | | // "whisper", |
|---|
| | | }; |
|---|
| | | inline for (examples) |name| { |
|---|
| | | const exe = b.addExecutable(.{ |
|---|
| | | .name = name, |
|---|
| | | .target = target, |
|---|
| | | .optimize = optimize, |
|---|
| | | }); |
|---|
| | | exe.addIncludePath(.{ .path = "./include" }); |
|---|
| | | exe.addIncludePath(.{ .path = "./include/ggml" }); |
|---|
| | | exe.addIncludePath(.{ .path = "./examples" }); |
|---|
| | | // exe.addIncludePath("./examples/whisper"); |
|---|
| | | exe.addCSourceFiles(&.{ |
|---|
| | | std.fmt.comptimePrint("examples/{s}/main.cpp", .{name}), |
|---|
| | | "examples/common.cpp", |
|---|
| | | "examples/common-ggml.cpp", |
|---|
| | | // "examples/whisper/whisper.cpp", |
|---|
| | | }, &.{"-std=c++11"}); |
|---|
| | | exe.linkLibrary(lib); |
|---|
| | | b.installArtifact(exe); |
|---|
| | | const run_cmd = b.addRunArtifact(exe); |
|---|
| | | run_cmd.step.dependOn(b.getInstallStep()); |
|---|
| | | if (b.args) |args| run_cmd.addArgs(args); |
|---|
| | | const run_step = b.step("run_" ++ name, "Run examples"); |
|---|
| | | run_step.dependOn(&run_cmd.step); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // tests |
|---|
| | | const tests = if (builtin.target.cpu.arch == .x86_64) .{ |
|---|
| | | // "test-blas0", |
|---|
| | | // "test-grad0", |
|---|
| | | "test-mul-mat0", |
|---|
| | | // "test-mul-mat1", |
|---|
| | | "test-mul-mat2", |
|---|
| | | // "test-opt", |
|---|
| | | // "test-svd0", |
|---|
| | | // "test-vec0", |
|---|
| | | "test-vec1", |
|---|
| | | // "test-vec2", |
|---|
| | | "test0", |
|---|
| | | "test1", |
|---|
| | | "test2", |
|---|
| | | "test3", |
|---|
| | | } else .{ |
|---|
| | | // "test-blas0", |
|---|
| | | // "test-grad0", |
|---|
| | | "test-mul-mat0", |
|---|
| | | // "test-mul-mat1", |
|---|
| | | "test-mul-mat2", |
|---|
| | | // "test-opt", |
|---|
| | | // "test-svd0", |
|---|
| | | // "test-vec0", |
|---|
| | | // "test-vec1", |
|---|
| | | // "test-vec2", |
|---|
| | | "test0", |
|---|
| | | "test1", |
|---|
| | | "test2", |
|---|
| | | "test3", |
|---|
| | | }; |
|---|
| | | inline for (tests) |name| { |
|---|
| | | const exe = b.addExecutable(.{ |
|---|
| | | .name = name, |
|---|
| | | .target = target, |
|---|
| | | .optimize = optimize, |
|---|
| | | }); |
|---|
| | | exe.addIncludePath(.{ .path = "./include" }); |
|---|
| | | exe.addIncludePath(.{ .path = "./include/ggml" }); |
|---|
| | | exe.addCSourceFiles(&.{ |
|---|
| | | std.fmt.comptimePrint("tests/{s}.c", .{name}), |
|---|
| | | }, &.{"-std=c11"}); |
|---|
| | | exe.linkLibrary(lib); |
|---|
| | | b.installArtifact(exe); |
|---|
| | | const run_cmd = b.addRunArtifact(exe); |
|---|
| | | run_cmd.step.dependOn(b.getInstallStep()); |
|---|
| | | if (b.args) |args| run_cmd.addArgs(args); |
|---|
| | | const run_step = b.step("run_" ++ name, "Run tests"); |
|---|
| | | run_step.dependOn(&run_cmd.step); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // zig_tests |
|---|
| | | const zig_tests = .{ |
|---|
| | | "test0", |
|---|
| | | "test1", |
|---|
| | | "test2", |
|---|
| | | "test3", |
|---|
| | | }; |
|---|
| | | inline for (zig_tests) |name| { |
|---|
| | | const exe = b.addExecutable(.{ |
|---|
| | | .name = name, |
|---|
| | | .root_source_file = .{ .path = std.fmt.comptimePrint("tests/{s}.zig", .{name}) }, |
|---|
| | | .target = target, |
|---|
| | | .optimize = optimize, |
|---|
| | | }); |
|---|
| | | exe.addIncludePath(.{ .path = "./include" }); |
|---|
| | | exe.addIncludePath(.{ .path = "./include/ggml" }); |
|---|
| | | exe.linkLibrary(lib); |
|---|
| | | b.installArtifact(exe); |
|---|
| | | const run_cmd = b.addRunArtifact(exe); |
|---|
| | | run_cmd.step.dependOn(b.getInstallStep()); |
|---|
| | | if (b.args) |args| run_cmd.addArgs(args); |
|---|
| | | const run_step = b.step("run_zig_" ++ name, "Run zig_tests"); |
|---|
| | | run_step.dependOn(&run_cmd.step); |
|---|
| | | } |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #/bin/bash |
|---|
| | | # |
|---|
| | | # sample usage: |
|---|
| | | # |
|---|
| | | # mkdir tmp |
|---|
| | | # |
|---|
| | | # # CPU-only build |
|---|
| | | # bash ./ci/run.sh ./tmp/results ./tmp/mnt |
|---|
| | | # |
|---|
| | | # # with CUDA support |
|---|
| | | # GG_BUILD_CUDA=1 bash ./ci/run.sh ./tmp/results ./tmp/mnt |
|---|
| | | # |
|---|
| | | |
|---|
| | | if [ -z "$2" ]; then |
|---|
| | | echo "usage: $0 <output-dir> <mnt-dir>" |
|---|
| | | exit 1 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | mkdir -p "$1" |
|---|
| | | mkdir -p "$2" |
|---|
| | | |
|---|
| | | OUT=$(realpath "$1") |
|---|
| | | MNT=$(realpath "$2") |
|---|
| | | |
|---|
| | | rm -v $OUT/*.log |
|---|
| | | rm -v $OUT/*.exit |
|---|
| | | rm -v $OUT/*.md |
|---|
| | | |
|---|
| | | sd=`dirname $0` |
|---|
| | | cd $sd/../ |
|---|
| | | SRC=`pwd` |
|---|
| | | |
|---|
| | | CMAKE_EXTRA="" |
|---|
| | | |
|---|
| | | if [ ! -z ${GG_BUILD_CUDA} ]; then |
|---|
| | | CMAKE_EXTRA="${CMAKE_EXTRA} -DGGML_CUBLAS=ON" |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ ! -z ${GG_BUILD_METAL} ]; then |
|---|
| | | CMAKE_EXTRA="${CMAKE_EXTRA} -DGGML_METAL=ON" |
|---|
| | | fi |
|---|
| | | |
|---|
| | | ## helpers |
|---|
| | | |
|---|
| | | # download a file if it does not exist or if it is outdated |
|---|
| | | function gg_wget { |
|---|
| | | local out=$1 |
|---|
| | | local url=$2 |
|---|
| | | |
|---|
| | | local cwd=`pwd` |
|---|
| | | |
|---|
| | | mkdir -p $out |
|---|
| | | cd $out |
|---|
| | | |
|---|
| | | # should not re-download if file is the same |
|---|
| | | wget -nv -N $url |
|---|
| | | |
|---|
| | | cd $cwd |
|---|
| | | } |
|---|
| | | |
|---|
| | | function gg_printf { |
|---|
| | | printf -- "$@" >> $OUT/README.md |
|---|
| | | } |
|---|
| | | |
|---|
| | | function gg_run { |
|---|
| | | ci=$1 |
|---|
| | | |
|---|
| | | set -o pipefail |
|---|
| | | set -x |
|---|
| | | |
|---|
| | | gg_run_$ci | tee $OUT/$ci.log |
|---|
| | | cur=$? |
|---|
| | | echo "$cur" > $OUT/$ci.exit |
|---|
| | | |
|---|
| | | set +x |
|---|
| | | set +o pipefail |
|---|
| | | |
|---|
| | | gg_sum_$ci |
|---|
| | | |
|---|
| | | ret=$((ret | cur)) |
|---|
| | | } |
|---|
| | | |
|---|
| | | ## ci |
|---|
| | | |
|---|
| | | # ctest_debug |
|---|
| | | |
|---|
| | | function gg_run_ctest_debug { |
|---|
| | | cd ${SRC} |
|---|
| | | |
|---|
| | | rm -rf build-ci-debug && mkdir build-ci-debug && cd build-ci-debug |
|---|
| | | |
|---|
| | | set -e |
|---|
| | | |
|---|
| | | (time cmake -DCMAKE_BUILD_TYPE=Debug ${CMAKE_EXTRA} .. ) 2>&1 | tee -a $OUT/${ci}-cmake.log |
|---|
| | | (time make -j ) 2>&1 | tee -a $OUT/${ci}-make.log |
|---|
| | | |
|---|
| | | if [ ! -z ${GG_BUILD_METAL} ]; then |
|---|
| | | export GGML_METAL_PATH_RESOURCES="$(pwd)/bin" |
|---|
| | | fi |
|---|
| | | |
|---|
| | | (time ctest --output-on-failure -E test-opt ) 2>&1 | tee -a $OUT/${ci}-ctest.log |
|---|
| | | |
|---|
| | | set +e |
|---|
| | | } |
|---|
| | | |
|---|
| | | function gg_sum_ctest_debug { |
|---|
| | | gg_printf '### %s\n\n' "${ci}" |
|---|
| | | |
|---|
| | | gg_printf 'Runs ctest in debug mode\n' |
|---|
| | | gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | gg_printf '%s\n' "$(cat $OUT/${ci}-ctest.log)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | gg_printf '\n' |
|---|
| | | } |
|---|
| | | |
|---|
| | | # ctest_release |
|---|
| | | |
|---|
| | | function gg_run_ctest_release { |
|---|
| | | cd ${SRC} |
|---|
| | | |
|---|
| | | rm -rf build-ci-release && mkdir build-ci-release && cd build-ci-release |
|---|
| | | |
|---|
| | | set -e |
|---|
| | | |
|---|
| | | (time cmake -DCMAKE_BUILD_TYPE=Release ${CMAKE_EXTRA} .. ) 2>&1 | tee -a $OUT/${ci}-cmake.log |
|---|
| | | (time make -j ) 2>&1 | tee -a $OUT/${ci}-make.log |
|---|
| | | |
|---|
| | | if [ ! -z ${GG_BUILD_METAL} ]; then |
|---|
| | | export GGML_METAL_PATH_RESOURCES="$(pwd)/bin" |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ -z $GG_BUILD_LOW_PERF ]; then |
|---|
| | | (time ctest --output-on-failure ) 2>&1 | tee -a $OUT/${ci}-ctest.log |
|---|
| | | else |
|---|
| | | (time ctest --output-on-failure -E test-opt ) 2>&1 | tee -a $OUT/${ci}-ctest.log |
|---|
| | | fi |
|---|
| | | |
|---|
| | | set +e |
|---|
| | | } |
|---|
| | | |
|---|
| | | function gg_sum_ctest_release { |
|---|
| | | gg_printf '### %s\n\n' "${ci}" |
|---|
| | | |
|---|
| | | gg_printf 'Runs ctest in release mode\n' |
|---|
| | | gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | gg_printf '%s\n' "$(cat $OUT/${ci}-ctest.log)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | } |
|---|
| | | |
|---|
| | | # gpt_2 |
|---|
| | | |
|---|
| | | function gg_run_gpt_2 { |
|---|
| | | cd ${SRC} |
|---|
| | | |
|---|
| | | gg_wget models-mnt/gpt-2 https://huggingface.co/ggerganov/ggml/resolve/main/ggml-model-gpt-2-117M.bin |
|---|
| | | |
|---|
| | | cd build-ci-release |
|---|
| | | |
|---|
| | | set -e |
|---|
| | | |
|---|
| | | model="../models-mnt/gpt-2/ggml-model-gpt-2-117M.bin" |
|---|
| | | prompts="../examples/prompts/gpt-2.txt" |
|---|
| | | |
|---|
| | | (time ./bin/gpt-2-backend2 --model ${model} -s 1234 -n 64 -tt ${prompts} ) 2>&1 | tee -a $OUT/${ci}-tg.log |
|---|
| | | (time ./bin/gpt-2-backend2 --model ${model} -s 1234 -n 64 -p "I believe the meaning of life is") 2>&1 | tee -a $OUT/${ci}-tg.log |
|---|
| | | |
|---|
| | | (time ./bin/gpt-2-batched --model ${model} -s 1234 -n 64 -np 8 -p "I believe the meaning of life is") 2>&1 | tee -a $OUT/${ci}-tg.log |
|---|
| | | |
|---|
| | | set +e |
|---|
| | | } |
|---|
| | | |
|---|
| | | function gg_sum_gpt_2 { |
|---|
| | | gg_printf '### %s\n\n' "${ci}" |
|---|
| | | |
|---|
| | | gg_printf 'Runs short GPT-2 text generation\n' |
|---|
| | | gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | gg_printf '%s\n' "$(cat $OUT/${ci}-tg.log)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | } |
|---|
| | | |
|---|
| | | # mnist |
|---|
| | | |
|---|
| | | function gg_run_mnist { |
|---|
| | | cd ${SRC} |
|---|
| | | |
|---|
| | | cd build-ci-release |
|---|
| | | |
|---|
| | | set -e |
|---|
| | | |
|---|
| | | mkdir -p models/mnist |
|---|
| | | python3 ../examples/mnist/convert-h5-to-ggml.py ../examples/mnist/models/mnist/mnist_model.state_dict |
|---|
| | | |
|---|
| | | model_f32="./models/mnist/ggml-model-f32.bin" |
|---|
| | | samples="../examples/mnist/models/mnist/t10k-images.idx3-ubyte" |
|---|
| | | |
|---|
| | | # first command runs and exports "mnist.ggml", the second command runs the exported model |
|---|
| | | |
|---|
| | | (time ./bin/mnist ${model_f32} ${samples} ) 2>&1 | tee -a $OUT/${ci}-mnist.log |
|---|
| | | (time ./bin/mnist-cpu ./mnist.ggml ${samples} ) 2>&1 | tee -a $OUT/${ci}-mnist.log |
|---|
| | | |
|---|
| | | set +e |
|---|
| | | } |
|---|
| | | |
|---|
| | | function gg_sum_mnist { |
|---|
| | | gg_printf '### %s\n\n' "${ci}" |
|---|
| | | |
|---|
| | | gg_printf 'MNIST\n' |
|---|
| | | gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | gg_printf '%s\n' "$(cat $OUT/${ci}-mnist.log)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | } |
|---|
| | | |
|---|
| | | # whisper |
|---|
| | | |
|---|
| | | function gg_run_whisper { |
|---|
| | | cd ${SRC} |
|---|
| | | |
|---|
| | | gg_wget models-mnt/whisper/ https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-base.en.bin |
|---|
| | | gg_wget models-mnt/whisper/ https://github.com/ggerganov/whisper.cpp/raw/master/samples/jfk.wav |
|---|
| | | |
|---|
| | | cd build-ci-release |
|---|
| | | |
|---|
| | | set -e |
|---|
| | | |
|---|
| | | path_models="../models-mnt/whisper/" |
|---|
| | | model_f16="${path_models}/ggml-base.en.bin" |
|---|
| | | audio_0="${path_models}/jfk.wav" |
|---|
| | | |
|---|
| | | (time ./bin/whisper -m ${model_f16} -f ${audio_0} ) 2>&1 | tee -a $OUT/${ci}-main.log |
|---|
| | | |
|---|
| | | grep -q "And so my fellow Americans" $OUT/${ci}-main.log |
|---|
| | | |
|---|
| | | set +e |
|---|
| | | } |
|---|
| | | |
|---|
| | | function gg_sum_whisper { |
|---|
| | | gg_printf '### %s\n\n' "${ci}" |
|---|
| | | |
|---|
| | | gg_printf 'Runs short Whisper transcription\n' |
|---|
| | | gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | gg_printf '%s\n' "$(cat $OUT/${ci}-main.log)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | } |
|---|
| | | |
|---|
| | | # sam |
|---|
| | | |
|---|
| | | function gg_run_sam { |
|---|
| | | cd ${SRC} |
|---|
| | | |
|---|
| | | gg_wget models-mnt/sam/ https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth |
|---|
| | | gg_wget models-mnt/sam/ https://raw.githubusercontent.com/YavorGIvanov/sam.cpp/ceafb7467bff7ec98e0c4f952e58a9eb8fd0238b/img.jpg |
|---|
| | | |
|---|
| | | cd build-ci-release |
|---|
| | | |
|---|
| | | set -e |
|---|
| | | |
|---|
| | | path_models="../models-mnt/sam/" |
|---|
| | | model_f16="${path_models}/ggml-model-f16.bin" |
|---|
| | | img_0="${path_models}/img.jpg" |
|---|
| | | |
|---|
| | | python3 ../examples/sam/convert-pth-to-ggml.py ${path_models}/sam_vit_b_01ec64.pth ${path_models}/ 1 |
|---|
| | | |
|---|
| | | (time ./bin/sam -m ${model_f16} -i ${img_0} ) 2>&1 | tee -a $OUT/${ci}-main.log |
|---|
| | | |
|---|
| | | grep -q "bbox (371, 436), (144, 168)" $OUT/${ci}-main.log |
|---|
| | | |
|---|
| | | set +e |
|---|
| | | } |
|---|
| | | |
|---|
| | | function gg_sum_sam { |
|---|
| | | gg_printf '### %s\n\n' "${ci}" |
|---|
| | | |
|---|
| | | gg_printf 'Run SAM\n' |
|---|
| | | gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | gg_printf '%s\n' "$(cat $OUT/${ci}-main.log)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | } |
|---|
| | | |
|---|
| | | # yolo |
|---|
| | | |
|---|
| | | function gg_run_yolo { |
|---|
| | | cd ${SRC} |
|---|
| | | |
|---|
| | | gg_wget models-mnt/yolo/ https://pjreddie.com/media/files/yolov3-tiny.weights |
|---|
| | | gg_wget models-mnt/yolo/ https://raw.githubusercontent.com/pjreddie/darknet/master/data/dog.jpg |
|---|
| | | |
|---|
| | | cd build-ci-release |
|---|
| | | cp -r ../examples/yolo/data . |
|---|
| | | |
|---|
| | | set -e |
|---|
| | | |
|---|
| | | path_models="../models-mnt/yolo/" |
|---|
| | | |
|---|
| | | python3 ../examples/yolo/convert-yolov3-tiny.py ${path_models}/yolov3-tiny.weights |
|---|
| | | |
|---|
| | | (time ./bin/yolov3-tiny -m yolov3-tiny.gguf -i ${path_models}/dog.jpg ) 2>&1 | tee -a $OUT/${ci}-main.log |
|---|
| | | |
|---|
| | | grep -q "dog: 57%" $OUT/${ci}-main.log |
|---|
| | | grep -q "car: 52%" $OUT/${ci}-main.log |
|---|
| | | grep -q "truck: 56%" $OUT/${ci}-main.log |
|---|
| | | grep -q "bicycle: 59%" $OUT/${ci}-main.log |
|---|
| | | |
|---|
| | | set +e |
|---|
| | | } |
|---|
| | | |
|---|
| | | function gg_sum_yolo { |
|---|
| | | gg_printf '### %s\n\n' "${ci}" |
|---|
| | | |
|---|
| | | gg_printf 'Run YOLO\n' |
|---|
| | | gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | gg_printf '%s\n' "$(cat $OUT/${ci}-main.log)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | } |
|---|
| | | |
|---|
| | | # mpt |
|---|
| | | |
|---|
| | | function gg_run_mpt { |
|---|
| | | cd ${SRC} |
|---|
| | | |
|---|
| | | gg_wget models-mnt/mpt/7B/ https://huggingface.co/mosaicml/mpt-7b/raw/main/config.json |
|---|
| | | gg_wget models-mnt/mpt/7B/ https://huggingface.co/mosaicml/mpt-7b/raw/main/tokenizer.json |
|---|
| | | gg_wget models-mnt/mpt/7B/ https://huggingface.co/mosaicml/mpt-7b/raw/main/tokenizer_config.json |
|---|
| | | gg_wget models-mnt/mpt/7B/ https://huggingface.co/mosaicml/mpt-7b/raw/main/pytorch_model.bin.index.json |
|---|
| | | gg_wget models-mnt/mpt/7B/ https://huggingface.co/mosaicml/mpt-7b/raw/main/configuration_mpt.py |
|---|
| | | gg_wget models-mnt/mpt/7B/ https://huggingface.co/mosaicml/mpt-7b/resolve/main/pytorch_model-00001-of-00002.bin |
|---|
| | | gg_wget models-mnt/mpt/7B/ https://huggingface.co/mosaicml/mpt-7b/resolve/main/pytorch_model-00002-of-00002.bin |
|---|
| | | |
|---|
| | | cd build-ci-release |
|---|
| | | |
|---|
| | | set -e |
|---|
| | | |
|---|
| | | path_models="../models-mnt/mpt/7B" |
|---|
| | | model_f16="${path_models}/ggml-model-f16.bin" |
|---|
| | | model_q4_0="${path_models}/ggml-model-q4_0.bin" |
|---|
| | | |
|---|
| | | python3 ../examples/mpt/convert-h5-to-ggml.py ${path_models} 1 |
|---|
| | | ./bin/mpt-quantize ${model_f16} ${model_q4_0} q4_0 |
|---|
| | | |
|---|
| | | (time ./bin/mpt --model ${model_f16} -s 1234 -n 64 -p "I believe the meaning of life is") 2>&1 | tee -a $OUT/${ci}-tg.log |
|---|
| | | (time ./bin/mpt --model ${model_q4_0} -s 1234 -n 64 -p "I believe the meaning of life is") 2>&1 | tee -a $OUT/${ci}-tg.log |
|---|
| | | |
|---|
| | | set +e |
|---|
| | | } |
|---|
| | | |
|---|
| | | function gg_sum_mpt { |
|---|
| | | gg_printf '### %s\n\n' "${ci}" |
|---|
| | | |
|---|
| | | gg_printf 'Runs short MPT text generation\n' |
|---|
| | | gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | gg_printf '%s\n' "$(cat $OUT/${ci}-tg.log)" |
|---|
| | | gg_printf '```\n' |
|---|
| | | } |
|---|
| | | |
|---|
| | | ## main |
|---|
| | | |
|---|
| | | if [ -z $GG_BUILD_LOW_PERF ]; then |
|---|
| | | rm -rf ${SRC}/models-mnt |
|---|
| | | |
|---|
| | | mnt_models=${MNT}/models |
|---|
| | | mkdir -p ${mnt_models} |
|---|
| | | ln -sfn ${mnt_models} ${SRC}/models-mnt |
|---|
| | | fi |
|---|
| | | |
|---|
| | | python3 -m pip install -r ${SRC}/requirements.txt |
|---|
| | | |
|---|
| | | ret=0 |
|---|
| | | |
|---|
| | | test $ret -eq 0 && gg_run ctest_debug |
|---|
| | | test $ret -eq 0 && gg_run ctest_release |
|---|
| | | |
|---|
| | | if [ ! -z ${GG_BUILD_METAL} ]; then |
|---|
| | | export GGML_METAL_PATH_RESOURCES="${SRC}/build-ci-release/bin" |
|---|
| | | fi |
|---|
| | | |
|---|
| | | test $ret -eq 0 && gg_run gpt_2 |
|---|
| | | test $ret -eq 0 && gg_run mnist |
|---|
| | | test $ret -eq 0 && gg_run whisper |
|---|
| | | test $ret -eq 0 && gg_run sam |
|---|
| | | test $ret -eq 0 && gg_run yolo |
|---|
| | | |
|---|
| | | if [ -z $GG_BUILD_LOW_PERF ]; then |
|---|
| | | if [ -z ${GG_BUILD_VRAM_GB} ] || [ ${GG_BUILD_VRAM_GB} -ge 16 ]; then |
|---|
| | | test $ret -eq 0 && gg_run mpt |
|---|
| | | fi |
|---|
| | | fi |
|---|
| | | |
|---|
| | | exit $ret |
|---|
| New file |
| | |
|---|
| | | # Add new build types |
|---|
| | | |
|---|
| | | # ReleaseGG - Release with enabled asserts |
|---|
| | | |
|---|
| | | SET(CMAKE_CXX_FLAGS_RELEASEGG |
|---|
| | | "-O3" |
|---|
| | | CACHE STRING "Flags used by the c++ compiler during release builds with enabled asserts." |
|---|
| | | FORCE ) |
|---|
| | | SET(CMAKE_C_FLAGS_RELEASEGG |
|---|
| | | "-O3" |
|---|
| | | CACHE STRING "Flags used by the compiler during release builds with enabled asserts." |
|---|
| | | FORCE ) |
|---|
| | | SET(CMAKE_EXE_LINKER_FLAGS_RELEASEGG |
|---|
| | | "" |
|---|
| | | CACHE STRING "Flags used for linking binaries during release builds with enabled asserts." |
|---|
| | | FORCE ) |
|---|
| | | SET(CMAKE_SHARED_LINKER_FLAGS_RELEASEGG |
|---|
| | | "" |
|---|
| | | CACHE STRING "Flags used by the shared libraries linker during release builds with enabled asserts." |
|---|
| | | FORCE ) |
|---|
| | | MARK_AS_ADVANCED( |
|---|
| | | CMAKE_CXX_FLAGS_RELEASEGG |
|---|
| | | CMAKE_C_FLAGS_RELEASEGG |
|---|
| | | CMAKE_EXE_LINKER_FLAGS_RELEASEGG |
|---|
| | | CMAKE_SHARED_LINKER_FLAGS_RELEASEGG ) |
|---|
| | | |
|---|
| | | # RelWithDebInfoGG - RelWithDebInfo with enabled asserts |
|---|
| | | |
|---|
| | | SET(CMAKE_CXX_FLAGS_RELWITHDEBINFOGG |
|---|
| | | "-O2 -g" |
|---|
| | | CACHE STRING "Flags used by the c++ compiler during release builds with debug symbols and enabled asserts." |
|---|
| | | FORCE ) |
|---|
| | | SET(CMAKE_C_FLAGS_RELWITHDEBINFOGG |
|---|
| | | "-O2 -g" |
|---|
| | | CACHE STRING "Flags used by the compiler during release builds with debug symbols and enabled asserts." |
|---|
| | | FORCE ) |
|---|
| | | SET(CMAKE_EXE_LINKER_FLAGS_RELWITHDEBINFOGG |
|---|
| | | "" |
|---|
| | | CACHE STRING "Flags used for linking binaries during release builds with debug symbols and enabled asserts." |
|---|
| | | FORCE ) |
|---|
| | | SET(CMAKE_SHARED_LINKER_FLAGS_RELWITHDEBINFOGG |
|---|
| | | "" |
|---|
| | | CACHE STRING "Flags used by the shared libraries linker during release builds with debug symbols and enabled asserts." |
|---|
| | | FORCE ) |
|---|
| | | MARK_AS_ADVANCED( |
|---|
| | | CMAKE_CXX_FLAGS_RELWITHDEBINFOGG |
|---|
| | | CMAKE_C_FLAGS_RELWITHDEBINFOGG |
|---|
| | | CMAKE_EXE_LINKER_FLAGS_RELWITHDEBINFOGG |
|---|
| | | CMAKE_SHARED_LINKER_FLAGS_RELWITHDEBINFOGG ) |
|---|
| | | |
|---|
| | | if (NOT XCODE AND NOT MSVC AND NOT CMAKE_BUILD_TYPE) |
|---|
| | | set(CMAKE_BUILD_TYPE Release CACHE STRING "Build type" FORCE) |
|---|
| | | set_property(CACHE CMAKE_BUILD_TYPE PROPERTY STRINGS "Debug" "Release" "MinSizeRel" "RelWithDebInfo" "ReleaseGG" "RelWithDebInfoGG") |
|---|
| | | endif() |
|---|
| New file |
| | |
|---|
| | | find_package(Git) |
|---|
| | | |
|---|
| | | # the commit's SHA1 |
|---|
| | | execute_process(COMMAND |
|---|
| | | "${GIT_EXECUTABLE}" describe --match=NeVeRmAtCh --always --abbrev=8 |
|---|
| | | WORKING_DIRECTORY "${CMAKE_SOURCE_DIR}" |
|---|
| | | OUTPUT_VARIABLE GIT_SHA1 |
|---|
| | | ERROR_QUIET OUTPUT_STRIP_TRAILING_WHITESPACE) |
|---|
| | | |
|---|
| | | # the date of the commit |
|---|
| | | execute_process(COMMAND |
|---|
| | | "${GIT_EXECUTABLE}" log -1 --format=%ad --date=local |
|---|
| | | WORKING_DIRECTORY "${CMAKE_SOURCE_DIR}" |
|---|
| | | OUTPUT_VARIABLE GIT_DATE |
|---|
| | | ERROR_QUIET OUTPUT_STRIP_TRAILING_WHITESPACE) |
|---|
| | | |
|---|
| | | # the subject of the commit |
|---|
| | | execute_process(COMMAND |
|---|
| | | "${GIT_EXECUTABLE}" log -1 --format=%s |
|---|
| | | WORKING_DIRECTORY "${CMAKE_SOURCE_DIR}" |
|---|
| | | OUTPUT_VARIABLE GIT_COMMIT_SUBJECT |
|---|
| | | ERROR_QUIET OUTPUT_STRIP_TRAILING_WHITESPACE) |
|---|
| New file |
| | |
|---|
| | | # GGUF |
|---|
| | | |
|---|
| | | GGUF is a file format for storing models for inference with GGML and executors based on GGML. GGUF is a binary format that is designed for fast loading and saving of models, and for ease of reading. Models are traditionally developed using PyTorch or another framework, and then converted to GGUF for use in GGML. |
|---|
| | | |
|---|
| | | It is a successor file format to GGML, GGMF and GGJT, and is designed to be unambiguous by containing all the information needed to load a model. It is also designed to be extensible, so that new information can be added to models without breaking compatibility. |
|---|
| | | |
|---|
| | | For more information about the motivation behind GGUF, see [Historical State of Affairs](#historical-state-of-affairs). |
|---|
| | | |
|---|
| | | ## Specification |
|---|
| | | |
|---|
| | | GGUF is a format based on the existing GGJT, but makes a few changes to the format to make it more extensible and easier to use. The following features are desired: |
|---|
| | | |
|---|
| | | - Single-file deployment: they can be easily distributed and loaded, and do not require any external files for additional information. |
|---|
| | | - Extensible: new features can be added to GGML-based executors/new information can be added to GGUF models without breaking compatibility with existing models. |
|---|
| | | - `mmap` compatibility: models can be loaded using `mmap` for fast loading and saving. |
|---|
| | | - Easy to use: models can be easily loaded and saved using a small amount of code, with no need for external libraries, regardless of the language used. |
|---|
| | | - Full information: all information needed to load a model is contained in the model file, and no additional information needs to be provided by the user. |
|---|
| | | |
|---|
| | | The key difference between GGJT and GGUF is the use of a key-value structure for the hyperparameters (now referred to as metadata), rather than a list of untyped values. This allows for new metadata to be added without breaking compatibility with existing models, and to annotate the model with additional information that may be useful for inference or for identifying the model. |
|---|
| | | |
|---|
| | | ### File Structure |
|---|
| | | |
|---|
| | | GGUF files are structured as follows. They use a global alignment specified in the `general.alignment` metadata field, referred to as `ALIGNMENT` below. Where required, the file is padded with `0x00` bytes to the next multiple of `general.alignment`. |
|---|
| | | |
|---|
| | | Fields, including arrays, are written sequentially without alignment unless otherwise specified. |
|---|
| | | |
|---|
| | | Models are little-endian by default. They can also come in big-endian for use with big-endian computers; in this case, all values (including metadata values and tensors) will also be big-endian. At the time of writing, there is no way to determine if a model is big-endian; this may be rectified in future versions. If no additional information is provided, assume the model is little-endian. |
|---|
| | | |
|---|
| | | ```c |
|---|
| | | enum ggml_type: uint32_t { |
|---|
| | | GGML_TYPE_F32 = 0, |
|---|
| | | GGML_TYPE_F16 = 1, |
|---|
| | | GGML_TYPE_Q4_0 = 2, |
|---|
| | | GGML_TYPE_Q4_1 = 3, |
|---|
| | | // GGML_TYPE_Q4_2 = 4, support has been removed |
|---|
| | | // GGML_TYPE_Q4_3 (5) support has been removed |
|---|
| | | GGML_TYPE_Q5_0 = 6, |
|---|
| | | GGML_TYPE_Q5_1 = 7, |
|---|
| | | GGML_TYPE_Q8_0 = 8, |
|---|
| | | GGML_TYPE_Q8_1 = 9, |
|---|
| | | // k-quantizations |
|---|
| | | GGML_TYPE_Q2_K = 10, |
|---|
| | | GGML_TYPE_Q3_K = 11, |
|---|
| | | GGML_TYPE_Q4_K = 12, |
|---|
| | | GGML_TYPE_Q5_K = 13, |
|---|
| | | GGML_TYPE_Q6_K = 14, |
|---|
| | | GGML_TYPE_Q8_K = 15, |
|---|
| | | GGML_TYPE_I8, |
|---|
| | | GGML_TYPE_I16, |
|---|
| | | GGML_TYPE_I32, |
|---|
| | | GGML_TYPE_COUNT, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | enum gguf_metadata_value_type: uint32_t { |
|---|
| | | // The value is a 8-bit unsigned integer. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_UINT8 = 0, |
|---|
| | | // The value is a 8-bit signed integer. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_INT8 = 1, |
|---|
| | | // The value is a 16-bit unsigned little-endian integer. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_UINT16 = 2, |
|---|
| | | // The value is a 16-bit signed little-endian integer. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_INT16 = 3, |
|---|
| | | // The value is a 32-bit unsigned little-endian integer. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_UINT32 = 4, |
|---|
| | | // The value is a 32-bit signed little-endian integer. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_INT32 = 5, |
|---|
| | | // The value is a 32-bit IEEE754 floating point number. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_FLOAT32 = 6, |
|---|
| | | // The value is a boolean. |
|---|
| | | // 1-byte value where 0 is false and 1 is true. |
|---|
| | | // Anything else is invalid, and should be treated as either the model being invalid or the reader being buggy. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_BOOL = 7, |
|---|
| | | // The value is a UTF-8 non-null-terminated string, with length prepended. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_STRING = 8, |
|---|
| | | // The value is an array of other values, with the length and type prepended. |
|---|
| | | /// |
|---|
| | | // Arrays can be nested, and the length of the array is the number of elements in the array, not the number of bytes. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_ARRAY = 9, |
|---|
| | | // The value is a 64-bit unsigned little-endian integer. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_UINT64 = 10, |
|---|
| | | // The value is a 64-bit signed little-endian integer. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_INT64 = 11, |
|---|
| | | // The value is a 64-bit IEEE754 floating point number. |
|---|
| | | GGUF_METADATA_VALUE_TYPE_FLOAT64 = 12, |
|---|
| | | } |
|---|
| | | |
|---|
| | | // A string in GGUF. |
|---|
| | | struct gguf_string_t { |
|---|
| | | // The length of the string, in bytes. |
|---|
| | | uint64_t len; |
|---|
| | | // The string as a UTF-8 non-null-terminated string. |
|---|
| | | char string[len]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | union gguf_metadata_value_t { |
|---|
| | | uint8_t uint8; |
|---|
| | | int8_t int8; |
|---|
| | | uint16_t uint16; |
|---|
| | | int16_t int16; |
|---|
| | | uint32_t uint32; |
|---|
| | | int32_t int32; |
|---|
| | | float float32; |
|---|
| | | uint64_t uint64; |
|---|
| | | int64_t int64; |
|---|
| | | double float64; |
|---|
| | | bool bool_; |
|---|
| | | gguf_string_t string; |
|---|
| | | struct { |
|---|
| | | // Any value type is valid, including arrays. |
|---|
| | | gguf_metadata_value_type type; |
|---|
| | | // Number of elements, not bytes |
|---|
| | | uint64_t len; |
|---|
| | | // The array of values. |
|---|
| | | gguf_metadata_value_t array[len]; |
|---|
| | | } array; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gguf_metadata_kv_t { |
|---|
| | | // The key of the metadata. It is a standard GGUF string, with the following caveats: |
|---|
| | | // - It must be a valid ASCII string. |
|---|
| | | // - It must be a hierarchical key, where each segment is `lower_snake_case` and separated by a `.`. |
|---|
| | | // - It must be at most 2^16-1/65535 bytes long. |
|---|
| | | // Any keys that do not follow these rules are invalid. |
|---|
| | | gguf_string_t key; |
|---|
| | | |
|---|
| | | // The type of the value. |
|---|
| | | // Must be one of the `gguf_metadata_value_type` values. |
|---|
| | | gguf_metadata_value_type value_type; |
|---|
| | | // The value. |
|---|
| | | gguf_metadata_value_t value; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gguf_header_t { |
|---|
| | | // Magic number to announce that this is a GGUF file. |
|---|
| | | // Must be `GGUF` at the byte level: `0x47` `0x47` `0x55` `0x46`. |
|---|
| | | // Your executor might do little-endian byte order, so it might be |
|---|
| | | // check for 0x46554747 and letting the endianness cancel out. |
|---|
| | | // Consider being *very* explicit about the byte order here. |
|---|
| | | uint32_t magic; |
|---|
| | | // The version of the format implemented. |
|---|
| | | // Must be `3` for version described in this spec, which introduces big-endian support. |
|---|
| | | // |
|---|
| | | // This version should only be increased for structural changes to the format. |
|---|
| | | // Changes that do not affect the structure of the file should instead update the metadata |
|---|
| | | // to signify the change. |
|---|
| | | uint32_t version; |
|---|
| | | // The number of tensors in the file. |
|---|
| | | // This is explicit, instead of being included in the metadata, to ensure it is always present |
|---|
| | | // for loading the tensors. |
|---|
| | | uint64_t tensor_count; |
|---|
| | | // The number of metadata key-value pairs. |
|---|
| | | uint64_t metadata_kv_count; |
|---|
| | | // The metadata key-value pairs. |
|---|
| | | gguf_metadata_kv_t metadata_kv[metadata_kv_count]; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | uint64_t align_offset(uint64_t offset) { |
|---|
| | | return offset + (ALIGNMENT - (offset % ALIGNMENT)) % ALIGNMENT; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct gguf_tensor_info_t { |
|---|
| | | // The name of the tensor. It is a standard GGUF string, with the caveat that |
|---|
| | | // it must be at most 64 bytes long. |
|---|
| | | gguf_string_t name; |
|---|
| | | // The number of dimensions in the tensor. |
|---|
| | | // Currently at most 4, but this may change in the future. |
|---|
| | | uint32_t n_dimensions; |
|---|
| | | // The dimensions of the tensor. |
|---|
| | | uint64_t dimensions[n_dimensions]; |
|---|
| | | // The type of the tensor. |
|---|
| | | ggml_type type; |
|---|
| | | // The offset of the tensor's data in this file in bytes. |
|---|
| | | // |
|---|
| | | // This offset is relative to `tensor_data`, not to the start |
|---|
| | | // of the file, to make it easier for writers to write the file. |
|---|
| | | // Readers should consider exposing this offset relative to the |
|---|
| | | // file to make it easier to read the data. |
|---|
| | | // |
|---|
| | | // Must be a multiple of `ALIGNMENT`. That is, `align_offset(offset) == offset`. |
|---|
| | | uint64_t offset; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gguf_file_t { |
|---|
| | | // The header of the file. |
|---|
| | | gguf_header_t header; |
|---|
| | | |
|---|
| | | // Tensor infos, which can be used to locate the tensor data. |
|---|
| | | gguf_tensor_info_t tensor_infos[header.tensor_count]; |
|---|
| | | |
|---|
| | | // Padding to the nearest multiple of `ALIGNMENT`. |
|---|
| | | // |
|---|
| | | // That is, if `sizeof(header) + sizeof(tensor_infos)` is not a multiple of `ALIGNMENT`, |
|---|
| | | // this padding is added to make it so. |
|---|
| | | // |
|---|
| | | // This can be calculated as `align_offset(position) - position`, where `position` is |
|---|
| | | // the position of the end of `tensor_infos` (i.e. `sizeof(header) + sizeof(tensor_infos)`). |
|---|
| | | uint8_t _padding[]; |
|---|
| | | |
|---|
| | | // Tensor data. |
|---|
| | | // |
|---|
| | | // This is arbitrary binary data corresponding to the weights of the model. This data should be close |
|---|
| | | // or identical to the data in the original model file, but may be different due to quantization or |
|---|
| | | // other optimizations for inference. Any such deviations should be recorded in the metadata or as |
|---|
| | | // part of the architecture definition. |
|---|
| | | // |
|---|
| | | // Each tensor's data must be stored within this array, and located through its `tensor_infos` entry. |
|---|
| | | // The offset of each tensor's data must be a multiple of `ALIGNMENT`, and the space between tensors |
|---|
| | | // should be padded to `ALIGNMENT` bytes. |
|---|
| | | uint8_t tensor_data[]; |
|---|
| | | }; |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Standardized key-value pairs |
|---|
| | | |
|---|
| | | The following key-value pairs are standardized. This list may grow in the future as more use cases are discovered. Where possible, names are shared with the original model definitions to make it easier to map between the two. |
|---|
| | | |
|---|
| | | Not all of these are required, but they are all recommended. Keys that are required are bolded. For omitted pairs, the reader should assume that the value is unknown and either default or error as appropriate. |
|---|
| | | |
|---|
| | | The community can develop their own key-value pairs to carry additional data. However, these should be namespaced with the relevant community name to avoid collisions. For example, the `rustformers` community might use `rustformers.` as a prefix for all of their keys. |
|---|
| | | |
|---|
| | | If a particular community key is widely used, it may be promoted to a standardized key. |
|---|
| | | |
|---|
| | | By convention, most counts/lengths/etc are `uint64` unless otherwise specified. This is to allow for larger models to be supported in the future. Some models may use `uint32` for their values; it is recommended that readers support both. |
|---|
| | | |
|---|
| | | ### General |
|---|
| | | |
|---|
| | | #### Required |
|---|
| | | |
|---|
| | | - **`general.architecture: string`**: describes what architecture this model implements. All lowercase ASCII, with only `[a-z0-9]+` characters allowed. Known values include: |
|---|
| | | - `llama` |
|---|
| | | - `mpt` |
|---|
| | | - `gptneox` |
|---|
| | | - `gptj` |
|---|
| | | - `gpt2` |
|---|
| | | - `bloom` |
|---|
| | | - `falcon` |
|---|
| | | - `rwkv` |
|---|
| | | - **`general.quantization_version: uint32`**: The version of the quantization format. Not required if the model is not quantized (i.e. no tensors are quantized). If any tensors are quantized, this _must_ be present. This is separate to the quantization scheme of the tensors itself; the quantization version may change without changing the scheme's name (e.g. the quantization scheme is Q5_K, and the quantization version is 4). |
|---|
| | | - **`general.alignment: uint32`**: the global alignment to use, as described above. This can vary to allow for different alignment schemes, but it must be a multiple of 8. Some writers may not write the alignment. If the alignment is **not** specified, assume it is `32`. |
|---|
| | | |
|---|
| | | #### General metadata |
|---|
| | | |
|---|
| | | - `general.name`: The name of the model. This should be a human-readable name that can be used to identify the model. It should be unique within the community that the model is defined in. |
|---|
| | | - `general.author`: The author of the model. |
|---|
| | | - `general.url`: URL to the model's homepage. This can be a GitHub repo, a paper, etc. |
|---|
| | | - `general.description: string`: free-form description of the model including anything that isn't covered by the other fields |
|---|
| | | - `general.license: string`: License of the model, expressed as a [SPDX license expression](https://spdx.github.io/spdx-spec/v2-draft/SPDX-license-expressions/) (e.g. `"MIT OR Apache-2.0`). Do not include any other information, such as the license text or the URL to the license. |
|---|
| | | - `general.file_type: uint32`: An enumerated value describing the type of the majority of the tensors in the file. Optional; can be inferred from the tensor types. |
|---|
| | | - `ALL_F32 = 0` |
|---|
| | | - `MOSTLY_F16 = 1` |
|---|
| | | - `MOSTLY_Q4_0 = 2` |
|---|
| | | - `MOSTLY_Q4_1 = 3` |
|---|
| | | - `MOSTLY_Q4_1_SOME_F16 = 4` |
|---|
| | | - `MOSTLY_Q4_2 = 5` (support removed) |
|---|
| | | - `MOSTLY_Q4_3 = 6` (support removed) |
|---|
| | | - `MOSTLY_Q8_0 = 7` |
|---|
| | | - `MOSTLY_Q5_0 = 8` |
|---|
| | | - `MOSTLY_Q5_1 = 9` |
|---|
| | | - `MOSTLY_Q2_K = 10` |
|---|
| | | - `MOSTLY_Q3_K_S = 11` |
|---|
| | | - `MOSTLY_Q3_K_M = 12` |
|---|
| | | - `MOSTLY_Q3_K_L = 13` |
|---|
| | | - `MOSTLY_Q4_K_S = 14` |
|---|
| | | - `MOSTLY_Q4_K_M = 15` |
|---|
| | | - `MOSTLY_Q5_K_S = 16` |
|---|
| | | - `MOSTLY_Q5_K_M = 17` |
|---|
| | | - `MOSTLY_Q6_K = 18` |
|---|
| | | |
|---|
| | | #### Source metadata |
|---|
| | | |
|---|
| | | Information about where this model came from. This is useful for tracking the provenance of the model, and for finding the original source if the model is modified. For a model that was converted from GGML, for example, these keys would point to the model that was converted from. |
|---|
| | | |
|---|
| | | - `general.source.url: string`: URL to the source of the model. Can be a GitHub repo, a paper, etc. |
|---|
| | | - `general.source.huggingface.repository: string`: Hugging Face model repository that this model is either hosted on or based on |
|---|
| | | |
|---|
| | | ### LLM |
|---|
| | | |
|---|
| | | In the following, `[llm]` is used to fill in for the name of a specific LLM architecture. For example, `llama` for LLaMA, `mpt` for MPT, etc. If mentioned in an architecture's section, it is required for that architecture, but not all keys are required for all architectures. Consult the relevant section for more information. |
|---|
| | | |
|---|
| | | - `[llm].context_length: uint64`: Also known as `n_ctx`. length of the context (in tokens) that the model was trained on. For most architectures, this is the hard limit on the length of the input. Architectures, like RWKV, that are not reliant on transformer-style attention may be able to handle larger inputs, but this is not guaranteed. |
|---|
| | | - `[llm].embedding_length: uint64`: Also known as `n_embd`. Embedding layer size. |
|---|
| | | - `[llm].block_count: uint64`: The number of blocks of attention+feed-forward layers (i.e. the bulk of the LLM). Does not include the input or embedding layers. |
|---|
| | | - `[llm].feed_forward_length: uint64`: Also known as `n_ff`. The length of the feed-forward layer. |
|---|
| | | - `[llm].use_parallel_residual: bool`: Whether or not the parallel residual logic should be used. |
|---|
| | | - `[llm].tensor_data_layout: string`: When a model is converted to GGUF, tensors may be rearranged to improve performance. This key describes the layout of the tensor data. This is not required; if not present, it is assumed to be `reference`. |
|---|
| | | - `reference`: tensors are laid out in the same order as the original model |
|---|
| | | - further options can be found for each architecture in their respective sections |
|---|
| | | - `[llm].expert_count: uint32`: Number of experts in MoE models (optional for non-MoE arches). |
|---|
| | | - `[llm].expert_used_count: uint32`: Number of experts used during each token token evaluation (optional for non-MoE arches). |
|---|
| | | |
|---|
| | | #### Attention |
|---|
| | | |
|---|
| | | - `[llm].attention.head_count: uint64`: Also known as `n_head`. Number of attention heads. |
|---|
| | | - `[llm].attention.head_count_kv: uint64`: The number of heads per group used in Grouped-Query-Attention. If not present or if present and equal to `[llm].attention.head_count`, the model does not use GQA. |
|---|
| | | - `[llm].attention.max_alibi_bias: float32`: The maximum bias to use for ALiBI. |
|---|
| | | - `[llm].attention.clamp_kqv: float32`: Value (`C`) to clamp the values of the `Q`, `K`, and `V` tensors between (`[-C, C]`). |
|---|
| | | - `[llm].attention.layer_norm_epsilon: float32`: Layer normalization epsilon. |
|---|
| | | - `[llm].attention.layer_norm_rms_epsilon: float32`: Layer RMS normalization epsilon. |
|---|
| | | - `[llm].attention.key_length: uint32`: The optional size of a key head, $d_k$. If not specified, it will be `n_embd / n_head`. |
|---|
| | | - `[llm].attention.value_length: uint32`: The optional size of a value head, $d_v$. If not specified, it will be `n_embd / n_head`. |
|---|
| | | |
|---|
| | | #### RoPE |
|---|
| | | |
|---|
| | | - `[llm].rope.dimension_count: uint64`: The number of rotary dimensions for RoPE. |
|---|
| | | - `[llm].rope.freq_base: float32`: The base frequency for RoPE. |
|---|
| | | |
|---|
| | | ##### Scaling |
|---|
| | | |
|---|
| | | The following keys describe RoPE scaling parameters: |
|---|
| | | |
|---|
| | | - `[llm].rope.scaling.type: string`: Can be `none`, `linear`, or `yarn`. |
|---|
| | | - `[llm].rope.scaling.factor: float32`: A scale factor for RoPE to adjust the context length. |
|---|
| | | - `[llm].rope.scaling.original_context_length: uint32_t`: The original context length of the base model. |
|---|
| | | - `[llm].rope.scaling.finetuned: bool`: True if model has been finetuned with RoPE scaling. |
|---|
| | | |
|---|
| | | Note that older models may not have these keys, and may instead use the following key: |
|---|
| | | |
|---|
| | | - `[llm].rope.scale_linear: float32`: A linear scale factor for RoPE to adjust the context length. |
|---|
| | | |
|---|
| | | It is recommended that models use the newer keys if possible, as they are more flexible and allow for more complex scaling schemes. Executors will need to support both indefinitely. |
|---|
| | | |
|---|
| | | #### Models |
|---|
| | | |
|---|
| | | The following sections describe the metadata for each model architecture. Each key specified _must_ be present. |
|---|
| | | |
|---|
| | | ##### LLaMA |
|---|
| | | |
|---|
| | | - `llama.context_length` |
|---|
| | | - `llama.embedding_length` |
|---|
| | | - `llama.block_count` |
|---|
| | | - `llama.feed_forward_length` |
|---|
| | | - `llama.rope.dimension_count` |
|---|
| | | - `llama.attention.head_count` |
|---|
| | | - `llama.attention.layer_norm_rms_epsilon` |
|---|
| | | |
|---|
| | | ###### Optional |
|---|
| | | |
|---|
| | | - `llama.rope.scale` |
|---|
| | | - `llama.attention.head_count_kv` |
|---|
| | | - `llama.tensor_data_layout`: |
|---|
| | | - `Meta AI original pth`: |
|---|
| | | ```python |
|---|
| | | def permute(weights: NDArray, n_head: int) -> NDArray: |
|---|
| | | return (weights.reshape(n_head, 2, weights.shape[0] // n_head // 2, *weights.shape[1:]) |
|---|
| | | .swapaxes(1, 2) |
|---|
| | | .reshape(weights.shape)) |
|---|
| | | ``` |
|---|
| | | - `llama.expert_count` |
|---|
| | | - `llama.expert_used_count` |
|---|
| | | |
|---|
| | | ##### MPT |
|---|
| | | |
|---|
| | | - `mpt.context_length` |
|---|
| | | - `mpt.embedding_length` |
|---|
| | | - `mpt.block_count` |
|---|
| | | - `mpt.attention.head_count` |
|---|
| | | - `mpt.attention.alibi_bias_max` |
|---|
| | | - `mpt.attention.clip_kqv` |
|---|
| | | - `mpt.attention.layer_norm_epsilon` |
|---|
| | | |
|---|
| | | ##### GPT-NeoX |
|---|
| | | |
|---|
| | | - `gptneox.context_length` |
|---|
| | | - `gptneox.embedding_length` |
|---|
| | | - `gptneox.block_count` |
|---|
| | | - `gptneox.use_parallel_residual` |
|---|
| | | - `gptneox.rope.dimension_count` |
|---|
| | | - `gptneox.attention.head_count` |
|---|
| | | - `gptneox.attention.layer_norm_epsilon` |
|---|
| | | |
|---|
| | | ###### Optional |
|---|
| | | |
|---|
| | | - `gptneox.rope.scale` |
|---|
| | | |
|---|
| | | ##### GPT-J |
|---|
| | | |
|---|
| | | - `gptj.context_length` |
|---|
| | | - `gptj.embedding_length` |
|---|
| | | - `gptj.block_count` |
|---|
| | | - `gptj.rope.dimension_count` |
|---|
| | | - `gptj.attention.head_count` |
|---|
| | | - `gptj.attention.layer_norm_epsilon` |
|---|
| | | |
|---|
| | | ###### Optional |
|---|
| | | |
|---|
| | | - `gptj.rope.scale` |
|---|
| | | |
|---|
| | | ##### GPT-2 |
|---|
| | | |
|---|
| | | - `gpt2.context_length` |
|---|
| | | - `gpt2.embedding_length` |
|---|
| | | - `gpt2.block_count` |
|---|
| | | - `gpt2.attention.head_count` |
|---|
| | | - `gpt2.attention.layer_norm_epsilon` |
|---|
| | | |
|---|
| | | ##### BLOOM |
|---|
| | | |
|---|
| | | - `bloom.context_length` |
|---|
| | | - `bloom.embedding_length` |
|---|
| | | - `bloom.block_count` |
|---|
| | | - `bloom.feed_forward_length` |
|---|
| | | - `bloom.attention.head_count` |
|---|
| | | - `bloom.attention.layer_norm_epsilon` |
|---|
| | | |
|---|
| | | ##### Falcon |
|---|
| | | |
|---|
| | | - `falcon.context_length` |
|---|
| | | - `falcon.embedding_length` |
|---|
| | | - `falcon.block_count` |
|---|
| | | - `falcon.attention.head_count` |
|---|
| | | - `falcon.attention.head_count_kv` |
|---|
| | | - `falcon.attention.use_norm` |
|---|
| | | - `falcon.attention.layer_norm_epsilon` |
|---|
| | | |
|---|
| | | ###### Optional |
|---|
| | | |
|---|
| | | - `falcon.tensor_data_layout`: |
|---|
| | | |
|---|
| | | - `jploski` (author of the original GGML implementation of Falcon): |
|---|
| | | |
|---|
| | | ```python |
|---|
| | | # The original query_key_value tensor contains n_head_kv "kv groups", |
|---|
| | | # each consisting of n_head/n_head_kv query weights followed by one key |
|---|
| | | # and one value weight (shared by all query heads in the kv group). |
|---|
| | | # This layout makes it a big pain to work with in GGML. |
|---|
| | | # So we rearrange them here,, so that we have n_head query weights |
|---|
| | | # followed by n_head_kv key weights followed by n_head_kv value weights, |
|---|
| | | # in contiguous fashion. |
|---|
| | | |
|---|
| | | if "query_key_value" in src: |
|---|
| | | qkv = model[src].view( |
|---|
| | | n_head_kv, n_head // n_head_kv + 2, head_dim, head_dim * n_head) |
|---|
| | | |
|---|
| | | q = qkv[:, :-2 ].reshape(n_head * head_dim, head_dim * n_head) |
|---|
| | | k = qkv[:, [-2]].reshape(n_head_kv * head_dim, head_dim * n_head) |
|---|
| | | v = qkv[:, [-1]].reshape(n_head_kv * head_dim, head_dim * n_head) |
|---|
| | | |
|---|
| | | model[src] = torch.cat((q,k,v)).reshape_as(model[src]) |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ##### RWKV |
|---|
| | | |
|---|
| | | The vocabulary size is the same as the number of rows in the `head` matrix. |
|---|
| | | |
|---|
| | | - `rwkv.architecture_version: uint32`: The only allowed value currently is 4. Version 5 is expected to appear some time in the future. |
|---|
| | | - `rwkv.context_length: uint64`: Length of the context used during training or fine-tuning. RWKV is able to handle larger context than this limit, but the output quality may suffer. |
|---|
| | | - `rwkv.block_count: uint64` |
|---|
| | | - `rwkv.embedding_length: uint64` |
|---|
| | | - `rwkv.feed_forward_length: uint64` |
|---|
| | | |
|---|
| | | ##### Whisper |
|---|
| | | |
|---|
| | | Keys that do not have types defined should be assumed to share definitions with `llm.` keys. |
|---|
| | | (For example, `whisper.context_length` is equivalent to `llm.context_length`.) |
|---|
| | | This is because they are both transformer models. |
|---|
| | | |
|---|
| | | - `whisper.encoder.context_length` |
|---|
| | | - `whisper.encoder.embedding_length` |
|---|
| | | - `whisper.encoder.block_count` |
|---|
| | | - `whisper.encoder.mels_count: uint64` |
|---|
| | | - `whisper.encoder.attention.head_count` |
|---|
| | | |
|---|
| | | - `whisper.decoder.context_length` |
|---|
| | | - `whisper.decoder.embedding_length` |
|---|
| | | - `whisper.decoder.block_count` |
|---|
| | | - `whisper.decoder.attention.head_count` |
|---|
| | | |
|---|
| | | #### Prompting |
|---|
| | | |
|---|
| | | **TODO**: Include prompt format, and/or metadata about how it should be used (instruction, conversation, autocomplete, etc). |
|---|
| | | |
|---|
| | | ### LoRA |
|---|
| | | |
|---|
| | | **TODO**: Figure out what metadata is needed for LoRA. Probably desired features: |
|---|
| | | |
|---|
| | | - match an existing model exactly, so that it can't be misapplied |
|---|
| | | - be marked as a LoRA so executors won't try to run it by itself |
|---|
| | | |
|---|
| | | Should this be an architecture, or should it share the details of the original model with additional fields to mark it as a LoRA? |
|---|
| | | |
|---|
| | | ### Tokenizer |
|---|
| | | |
|---|
| | | The following keys are used to describe the tokenizer of the model. It is recommended that model authors support as many of these as possible, as it will allow for better tokenization quality with supported executors. |
|---|
| | | |
|---|
| | | #### GGML |
|---|
| | | |
|---|
| | | GGML supports an embedded vocabulary that enables inference of the model, but implementations of tokenization using this vocabulary (i.e. `llama.cpp`'s tokenizer) may have lower accuracy than the original tokenizer used for the model. When a more accurate tokenizer is available and supported, it should be used instead. |
|---|
| | | |
|---|
| | | It is not guaranteed to be standardized across models, and may change in the future. It is recommended that model authors use a more standardized tokenizer if possible. |
|---|
| | | |
|---|
| | | - `tokenizer.ggml.model: string`: The name of the tokenizer model. |
|---|
| | | - `llama`: Llama style SentencePiece (tokens and scores extracted from HF `tokenizer.model`) |
|---|
| | | - `replit`: Replit style SentencePiece (tokens and scores extracted from HF `spiece.model`) |
|---|
| | | - `gpt2`: GPT-2 / GPT-NeoX style BPE (tokens extracted from HF `tokenizer.json`) |
|---|
| | | - `rwkv`: RWKV tokenizer |
|---|
| | | - `tokenizer.ggml.tokens: array[string]`: A list of tokens indexed by the token ID used by the model. |
|---|
| | | - `tokenizer.ggml.scores: array[float32]`: If present, the score/probability of each token. If not present, all tokens are assumed to have equal probability. If present, it must have the same length and index as `tokens`. |
|---|
| | | - `tokenizer.ggml.token_type: array[int32]`: The token type (1=normal, 2=unknown, 3=control, 4=user defined, 5=unused, 6=byte). If present, it must have the same length and index as `tokens`. |
|---|
| | | - `tokenizer.ggml.merges: array[string]`: If present, the merges of the tokenizer. If not present, the tokens are assumed to be atomic. |
|---|
| | | - `tokenizer.ggml.added_tokens: array[string]`: If present, tokens that were added after training. |
|---|
| | | |
|---|
| | | ##### Special tokens |
|---|
| | | |
|---|
| | | - `tokenizer.ggml.bos_token_id: uint32`: Beginning of sequence marker |
|---|
| | | - `tokenizer.ggml.eos_token_id: uint32`: End of sequence marker |
|---|
| | | - `tokenizer.ggml.unknown_token_id: uint32`: Unknown token |
|---|
| | | - `tokenizer.ggml.separator_token_id: uint32`: Separator token |
|---|
| | | - `tokenizer.ggml.padding_token_id: uint32`: Padding token |
|---|
| | | |
|---|
| | | #### Hugging Face |
|---|
| | | |
|---|
| | | Hugging Face maintains their own `tokenizers` library that supports a wide variety of tokenizers. If your executor uses this library, it may be able to use the model's tokenizer directly. |
|---|
| | | |
|---|
| | | - `tokenizer.huggingface.json: string`: the entirety of the HF `tokenizer.json` for a given model (e.g. <https://huggingface.co/mosaicml/mpt-7b-instruct/blob/main/tokenizer.json>). Included for compatibility with executors that support HF tokenizers directly. |
|---|
| | | |
|---|
| | | #### Other |
|---|
| | | |
|---|
| | | Other tokenizers may be used, but are not necessarily standardized. They may be executor-specific. They will be documented here as they are discovered/further developed. |
|---|
| | | |
|---|
| | | - `tokenizer.rwkv.world: string`: a RWKV World tokenizer, like [this](https://github.com/BlinkDL/ChatRWKV/blob/main/tokenizer/rwkv_vocab_v20230424.txt). This text file should be included verbatim. |
|---|
| | | - `tokenizer.chat_template : string`: a Jinja template that specifies the input format expected by the model. For more details see: <https://huggingface.co/docs/transformers/main/en/chat_templating> |
|---|
| | | |
|---|
| | | ### Computation graph |
|---|
| | | |
|---|
| | | This is a future extension and still needs to be discussed, and may necessitate a new GGUF version. At the time of writing, the primary blocker is the stabilization of the computation graph format. |
|---|
| | | |
|---|
| | | A sample computation graph of GGML nodes could be included in the model itself, allowing an executor to run the model without providing its own implementation of the architecture. This would allow for a more consistent experience across executors, and would allow for more complex architectures to be supported without requiring the executor to implement them. |
|---|
| | | |
|---|
| | | ## Standardized tensor names |
|---|
| | | |
|---|
| | | To minimize complexity and maximize compatibility, it is recommended that models using the transformer architecture use the following naming convention for their tensors: |
|---|
| | | |
|---|
| | | ### Base layers |
|---|
| | | |
|---|
| | | `AA.weight` `AA.bias` |
|---|
| | | |
|---|
| | | where `AA` can be: |
|---|
| | | |
|---|
| | | - `token_embd`: Token embedding layer |
|---|
| | | - `pos_embd`: Position embedding layer |
|---|
| | | - `output_norm`: Output normalization layer |
|---|
| | | - `output`: Output layer |
|---|
| | | |
|---|
| | | ### Attention and feed-forward layer blocks |
|---|
| | | |
|---|
| | | `blk.N.BB.weight` `blk.N.BB.bias` |
|---|
| | | |
|---|
| | | where N signifies the block number a layer belongs to, and where `BB` could be: |
|---|
| | | |
|---|
| | | - `attn_norm`: Attention normalization layer |
|---|
| | | - `attn_norm_2`: Attention normalization layer |
|---|
| | | - `attn_qkv`: Attention query-key-value layer |
|---|
| | | - `attn_q`: Attention query layer |
|---|
| | | - `attn_k`: Attention key layer |
|---|
| | | - `attn_v`: Attention value layer |
|---|
| | | - `attn_output`: Attention output layer |
|---|
| | | |
|---|
| | | - `ffn_norm`: Feed-forward network normalization layer |
|---|
| | | - `ffn_up`: Feed-forward network "up" layer |
|---|
| | | - `ffn_gate`: Feed-forward network "gate" layer |
|---|
| | | - `ffn_down`: Feed-forward network "down" layer |
|---|
| | | - `ffn_gate_inp`: Expert-routing layer for the Fee-forward network in MoE models |
|---|
| | | - `ffn_gate_exp`: Feed-forward network "gate" layer per expert in MoE models |
|---|
| | | - `ffn_down_exp`: Feed-forward network "down" layer per expert in MoE models |
|---|
| | | - `ffn_up_exp`: Feed-forward network "up" layer per expert in MoE models |
|---|
| | | |
|---|
| | | ## Version History |
|---|
| | | |
|---|
| | | This document is actively updated to describe the current state of the metadata, and these changes are not tracked outside of the commits. |
|---|
| | | |
|---|
| | | However, the format _itself_ has changed. The following sections describe the changes to the format itself. |
|---|
| | | |
|---|
| | | ### v3 |
|---|
| | | |
|---|
| | | Adds big-endian support. |
|---|
| | | |
|---|
| | | ### v2 |
|---|
| | | |
|---|
| | | Most countable values (lengths, etc) were changed from `uint32` to `uint64` to allow for larger models to be supported in the future. |
|---|
| | | |
|---|
| | | ### v1 |
|---|
| | | |
|---|
| | | Initial version. |
|---|
| | | |
|---|
| | | ## Historical State of Affairs |
|---|
| | | |
|---|
| | | The following information is provided for context, but is not necessary to understand the rest of this document. |
|---|
| | | |
|---|
| | | ### Overview |
|---|
| | | |
|---|
| | | At present, there are three GGML file formats floating around for LLMs: |
|---|
| | | |
|---|
| | | - **GGML** (unversioned): baseline format, with no versioning or alignment. |
|---|
| | | - **GGMF** (versioned): the same as GGML, but with versioning. Only one version exists. |
|---|
| | | - **GGJT**: Aligns the tensors to allow for use with `mmap`, which requires alignment. v1, v2 and v3 are identical, but the latter versions use a different quantization scheme that is incompatible with previous versions. |
|---|
| | | |
|---|
| | | GGML is primarily used by the examples in `ggml`, while GGJT is used by `llama.cpp` models. Other executors may use any of the three formats, but this is not 'officially' supported. |
|---|
| | | |
|---|
| | | These formats share the same fundamental structure: |
|---|
| | | |
|---|
| | | - a magic number with an optional version number |
|---|
| | | - model-specific hyperparameters, including |
|---|
| | | - metadata about the model, such as the number of layers, the number of heads, etc. |
|---|
| | | - a `ftype` that describes the type of the majority of the tensors, |
|---|
| | | - for GGML files, the quantization version is encoded in the `ftype` divided by 1000 |
|---|
| | | - an embedded vocabulary, which is a list of strings with length prepended. The GGMF/GGJT formats embed a float32 score next to the strings. |
|---|
| | | - finally, a list of tensors with their length-prepended name, type, and (aligned, in the case of GGJT) tensor data |
|---|
| | | |
|---|
| | | Notably, this structure does not identify what model architecture the model belongs to, nor does it offer any flexibility for changing the structure of the hyperparameters. This means that the only way to add new hyperparameters is to add them to the end of the list, which is a breaking change for existing models. |
|---|
| | | |
|---|
| | | ### Drawbacks |
|---|
| | | |
|---|
| | | Unfortunately, over the last few months, there are a few issues that have become apparent with the existing models: |
|---|
| | | |
|---|
| | | - There's no way to identify which model architecture a given model is for, because that information isn't present |
|---|
| | | - Similarly, existing programs cannot intelligently fail upon encountering new architectures |
|---|
| | | - Adding or removing any new hyperparameters is a breaking change, which is impossible for a reader to detect without using heuristics |
|---|
| | | - Each model architecture requires its own conversion script to their architecture's variant of GGML |
|---|
| | | - Maintaining backwards compatibility without breaking the structure of the format requires clever tricks, like packing the quantization version into the ftype, which are not guaranteed to be picked up by readers/writers, and are not consistent between the two formats |
|---|
| | | |
|---|
| | | ### Why not other formats? |
|---|
| | | |
|---|
| | | There are a few other formats that could be used, but issues include: |
|---|
| | | |
|---|
| | | - requiring additional dependencies to load or save the model, which is complicated in a C environment |
|---|
| | | - limited or no support for 4-bit quantization |
|---|
| | | - existing cultural expectations (e.g. whether or not the model is a directory or a file) |
|---|
| | | - lack of support for embedded vocabularies |
|---|
| | | - lack of control over direction of future development |
|---|
| | | |
|---|
| | | Ultimately, it is likely that GGUF will remain necessary for the foreseeable future, and it is better to have a single format that is well-documented and supported by all executors than to contort an existing format to fit the needs of GGML. |
|---|
| New file |
| | |
|---|
| | | if (GGML_ALL_WARNINGS) |
|---|
| | | if (NOT MSVC) |
|---|
| | | set(cxx_flags |
|---|
| | | # TODO(marella): Add other warnings. |
|---|
| | | -Wpedantic |
|---|
| | | -Wunused-variable |
|---|
| | | -Wno-unused-function |
|---|
| | | -Wno-multichar |
|---|
| | | ) |
|---|
| | | add_compile_options("$<$<COMPILE_LANGUAGE:CXX>:${cxx_flags}>") |
|---|
| | | endif() |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | add_library(common STATIC common.cpp) |
|---|
| | | target_include_directories(common PUBLIC ${CMAKE_CURRENT_SOURCE_DIR}) |
|---|
| | | |
|---|
| | | add_library(common-ggml STATIC common-ggml.cpp) |
|---|
| | | target_link_libraries(common-ggml PRIVATE ggml) |
|---|
| | | target_include_directories(common-ggml PUBLIC ${CMAKE_CURRENT_SOURCE_DIR}) |
|---|
| | | |
|---|
| | | add_subdirectory(gpt-2) |
|---|
| | | add_subdirectory(gpt-j) |
|---|
| | | add_subdirectory(whisper) |
|---|
| | | add_subdirectory(mnist) |
|---|
| | | add_subdirectory(gpt-neox) |
|---|
| | | add_subdirectory(dolly-v2) |
|---|
| | | add_subdirectory(replit) |
|---|
| | | add_subdirectory(mpt) |
|---|
| | | add_subdirectory(starcoder) |
|---|
| | | add_subdirectory(sam) |
|---|
| | | add_subdirectory(yolo) |
|---|
| New file |
| | |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <regex> |
|---|
| | | #include <map> |
|---|
| | | |
|---|
| | | static const std::map<std::string, enum ggml_ftype> GGML_FTYPE_MAP = { |
|---|
| | | {"q4_0", GGML_FTYPE_MOSTLY_Q4_0}, |
|---|
| | | {"q4_1", GGML_FTYPE_MOSTLY_Q4_1}, |
|---|
| | | {"q5_0", GGML_FTYPE_MOSTLY_Q5_0}, |
|---|
| | | {"q5_1", GGML_FTYPE_MOSTLY_Q5_1}, |
|---|
| | | {"q8_0", GGML_FTYPE_MOSTLY_Q8_0}, |
|---|
| | | {"q2_k", GGML_FTYPE_MOSTLY_Q2_K}, |
|---|
| | | {"q3_k", GGML_FTYPE_MOSTLY_Q3_K}, |
|---|
| | | {"q4_k", GGML_FTYPE_MOSTLY_Q4_K}, |
|---|
| | | {"q5_k", GGML_FTYPE_MOSTLY_Q5_K}, |
|---|
| | | {"q6_k", GGML_FTYPE_MOSTLY_Q6_K}, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | void ggml_print_ftypes(FILE * fp) { |
|---|
| | | for (auto it = GGML_FTYPE_MAP.begin(); it != GGML_FTYPE_MAP.end(); it++) { |
|---|
| | | fprintf(fp, " type = \"%s\" or %d\n", it->first.c_str(), it->second); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | enum ggml_ftype ggml_parse_ftype(const char * str) { |
|---|
| | | enum ggml_ftype ftype; |
|---|
| | | if (str[0] == 'q') { |
|---|
| | | const auto it = GGML_FTYPE_MAP.find(str); |
|---|
| | | if (it == GGML_FTYPE_MAP.end()) { |
|---|
| | | fprintf(stderr, "%s: unknown ftype '%s'\n", __func__, str); |
|---|
| | | return GGML_FTYPE_UNKNOWN; |
|---|
| | | } |
|---|
| | | ftype = it->second; |
|---|
| | | } else { |
|---|
| | | ftype = (enum ggml_ftype) atoi(str); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return ftype; |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool ggml_common_quantize_0( |
|---|
| | | std::ifstream & finp, |
|---|
| | | std::ofstream & fout, |
|---|
| | | const ggml_ftype ftype, |
|---|
| | | const std::vector<std::string> & to_quant, |
|---|
| | | const std::vector<std::string> & to_skip) { |
|---|
| | | |
|---|
| | | ggml_type qtype = GGML_TYPE_F32; |
|---|
| | | |
|---|
| | | switch (ftype) { |
|---|
| | | case GGML_FTYPE_MOSTLY_Q4_0: qtype = GGML_TYPE_Q4_0; break; |
|---|
| | | case GGML_FTYPE_MOSTLY_Q4_1: qtype = GGML_TYPE_Q4_1; break; |
|---|
| | | case GGML_FTYPE_MOSTLY_Q5_0: qtype = GGML_TYPE_Q5_0; break; |
|---|
| | | case GGML_FTYPE_MOSTLY_Q5_1: qtype = GGML_TYPE_Q5_1; break; |
|---|
| | | case GGML_FTYPE_MOSTLY_Q8_0: qtype = GGML_TYPE_Q8_0; break; |
|---|
| | | case GGML_FTYPE_MOSTLY_Q2_K: qtype = GGML_TYPE_Q2_K; break; |
|---|
| | | case GGML_FTYPE_MOSTLY_Q3_K: qtype = GGML_TYPE_Q3_K; break; |
|---|
| | | case GGML_FTYPE_MOSTLY_Q4_K: qtype = GGML_TYPE_Q4_K; break; |
|---|
| | | case GGML_FTYPE_MOSTLY_Q5_K: qtype = GGML_TYPE_Q5_K; break; |
|---|
| | | case GGML_FTYPE_MOSTLY_Q6_K: qtype = GGML_TYPE_Q6_K; break; |
|---|
| | | case GGML_FTYPE_UNKNOWN: |
|---|
| | | case GGML_FTYPE_ALL_F32: |
|---|
| | | case GGML_FTYPE_MOSTLY_F16: |
|---|
| | | case GGML_FTYPE_MOSTLY_Q4_1_SOME_F16: |
|---|
| | | case GGML_FTYPE_MOSTLY_IQ2_XXS: |
|---|
| | | case GGML_FTYPE_MOSTLY_IQ2_XS: |
|---|
| | | { |
|---|
| | | fprintf(stderr, "%s: invalid model type %d\n", __func__, ftype); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | if (!ggml_is_quantized(qtype)) { |
|---|
| | | fprintf(stderr, "%s: invalid quantization type %d (%s)\n", __func__, qtype, ggml_type_name(qtype)); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | size_t total_size_org = 0; |
|---|
| | | size_t total_size_new = 0; |
|---|
| | | |
|---|
| | | std::vector<float> work; |
|---|
| | | |
|---|
| | | std::vector<uint8_t> data_u8; |
|---|
| | | std::vector<ggml_fp16_t> data_f16; |
|---|
| | | std::vector<float> data_f32; |
|---|
| | | |
|---|
| | | std::vector<int64_t> hist_all(1 << 4, 0); |
|---|
| | | |
|---|
| | | while (true) { |
|---|
| | | int32_t n_dims; |
|---|
| | | int32_t length; |
|---|
| | | int32_t ttype; |
|---|
| | | |
|---|
| | | finp.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | finp.read(reinterpret_cast<char *>(&length), sizeof(length)); |
|---|
| | | finp.read(reinterpret_cast<char *>(&ttype), sizeof(ttype)); |
|---|
| | | |
|---|
| | | if (finp.eof()) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int32_t nelements = 1; |
|---|
| | | int32_t ne[4] = { 1, 1, 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | finp.read (reinterpret_cast<char *>(&ne[i]), sizeof(ne[i])); |
|---|
| | | nelements *= ne[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string name(length, 0); |
|---|
| | | finp.read (&name[0], length); |
|---|
| | | |
|---|
| | | printf("%64s - [%5d, %5d, %5d], type = %6s ", name.data(), ne[0], ne[1], ne[2], ggml_type_name((ggml_type) ttype)); |
|---|
| | | |
|---|
| | | bool quantize = false; |
|---|
| | | |
|---|
| | | // check if we should quantize this tensor |
|---|
| | | for (const auto & s : to_quant) { |
|---|
| | | if (std::regex_match(name, std::regex(s))) { |
|---|
| | | quantize = true; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // check if we should skip this tensor |
|---|
| | | for (const auto & s : to_skip) { |
|---|
| | | if (std::regex_match(name, std::regex(s))) { |
|---|
| | | quantize = false; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // quantize only 2D tensors |
|---|
| | | quantize &= (n_dims == 2); |
|---|
| | | |
|---|
| | | if (quantize) { |
|---|
| | | if (ttype != GGML_TYPE_F32 && ttype != GGML_TYPE_F16) { |
|---|
| | | fprintf(stderr, "%s: unsupported ttype %d (%s) for integer quantization\n", __func__, ttype, ggml_type_name((ggml_type) ttype)); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (ttype == GGML_TYPE_F16) { |
|---|
| | | data_f16.resize(nelements); |
|---|
| | | finp.read(reinterpret_cast<char *>(data_f16.data()), nelements * sizeof(ggml_fp16_t)); |
|---|
| | | data_f32.resize(nelements); |
|---|
| | | for (int i = 0; i < nelements; ++i) { |
|---|
| | | data_f32[i] = ggml_fp16_to_fp32(data_f16[i]); |
|---|
| | | } |
|---|
| | | } else { |
|---|
| | | data_f32.resize(nelements); |
|---|
| | | finp.read(reinterpret_cast<char *>(data_f32.data()), nelements * sizeof(float)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ttype = qtype; |
|---|
| | | } else { |
|---|
| | | const int bpe = (ttype == 0) ? sizeof(float) : sizeof(uint16_t); |
|---|
| | | |
|---|
| | | data_u8.resize(nelements*bpe); |
|---|
| | | finp.read(reinterpret_cast<char *>(data_u8.data()), nelements * bpe); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fout.write(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | fout.write(reinterpret_cast<char *>(&length), sizeof(length)); |
|---|
| | | fout.write(reinterpret_cast<char *>(&ttype), sizeof(ttype)); |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fout.write(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i])); |
|---|
| | | } |
|---|
| | | fout.write(&name[0], length); |
|---|
| | | |
|---|
| | | if (quantize) { |
|---|
| | | work.resize(nelements); // for quantization |
|---|
| | | |
|---|
| | | size_t cur_size = 0; |
|---|
| | | std::vector<int64_t> hist_cur(1 << 4, 0); |
|---|
| | | |
|---|
| | | switch ((ggml_type) ttype) { |
|---|
| | | case GGML_TYPE_Q4_0: |
|---|
| | | case GGML_TYPE_Q4_1: |
|---|
| | | case GGML_TYPE_Q5_0: |
|---|
| | | case GGML_TYPE_Q5_1: |
|---|
| | | case GGML_TYPE_Q8_0: |
|---|
| | | case GGML_TYPE_Q2_K: |
|---|
| | | case GGML_TYPE_Q3_K: |
|---|
| | | case GGML_TYPE_Q4_K: |
|---|
| | | case GGML_TYPE_Q5_K: |
|---|
| | | case GGML_TYPE_Q6_K: |
|---|
| | | { |
|---|
| | | cur_size = ggml_quantize_chunk((ggml_type) ttype, data_f32.data(), work.data(), 0, nelements, hist_cur.data()); |
|---|
| | | } break; |
|---|
| | | case GGML_TYPE_F32: |
|---|
| | | case GGML_TYPE_F16: |
|---|
| | | case GGML_TYPE_I8: |
|---|
| | | case GGML_TYPE_I16: |
|---|
| | | case GGML_TYPE_I32: |
|---|
| | | case GGML_TYPE_Q8_1: |
|---|
| | | case GGML_TYPE_Q8_K: |
|---|
| | | case GGML_TYPE_IQ2_XXS: |
|---|
| | | case GGML_TYPE_IQ2_XS: |
|---|
| | | case GGML_TYPE_COUNT: |
|---|
| | | { |
|---|
| | | fprintf(stderr, "%s: unsupported quantization type %d (%s)\n", __func__, ttype, ggml_type_name((ggml_type) ttype)); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | fout.write(reinterpret_cast<char *>(work.data()), cur_size); |
|---|
| | | total_size_new += cur_size; |
|---|
| | | |
|---|
| | | printf("size = %8.2f MB -> %8.2f MB | hist: ", nelements * sizeof(float)/1024.0/1024.0, cur_size/1024.0/1024.0); |
|---|
| | | for (int i = 0; i < (int) hist_cur.size(); ++i) { |
|---|
| | | hist_all[i] += hist_cur[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | for (int i = 0; i < (int) hist_cur.size(); ++i) { |
|---|
| | | printf("%5.3f ", hist_cur[i] / (float)nelements); |
|---|
| | | } |
|---|
| | | printf("\n"); |
|---|
| | | } else { |
|---|
| | | printf("size = %8.3f MB\n", data_u8.size()/1024.0/1024.0); |
|---|
| | | fout.write(reinterpret_cast<char *>(data_u8.data()), data_u8.size()); |
|---|
| | | total_size_new += data_u8.size(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | total_size_org += nelements * sizeof(float); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: model size = %8.2f MB\n", __func__, total_size_org/1024.0/1024.0); |
|---|
| | | printf("%s: quant size = %8.2f MB | ftype = %d (%s)\n", __func__, total_size_new/1024.0/1024.0, ftype, ggml_type_name(qtype)); |
|---|
| | | |
|---|
| | | { |
|---|
| | | int64_t sum_all = 0; |
|---|
| | | for (int i = 0; i < (int) hist_all.size(); ++i) { |
|---|
| | | sum_all += hist_all[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: hist: ", __func__); |
|---|
| | | for (int i = 0; i < (int) hist_all.size(); ++i) { |
|---|
| | | printf("%5.3f ", hist_all[i] / (float)sum_all); |
|---|
| | | } |
|---|
| | | printf("\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #pragma once |
|---|
| | | |
|---|
| | | #include "ggml.h" |
|---|
| | | |
|---|
| | | #include <fstream> |
|---|
| | | #include <vector> |
|---|
| | | #include <string> |
|---|
| | | |
|---|
| | | enum ggml_ftype ggml_parse_ftype(const char * str); |
|---|
| | | |
|---|
| | | void ggml_print_ftypes(FILE * fp = stderr); |
|---|
| | | |
|---|
| | | bool ggml_common_quantize_0( |
|---|
| | | std::ifstream & finp, |
|---|
| | | std::ofstream & fout, |
|---|
| | | const ggml_ftype ftype, |
|---|
| | | const std::vector<std::string> & to_quant, |
|---|
| | | const std::vector<std::string> & to_skip); |
|---|
| New file |
| | |
|---|
| | | #define _USE_MATH_DEFINES // for M_PI |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | |
|---|
| | | // third-party utilities |
|---|
| | | // use your favorite implementations |
|---|
| | | #define DR_WAV_IMPLEMENTATION |
|---|
| | | #include "dr_wav.h" |
|---|
| | | |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <regex> |
|---|
| | | #include <locale> |
|---|
| | | #include <codecvt> |
|---|
| | | #include <sstream> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | // Function to check if the next argument exists |
|---|
| | | std::string get_next_arg(int& i, int argc, char** argv, const std::string& flag, gpt_params& params) { |
|---|
| | | if (i + 1 < argc && argv[i + 1][0] != '-') { |
|---|
| | | return argv[++i]; |
|---|
| | | } else { |
|---|
| | | fprintf(stderr, "error: %s requires one argument.\n", flag.c_str()); |
|---|
| | | gpt_print_usage(argc, argv, params); |
|---|
| | | exit(0); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool gpt_params_parse(int argc, char ** argv, gpt_params & params) { |
|---|
| | | for (int i = 1; i < argc; i++) { |
|---|
| | | std::string arg = argv[i]; |
|---|
| | | |
|---|
| | | if (arg == "-s" || arg == "--seed") { |
|---|
| | | params.seed = std::stoi(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "-t" || arg == "--threads") { |
|---|
| | | params.n_threads = std::stoi(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "-p" || arg == "--prompt") { |
|---|
| | | params.prompt = get_next_arg(i, argc, argv, arg, params); |
|---|
| | | } else if (arg == "-n" || arg == "--n_predict") { |
|---|
| | | params.n_predict = std::stoi(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "-np" || arg == "--n_parallel") { |
|---|
| | | params.n_parallel = std::stoi(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "--top_k") { |
|---|
| | | params.top_k = std::stoi(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "--top_p") { |
|---|
| | | params.top_p = std::stof(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "--temp") { |
|---|
| | | params.temp = std::stof(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "--repeat-last-n") { |
|---|
| | | params.repeat_last_n = std::stoi(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "--repeat-penalty") { |
|---|
| | | params.repeat_penalty = std::stof(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "-b" || arg == "--batch_size") { |
|---|
| | | params.n_batch= std::stoi(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "-c" || arg == "--context") { |
|---|
| | | params.n_ctx= std::stoi(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "-ngl" || arg == "--gpu-layers" || arg == "--n-gpu-layers") { |
|---|
| | | params.n_gpu_layers = std::stoi(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "--ignore-eos") { |
|---|
| | | params.ignore_eos = true; |
|---|
| | | } else if (arg == "-m" || arg == "--model") { |
|---|
| | | params.model = get_next_arg(i, argc, argv, arg, params); |
|---|
| | | } else if (arg == "-i" || arg == "--interactive") { |
|---|
| | | params.interactive = true; |
|---|
| | | } else if (arg == "-ip" || arg == "--interactive-port") { |
|---|
| | | params.interactive = true; |
|---|
| | | params.interactive_port = std::stoi(get_next_arg(i, argc, argv, arg, params)); |
|---|
| | | } else if (arg == "-h" || arg == "--help") { |
|---|
| | | gpt_print_usage(argc, argv, params); |
|---|
| | | exit(0); |
|---|
| | | } else if (arg == "-f" || arg == "--file") { |
|---|
| | | get_next_arg(i, argc, argv, arg, params); |
|---|
| | | std::ifstream file(argv[i]); |
|---|
| | | if (!file) { |
|---|
| | | fprintf(stderr, "error: failed to open file '%s'\n", argv[i]); |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | std::copy(std::istreambuf_iterator<char>(file), std::istreambuf_iterator<char>(), back_inserter(params.prompt)); |
|---|
| | | if (params.prompt.back() == '\n') { |
|---|
| | | params.prompt.pop_back(); |
|---|
| | | } |
|---|
| | | } else if (arg == "-tt" || arg == "--token_test") { |
|---|
| | | params.token_test = get_next_arg(i, argc, argv, arg, params); |
|---|
| | | } |
|---|
| | | else { |
|---|
| | | fprintf(stderr, "error: unknown argument: %s\n", arg.c_str()); |
|---|
| | | gpt_print_usage(argc, argv, params); |
|---|
| | | exit(0); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void gpt_print_usage(int /*argc*/, char ** argv, const gpt_params & params) { |
|---|
| | | fprintf(stderr, "usage: %s [options]\n", argv[0]); |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | fprintf(stderr, "options:\n"); |
|---|
| | | fprintf(stderr, " -h, --help show this help message and exit\n"); |
|---|
| | | fprintf(stderr, " -s SEED, --seed SEED RNG seed (default: -1)\n"); |
|---|
| | | fprintf(stderr, " -t N, --threads N number of threads to use during computation (default: %d)\n", params.n_threads); |
|---|
| | | fprintf(stderr, " -p PROMPT, --prompt PROMPT\n"); |
|---|
| | | fprintf(stderr, " prompt to start generation with (default: random)\n"); |
|---|
| | | fprintf(stderr, " -f FNAME, --file FNAME\n"); |
|---|
| | | fprintf(stderr, " load prompt from a file\n"); |
|---|
| | | fprintf(stderr, " -tt TOKEN_TEST, --token_test TOKEN_TEST\n"); |
|---|
| | | fprintf(stderr, " test tokenization\n"); |
|---|
| | | fprintf(stderr, " -n N, --n_predict N number of tokens to predict (default: %d)\n", params.n_predict); |
|---|
| | | fprintf(stderr, " --top_k N top-k sampling (default: %d)\n", params.top_k); |
|---|
| | | fprintf(stderr, " --top_p N top-p sampling (default: %.1f)\n", params.top_p); |
|---|
| | | fprintf(stderr, " --temp N temperature (default: %.1f)\n", params.temp); |
|---|
| | | fprintf(stderr, " --repeat-last-n N last n tokens to consider for penalize (default: %d, 0 = disabled)\n", params.repeat_last_n); |
|---|
| | | fprintf(stderr, " --repeat-penalty N penalize repeat sequence of tokens (default: %.2f, 1.0 = disabled)\n", (double)params.repeat_penalty); |
|---|
| | | fprintf(stderr, " -b N, --batch_size N batch size for prompt processing (default: %d)\n", params.n_batch); |
|---|
| | | fprintf(stderr, " -c N, --context N context / KV cache size (default: %d)\n", params.n_ctx); |
|---|
| | | fprintf(stderr, " --ignore-eos ignore EOS token during generation\n"); |
|---|
| | | fprintf(stderr, " -ngl N, --gpu-layers N number of layers to offload to GPU on supported models (default: %d)\n", params.n_gpu_layers); |
|---|
| | | fprintf(stderr, " -m FNAME, --model FNAME\n"); |
|---|
| | | fprintf(stderr, " model path (default: %s)\n", params.model.c_str()); |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string gpt_random_prompt(std::mt19937 & rng) { |
|---|
| | | const int r = rng() % 10; |
|---|
| | | switch (r) { |
|---|
| | | case 0: return "So"; |
|---|
| | | case 1: return "Once upon a time"; |
|---|
| | | case 2: return "When"; |
|---|
| | | case 3: return "The"; |
|---|
| | | case 4: return "After"; |
|---|
| | | case 5: return "If"; |
|---|
| | | case 6: return "import"; |
|---|
| | | case 7: return "He"; |
|---|
| | | case 8: return "She"; |
|---|
| | | case 9: return "They"; |
|---|
| | | default: return "To"; |
|---|
| | | } |
|---|
| | | |
|---|
| | | return "The"; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string trim(const std::string & s) { |
|---|
| | | std::regex e("^\\s+|\\s+$"); |
|---|
| | | return std::regex_replace(s, e, ""); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string replace(const std::string & s, const std::string & from, const std::string & to) { |
|---|
| | | std::string result = s; |
|---|
| | | size_t pos = 0; |
|---|
| | | while ((pos = result.find(from, pos)) != std::string::npos) { |
|---|
| | | result.replace(pos, from.length(), to); |
|---|
| | | pos += to.length(); |
|---|
| | | } |
|---|
| | | return result; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void gpt_vocab::add_special_token(const std::string & token) { |
|---|
| | | special_tokens.push_back(token); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::map<std::string, int32_t> json_parse(const std::string & fname) { |
|---|
| | | std::map<std::string, int32_t> result; |
|---|
| | | |
|---|
| | | // read file into string |
|---|
| | | std::string json; |
|---|
| | | { |
|---|
| | | std::ifstream ifs(fname); |
|---|
| | | if (!ifs) { |
|---|
| | | fprintf(stderr, "Failed to open %s\n", fname.c_str()); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | json = std::string((std::istreambuf_iterator<char>(ifs)), |
|---|
| | | (std::istreambuf_iterator<char>())); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (json[0] != '{') { |
|---|
| | | return result; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // parse json |
|---|
| | | { |
|---|
| | | bool has_key = false; |
|---|
| | | bool in_token = false; |
|---|
| | | |
|---|
| | | std::string str_key = ""; |
|---|
| | | std::string str_val = ""; |
|---|
| | | |
|---|
| | | int n = json.size(); |
|---|
| | | for (int i = 1; i < n; ++i) { |
|---|
| | | if (!in_token) { |
|---|
| | | if (json[i] == ' ') continue; |
|---|
| | | if (json[i] == '"') { |
|---|
| | | in_token = true; |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | } else { |
|---|
| | | if (json[i] == '\\' && i+1 < n) { |
|---|
| | | if (has_key == false) { |
|---|
| | | str_key += json[i]; |
|---|
| | | } else { |
|---|
| | | str_val += json[i]; |
|---|
| | | } |
|---|
| | | ++i; |
|---|
| | | } else if (json[i] == '"') { |
|---|
| | | if (has_key == false) { |
|---|
| | | has_key = true; |
|---|
| | | ++i; |
|---|
| | | while (json[i] == ' ') ++i; |
|---|
| | | ++i; // : |
|---|
| | | while (json[i] == ' ') ++i; |
|---|
| | | if (json[i] != '\"') { |
|---|
| | | while (json[i] != ',' && json[i] != '}') { |
|---|
| | | str_val += json[i++]; |
|---|
| | | } |
|---|
| | | has_key = false; |
|---|
| | | } else { |
|---|
| | | in_token = true; |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | } else { |
|---|
| | | has_key = false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | str_key = ::replace(str_key, "\\u0120", " " ); // \u0120 -> space |
|---|
| | | str_key = ::replace(str_key, "\\u010a", "\n"); // \u010a -> new line |
|---|
| | | str_key = ::replace(str_key, "\\\"", "\""); // \\\" -> " |
|---|
| | | |
|---|
| | | try { |
|---|
| | | result[str_key] = std::stoi(str_val); |
|---|
| | | } catch (...) { |
|---|
| | | //fprintf(stderr, "%s: ignoring key '%s' with value '%s'\n", fname.c_str(), str_key.c_str(), str_val.c_str()); |
|---|
| | | |
|---|
| | | } |
|---|
| | | str_key = ""; |
|---|
| | | str_val = ""; |
|---|
| | | in_token = false; |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | if (has_key == false) { |
|---|
| | | str_key += json[i]; |
|---|
| | | } else { |
|---|
| | | str_val += json[i]; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | return result; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string convert_to_utf8(const std::wstring & input) { |
|---|
| | | std::wstring_convert<std::codecvt_utf8<wchar_t>> converter; |
|---|
| | | return converter.to_bytes(input); |
|---|
| | | } |
|---|
| | | |
|---|
| | | |
|---|
| | | std::wstring convert_to_wstring(const std::string & input) { |
|---|
| | | std::wstring_convert<std::codecvt_utf8<wchar_t>> converter; |
|---|
| | | return converter.from_bytes(input); |
|---|
| | | } |
|---|
| | | |
|---|
| | | void gpt_split_words(std::string str, std::vector<std::string>& words) { |
|---|
| | | const std::string pattern = R"('s|'t|'re|'ve|'m|'ll|'d| ?[[:alpha:]]+| ?[[:digit:]]+| ?[^\s[:alpha:][:digit:]]+|\s+(?!\S)|\s+)"; |
|---|
| | | const std::regex re(pattern); |
|---|
| | | std::smatch m; |
|---|
| | | |
|---|
| | | while (std::regex_search(str, m, re)) { |
|---|
| | | for (auto x : m) { |
|---|
| | | words.push_back(x); |
|---|
| | | } |
|---|
| | | str = m.suffix(); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::vector<gpt_vocab::id> gpt_tokenize(const gpt_vocab & vocab, const std::string & text) { |
|---|
| | | std::vector<std::string> words; |
|---|
| | | |
|---|
| | | // first split the text into words |
|---|
| | | { |
|---|
| | | std::string str = text; |
|---|
| | | |
|---|
| | | // Generate the subpattern from the special_tokens vector if it's not empty |
|---|
| | | if (!vocab.special_tokens.empty()) { |
|---|
| | | const std::regex escape(R"([\[\\\^\$\.\|\?\*\+\(\)\{\}])"); |
|---|
| | | std::string special_tokens_subpattern; |
|---|
| | | for (const auto & token : vocab.special_tokens) { |
|---|
| | | if (!special_tokens_subpattern.empty()) { |
|---|
| | | special_tokens_subpattern += "|"; |
|---|
| | | } |
|---|
| | | special_tokens_subpattern += std::regex_replace(token, escape, R"(\$&)"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::regex re(special_tokens_subpattern); |
|---|
| | | std::smatch m; |
|---|
| | | // Split the text by special tokens. |
|---|
| | | while (std::regex_search(str, m, re)) { |
|---|
| | | // Split the substrings in-between special tokens into words. |
|---|
| | | gpt_split_words(m.prefix(), words); |
|---|
| | | // Add matched special tokens as words. |
|---|
| | | for (auto x : m) { |
|---|
| | | words.push_back(x); |
|---|
| | | } |
|---|
| | | str = m.suffix(); |
|---|
| | | } |
|---|
| | | // Remaining text without special tokens will be handled below. |
|---|
| | | } |
|---|
| | | |
|---|
| | | gpt_split_words(str, words); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // find the longest token that forms each word in words: |
|---|
| | | std::vector<gpt_vocab::id> tokens; |
|---|
| | | for (const auto & word : words) { |
|---|
| | | for (int i = 0; i < (int) word.size(); ){ |
|---|
| | | for (int j = word.size() - 1; j >= i; j--){ |
|---|
| | | auto cand = word.substr(i, j-i+1); |
|---|
| | | auto it = vocab.token_to_id.find(cand); |
|---|
| | | if (it != vocab.token_to_id.end()){ // word.substr(i, j-i+1) in vocab |
|---|
| | | tokens.push_back(it->second); |
|---|
| | | i = j + 1; |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | else if (j == i){ // word.substr(i, 1) has no matching |
|---|
| | | fprintf(stderr, "%s: unknown token '%s'\n", __func__, word.substr(i, 1).data()); |
|---|
| | | i++; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | return tokens; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::vector<gpt_vocab::id> parse_tokens_from_string(const std::string& input, char delimiter) { |
|---|
| | | std::vector<gpt_vocab::id> output; |
|---|
| | | std::stringstream ss(input); |
|---|
| | | std::string token; |
|---|
| | | |
|---|
| | | while (std::getline(ss, token, delimiter)) { |
|---|
| | | output.push_back(std::stoi(token)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return output; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::map<std::string, std::vector<gpt_vocab::id>> extract_tests_from_file(const std::string & fpath_test){ |
|---|
| | | if (fpath_test.empty()){ |
|---|
| | | fprintf(stderr, "%s : No test file found.\n", __func__); |
|---|
| | | return std::map<std::string, std::vector<gpt_vocab::id>>(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::map<std::string, std::vector<gpt_vocab::id>> tests; |
|---|
| | | |
|---|
| | | auto fin = std::ifstream(fpath_test, std::ios_base::in); |
|---|
| | | const char * delimeter = " => "; |
|---|
| | | const char del_tok = ','; |
|---|
| | | std::string line; |
|---|
| | | while (std::getline(fin, line)) { |
|---|
| | | size_t delimiterPos = line.find(delimeter); |
|---|
| | | if (delimiterPos != std::string::npos) { |
|---|
| | | std::string text = line.substr(0, delimiterPos); |
|---|
| | | std::string s_tokens = line.substr(delimiterPos + std::strlen(delimeter)); |
|---|
| | | tests[text] = parse_tokens_from_string(s_tokens, del_tok); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | return tests; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void test_gpt_tokenizer(gpt_vocab & vocab, const std::string & fpath_test){ |
|---|
| | | std::map<std::string, std::vector<gpt_vocab::id>> tests = extract_tests_from_file(fpath_test); |
|---|
| | | |
|---|
| | | size_t n_fails = 0; |
|---|
| | | |
|---|
| | | for (const auto & test : tests) { |
|---|
| | | std::vector<gpt_vocab::id> tokens = gpt_tokenize(vocab, test.first); |
|---|
| | | |
|---|
| | | if (tokens != test.second){ |
|---|
| | | n_fails++; |
|---|
| | | |
|---|
| | | // print out failure cases |
|---|
| | | fprintf(stderr, "%s : failed test: '%s'\n", __func__, test.first.c_str()); |
|---|
| | | fprintf(stderr, "%s : tokens in hf: ", __func__); |
|---|
| | | for (const auto & t : test.second) { |
|---|
| | | fprintf(stderr, "%s(%d), ", vocab.id_to_token[t].c_str(), t); |
|---|
| | | } |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | fprintf(stderr, "%s : tokens in ggml: ", __func__); |
|---|
| | | for (const auto & t : tokens) { |
|---|
| | | fprintf(stderr, "%s(%d), ", vocab.id_to_token[t].c_str(), t); |
|---|
| | | } |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s : %zu tests failed out of %zu tests.\n", __func__, n_fails, tests.size()); |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool gpt_vocab_init(const std::string & fname, gpt_vocab & vocab) { |
|---|
| | | printf("%s: loading vocab from '%s'\n", __func__, fname.c_str()); |
|---|
| | | |
|---|
| | | vocab.token_to_id = ::json_parse(fname); |
|---|
| | | |
|---|
| | | for (const auto & kv : vocab.token_to_id) { |
|---|
| | | vocab.id_to_token[kv.second] = kv.first; |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: vocab size = %d\n", __func__, (int) vocab.token_to_id.size()); |
|---|
| | | |
|---|
| | | // print the vocabulary |
|---|
| | | //for (auto kv : vocab.token_to_id) { |
|---|
| | | // printf("'%s' -> %d\n", kv.first.data(), kv.second); |
|---|
| | | //} |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | gpt_vocab::id gpt_sample_top_k_top_p( |
|---|
| | | const gpt_vocab & vocab, |
|---|
| | | const float * logits, |
|---|
| | | int top_k, |
|---|
| | | double top_p, |
|---|
| | | double temp, |
|---|
| | | std::mt19937 & rng) { |
|---|
| | | int n_logits = vocab.id_to_token.size(); |
|---|
| | | |
|---|
| | | std::vector<std::pair<double, gpt_vocab::id>> logits_id; |
|---|
| | | logits_id.reserve(n_logits); |
|---|
| | | |
|---|
| | | { |
|---|
| | | const double scale = 1.0/temp; |
|---|
| | | for (int i = 0; i < n_logits; ++i) { |
|---|
| | | logits_id.push_back(std::make_pair(logits[i]*scale, i)); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // find the top K tokens |
|---|
| | | std::partial_sort( |
|---|
| | | logits_id.begin(), |
|---|
| | | logits_id.begin() + top_k, logits_id.end(), |
|---|
| | | [](const std::pair<double, gpt_vocab::id> & a, const std::pair<double, gpt_vocab::id> & b) { |
|---|
| | | return a.first > b.first; |
|---|
| | | }); |
|---|
| | | |
|---|
| | | logits_id.resize(top_k); |
|---|
| | | |
|---|
| | | double maxl = -INFINITY; |
|---|
| | | for (const auto & kv : logits_id) { |
|---|
| | | maxl = std::max(maxl, kv.first); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // compute probs for the top K tokens |
|---|
| | | std::vector<double> probs; |
|---|
| | | probs.reserve(logits_id.size()); |
|---|
| | | |
|---|
| | | double sum = 0.0; |
|---|
| | | for (const auto & kv : logits_id) { |
|---|
| | | double p = exp(kv.first - maxl); |
|---|
| | | probs.push_back(p); |
|---|
| | | sum += p; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // normalize the probs |
|---|
| | | for (auto & p : probs) { |
|---|
| | | p /= sum; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (top_p < 1.0f) { |
|---|
| | | double cumsum = 0.0f; |
|---|
| | | for (int i = 0; i < top_k; i++) { |
|---|
| | | cumsum += probs[i]; |
|---|
| | | if (cumsum >= top_p) { |
|---|
| | | top_k = i + 1; |
|---|
| | | probs.resize(top_k); |
|---|
| | | logits_id.resize(top_k); |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | cumsum = 1.0/cumsum; |
|---|
| | | for (int i = 0; i < (int) probs.size(); i++) { |
|---|
| | | probs[i] *= cumsum; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | //printf("\n"); |
|---|
| | | //for (int i = 0; i < (int) probs.size(); i++) { |
|---|
| | | // printf("%d: '%s' %f\n", i, vocab.id_to_token.at(logits_id[i].second).c_str(), probs[i]); |
|---|
| | | //} |
|---|
| | | //exit(0); |
|---|
| | | |
|---|
| | | std::discrete_distribution<> dist(probs.begin(), probs.end()); |
|---|
| | | int idx = dist(rng); |
|---|
| | | |
|---|
| | | return logits_id[idx].second; |
|---|
| | | } |
|---|
| | | |
|---|
| | | gpt_vocab::id gpt_sample_top_k_top_p_repeat( |
|---|
| | | const gpt_vocab & vocab, |
|---|
| | | const float * logits, |
|---|
| | | const int32_t * last_n_tokens_data, |
|---|
| | | size_t last_n_tokens_data_size, |
|---|
| | | int top_k, |
|---|
| | | double top_p, |
|---|
| | | double temp, |
|---|
| | | int repeat_last_n, |
|---|
| | | float repeat_penalty, |
|---|
| | | std::mt19937 & rng) { |
|---|
| | | |
|---|
| | | int n_logits = vocab.id_to_token.size(); |
|---|
| | | |
|---|
| | | const auto * plogits = logits; |
|---|
| | | |
|---|
| | | const auto last_n_tokens = std::vector<int32_t>(last_n_tokens_data, last_n_tokens_data + last_n_tokens_data_size); |
|---|
| | | |
|---|
| | | if (temp <= 0) { |
|---|
| | | // select the token with the highest logit directly |
|---|
| | | float max_logit = plogits[0]; |
|---|
| | | gpt_vocab::id max_id = 0; |
|---|
| | | |
|---|
| | | for (int i = 1; i < n_logits; ++i) { |
|---|
| | | if (plogits[i] > max_logit) { |
|---|
| | | max_logit = plogits[i]; |
|---|
| | | max_id = i; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | return max_id; |
|---|
| | | } |
|---|
| | | |
|---|
| | | |
|---|
| | | std::vector<std::pair<double, gpt_vocab::id>> logits_id; |
|---|
| | | logits_id.reserve(n_logits); |
|---|
| | | |
|---|
| | | { |
|---|
| | | const float scale = 1.0f/temp; |
|---|
| | | for (int i = 0; i < n_logits; ++i) { |
|---|
| | | // repetition penalty from ctrl paper (https://arxiv.org/abs/1909.05858) |
|---|
| | | // credit https://github.com/facebookresearch/llama/compare/main...shawwn:llama:main |
|---|
| | | if (repeat_last_n > 0 && std::find(last_n_tokens.end()-repeat_last_n, last_n_tokens.end(), i) != last_n_tokens.end()) { |
|---|
| | | // if score < 0 then repetition penalty has to multiplied to reduce the previous token probability |
|---|
| | | if (plogits[i] < 0.0f) { |
|---|
| | | logits_id.push_back(std::make_pair(plogits[i]*scale*repeat_penalty, i)); |
|---|
| | | } else { |
|---|
| | | logits_id.push_back(std::make_pair(plogits[i]*scale/repeat_penalty, i)); |
|---|
| | | } |
|---|
| | | } else { |
|---|
| | | logits_id.push_back(std::make_pair(plogits[i]*scale, i)); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // find the top K tokens |
|---|
| | | std::partial_sort( |
|---|
| | | logits_id.begin(), |
|---|
| | | logits_id.begin() + top_k, logits_id.end(), |
|---|
| | | [](const std::pair<double, gpt_vocab::id> & a, const std::pair<double, gpt_vocab::id> & b) { |
|---|
| | | return a.first > b.first; |
|---|
| | | }); |
|---|
| | | |
|---|
| | | logits_id.resize(top_k); |
|---|
| | | |
|---|
| | | double maxl = -INFINITY; |
|---|
| | | for (const auto & kv : logits_id) { |
|---|
| | | maxl = std::max(maxl, kv.first); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // compute probs for the top K tokens |
|---|
| | | std::vector<double> probs; |
|---|
| | | probs.reserve(logits_id.size()); |
|---|
| | | |
|---|
| | | double sum = 0.0; |
|---|
| | | for (const auto & kv : logits_id) { |
|---|
| | | double p = exp(kv.first - maxl); |
|---|
| | | probs.push_back(p); |
|---|
| | | sum += p; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // normalize the probs |
|---|
| | | for (auto & p : probs) { |
|---|
| | | p /= sum; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (top_p < 1.0f) { |
|---|
| | | double cumsum = 0.0f; |
|---|
| | | for (int i = 0; i < top_k; i++) { |
|---|
| | | cumsum += probs[i]; |
|---|
| | | if (cumsum >= top_p) { |
|---|
| | | top_k = i + 1; |
|---|
| | | probs.resize(top_k); |
|---|
| | | logits_id.resize(top_k); |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | cumsum = 1.0/cumsum; |
|---|
| | | for (int i = 0; i < (int) probs.size(); i++) { |
|---|
| | | probs[i] *= cumsum; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // printf("\n"); |
|---|
| | | // for (int i = 0; i < (int) probs.size(); i++) { |
|---|
| | | // for (int i = 0; i < 10; i++) { |
|---|
| | | // printf("%d: '%s' %f\n", i, vocab.id_to_token.at(logits_id[i].second).c_str(), probs[i]); |
|---|
| | | // } |
|---|
| | | |
|---|
| | | std::discrete_distribution<> dist(probs.begin(), probs.end()); |
|---|
| | | int idx = dist(rng); |
|---|
| | | |
|---|
| | | return logits_id[idx].second; |
|---|
| | | |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool read_wav(const std::string & fname, std::vector<float>& pcmf32, std::vector<std::vector<float>>& pcmf32s, bool stereo) { |
|---|
| | | drwav wav; |
|---|
| | | std::vector<uint8_t> wav_data; // used for pipe input from stdin |
|---|
| | | |
|---|
| | | if (fname == "-") { |
|---|
| | | { |
|---|
| | | uint8_t buf[1024]; |
|---|
| | | while (true) |
|---|
| | | { |
|---|
| | | const size_t n = fread(buf, 1, sizeof(buf), stdin); |
|---|
| | | if (n == 0) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | wav_data.insert(wav_data.end(), buf, buf + n); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (drwav_init_memory(&wav, wav_data.data(), wav_data.size(), nullptr) == false) { |
|---|
| | | fprintf(stderr, "error: failed to open WAV file from stdin\n"); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s: read %zu bytes from stdin\n", __func__, wav_data.size()); |
|---|
| | | } |
|---|
| | | else if (drwav_init_file(&wav, fname.c_str(), nullptr) == false) { |
|---|
| | | fprintf(stderr, "error: failed to open '%s' as WAV file\n", fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (wav.channels != 1 && wav.channels != 2) { |
|---|
| | | fprintf(stderr, "%s: WAV file '%s' must be mono or stereo\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (stereo && wav.channels != 2) { |
|---|
| | | fprintf(stderr, "%s: WAV file '%s' must be stereo for diarization\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (wav.sampleRate != COMMON_SAMPLE_RATE) { |
|---|
| | | fprintf(stderr, "%s: WAV file '%s' must be %i kHz\n", __func__, fname.c_str(), COMMON_SAMPLE_RATE/1000); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (wav.bitsPerSample != 16) { |
|---|
| | | fprintf(stderr, "%s: WAV file '%s' must be 16-bit\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | const uint64_t n = wav_data.empty() ? wav.totalPCMFrameCount : wav_data.size()/(wav.channels*wav.bitsPerSample/8); |
|---|
| | | |
|---|
| | | std::vector<int16_t> pcm16; |
|---|
| | | pcm16.resize(n*wav.channels); |
|---|
| | | drwav_read_pcm_frames_s16(&wav, n, pcm16.data()); |
|---|
| | | drwav_uninit(&wav); |
|---|
| | | |
|---|
| | | // convert to mono, float |
|---|
| | | pcmf32.resize(n); |
|---|
| | | if (wav.channels == 1) { |
|---|
| | | for (uint64_t i = 0; i < n; i++) { |
|---|
| | | pcmf32[i] = float(pcm16[i])/32768.0f; |
|---|
| | | } |
|---|
| | | } else { |
|---|
| | | for (uint64_t i = 0; i < n; i++) { |
|---|
| | | pcmf32[i] = float(pcm16[2*i] + pcm16[2*i + 1])/65536.0f; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (stereo) { |
|---|
| | | // convert to stereo, float |
|---|
| | | pcmf32s.resize(2); |
|---|
| | | |
|---|
| | | pcmf32s[0].resize(n); |
|---|
| | | pcmf32s[1].resize(n); |
|---|
| | | for (uint64_t i = 0; i < n; i++) { |
|---|
| | | pcmf32s[0][i] = float(pcm16[2*i])/32768.0f; |
|---|
| | | pcmf32s[1][i] = float(pcm16[2*i + 1])/32768.0f; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void high_pass_filter(std::vector<float> & data, float cutoff, float sample_rate) { |
|---|
| | | const float rc = 1.0f / (2.0f * M_PI * cutoff); |
|---|
| | | const float dt = 1.0f / sample_rate; |
|---|
| | | const float alpha = dt / (rc + dt); |
|---|
| | | |
|---|
| | | float y = data[0]; |
|---|
| | | |
|---|
| | | for (size_t i = 1; i < data.size(); i++) { |
|---|
| | | y = alpha * (y + data[i] - data[i - 1]); |
|---|
| | | data[i] = y; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool vad_simple(std::vector<float> & pcmf32, int sample_rate, int last_ms, float vad_thold, float freq_thold, bool verbose) { |
|---|
| | | const int n_samples = pcmf32.size(); |
|---|
| | | const int n_samples_last = (sample_rate * last_ms) / 1000; |
|---|
| | | |
|---|
| | | if (n_samples_last >= n_samples) { |
|---|
| | | // not enough samples - assume no speech |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (freq_thold > 0.0f) { |
|---|
| | | high_pass_filter(pcmf32, freq_thold, sample_rate); |
|---|
| | | } |
|---|
| | | |
|---|
| | | float energy_all = 0.0f; |
|---|
| | | float energy_last = 0.0f; |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_samples; i++) { |
|---|
| | | energy_all += fabsf(pcmf32[i]); |
|---|
| | | |
|---|
| | | if (i >= n_samples - n_samples_last) { |
|---|
| | | energy_last += fabsf(pcmf32[i]); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | energy_all /= n_samples; |
|---|
| | | energy_last /= n_samples_last; |
|---|
| | | |
|---|
| | | if (verbose) { |
|---|
| | | fprintf(stderr, "%s: energy_all: %f, energy_last: %f, vad_thold: %f, freq_thold: %f\n", __func__, energy_all, energy_last, vad_thold, freq_thold); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (energy_last > vad_thold*energy_all) { |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | float similarity(const std::string & s0, const std::string & s1) { |
|---|
| | | const size_t len0 = s0.size() + 1; |
|---|
| | | const size_t len1 = s1.size() + 1; |
|---|
| | | |
|---|
| | | std::vector<int> col(len1, 0); |
|---|
| | | std::vector<int> prevCol(len1, 0); |
|---|
| | | |
|---|
| | | for (size_t i = 0; i < len1; i++) { |
|---|
| | | prevCol[i] = i; |
|---|
| | | } |
|---|
| | | |
|---|
| | | for (size_t i = 0; i < len0; i++) { |
|---|
| | | col[0] = i; |
|---|
| | | for (size_t j = 1; j < len1; j++) { |
|---|
| | | col[j] = std::min(std::min(1 + col[j - 1], 1 + prevCol[j]), prevCol[j - 1] + (i > 0 && s0[i - 1] == s1[j - 1] ? 0 : 1)); |
|---|
| | | } |
|---|
| | | col.swap(prevCol); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const float dist = prevCol[len1 - 1]; |
|---|
| | | |
|---|
| | | return 1.0f - (dist / std::max(s0.size(), s1.size())); |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool sam_params_parse(int argc, char ** argv, sam_params & params) { |
|---|
| | | for (int i = 1; i < argc; i++) { |
|---|
| | | std::string arg = argv[i]; |
|---|
| | | |
|---|
| | | if (arg == "-s" || arg == "--seed") { |
|---|
| | | params.seed = std::stoi(argv[++i]); |
|---|
| | | } else if (arg == "-t" || arg == "--threads") { |
|---|
| | | params.n_threads = std::stoi(argv[++i]); |
|---|
| | | } else if (arg == "-m" || arg == "--model") { |
|---|
| | | params.model = argv[++i]; |
|---|
| | | } else if (arg == "-i" || arg == "--inp") { |
|---|
| | | params.fname_inp = argv[++i]; |
|---|
| | | } else if (arg == "-o" || arg == "--out") { |
|---|
| | | params.fname_out = argv[++i]; |
|---|
| | | } else if (arg == "-h" || arg == "--help") { |
|---|
| | | sam_print_usage(argc, argv, params); |
|---|
| | | exit(0); |
|---|
| | | } else { |
|---|
| | | fprintf(stderr, "error: unknown argument: %s\n", arg.c_str()); |
|---|
| | | sam_print_usage(argc, argv, params); |
|---|
| | | exit(0); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void sam_print_usage(int /*argc*/, char ** argv, const sam_params & params) { |
|---|
| | | fprintf(stderr, "usage: %s [options]\n", argv[0]); |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | fprintf(stderr, "options:\n"); |
|---|
| | | fprintf(stderr, " -h, --help show this help message and exit\n"); |
|---|
| | | fprintf(stderr, " -s SEED, --seed SEED RNG seed (default: -1)\n"); |
|---|
| | | fprintf(stderr, " -t N, --threads N number of threads to use during computation (default: %d)\n", params.n_threads); |
|---|
| | | fprintf(stderr, " -m FNAME, --model FNAME\n"); |
|---|
| | | fprintf(stderr, " model path (default: %s)\n", params.model.c_str()); |
|---|
| | | fprintf(stderr, " -i FNAME, --inp FNAME\n"); |
|---|
| | | fprintf(stderr, " input file (default: %s)\n", params.fname_inp.c_str()); |
|---|
| | | fprintf(stderr, " -o FNAME, --out FNAME\n"); |
|---|
| | | fprintf(stderr, " output file (default: %s)\n", params.fname_out.c_str()); |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | // Various helper functions and utilities |
|---|
| | | |
|---|
| | | #pragma once |
|---|
| | | |
|---|
| | | #include <string> |
|---|
| | | #include <map> |
|---|
| | | #include <vector> |
|---|
| | | #include <random> |
|---|
| | | #include <thread> |
|---|
| | | #include <ctime> |
|---|
| | | #include <fstream> |
|---|
| | | |
|---|
| | | #define COMMON_SAMPLE_RATE 16000 |
|---|
| | | |
|---|
| | | // |
|---|
| | | // GPT CLI argument parsing |
|---|
| | | // |
|---|
| | | |
|---|
| | | struct gpt_params { |
|---|
| | | int32_t seed = -1; // RNG seed |
|---|
| | | int32_t n_threads = std::min(4, (int32_t) std::thread::hardware_concurrency()); |
|---|
| | | int32_t n_predict = 200; // new tokens to predict |
|---|
| | | int32_t n_parallel = 1; // number of parallel streams |
|---|
| | | int32_t n_batch = 8; // batch size for prompt processing |
|---|
| | | int32_t n_ctx = 2048; // context size (this is the KV cache max size) |
|---|
| | | int32_t n_gpu_layers = 0; // number of layers to offlload to the GPU |
|---|
| | | |
|---|
| | | bool ignore_eos = false; // ignore EOS token when generating text |
|---|
| | | |
|---|
| | | // sampling parameters |
|---|
| | | int32_t top_k = 40; |
|---|
| | | float top_p = 0.9f; |
|---|
| | | float temp = 0.9f; |
|---|
| | | int32_t repeat_last_n = 64; |
|---|
| | | float repeat_penalty = 1.00f; |
|---|
| | | |
|---|
| | | std::string model = "models/gpt-2-117M/ggml-model.bin"; // model path |
|---|
| | | std::string prompt = ""; |
|---|
| | | std::string token_test = ""; |
|---|
| | | |
|---|
| | | bool interactive = false; |
|---|
| | | int32_t interactive_port = -1; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | bool gpt_params_parse(int argc, char ** argv, gpt_params & params); |
|---|
| | | |
|---|
| | | void gpt_print_usage(int argc, char ** argv, const gpt_params & params); |
|---|
| | | |
|---|
| | | std::string gpt_random_prompt(std::mt19937 & rng); |
|---|
| | | |
|---|
| | | // |
|---|
| | | // Vocab utils |
|---|
| | | // |
|---|
| | | |
|---|
| | | std::string trim(const std::string & s); |
|---|
| | | |
|---|
| | | std::string replace( |
|---|
| | | const std::string & s, |
|---|
| | | const std::string & from, |
|---|
| | | const std::string & to); |
|---|
| | | |
|---|
| | | struct gpt_vocab { |
|---|
| | | using id = int32_t; |
|---|
| | | using token = std::string; |
|---|
| | | |
|---|
| | | std::map<token, id> token_to_id; |
|---|
| | | std::map<id, token> id_to_token; |
|---|
| | | std::vector<std::string> special_tokens; |
|---|
| | | |
|---|
| | | void add_special_token(const std::string & token); |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // poor-man's JSON parsing |
|---|
| | | std::map<std::string, int32_t> json_parse(const std::string & fname); |
|---|
| | | |
|---|
| | | std::string convert_to_utf8(const std::wstring & input); |
|---|
| | | |
|---|
| | | std::wstring convert_to_wstring(const std::string & input); |
|---|
| | | |
|---|
| | | void gpt_split_words(std::string str, std::vector<std::string>& words); |
|---|
| | | |
|---|
| | | // split text into tokens |
|---|
| | | // |
|---|
| | | // ref: https://github.com/openai/gpt-2/blob/a74da5d99abaaba920de8131d64da2862a8f213b/src/encoder.py#L53 |
|---|
| | | // |
|---|
| | | // Regex (Python): |
|---|
| | | // r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""" |
|---|
| | | // |
|---|
| | | // Regex (C++): |
|---|
| | | // R"('s|'t|'re|'ve|'m|'ll|'d| ?[[:alpha:]]+| ?[[:digit:]]+| ?[^\s[:alpha:][:digit:]]+|\s+(?!\S)|\s+)" |
|---|
| | | // |
|---|
| | | std::vector<gpt_vocab::id> gpt_tokenize(const gpt_vocab & vocab, const std::string & text); |
|---|
| | | |
|---|
| | | // test outputs of gpt_tokenize |
|---|
| | | // |
|---|
| | | // - compare with tokens generated by the huggingface tokenizer |
|---|
| | | // - test cases are chosen based on the model's main language (under 'prompt' directory) |
|---|
| | | // - if all sentences are tokenized identically, print 'All tests passed.' |
|---|
| | | // - otherwise, print sentence, huggingface tokens, ggml tokens |
|---|
| | | // |
|---|
| | | void test_gpt_tokenizer(gpt_vocab & vocab, const std::string & fpath_test); |
|---|
| | | |
|---|
| | | // load the tokens from encoder.json |
|---|
| | | bool gpt_vocab_init(const std::string & fname, gpt_vocab & vocab); |
|---|
| | | |
|---|
| | | // sample next token given probabilities for each embedding |
|---|
| | | // |
|---|
| | | // - consider only the top K tokens |
|---|
| | | // - from them, consider only the top tokens with cumulative probability > P |
|---|
| | | // |
|---|
| | | // TODO: not sure if this implementation is correct |
|---|
| | | // TODO: temperature is not implemented |
|---|
| | | // |
|---|
| | | gpt_vocab::id gpt_sample_top_k_top_p( |
|---|
| | | const gpt_vocab & vocab, |
|---|
| | | const float * logits, |
|---|
| | | int top_k, |
|---|
| | | double top_p, |
|---|
| | | double temp, |
|---|
| | | std::mt19937 & rng); |
|---|
| | | |
|---|
| | | gpt_vocab::id gpt_sample_top_k_top_p_repeat( |
|---|
| | | const gpt_vocab & vocab, |
|---|
| | | const float * logits, |
|---|
| | | const int32_t * last_n_tokens_data, |
|---|
| | | size_t last_n_tokens_data_size, |
|---|
| | | int top_k, |
|---|
| | | double top_p, |
|---|
| | | double temp, |
|---|
| | | int repeat_last_n, |
|---|
| | | float repeat_penalty, |
|---|
| | | std::mt19937 & rng); |
|---|
| | | |
|---|
| | | // |
|---|
| | | // Audio utils |
|---|
| | | // |
|---|
| | | |
|---|
| | | // Read WAV audio file and store the PCM data into pcmf32 |
|---|
| | | // The sample rate of the audio must be equal to COMMON_SAMPLE_RATE |
|---|
| | | // If stereo flag is set and the audio has 2 channels, the pcmf32s will contain 2 channel PCM |
|---|
| | | bool read_wav( |
|---|
| | | const std::string & fname, |
|---|
| | | std::vector<float> & pcmf32, |
|---|
| | | std::vector<std::vector<float>> & pcmf32s, |
|---|
| | | bool stereo); |
|---|
| | | |
|---|
| | | // Write PCM data into WAV audio file |
|---|
| | | class wav_writer { |
|---|
| | | private: |
|---|
| | | std::ofstream file; |
|---|
| | | uint32_t dataSize = 0; |
|---|
| | | std::string wav_filename; |
|---|
| | | |
|---|
| | | bool write_header(const uint32_t sample_rate, |
|---|
| | | const uint16_t bits_per_sample, |
|---|
| | | const uint16_t channels) { |
|---|
| | | |
|---|
| | | file.write("RIFF", 4); |
|---|
| | | file.write("\0\0\0\0", 4); // Placeholder for file size |
|---|
| | | file.write("WAVE", 4); |
|---|
| | | file.write("fmt ", 4); |
|---|
| | | |
|---|
| | | const uint32_t sub_chunk_size = 16; |
|---|
| | | const uint16_t audio_format = 1; // PCM format |
|---|
| | | const uint32_t byte_rate = sample_rate * channels * bits_per_sample / 8; |
|---|
| | | const uint16_t block_align = channels * bits_per_sample / 8; |
|---|
| | | |
|---|
| | | file.write(reinterpret_cast<const char *>(&sub_chunk_size), 4); |
|---|
| | | file.write(reinterpret_cast<const char *>(&audio_format), 2); |
|---|
| | | file.write(reinterpret_cast<const char *>(&channels), 2); |
|---|
| | | file.write(reinterpret_cast<const char *>(&sample_rate), 4); |
|---|
| | | file.write(reinterpret_cast<const char *>(&byte_rate), 4); |
|---|
| | | file.write(reinterpret_cast<const char *>(&block_align), 2); |
|---|
| | | file.write(reinterpret_cast<const char *>(&bits_per_sample), 2); |
|---|
| | | file.write("data", 4); |
|---|
| | | file.write("\0\0\0\0", 4); // Placeholder for data size |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // It is assumed that PCM data is normalized to a range from -1 to 1 |
|---|
| | | bool write_audio(const float * data, size_t length) { |
|---|
| | | for (size_t i = 0; i < length; ++i) { |
|---|
| | | const int16_t intSample = data[i] * 32767; |
|---|
| | | file.write(reinterpret_cast<const char *>(&intSample), sizeof(int16_t)); |
|---|
| | | dataSize += sizeof(int16_t); |
|---|
| | | } |
|---|
| | | if (file.is_open()) { |
|---|
| | | file.seekp(4, std::ios::beg); |
|---|
| | | uint32_t fileSize = 36 + dataSize; |
|---|
| | | file.write(reinterpret_cast<char *>(&fileSize), 4); |
|---|
| | | file.seekp(40, std::ios::beg); |
|---|
| | | file.write(reinterpret_cast<char *>(&dataSize), 4); |
|---|
| | | file.seekp(0, std::ios::end); |
|---|
| | | } |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool open_wav(const std::string & filename) { |
|---|
| | | if (filename != wav_filename) { |
|---|
| | | if (file.is_open()) { |
|---|
| | | file.close(); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | if (!file.is_open()) { |
|---|
| | | file.open(filename, std::ios::binary); |
|---|
| | | wav_filename = filename; |
|---|
| | | dataSize = 0; |
|---|
| | | } |
|---|
| | | return file.is_open(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | public: |
|---|
| | | bool open(const std::string & filename, |
|---|
| | | const uint32_t sample_rate, |
|---|
| | | const uint16_t bits_per_sample, |
|---|
| | | const uint16_t channels) { |
|---|
| | | |
|---|
| | | if (open_wav(filename)) { |
|---|
| | | write_header(sample_rate, bits_per_sample, channels); |
|---|
| | | } else { |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool close() { |
|---|
| | | file.close(); |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool write(const float * data, size_t length) { |
|---|
| | | return write_audio(data, length); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ~wav_writer() { |
|---|
| | | if (file.is_open()) { |
|---|
| | | file.close(); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | |
|---|
| | | // Apply a high-pass frequency filter to PCM audio |
|---|
| | | // Suppresses frequencies below cutoff Hz |
|---|
| | | void high_pass_filter( |
|---|
| | | std::vector<float> & data, |
|---|
| | | float cutoff, |
|---|
| | | float sample_rate); |
|---|
| | | |
|---|
| | | // Basic voice activity detection (VAD) using audio energy adaptive threshold |
|---|
| | | bool vad_simple( |
|---|
| | | std::vector<float> & pcmf32, |
|---|
| | | int sample_rate, |
|---|
| | | int last_ms, |
|---|
| | | float vad_thold, |
|---|
| | | float freq_thold, |
|---|
| | | bool verbose); |
|---|
| | | |
|---|
| | | // compute similarity between two strings using Levenshtein distance |
|---|
| | | float similarity(const std::string & s0, const std::string & s1); |
|---|
| | | |
|---|
| | | // |
|---|
| | | // SAM argument parsing |
|---|
| | | // |
|---|
| | | |
|---|
| | | struct sam_params { |
|---|
| | | int32_t seed = -1; // RNG seed |
|---|
| | | int32_t n_threads = std::min(4, (int32_t) std::thread::hardware_concurrency()); |
|---|
| | | |
|---|
| | | std::string model = "models/sam-vit-b/ggml-model-f16.bin"; // model path |
|---|
| | | std::string fname_inp = "img.jpg"; |
|---|
| | | std::string fname_out = "img.out"; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | bool sam_params_parse(int argc, char ** argv, sam_params & params); |
|---|
| | | |
|---|
| | | void sam_print_usage(int argc, char ** argv, const sam_params & params); |
|---|
| New file |
| | |
|---|
| | | # |
|---|
| | | # dollyv2 |
|---|
| | | |
|---|
| | | set(TEST_TARGET dollyv2) |
|---|
| | | add_executable(${TEST_TARGET} main.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| | | |
|---|
| | | # |
|---|
| | | # dollyv2-quantize |
|---|
| | | |
|---|
| | | set(TEST_TARGET dollyv2-quantize) |
|---|
| | | add_executable(${TEST_TARGET} quantize.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| New file |
| | |
|---|
| | | # Dolly-V2 |
|---|
| | | |
|---|
| | | Transformer architecture: GPT-NeoX |
|---|
| | | |
|---|
| | | Modeled from examples/stablelm |
|---|
| | | |
|---|
| | | Ref: https://github.com/databrickslabs/dolly |
|---|
| | | |
|---|
| | | Ref: https://github.com/stability-AI/stableLM/#stablelm-alpha |
|---|
| | | |
|---|
| | | ## Usage |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | # get the repo and build it |
|---|
| | | git clone https://github.com/ggerganov/ggml |
|---|
| | | cd ggml |
|---|
| | | mkdir build && cd build |
|---|
| | | cmake .. |
|---|
| | | make -j |
|---|
| | | |
|---|
| | | # get the Dolly-V2 3B model |
|---|
| | | git clone https://huggingface.co/databricks/dolly-v2-3b |
|---|
| | | |
|---|
| | | # install Python dependencies |
|---|
| | | python3 -m pip install -r ../requirements.txt |
|---|
| | | |
|---|
| | | # convert model to FP16 |
|---|
| | | python3 ../examples/dolly-v2/convert-h5-to-ggml.py ./dolly-v2-3b/ 1 |
|---|
| | | |
|---|
| | | # run inference using FP16 precision |
|---|
| | | ./bin/dollyv2 -m ./dolly-v2-3b/ggml-model-f16.bin -p "State the meaning of life." -t 6 -n 64 |
|---|
| | | |
|---|
| | | main: seed = 1683218142 |
|---|
| | | dollyv2_model_load: loading model from './dolly-v2-3b/ggml-model-f16.bin' - please wait ... |
|---|
| | | dollyv2_model_load: n_vocab = 50280 |
|---|
| | | dollyv2_model_load: n_ctx = 2048 |
|---|
| | | dollyv2_model_load: n_embd = 2560 |
|---|
| | | dollyv2_model_load: n_head = 32 |
|---|
| | | dollyv2_model_load: n_layer = 32 |
|---|
| | | dollyv2_model_load: n_rot = 20 |
|---|
| | | dollyv2_model_load: ftype = 1 |
|---|
| | | dollyv2_model_load: ggml ctx size = 7374.91 MB |
|---|
| | | dollyv2_model_load: memory_size = 640.00 MB, n_mem = 65536 |
|---|
| | | dollyv2_model_load: ................................................ done |
|---|
| | | dollyv2_model_load: model size = 5295.10 MB / num tensors = 388 |
|---|
| | | main: number of tokens in prompt = 32 |
|---|
| | | main: token[0] = 30003, Below |
|---|
| | | main: token[1] = 310, is |
|---|
| | | main: token[2] = 271, an |
|---|
| | | main: token[3] = 9775, instruction |
|---|
| | | main: token[4] = 326, that |
|---|
| | | main: token[5] = 8631, describes |
|---|
| | | main: token[6] = 247, a |
|---|
| | | main: token[7] = 4836, task |
|---|
| | | main: token[8] = 964, . |
|---|
| | | main: token[9] = 19566, Write |
|---|
| | | main: token[10] = 247, a |
|---|
| | | main: token[11] = 2380, response |
|---|
| | | main: token[12] = 326, that |
|---|
| | | main: token[13] = 20420, appropriately |
|---|
| | | main: token[14] = 29141, completes |
|---|
| | | main: token[15] = 253, the |
|---|
| | | main: token[16] = 2748, request |
|---|
| | | main: token[17] = 964, . |
|---|
| | | main: token[18] = 187, |
|---|
| | | |
|---|
| | | main: token[19] = 187, |
|---|
| | | |
|---|
| | | main: token[20] = 50278, ### Instruction: |
|---|
| | | main: token[21] = 187, |
|---|
| | | |
|---|
| | | main: token[22] = 5443, State |
|---|
| | | main: token[23] = 253, the |
|---|
| | | main: token[24] = 4495, meaning |
|---|
| | | main: token[25] = 273, of |
|---|
| | | main: token[26] = 1495, life |
|---|
| | | main: token[27] = 964, . |
|---|
| | | main: token[28] = 187, |
|---|
| | | |
|---|
| | | main: token[29] = 187, |
|---|
| | | |
|---|
| | | main: token[30] = 50279, ### Response: |
|---|
| | | main: token[31] = 187, |
|---|
| | | |
|---|
| | | |
|---|
| | | Below is an instruction that describes a task. Write a response that appropriately completes the request. |
|---|
| | | |
|---|
| | | ### Instruction: |
|---|
| | | State the meaning of life. |
|---|
| | | |
|---|
| | | ### Response: |
|---|
| | | The meaning of life is to love and be loved. |
|---|
| | | |
|---|
| | | ### End |
|---|
| | | |
|---|
| | | main: mem per token = 16136720 bytes |
|---|
| | | main: load time = 2202.58 ms |
|---|
| | | main: sample time = 2.57 ms |
|---|
| | | main: predict time = 1497.14 ms / 33.27 ms per token |
|---|
| | | main: total time = 6187.27 ms |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## 5-bit integer quantization mode |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | # quantize the model to 5-bits using Q5_0 quantization |
|---|
| | | ./bin/dollyv2-quantize ./dolly-v2-3b/ggml-model-f16.bin ./dolly-v2-3b/ggml-model-q5_0.bin q5_0 |
|---|
| | | |
|---|
| | | # run the quantized model |
|---|
| | | ./bin/dollyv2 -m ./dolly-v2-3b/ggml-model-q5_0.bin -p "State the meaning of life." -t 6 -n 64 |
|---|
| | | |
|---|
| | | main: seed = 1683218518 |
|---|
| | | dollyv2_model_load: loading model from './dolly-v2-3b/ggml-model-q5_0.bin' - please wait ... |
|---|
| | | dollyv2_model_load: n_vocab = 50280 |
|---|
| | | dollyv2_model_load: n_ctx = 2048 |
|---|
| | | dollyv2_model_load: n_embd = 2560 |
|---|
| | | dollyv2_model_load: n_head = 32 |
|---|
| | | dollyv2_model_load: n_layer = 32 |
|---|
| | | dollyv2_model_load: n_rot = 20 |
|---|
| | | dollyv2_model_load: ftype = 8 |
|---|
| | | dollyv2_model_load: ggml ctx size = 3902.68 MB |
|---|
| | | dollyv2_model_load: memory_size = 640.00 MB, n_mem = 65536 |
|---|
| | | dollyv2_model_load: ................................................ done |
|---|
| | | dollyv2_model_load: model size = 1822.87 MB / num tensors = 388 |
|---|
| | | main: number of tokens in prompt = 32 |
|---|
| | | main: token[0] = 30003, Below |
|---|
| | | main: token[1] = 310, is |
|---|
| | | main: token[2] = 271, an |
|---|
| | | main: token[3] = 9775, instruction |
|---|
| | | main: token[4] = 326, that |
|---|
| | | main: token[5] = 8631, describes |
|---|
| | | main: token[6] = 247, a |
|---|
| | | main: token[7] = 4836, task |
|---|
| | | main: token[8] = 964, . |
|---|
| | | main: token[9] = 19566, Write |
|---|
| | | main: token[10] = 247, a |
|---|
| | | main: token[11] = 2380, response |
|---|
| | | main: token[12] = 326, that |
|---|
| | | main: token[13] = 20420, appropriately |
|---|
| | | main: token[14] = 29141, completes |
|---|
| | | main: token[15] = 253, the |
|---|
| | | main: token[16] = 2748, request |
|---|
| | | main: token[17] = 964, . |
|---|
| | | main: token[18] = 187, |
|---|
| | | |
|---|
| | | main: token[19] = 187, |
|---|
| | | |
|---|
| | | main: token[20] = 50278, ### Instruction: |
|---|
| | | main: token[21] = 187, |
|---|
| | | |
|---|
| | | main: token[22] = 5443, State |
|---|
| | | main: token[23] = 253, the |
|---|
| | | main: token[24] = 4495, meaning |
|---|
| | | main: token[25] = 273, of |
|---|
| | | main: token[26] = 1495, life |
|---|
| | | main: token[27] = 964, . |
|---|
| | | main: token[28] = 187, |
|---|
| | | |
|---|
| | | main: token[29] = 187, |
|---|
| | | |
|---|
| | | main: token[30] = 50279, ### Response: |
|---|
| | | main: token[31] = 187, |
|---|
| | | |
|---|
| | | |
|---|
| | | Below is an instruction that describes a task. Write a response that appropriately completes the request. |
|---|
| | | |
|---|
| | | ### Instruction: |
|---|
| | | State the meaning of life. |
|---|
| | | |
|---|
| | | ### Response: |
|---|
| | | The meaning of life is the discovery of the true self. |
|---|
| | | |
|---|
| | | ### End |
|---|
| | | |
|---|
| | | main: mem per token = 16127760 bytes |
|---|
| | | main: load time = 1011.09 ms |
|---|
| | | main: sample time = 2.79 ms |
|---|
| | | main: predict time = 1271.62 ms / 27.64 ms per token |
|---|
| | | main: total time = 2802.51 ms |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Notes |
|---|
| | | |
|---|
| | | - No guarantees for correctness |
|---|
| | | - The tokenizer is currently hacked - probably works only for English |
|---|
| | | - Non-parallel residual is not supported |
|---|
| | | - Contributions and improvements are welcome |
|---|
| New file |
| | |
|---|
| | | import sys |
|---|
| | | import struct |
|---|
| | | import json |
|---|
| | | import numpy as np |
|---|
| | | |
|---|
| | | from transformers import AutoModelForCausalLM, AutoTokenizer |
|---|
| | | |
|---|
| | | if len(sys.argv) < 3: |
|---|
| | | print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n") |
|---|
| | | print(" ftype == 0 -> float32") |
|---|
| | | print(" ftype == 1 -> float16") |
|---|
| | | sys.exit(1) |
|---|
| | | |
|---|
| | | # output in the same directory as the model |
|---|
| | | dir_model = sys.argv[1] |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model.bin" |
|---|
| | | |
|---|
| | | with open(dir_model + "/tokenizer.json", "r", encoding="utf-8") as f: |
|---|
| | | encoder = json.load(f) |
|---|
| | | |
|---|
| | | with open(dir_model + "/config.json", "r", encoding="utf-8") as f: |
|---|
| | | hparams = json.load(f) |
|---|
| | | |
|---|
| | | # possible data types |
|---|
| | | # ftype == 0 -> float32 |
|---|
| | | # ftype == 1 -> float16 |
|---|
| | | # |
|---|
| | | # map from ftype to string |
|---|
| | | ftype_str = ["f32", "f16"] |
|---|
| | | |
|---|
| | | ftype = 1 |
|---|
| | | if len(sys.argv) > 2: |
|---|
| | | ftype = int(sys.argv[2]) |
|---|
| | | if ftype < 0 or ftype > 1: |
|---|
| | | print("Invalid ftype: " + str(ftype)) |
|---|
| | | sys.exit(1) |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model-" + ftype_str[ftype] + ".bin" |
|---|
| | | |
|---|
| | | |
|---|
| | | tokenizer = AutoTokenizer.from_pretrained(dir_model) |
|---|
| | | model = AutoModelForCausalLM.from_pretrained(dir_model, low_cpu_mem_usage=True) |
|---|
| | | #print (model) |
|---|
| | | |
|---|
| | | #print(tokenizer.encode('I believe the meaning of life is')) |
|---|
| | | |
|---|
| | | list_vars = model.state_dict() |
|---|
| | | for name in list_vars.keys(): |
|---|
| | | print(name, list_vars[name].shape, list_vars[name].dtype) |
|---|
| | | |
|---|
| | | fout = open(fname_out, "wb") |
|---|
| | | |
|---|
| | | print(hparams) |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex |
|---|
| | | fout.write(struct.pack("i", hparams["vocab_size"])) |
|---|
| | | fout.write(struct.pack("i", hparams["max_position_embeddings"])) |
|---|
| | | fout.write(struct.pack("i", hparams["hidden_size"])) |
|---|
| | | fout.write(struct.pack("i", hparams["num_attention_heads"])) |
|---|
| | | fout.write(struct.pack("i", hparams["num_hidden_layers"])) |
|---|
| | | fout.write(struct.pack("i", int(hparams["rotary_pct"]*(hparams["hidden_size"]//hparams["num_attention_heads"])))) |
|---|
| | | fout.write(struct.pack("i", hparams["use_parallel_residual"])) |
|---|
| | | fout.write(struct.pack("i", ftype)) |
|---|
| | | |
|---|
| | | # TODO: temporary hack to not deal with implementing the tokenizer |
|---|
| | | dot_token = tokenizer.encode('.')[0] |
|---|
| | | for i in range(hparams["vocab_size"]): |
|---|
| | | text = tokenizer.decode([dot_token, i]).encode('utf-8') |
|---|
| | | # remove the first byte (it's always '.') |
|---|
| | | text = text[1:] |
|---|
| | | fout.write(struct.pack("i", len(text))) |
|---|
| | | fout.write(text) |
|---|
| | | |
|---|
| | | for name in list_vars.keys(): |
|---|
| | | data = list_vars[name].squeeze().numpy() |
|---|
| | | print("Processing variable: " + name + " with shape: ", data.shape) |
|---|
| | | |
|---|
| | | # we don't need these |
|---|
| | | if name.endswith(".attention.masked_bias") or \ |
|---|
| | | name.endswith(".attention.bias") or \ |
|---|
| | | name.endswith(".attention.rotary_emb.inv_freq"): |
|---|
| | | print(" Skipping variable: " + name) |
|---|
| | | continue |
|---|
| | | |
|---|
| | | n_dims = len(data.shape); |
|---|
| | | |
|---|
| | | # ftype == 0 -> float32, ftype == 1 -> float16 |
|---|
| | | ftype_cur = 0; |
|---|
| | | if ftype != 0: |
|---|
| | | if name[-7:] == ".weight" and n_dims == 2: |
|---|
| | | print(" Converting to float16") |
|---|
| | | data = data.astype(np.float16) |
|---|
| | | ftype_cur = 1 |
|---|
| | | else: |
|---|
| | | print(" Converting to float32") |
|---|
| | | data = data.astype(np.float32) |
|---|
| | | ftype_cur = 0 |
|---|
| | | else: |
|---|
| | | if data.dtype != np.float32: |
|---|
| | | print(" Converting to float32") |
|---|
| | | data = data.astype(np.float32) |
|---|
| | | ftype_cur = 0 |
|---|
| | | |
|---|
| | | # header |
|---|
| | | str = name.encode('utf-8') |
|---|
| | | fout.write(struct.pack("iii", n_dims, len(str), ftype_cur)) |
|---|
| | | for i in range(n_dims): |
|---|
| | | fout.write(struct.pack("i", data.shape[n_dims - 1 - i])) |
|---|
| | | fout.write(str); |
|---|
| | | |
|---|
| | | # data |
|---|
| | | data.tofile(fout) |
|---|
| | | |
|---|
| | | fout.close() |
|---|
| | | |
|---|
| | | print("Done. Output file: " + fname_out) |
|---|
| | | print("") |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <cinttypes> |
|---|
| | | #include <fstream> |
|---|
| | | #include <iostream> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | #if !defined(_WIN32) |
|---|
| | | #define DOLLY_INTERACTIVE_PORT |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #if defined(DOLLY_INTERACTIVE_PORT) |
|---|
| | | #include <arpa/inet.h> |
|---|
| | | #include <netinet/in.h> |
|---|
| | | #include <sys/socket.h> |
|---|
| | | #include <unistd.h> |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | // default hparams (Dolly-V2 3B) |
|---|
| | | struct dollyv2_hparams { |
|---|
| | | int32_t n_vocab = 50254; // tokenizer.vocab_size |
|---|
| | | int32_t n_ctx = 2048; // model.config.max_position_embeddings |
|---|
| | | int32_t n_embd = 2560; // model.config.hidden_size |
|---|
| | | int32_t n_head = 32; // model.config.num_attention_heads |
|---|
| | | int32_t n_layer = 32; // model.config.num_hidden_layers |
|---|
| | | int32_t n_rot = 20; // rotary_pct[25%] * (n_embd / n_head) |
|---|
| | | int32_t par_res = 1; // 1 = true, 0 = false |
|---|
| | | int32_t ftype = GGML_FTYPE_MOSTLY_F16; |
|---|
| | | float eps = 1e-5f; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | const std::string INSTRUCTION_KEY = "### Instruction:"; |
|---|
| | | const std::string RESPONSE_KEY = "### Response:"; |
|---|
| | | const std::string END_KEY = "### End"; |
|---|
| | | const std::string INTRO_BLURB = "Below is an instruction that describes a task. Write a response that appropriately completes the request."; |
|---|
| | | |
|---|
| | | // dollyv2 prompt format |
|---|
| | | std::string prompt_for_generation(const std::string& instruction) { |
|---|
| | | return INTRO_BLURB + "\n\n" + INSTRUCTION_KEY + "\n" + instruction + "\n\n" + RESPONSE_KEY + "\n"; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct dollyv2_layer { |
|---|
| | | // pre normalization |
|---|
| | | struct ggml_tensor * ln_1_g; |
|---|
| | | struct ggml_tensor * ln_1_b; |
|---|
| | | |
|---|
| | | // attention |
|---|
| | | struct ggml_tensor * c_attn_attn_w; |
|---|
| | | struct ggml_tensor * c_attn_attn_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_attn_proj_w; |
|---|
| | | struct ggml_tensor * c_attn_proj_b; |
|---|
| | | |
|---|
| | | // post normalization |
|---|
| | | struct ggml_tensor * ln_2_g; |
|---|
| | | struct ggml_tensor * ln_2_b; |
|---|
| | | |
|---|
| | | // ff |
|---|
| | | struct ggml_tensor * c_mlp_fc_w; |
|---|
| | | struct ggml_tensor * c_mlp_fc_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_mlp_proj_w; |
|---|
| | | struct ggml_tensor * c_mlp_proj_b; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct dollyv2_model { |
|---|
| | | dollyv2_hparams hparams; |
|---|
| | | |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_f_g; |
|---|
| | | struct ggml_tensor * ln_f_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * wte; // position embedding |
|---|
| | | |
|---|
| | | struct ggml_tensor * lmh_g; // language model head |
|---|
| | | //struct ggml_tensor * lmh_b; // language model bias |
|---|
| | | |
|---|
| | | std::vector<dollyv2_layer> layers; |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | struct ggml_tensor * memory_k; |
|---|
| | | struct ggml_tensor * memory_v; |
|---|
| | | |
|---|
| | | // |
|---|
| | | struct ggml_context * ctx; |
|---|
| | | std::map<std::string, struct ggml_tensor *> tensors; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // load the model's weights from a file |
|---|
| | | bool dollyv2_model_load(const std::string & fname, dollyv2_model & model, gpt_vocab & vocab) { |
|---|
| | | printf("%s: loading model from '%s' - please wait ...\n", __func__, fname.c_str()); |
|---|
| | | |
|---|
| | | auto fin = std::ifstream(fname, std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | fin.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fin.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fin.read((char *) &hparams.n_rot, sizeof(hparams.n_rot)); |
|---|
| | | fin.read((char *) &hparams.par_res, sizeof(hparams.par_res)); |
|---|
| | | fin.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: n_rot = %d\n", __func__, hparams.n_rot); |
|---|
| | | printf("%s: par_res = %d\n", __func__, hparams.par_res); |
|---|
| | | printf("%s: ftype = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr = %d\n", __func__, qntvr); |
|---|
| | | |
|---|
| | | hparams.ftype %= GGML_QNT_VERSION_FACTOR; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | const int32_t n_vocab = model.hparams.n_vocab; |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | std::vector<char> buf(128); |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | fin.read((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | buf.resize(len); |
|---|
| | | fin.read((char *) buf.data(), len); |
|---|
| | | word.assign(buf.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | |
|---|
| | | vocab.add_special_token("### End"); |
|---|
| | | vocab.add_special_token("### Instruction:"); |
|---|
| | | vocab.add_special_token("### Response:"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for the big tensors, we have the option to store the data in 16-bit floats or quantized |
|---|
| | | // in order to save memory and also to speed up the computation |
|---|
| | | ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype)); |
|---|
| | | if (wtype == GGML_TYPE_COUNT) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n", |
|---|
| | | __func__, fname.c_str(), model.hparams.ftype); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto & ctx = model.ctx; |
|---|
| | | |
|---|
| | | size_t ctx_size = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_g |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_b |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(wtype, n_embd*n_vocab); // wte |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(wtype, n_embd*n_vocab); // lmh_g |
|---|
| | | //ctx_size += ggml_row_size(GGML_TYPE_F32, n_vocab); // lmh_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_g |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 3*n_embd*n_embd)); // c_attn_attn_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 3*n_embd)); // c_attn_attn_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, n_embd*n_embd)); // c_attn_proj_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd*n_embd)); // c_attn_proj_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_2_g |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_2_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_fc_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 4*n_embd)); // c_mlp_fc_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_proj_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // c_mlp_proj_b |
|---|
| | | |
|---|
| | | ctx_size += n_ctx*n_layer*ggml_row_size(GGML_TYPE_F32, n_embd); // memory_k |
|---|
| | | ctx_size += n_ctx*n_layer*ggml_row_size(GGML_TYPE_F32, n_embd); // memory_v |
|---|
| | | |
|---|
| | | ctx_size += (6 + 16*n_layer)*512; // object overhead |
|---|
| | | |
|---|
| | | printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // create the ggml context |
|---|
| | | { |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ ctx_size, |
|---|
| | | /*.mem_buffer =*/ NULL, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | model.ctx = ggml_init(params); |
|---|
| | | if (!model.ctx) { |
|---|
| | | fprintf(stderr, "%s: ggml_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // prepare memory for the weights |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | model.layers.resize(n_layer); |
|---|
| | | |
|---|
| | | model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | |
|---|
| | | model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | model.lmh_g = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | //model.lmh_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_vocab); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["gpt_neox.embed_in.weight"] = model.wte; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.final_layer_norm.weight"] = model.ln_f_g; |
|---|
| | | model.tensors["gpt_neox.final_layer_norm.bias"] = model.ln_f_b; |
|---|
| | | |
|---|
| | | model.tensors["embed_out.weight"] = model.lmh_g; |
|---|
| | | //model.tensors["lm_head.bias"] = model.lmh_b; |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_layer; ++i) { |
|---|
| | | auto & layer = model.layers[i]; |
|---|
| | | |
|---|
| | | layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_attn_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 3*n_embd); |
|---|
| | | layer.c_attn_attn_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 3*n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | layer.c_attn_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.ln_2_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_2_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd); |
|---|
| | | layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd); |
|---|
| | | layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | |
|---|
| | | // unmapped: attention.rotary_emb, mlp.act |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".input_layernorm.weight"] = layer.ln_1_g; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".input_layernorm.bias"] = layer.ln_1_b; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.query_key_value.weight"] = layer.c_attn_attn_w; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.query_key_value.bias"] = layer.c_attn_attn_b; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.dense.weight"] = layer.c_attn_proj_w; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.dense.bias"] = layer.c_attn_proj_b; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".post_attention_layernorm.weight"] = layer.ln_2_g; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".post_attention_layernorm.bias"] = layer.ln_2_b; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_h_to_4h.weight"] = layer.c_mlp_fc_w; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_h_to_4h.bias"] = layer.c_mlp_fc_b; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_4h_to_h.weight"] = layer.c_mlp_proj_w; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_4h_to_h.bias"] = layer.c_mlp_proj_b; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | |
|---|
| | | const int64_t n_mem = n_layer*n_ctx; |
|---|
| | | const int64_t n_elements = n_embd*n_mem; |
|---|
| | | |
|---|
| | | model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements); |
|---|
| | | model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements); |
|---|
| | | |
|---|
| | | const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v); |
|---|
| | | |
|---|
| | | printf("%s: memory_size = %8.2f MB, n_mem = %" PRId64 "\n", __func__, memory_size/1024.0/1024.0, n_mem); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load weights |
|---|
| | | { |
|---|
| | | int n_tensors = 0; |
|---|
| | | size_t total_size = 0; |
|---|
| | | |
|---|
| | | printf("%s: ", __func__); |
|---|
| | | |
|---|
| | | while (true) { |
|---|
| | | int32_t n_dims; |
|---|
| | | int32_t length; |
|---|
| | | int32_t ttype; |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&length), sizeof(length)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype)); |
|---|
| | | |
|---|
| | | if (fin.eof()) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int32_t nelements = 1; |
|---|
| | | int32_t ne[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i])); |
|---|
| | | nelements *= ne[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string name(length, 0); |
|---|
| | | fin.read(&name[0], length); |
|---|
| | | |
|---|
| | | if (model.tensors.find(name) == model.tensors.end()) { |
|---|
| | | fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto tensor = model.tensors[name]; |
|---|
| | | if (ggml_nelements(tensor) != nelements) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%5d, %5d], expected [%5d, %5d]\n", |
|---|
| | | __func__, name.c_str(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for debugging |
|---|
| | | if (0) { |
|---|
| | | printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.c_str(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const size_t bpe = ggml_type_size(ggml_type(ttype)); |
|---|
| | | |
|---|
| | | if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n", |
|---|
| | | __func__, name.c_str(), ggml_nbytes(tensor), nelements*bpe); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor)); |
|---|
| | | |
|---|
| | | total_size += ggml_nbytes(tensor); |
|---|
| | | if (++n_tensors % 8 == 0) { |
|---|
| | | printf("."); |
|---|
| | | fflush(stdout); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf(" done\n"); |
|---|
| | | |
|---|
| | | printf("%s: model size = %8.2f MB / num tensors = %d\n", __func__, total_size/1024.0/1024.0, n_tensors); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // feed-forward network |
|---|
| | | ggml_tensor * gpt_neox_ff( |
|---|
| | | const dollyv2_layer & layer, |
|---|
| | | ggml_context * ctx0, |
|---|
| | | ggml_tensor * inp, |
|---|
| | | float eps) { |
|---|
| | | ggml_tensor * cur = ggml_norm(ctx0, inp, eps); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, layer.ln_2_g, cur), |
|---|
| | | cur), |
|---|
| | | ggml_repeat(ctx0, layer.ln_2_b, cur)); |
|---|
| | | |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | layer.c_mlp_fc_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, layer.c_mlp_fc_b, cur), |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | // GELU activation |
|---|
| | | cur = ggml_gelu(ctx0, cur); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | layer.c_mlp_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, layer.c_mlp_proj_b, cur), |
|---|
| | | cur); |
|---|
| | | return cur; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // evaluate the transformer |
|---|
| | | // |
|---|
| | | // - model: the model |
|---|
| | | // - n_threads: number of threads to use |
|---|
| | | // - n_past: the context size so far |
|---|
| | | // - embd_inp: the embeddings of the tokens in the context |
|---|
| | | // - embd_w: the predicted logits for the next token |
|---|
| | | // |
|---|
| | | bool dollyv2_eval( |
|---|
| | | const dollyv2_model & model, |
|---|
| | | const int n_threads, |
|---|
| | | const int n_past, |
|---|
| | | const std::vector<gpt_vocab::id> & embd_inp, |
|---|
| | | std::vector<float> & embd_w, |
|---|
| | | size_t & mem_per_token) { |
|---|
| | | const int N = embd_inp.size(); |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_head = hparams.n_head; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | const int n_rot = hparams.n_rot; |
|---|
| | | |
|---|
| | | static size_t buf_size = 256u*1024*1024; |
|---|
| | | static void * buf = malloc(buf_size); |
|---|
| | | |
|---|
| | | if (mem_per_token > 0 && mem_per_token*N > buf_size) { |
|---|
| | | const size_t buf_size_new = 1.1*(mem_per_token*N); // add 10% to account for ggml object overhead |
|---|
| | | //printf("\n%s: reallocating buffer from %zu to %zu bytes\n", __func__, buf_size, buf_size_new); |
|---|
| | | |
|---|
| | | // reallocate |
|---|
| | | buf_size = buf_size_new; |
|---|
| | | buf = realloc(buf, buf_size); |
|---|
| | | if (buf == nullptr) { |
|---|
| | | fprintf(stderr, "%s: failed to allocate %zu bytes\n", __func__, buf_size); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx0 = ggml_init(params); |
|---|
| | | struct ggml_cgraph * gf = ggml_new_graph(ctx0); |
|---|
| | | |
|---|
| | | // KQ_pos - contains the positions |
|---|
| | | struct ggml_tensor * KQ_pos = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | int * data = (int *) KQ_pos->data; |
|---|
| | | for (int i = 0; i < N; ++i) { |
|---|
| | | data[i] = n_past + i; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | memcpy(embd->data, embd_inp.data(), N*ggml_element_size(embd)); |
|---|
| | | |
|---|
| | | // wte |
|---|
| | | struct ggml_tensor * inpL = ggml_get_rows(ctx0, model.wte, embd); |
|---|
| | | |
|---|
| | | for (int il = 0; il < n_layer; ++il) { |
|---|
| | | struct ggml_tensor * cur; |
|---|
| | | |
|---|
| | | // self-attention |
|---|
| | | { |
|---|
| | | { |
|---|
| | | cur = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_1_g, cur), |
|---|
| | | cur), |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_1_b, cur)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // compute QKV |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_attn_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_attn_attn_b, cur), |
|---|
| | | cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * Qcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 0*sizeof(float)*n_embd/n_head)); |
|---|
| | | struct ggml_tensor * Kcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 1*sizeof(float)*n_embd/n_head)); |
|---|
| | | struct ggml_tensor * Vcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 2*sizeof(float)*n_embd/n_head)); |
|---|
| | | |
|---|
| | | // using mode = 2 for GPT-NeoX mode |
|---|
| | | Qcur = ggml_rope_inplace(ctx0, Qcur, KQ_pos, n_rot, 2, 0); |
|---|
| | | Kcur = ggml_rope_inplace(ctx0, Kcur, KQ_pos, n_rot, 2, 0); |
|---|
| | | |
|---|
| | | // store key and value to memory |
|---|
| | | { |
|---|
| | | Vcur = ggml_transpose(ctx0, ggml_reshape_2d(ctx0, Vcur, n_embd, N)); |
|---|
| | | |
|---|
| | | struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past)); |
|---|
| | | struct ggml_tensor * v = ggml_view_2d(ctx0, model.memory_v, N, n_embd, |
|---|
| | | ( n_ctx)*ggml_element_size(model.memory_v), |
|---|
| | | (il*n_ctx)*ggml_element_size(model.memory_v)*n_embd + n_past*ggml_element_size(model.memory_v)); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3) |
|---|
| | | struct ggml_tensor * Q = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | Qcur, |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3) |
|---|
| | | struct ggml_tensor * K = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_past + N), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // K * Q |
|---|
| | | struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); |
|---|
| | | |
|---|
| | | // KQ_scaled = KQ / sqrt(n_embd/n_head) |
|---|
| | | struct ggml_tensor * KQ_scaled = |
|---|
| | | ggml_scale_inplace(ctx0, |
|---|
| | | KQ, |
|---|
| | | 1.0f/sqrt(float(n_embd)/n_head)); |
|---|
| | | |
|---|
| | | // KQ_masked = mask_past(KQ_scaled) |
|---|
| | | struct ggml_tensor * KQ_masked = ggml_diag_mask_inf_inplace(ctx0, KQ_scaled, n_past); |
|---|
| | | |
|---|
| | | // KQ = soft_max(KQ_masked) |
|---|
| | | struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked); |
|---|
| | | |
|---|
| | | // V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous() |
|---|
| | | struct ggml_tensor * V = |
|---|
| | | ggml_view_3d(ctx0, model.memory_v, |
|---|
| | | n_past + N, n_embd/n_head, n_head, |
|---|
| | | n_ctx*ggml_element_size(model.memory_v), |
|---|
| | | n_ctx*ggml_element_size(model.memory_v)*n_embd/n_head, |
|---|
| | | il*n_ctx*ggml_element_size(model.memory_v)*n_embd); |
|---|
| | | |
|---|
| | | // KQV = transpose(V) * KQ_soft_max |
|---|
| | | struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max); |
|---|
| | | |
|---|
| | | // KQV_merged = KQV.permute(0, 2, 1, 3) |
|---|
| | | struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // cur = KQV_merged.contiguous().view(n_embd, N) |
|---|
| | | cur = ggml_cpy(ctx0, |
|---|
| | | KQV_merged, |
|---|
| | | ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N)); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, ggml_repeat(ctx0, model.layers[il].c_attn_proj_b, cur), cur); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (hparams.par_res == 0) { |
|---|
| | | struct ggml_tensor * inpFF = ggml_add(ctx0, cur, inpL); |
|---|
| | | |
|---|
| | | cur = gpt_neox_ff(model.layers[il], ctx0, inpFF, hparams.eps); |
|---|
| | | |
|---|
| | | // input for next layer |
|---|
| | | inpL = ggml_add(ctx0, cur, inpFF); |
|---|
| | | } else { |
|---|
| | | struct ggml_tensor * inpFF = cur; |
|---|
| | | |
|---|
| | | // this is independent of the self-attention result, so it could be done in parallel to the self-attention |
|---|
| | | // note here we pass inpL instead of cur |
|---|
| | | cur = gpt_neox_ff(model.layers[il], ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // layer input + FF |
|---|
| | | cur = ggml_add(ctx0, cur, inpFF); |
|---|
| | | |
|---|
| | | // input for next layer |
|---|
| | | inpL = ggml_add(ctx0, cur, inpL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | } |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | inpL = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // inpL = ln_f_g*inpL + ln_f_b |
|---|
| | | inpL = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.ln_f_g, inpL), |
|---|
| | | inpL), |
|---|
| | | ggml_repeat(ctx0, model.ln_f_b, inpL)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // lm_head |
|---|
| | | { |
|---|
| | | inpL = ggml_mul_mat(ctx0, model.lmh_g, inpL); |
|---|
| | | |
|---|
| | | //inpL = ggml_add(ctx0, |
|---|
| | | // ggml_repeat(ctx0, model.lmh_b, inpL), |
|---|
| | | // inpL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // logits -> probs |
|---|
| | | //inpL = ggml_soft_max_inplace(ctx0, inpL); |
|---|
| | | |
|---|
| | | // run the computation |
|---|
| | | ggml_build_forward_expand(gf, inpL); |
|---|
| | | ggml_graph_compute_with_ctx(ctx0, gf, n_threads); |
|---|
| | | |
|---|
| | | //if (n_past%100 == 0) { |
|---|
| | | // ggml_graph_print (&gf); |
|---|
| | | // ggml_graph_dump_dot(&gf, NULL, "gpt-2.dot"); |
|---|
| | | //} |
|---|
| | | |
|---|
| | | //embd_w.resize(n_vocab*N); |
|---|
| | | //memcpy(embd_w.data(), ggml_get_data(inpL), sizeof(float)*n_vocab*N); |
|---|
| | | |
|---|
| | | // return result for just the last token |
|---|
| | | embd_w.resize(n_vocab); |
|---|
| | | memcpy(embd_w.data(), (float *) ggml_get_data(inpL) + (n_vocab*(N-1)), sizeof(float)*n_vocab); |
|---|
| | | |
|---|
| | | if (mem_per_token == 0) { |
|---|
| | | mem_per_token = ggml_used_mem(ctx0)/N; |
|---|
| | | } |
|---|
| | | //printf("used_mem = %zu\n", ggml_used_mem(ctx0)); |
|---|
| | | |
|---|
| | | ggml_free(ctx0); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string execute_prompt( |
|---|
| | | const dollyv2_model &model, |
|---|
| | | gpt_vocab &vocab, |
|---|
| | | const std::string &prompt, |
|---|
| | | gpt_params ¶ms, |
|---|
| | | std::mt19937 &rng, |
|---|
| | | int64_t t_load_us, |
|---|
| | | int64_t t_sample_us, |
|---|
| | | int64_t t_predict_us, |
|---|
| | | size_t mem_per_token, |
|---|
| | | int n_past, |
|---|
| | | bool stream_response_to_cout = false) { |
|---|
| | | std::string output = ""; |
|---|
| | | std::vector<float> logits; |
|---|
| | | |
|---|
| | | // tokenize the prompt |
|---|
| | | std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, prompt); |
|---|
| | | |
|---|
| | | params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int)embd_inp.size()); |
|---|
| | | |
|---|
| | | printf("%s: number of tokens in prompt = %zu\n", __func__, embd_inp.size()); |
|---|
| | | for (size_t i = 0; i < embd_inp.size(); i++) { |
|---|
| | | printf("%s: token[%zu] = %6d, %s\n", __func__, i, embd_inp[i], vocab.id_to_token.at(embd_inp[i]).c_str()); |
|---|
| | | } |
|---|
| | | printf("\n"); |
|---|
| | | |
|---|
| | | std::vector<gpt_vocab::id> embd; |
|---|
| | | |
|---|
| | | dollyv2_eval(model, params.n_threads, 0, {0, 1, 2, 3}, logits, mem_per_token); |
|---|
| | | |
|---|
| | | const int32_t end_token = vocab.token_to_id["### End"]; |
|---|
| | | |
|---|
| | | for (size_t i = embd.size(); i < embd_inp.size() + params.n_predict; i++) { |
|---|
| | | // predict |
|---|
| | | if (embd.size() > 0) { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!dollyv2_eval(model, params.n_threads, n_past, embd, logits, mem_per_token)) { |
|---|
| | | printf("Failed to predict\n"); |
|---|
| | | return output; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_predict_us += ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | n_past += embd.size(); |
|---|
| | | embd.clear(); |
|---|
| | | |
|---|
| | | if (i >= embd_inp.size()) { |
|---|
| | | // sample next token |
|---|
| | | const int top_k = params.top_k; |
|---|
| | | const float top_p = params.top_p; |
|---|
| | | const float temp = params.temp; |
|---|
| | | |
|---|
| | | const int n_vocab = model.hparams.n_vocab; |
|---|
| | | |
|---|
| | | gpt_vocab::id id = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const int64_t t_start_sample_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng); |
|---|
| | | |
|---|
| | | t_sample_us += ggml_time_us() - t_start_sample_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add it to the context |
|---|
| | | embd.push_back(id); |
|---|
| | | } else { |
|---|
| | | // if here, it means we are still processing the input prompt |
|---|
| | | for (size_t k = i; k < embd_inp.size(); k++) { |
|---|
| | | embd.push_back(embd_inp[k]); |
|---|
| | | if (int32_t(embd.size()) > params.n_batch) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | i += embd.size() - 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // display text |
|---|
| | | for (auto id : embd) { |
|---|
| | | output += vocab.id_to_token[id]; |
|---|
| | | if (stream_response_to_cout) { |
|---|
| | | printf("%s", vocab.id_to_token[id].c_str()); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | if (stream_response_to_cout) { |
|---|
| | | fflush(stdout); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // end of text token |
|---|
| | | if (embd.back() == 0 || (end_token > 0 && embd.back() == end_token)) { |
|---|
| | | return output; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | return output; |
|---|
| | | } |
|---|
| | | |
|---|
| | | #if defined(DOLLY_INTERACTIVE_PORT) |
|---|
| | | int setup_port(const int port) { |
|---|
| | | int sockfd = socket(AF_INET, SOCK_STREAM, 0); |
|---|
| | | if (sockfd < 0) { |
|---|
| | | fprintf(stderr, "%s: Failed to create new socket\n", __func__); |
|---|
| | | return -1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | sockaddr_in servaddr; |
|---|
| | | std::memset(&servaddr, 0, sizeof(servaddr)); |
|---|
| | | |
|---|
| | | servaddr.sin_family = AF_INET; |
|---|
| | | servaddr.sin_addr.s_addr = htonl(INADDR_ANY); |
|---|
| | | servaddr.sin_port = htons(port); |
|---|
| | | |
|---|
| | | if (bind(sockfd, (struct sockaddr *)&servaddr, sizeof(servaddr)) < 0) { |
|---|
| | | fprintf(stderr, "%s: Failed to bind to port %i\n", __func__, port); |
|---|
| | | return -1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (listen(sockfd, 10) < 0) { |
|---|
| | | fprintf(stderr, "%s: Failed to listen to socket on port %i\n", __func__, port); |
|---|
| | | return -1; |
|---|
| | | } |
|---|
| | | return sockfd; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string read_from_port(int sockfd, int clientfd) { |
|---|
| | | if (clientfd < 0) { |
|---|
| | | fprintf(stderr, "%s: Failed to accept new connection\n", __func__); |
|---|
| | | return ""; |
|---|
| | | } |
|---|
| | | |
|---|
| | | char buffer[4096]; |
|---|
| | | std::memset(buffer, 0, sizeof(buffer)); |
|---|
| | | |
|---|
| | | if (read(clientfd, buffer, sizeof(buffer)) < 0) { |
|---|
| | | fprintf(stderr, "%s: Failed to read from client\n", __func__); |
|---|
| | | } else { |
|---|
| | | std::cout << "Received: " << buffer; |
|---|
| | | return std::string(buffer); |
|---|
| | | } |
|---|
| | | return std::string(""); |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | gpt_params params; |
|---|
| | | params.model = "models/dolly-v2-3b/ggml-model-f16.bin"; |
|---|
| | | |
|---|
| | | if (gpt_params_parse(argc, argv, params) == false) { |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.seed < 0) { |
|---|
| | | params.seed = time(NULL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: seed = %d\n", __func__, params.seed); |
|---|
| | | |
|---|
| | | std::mt19937 rng(params.seed); |
|---|
| | | |
|---|
| | | int64_t t_load_us = 0; |
|---|
| | | int64_t t_sample_us = 0; |
|---|
| | | int64_t t_predict_us = 0; |
|---|
| | | |
|---|
| | | // determine the required inference memory per token: |
|---|
| | | size_t mem_per_token = 0; |
|---|
| | | |
|---|
| | | int n_past = 0; |
|---|
| | | |
|---|
| | | gpt_vocab vocab; |
|---|
| | | dollyv2_model model; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!dollyv2_model_load(params.model, model, vocab)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | test_gpt_tokenizer(vocab, params.token_test); |
|---|
| | | } |
|---|
| | | |
|---|
| | | #if defined(DOLLY_INTERACTIVE_PORT) |
|---|
| | | int sockfd = -1; |
|---|
| | | if (params.interactive_port != -1) { |
|---|
| | | sockfd = setup_port(params.interactive_port); |
|---|
| | | if (sockfd == -1) { |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | fprintf(stdout, "Model is ready on port %i\n", params.interactive_port); |
|---|
| | | fflush(stdout); |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | if (params.interactive || params.interactive_port != -1) { |
|---|
| | | while (true) { |
|---|
| | | std::string prompt_input; |
|---|
| | | #if defined(DOLLY_INTERACTIVE_PORT) |
|---|
| | | int clientfd = -1; |
|---|
| | | if (params.interactive_port != -1) { |
|---|
| | | sockaddr_in clientaddr; |
|---|
| | | socklen_t clientaddrlen = sizeof(clientaddr); |
|---|
| | | clientfd = accept(sockfd, (struct sockaddr *)&clientaddr, &clientaddrlen); |
|---|
| | | prompt_input = read_from_port(sockfd, clientfd); |
|---|
| | | } else |
|---|
| | | #endif |
|---|
| | | { |
|---|
| | | printf("Please enter your quesiton:\n>"); |
|---|
| | | fflush(stdout); |
|---|
| | | |
|---|
| | | std::getline(std::cin, prompt_input); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (strcmp(prompt_input.c_str(), "exit") == 0) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | const std::string prompt = prompt_for_generation(prompt_input); |
|---|
| | | // call the model |
|---|
| | | const std::string response = execute_prompt(model, vocab, prompt, params, rng, t_load_us, t_sample_us, t_predict_us, mem_per_token, n_past, true); |
|---|
| | | |
|---|
| | | #if defined(DOLLY_INTERACTIVE_PORT) |
|---|
| | | if (params.interactive_port != -1) { |
|---|
| | | if (write(clientfd, response.c_str(), response.size()) < 0) { |
|---|
| | | fprintf(stderr, "%s: Failed to write answer '%s' to client\n", __func__, response.c_str()); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (close(clientfd) < 0) { |
|---|
| | | fprintf(stderr, "%s: Failed to close client socket\n", __func__); |
|---|
| | | } |
|---|
| | | } else |
|---|
| | | #endif |
|---|
| | | { |
|---|
| | | printf("%s\n\n", response.c_str()); |
|---|
| | | } |
|---|
| | | fflush(stdout); |
|---|
| | | } |
|---|
| | | } else { |
|---|
| | | if (params.prompt.empty()) { |
|---|
| | | params.prompt = gpt_random_prompt(rng); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const std::string prompt = prompt_for_generation(params.prompt); |
|---|
| | | execute_prompt(model, vocab, prompt, params, rng, t_load_us, t_sample_us, t_predict_us, mem_per_token, n_past, true); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n\n"); |
|---|
| | | printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token); |
|---|
| | | printf("%s: load time = %8.2f ms\n", __func__, t_load_us / 1000.0f); |
|---|
| | | printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us / 1000.0f); |
|---|
| | | printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us / 1000.0f, t_predict_us / 1000.0f / n_past); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us) / 1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | #if defined(DOLLY_INTERACTIVE_PORT) |
|---|
| | | if (params.interactive_port != -1 && close(sockfd) < 0) { |
|---|
| | | fprintf(stderr, "%s: Failed to close server socket\n", __func__); |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | #include <regex> |
|---|
| | | |
|---|
| | | // default hparams (dollyv2 3B) |
|---|
| | | struct dollyv2_hparams { |
|---|
| | | int32_t n_vocab = 50254; // tokenizer.vocab_size |
|---|
| | | int32_t n_ctx = 2048; // model.config.max_position_embeddings |
|---|
| | | int32_t n_embd = 2560; // model.config.hidden_size |
|---|
| | | int32_t n_head = 32; // model.config.num_attention_heads |
|---|
| | | int32_t n_layer = 32; // model.config.num_hidden_layers |
|---|
| | | int32_t n_rot = 20; // rotary_pct[25%] * (n_embd / n_head) |
|---|
| | | int32_t par_res = 1; // 1 = true, 0 = false |
|---|
| | | int32_t ftype = GGML_FTYPE_MOSTLY_F16; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // quantize a model |
|---|
| | | bool dollyv2_model_quantize(const std::string & fname_inp, const std::string & fname_out, ggml_ftype ftype) { |
|---|
| | | gpt_vocab vocab; |
|---|
| | | |
|---|
| | | printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | |
|---|
| | | auto finp = std::ifstream(fname_inp, std::ios::binary); |
|---|
| | | if (!finp) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto fout = std::ofstream(fname_out, std::ios::binary); |
|---|
| | | if (!fout) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname_out.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | finp.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | fout.write((char *) &magic, sizeof(magic)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | dollyv2_hparams hparams; |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | finp.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | finp.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | finp.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | finp.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | finp.read((char *) &hparams.n_rot, sizeof(hparams.n_rot)); |
|---|
| | | finp.read((char *) &hparams.par_res, sizeof(hparams.par_res)); |
|---|
| | | finp.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: par_res = %d\n", __func__, hparams.par_res); |
|---|
| | | printf("%s: ftype (src) = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr (src) = %d\n", __func__, qntvr_src); |
|---|
| | | printf("%s: ftype (dst) = %d\n", __func__, ftype_dst); |
|---|
| | | printf("%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION); |
|---|
| | | |
|---|
| | | fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fout.write((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fout.write((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fout.write((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fout.write((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fout.write((char *) &hparams.n_rot, sizeof(hparams.n_rot)); |
|---|
| | | fout.write((char *) &hparams.par_res, sizeof(hparams.par_res)); |
|---|
| | | fout.write((char *) &ftype_dst, sizeof(ftype_dst)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | const int32_t n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | finp.read ((char *) &len, sizeof(len)); |
|---|
| | | fout.write((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | word.resize(len); |
|---|
| | | finp.read ((char *) word.data(), len); |
|---|
| | | fout.write((char *) word.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // regexes of tensor names to be quantized |
|---|
| | | const std::vector<std::string> to_quant = { |
|---|
| | | ".*weight", |
|---|
| | | }; |
|---|
| | | |
|---|
| | | if (!ggml_common_quantize_0(finp, fout, ftype, to_quant, {})) { |
|---|
| | | fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | finp.close(); |
|---|
| | | fout.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // usage: |
|---|
| | | // ./dollyv2-quantize models/dolly-v2-3B/ggml-model.bin models/dolly-v2-3B/ggml-model-quant.bin type |
|---|
| | | // |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | if (argc != 4) { |
|---|
| | | fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n", argv[0]); |
|---|
| | | ggml_print_ftypes(stderr); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // needed to initialize f16 tables |
|---|
| | | { |
|---|
| | | struct ggml_init_params params = { 0, NULL, false }; |
|---|
| | | struct ggml_context * ctx = ggml_init(params); |
|---|
| | | ggml_free(ctx); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const std::string fname_inp = argv[1]; |
|---|
| | | const std::string fname_out = argv[2]; |
|---|
| | | |
|---|
| | | const ggml_ftype ftype = ggml_parse_ftype(argv[3]); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | int64_t t_quantize_us = 0; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!dollyv2_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) { |
|---|
| | | fprintf(stderr, "%s: failed to quantize model from '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_quantize_us = ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n"); |
|---|
| | | printf("%s: quantize time = %8.2f ms\n", __func__, t_quantize_us/1000.0f); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | # |
|---|
| | | # gpt-2 |
|---|
| | | |
|---|
| | | set(TEST_TARGET gpt-2-ctx) |
|---|
| | | add_executable(${TEST_TARGET} main-ctx.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| | | |
|---|
| | | set(TEST_TARGET gpt-2-alloc) |
|---|
| | | add_executable(${TEST_TARGET} main-alloc.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| | | |
|---|
| | | set(TEST_TARGET gpt-2-backend) |
|---|
| | | add_executable(${TEST_TARGET} main-backend.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| | | |
|---|
| | | set(TEST_TARGET gpt-2-backend2) |
|---|
| | | add_executable(${TEST_TARGET} main.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| | | |
|---|
| | | # |
|---|
| | | # gpt-2-quantize |
|---|
| | | |
|---|
| | | set(TEST_TARGET gpt-2-quantize) |
|---|
| | | add_executable(${TEST_TARGET} quantize.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| | | |
|---|
| | | # |
|---|
| | | # gpt-2-batched |
|---|
| | | |
|---|
| | | set(TEST_TARGET gpt-2-batched) |
|---|
| | | add_executable(${TEST_TARGET} main-batched.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| | | |
|---|
| | | |
|---|
| | | # |
|---|
| | | # For GPU offloading |
|---|
| | | |
|---|
| | | if (GGML_CUBLAS) |
|---|
| | | add_compile_definitions(GGML_USE_CUBLAS) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | if (GGML_CLBLAST) |
|---|
| | | add_compile_definitions(GGML_USE_CLBLAST) |
|---|
| | | endif() |
|---|
| | | |
|---|
| | | if (GGML_METAL) |
|---|
| | | add_compile_definitions(GGML_USE_METAL) |
|---|
| | | endif() |
|---|
| New file |
| | |
|---|
| | | # gpt-2 |
|---|
| | | |
|---|
| | | This is a C++ example running GPT-2 inference using the [ggml](https://github.com/ggerganov/ggml) library. |
|---|
| | | |
|---|
| | | The program runs on the CPU - no video card is required. |
|---|
| | | |
|---|
| | | The [Cerebras-GPT](https://huggingface.co/cerebras) models are also supported. |
|---|
| | | |
|---|
| | | The example supports the following GPT-2 models: |
|---|
| | | |
|---|
| | | | Model | Description | Disk Size | |
|---|
| | | | --- | --- | --- | |
|---|
| | | | 117M | Small model | 240 MB | |
|---|
| | | | 345M | Medium model | 680 MB | |
|---|
| | | | 774M | Large model | 1.5 GB | |
|---|
| | | | 1558M | XL model | 3.0 GB | |
|---|
| | | |
|---|
| | | Sample performance on MacBook M1 Pro: |
|---|
| | | |
|---|
| | | | Model | Size | Time / Token | |
|---|
| | | | --- | --- | --- | |
|---|
| | | | GPT-2 | 117M | 5 ms | |
|---|
| | | | GPT-2 | 345M | 12 ms | |
|---|
| | | | GPT-2 | 774M | 23 ms | |
|---|
| | | | GPT-2 | 1558M | 42 ms | |
|---|
| | | |
|---|
| | | *TODO: add tables for Cerebras-GPT models* |
|---|
| | | |
|---|
| | | Sample output: |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | $ ./bin/gpt-2 -h |
|---|
| | | usage: ./bin/gpt-2 [options] |
|---|
| | | |
|---|
| | | options: |
|---|
| | | -h, --help show this help message and exit |
|---|
| | | -s SEED, --seed SEED RNG seed (default: -1) |
|---|
| | | -t N, --threads N number of threads to use during computation (default: 8) |
|---|
| | | -p PROMPT, --prompt PROMPT |
|---|
| | | prompt to start generation with (default: random) |
|---|
| | | -n N, --n_predict N number of tokens to predict (default: 200) |
|---|
| | | --top_k N top-k sampling (default: 40) |
|---|
| | | --top_p N top-p sampling (default: 0.9) |
|---|
| | | --temp N temperature (default: 1.0) |
|---|
| | | -b N, --batch_size N batch size for prompt processing (default: 8) |
|---|
| | | -m FNAME, --model FNAME |
|---|
| | | model path (default: models/gpt-2-117M/ggml-model.bin) |
|---|
| | | |
|---|
| | | $ ./bin/gpt-2 |
|---|
| | | gpt2_model_load: loading model from 'models/gpt-2-117M/ggml-model.bin' |
|---|
| | | gpt2_model_load: n_vocab = 50257 |
|---|
| | | gpt2_model_load: n_ctx = 1024 |
|---|
| | | gpt2_model_load: n_embd = 768 |
|---|
| | | gpt2_model_load: n_head = 12 |
|---|
| | | gpt2_model_load: n_layer = 12 |
|---|
| | | gpt2_model_load: f16 = 1 |
|---|
| | | gpt2_model_load: ggml ctx size = 311.12 MB |
|---|
| | | gpt2_model_load: memory size = 72.00 MB, n_mem = 12288 |
|---|
| | | gpt2_model_load: model size = 239.08 MB |
|---|
| | | main: number of tokens in prompt = 1 |
|---|
| | | |
|---|
| | | So this is going to be the end of the line for us. |
|---|
| | | |
|---|
| | | If the Dolphins continue to do their business, it's possible that the team could make a bid to bring in new defensive coordinator Scott Linehan. |
|---|
| | | |
|---|
| | | Linehan's job is a little daunting, but he's a great coach and an excellent coach. I don't believe we're going to make the playoffs. |
|---|
| | | |
|---|
| | | We're going to have to work hard to keep our heads down and get ready to go.<|endoftext|> |
|---|
| | | |
|---|
| | | main: mem per token = 2048612 bytes |
|---|
| | | main: load time = 106.32 ms |
|---|
| | | main: sample time = 7.10 ms |
|---|
| | | main: predict time = 506.40 ms / 5.06 ms per token |
|---|
| | | main: total time = 629.84 ms |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Downloading and converting the original models (GPT-2) |
|---|
| | | |
|---|
| | | You can download the original model files using the [download-model.sh](download-model.sh) Bash script. The models are |
|---|
| | | in Tensorflow format, so in order to use them with ggml, you need to convert them to appropriate format. This is done |
|---|
| | | via the [convert-ckpt-to-ggml.py](convert-ckpt-to-ggml.py) python script. |
|---|
| | | |
|---|
| | | Here is the entire process for the GPT-2 117M model (download from official site + conversion): |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | cd ggml/build |
|---|
| | | ../examples/gpt-2/download-model.sh 117M |
|---|
| | | |
|---|
| | | Downloading model 117M ... |
|---|
| | | models/gpt-2-117M/checkpoint 100%[=============================>] 77 --.-KB/s in 0s |
|---|
| | | models/gpt-2-117M/encoder.json 100%[=============================>] 1018K 1.20MB/s in 0.8s |
|---|
| | | models/gpt-2-117M/hparams.json 100%[=============================>] 90 --.-KB/s in 0s |
|---|
| | | models/gpt-2-117M/model.ckpt.data-00000-of-00001 100%[=============================>] 474.70M 1.21MB/s in 8m 39s |
|---|
| | | models/gpt-2-117M/model.ckpt.index 100%[=============================>] 5.09K --.-KB/s in 0s |
|---|
| | | models/gpt-2-117M/model.ckpt.meta 100%[=============================>] 460.11K 806KB/s in 0.6s |
|---|
| | | models/gpt-2-117M/vocab.bpe 100%[=============================>] 445.62K 799KB/s in 0.6s |
|---|
| | | Done! Model '117M' saved in 'models/gpt-2-117M/' |
|---|
| | | |
|---|
| | | Run the convert-ckpt-to-ggml.py script to convert the model to ggml format. |
|---|
| | | |
|---|
| | | python /Users/john/ggml/examples/gpt-2/convert-ckpt-to-ggml.py models/gpt-2-117M/ 1 |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | This conversion requires that you have python and Tensorflow installed on your computer. Still, if you want to avoid |
|---|
| | | this, you can download the already converted ggml models as described below. |
|---|
| | | |
|---|
| | | ## Downloading and converting the original models (Cerebras-GPT) |
|---|
| | | |
|---|
| | | Clone the respective repository from here: https://huggingface.co/cerebras |
|---|
| | | |
|---|
| | | Use the [convert-cerebras-to-ggml.py](convert-cerebras-to-ggml.py) script to convert the model to `ggml` format: |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | cd ggml/build |
|---|
| | | git clone https://huggingface.co/cerebras/Cerebras-GPT-111M models/ |
|---|
| | | python ../examples/gpt-2/convert-cerebras-to-ggml.py models/Cerebras-GPT-111M/ |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Downloading the ggml model directly (GPT-2) |
|---|
| | | |
|---|
| | | For convenience, I will be hosting the converted ggml model files in order to make it easier to run the examples. This |
|---|
| | | way, you can directly download a single binary file and start using it. No python or Tensorflow is required. |
|---|
| | | |
|---|
| | | Here is how to get the 117M ggml model: |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | cd ggml/build |
|---|
| | | ../examples/gpt-2/download-ggml-model.sh 117M |
|---|
| | | |
|---|
| | | Downloading ggml model 117M ... |
|---|
| | | models/gpt-2-117M/ggml-model.bin 100%[===============================>] 239.58M 8.52MB/s in 28s |
|---|
| | | Done! Model '117M' saved in 'models/gpt-2-117M/ggml-model.bin' |
|---|
| | | You can now use it like this: |
|---|
| | | |
|---|
| | | $ ./bin/gpt-2 -m models/gpt-2-117M/ggml-model.bin -p "This is an example" |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | At some point, I might decide to stop hosting these models. So in that case, simply revert to the manual process above. |
|---|
| | | |
|---|
| | | ## Quantizing the models |
|---|
| | | |
|---|
| | | You can also try to quantize the `ggml` models via 4-bit integer quantization. |
|---|
| | | Keep in mind that for smaller models, this will render them completely useless. |
|---|
| | | You generally want to quantize larger models. |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | # quantize GPT-2 F16 to Q4_0 (faster but less precise) |
|---|
| | | ./bin/gpt-2-quantize models/gpt-2-1558M/ggml-model-f16.bin models/gpt-2-1558M/ggml-model-q4_0.bin 2 |
|---|
| | | ./bin/gpt-2 -m models/gpt-2-1558M/ggml-model-q4_0.bin -p "This is an example" |
|---|
| | | |
|---|
| | | # quantize Cerebras F16 to Q4_1 (slower but more precise) |
|---|
| | | ./bin/gpt-2-quantize models/Cerebras-GPT-6.7B/ggml-model-f16.bin models/Cerebras-GPT-6.7B/ggml-model-q4_1.bin 3 |
|---|
| | | ./bin/gpt-2 -m models/Cerebras-GPT-6.7B/ggml-model-q4_1.bin -p "This is an example" |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Batched generation example |
|---|
| | | |
|---|
| | | You can try the batched generation from a given prompt using the gpt-2-batched binary. |
|---|
| | | |
|---|
| | | Sample output: |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | $ gpt-2-batched -np 5 -m models/gpt-2-117M/ggml-model.bin -p "Hello my name is" -n 50 |
|---|
| | | |
|---|
| | | main: seed = 1697037431 |
|---|
| | | gpt2_model_load: loading model from 'models/gpt-2-117M/ggml-model.bin' |
|---|
| | | gpt2_model_load: n_vocab = 50257 |
|---|
| | | gpt2_model_load: n_ctx = 1024 |
|---|
| | | gpt2_model_load: n_embd = 768 |
|---|
| | | gpt2_model_load: n_head = 12 |
|---|
| | | gpt2_model_load: n_layer = 12 |
|---|
| | | gpt2_model_load: ftype = 1 |
|---|
| | | gpt2_model_load: qntvr = 0 |
|---|
| | | gpt2_model_load: ggml tensor size = 320 bytes |
|---|
| | | gpt2_model_load: backend buffer size = 312.72 MB |
|---|
| | | ggml_init_cublas: found 1 CUDA devices: |
|---|
| | | Device 0: NVIDIA GeForce GTX 1660, compute capability 7.5 |
|---|
| | | gpt2_model_load: using CPU backend |
|---|
| | | gpt2_model_load: memory size = 72.00 MB, n_mem = 12288 |
|---|
| | | gpt2_model_load: model size = 239.08 MB |
|---|
| | | extract_tests_from_file : No test file found. |
|---|
| | | test_gpt_tokenizer : 0 tests failed out of 0 tests. |
|---|
| | | main: compute buffer size: 3.26 MB |
|---|
| | | |
|---|
| | | |
|---|
| | | main: generating 5 sequences ... |
|---|
| | | main: prompt: 'Hello my name is' |
|---|
| | | main: number of tokens in prompt = 4, first 8 tokens: 15496 616 1438 318 |
|---|
| | | |
|---|
| | | |
|---|
| | | sequence 0: |
|---|
| | | |
|---|
| | | Hello my name is John. You can call me any way you want, if you want, but for my very first date, I will be on the phone with you. We're both in our early 20s, but I feel like it's all |
|---|
| | | |
|---|
| | | sequence 1: |
|---|
| | | |
|---|
| | | Hello my name is Robert, and I want to say that we're proud to have your company here on the world's largest platform for sharing your stories with us. This is a huge opportunity for our community. We have hundreds of people on this team and |
|---|
| | | |
|---|
| | | sequence 2: |
|---|
| | | |
|---|
| | | Hello my name is Jack. I'm the one who created you. |
|---|
| | | |
|---|
| | | Jack is a boy with a big smile and a big heart. He is a handsome guy. He loves the outdoors and loves the people he meets. He wants to be a |
|---|
| | | |
|---|
| | | sequence 3: |
|---|
| | | |
|---|
| | | Hello my name is John. I am a Canadian citizen with a large number of family in Quebec and I am interested in studying. My aim is to take up a post in the Journal of the International Academy of Sciences of Canada which I am currently finishing. |
|---|
| | | |
|---|
| | | sequence 4: |
|---|
| | | |
|---|
| | | Hello my name is Dan. I am an entrepreneur. I am a great father. I am a great husband. I am a great husband. I am a great dad. And I am a great husband. |
|---|
| | | |
|---|
| | | I love my life. I love |
|---|
| | | |
|---|
| | | |
|---|
| | | |
|---|
| | | main: load time = 880.80 ms |
|---|
| | | main: sample time = 91.43 ms |
|---|
| | | main: predict time = 2518.29 ms |
|---|
| | | main: total time = 3544.32 ms |
|---|
| | | ``` |
|---|
| New file |
| | |
|---|
| | | # Convert Cerebras models to ggml format |
|---|
| | | # |
|---|
| | | # ref: https://www.cerebras.net/blog/cerebras-gpt-a-family-of-open-compute-efficient-large-language-models/ |
|---|
| | | # |
|---|
| | | |
|---|
| | | import sys |
|---|
| | | import struct |
|---|
| | | import json |
|---|
| | | import torch |
|---|
| | | import numpy as np |
|---|
| | | import re |
|---|
| | | |
|---|
| | | from transformers import AutoModelForCausalLM |
|---|
| | | |
|---|
| | | # ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py |
|---|
| | | def bytes_to_unicode(): |
|---|
| | | """ |
|---|
| | | Returns list of utf-8 byte and a corresponding list of unicode strings. |
|---|
| | | The reversible bpe codes work on unicode strings. |
|---|
| | | This means you need a large # of unicode characters in your vocab if you want to avoid UNKs. |
|---|
| | | When you're at something like a 10B token dataset you end up needing around 5K for decent coverage. |
|---|
| | | This is a signficant percentage of your normal, say, 32K bpe vocab. |
|---|
| | | To avoid that, we want lookup tables between utf-8 bytes and unicode strings. |
|---|
| | | And avoids mapping to whitespace/control characters the bpe code barfs on. |
|---|
| | | """ |
|---|
| | | bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1)) |
|---|
| | | cs = bs[:] |
|---|
| | | n = 0 |
|---|
| | | for b in range(2**8): |
|---|
| | | if b not in bs: |
|---|
| | | bs.append(b) |
|---|
| | | cs.append(2**8+n) |
|---|
| | | n += 1 |
|---|
| | | cs = [chr(n) for n in cs] |
|---|
| | | return dict(zip(bs, cs)) |
|---|
| | | |
|---|
| | | if len(sys.argv) < 2: |
|---|
| | | print("Usage: convert-cerebras-to-ggml.py dir-model [use-f32]\n") |
|---|
| | | sys.exit(1) |
|---|
| | | |
|---|
| | | # output in the same directory as the model |
|---|
| | | dir_model = sys.argv[1] |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model-f16.bin" |
|---|
| | | |
|---|
| | | with open(dir_model + "/vocab.json", "r", encoding="utf-8") as f: |
|---|
| | | encoder = json.load(f) |
|---|
| | | |
|---|
| | | with open(dir_model + "/config.json", "r", encoding="utf-8") as f: |
|---|
| | | hparams = json.load(f) |
|---|
| | | |
|---|
| | | # use 16-bit or 32-bit floats |
|---|
| | | use_f16 = True |
|---|
| | | if len(sys.argv) > 2: |
|---|
| | | use_f16 = False |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model-f32.bin" |
|---|
| | | |
|---|
| | | model = AutoModelForCausalLM.from_pretrained(dir_model, low_cpu_mem_usage=True) |
|---|
| | | #print (model) |
|---|
| | | |
|---|
| | | list_vars = model.state_dict() |
|---|
| | | #print (list_vars) |
|---|
| | | |
|---|
| | | print(hparams) |
|---|
| | | |
|---|
| | | fout = open(fname_out, "wb") |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex |
|---|
| | | fout.write(struct.pack("i", hparams["vocab_size"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_positions"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_embd"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_head"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_layer"])) |
|---|
| | | fout.write(struct.pack("i", use_f16)) |
|---|
| | | |
|---|
| | | byte_encoder = bytes_to_unicode() |
|---|
| | | byte_decoder = {v:k for k, v in byte_encoder.items()} |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", len(encoder))) |
|---|
| | | |
|---|
| | | for key in encoder: |
|---|
| | | text = bytearray([byte_decoder[c] for c in key]) |
|---|
| | | fout.write(struct.pack("i", len(text))) |
|---|
| | | fout.write(text) |
|---|
| | | |
|---|
| | | for name in list_vars.keys(): |
|---|
| | | data = list_vars[name].squeeze().numpy() |
|---|
| | | print("Processing variable: " + name + " with shape: ", data.shape) |
|---|
| | | |
|---|
| | | # rename headers to keep compatibility |
|---|
| | | if name == "transformer.ln_f.weight": |
|---|
| | | name = "model/ln_f/g" |
|---|
| | | elif name == "transformer.ln_f.bias": |
|---|
| | | name = "model/ln_f/b" |
|---|
| | | elif name == "transformer.wte.weight": |
|---|
| | | name = "model/wte" |
|---|
| | | elif name == "transformer.wpe.weight": |
|---|
| | | name = "model/wpe" |
|---|
| | | elif name == "lm_head.weight": |
|---|
| | | name = "model/lm_head" |
|---|
| | | elif re.match(r"transformer.h\.\d+\.ln_1\.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/ln_1/g" |
|---|
| | | elif re.match(r"transformer.h\.\d+\.ln_1\.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/ln_1/b" |
|---|
| | | elif re.match(r"transformer.h\.\d+\.attn\.c_attn\.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/attn/c_attn/w" |
|---|
| | | elif re.match(r"transformer.h\.\d+\.attn\.c_attn\.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/attn/c_attn/b" |
|---|
| | | elif re.match(r"transformer.h\.\d+\.attn\.c_proj\.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/attn/c_proj/w" |
|---|
| | | elif re.match(r"transformer.h.\d+.attn.c_proj.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/attn/c_proj/b" |
|---|
| | | elif re.match(r"transformer.h.\d+.ln_2.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/ln_2/g" |
|---|
| | | elif re.match(r"transformer.h.\d+.ln_2.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/ln_2/b" |
|---|
| | | elif re.match(r"transformer.h.\d+.mlp.c_fc.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/mlp/c_fc/w" |
|---|
| | | elif re.match(r"transformer.h.\d+.mlp.c_fc.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/mlp/c_fc/b" |
|---|
| | | elif re.match(r"transformer.h.\d+.mlp.c_proj.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/mlp/c_proj/w" |
|---|
| | | elif re.match(r"transformer.h.\d+.mlp.c_proj.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/mlp/c_proj/b" |
|---|
| | | else: |
|---|
| | | print("Unrecognized variable name. %s", name) |
|---|
| | | |
|---|
| | | # we don't need these |
|---|
| | | if name.endswith("attn.masked_bias") or name.endswith(".attn.bias"): |
|---|
| | | print(" Skipping variable: " + name) |
|---|
| | | continue |
|---|
| | | |
|---|
| | | n_dims = len(data.shape); |
|---|
| | | |
|---|
| | | # ftype == 0 -> float32, ftype == 1 -> float16 |
|---|
| | | ftype = 0; |
|---|
| | | if use_f16: |
|---|
| | | if (name == "model/wte" or name == "model/lm_head" or name[-2:] == "/g" or name[-2:] == "/w") and n_dims == 2: |
|---|
| | | print(" Converting to float16") |
|---|
| | | data = data.astype(np.float16) |
|---|
| | | ftype = 1 |
|---|
| | | else: |
|---|
| | | print(" Converting to float32") |
|---|
| | | data = data.astype(np.float32) |
|---|
| | | ftype = 0 |
|---|
| | | |
|---|
| | | # for efficiency - transpose the projection matrices |
|---|
| | | # "model/h.*/attn/c_attn/w" |
|---|
| | | # "model/h.*/attn/c_proj/w" |
|---|
| | | # "model/h.*/mlp/c_fc/w" |
|---|
| | | # "model/h.*/mlp/c_proj/w" |
|---|
| | | if name[-14:] == "/attn/c_attn/w" or \ |
|---|
| | | name[-14:] == "/attn/c_proj/w" or \ |
|---|
| | | name[-11:] == "/mlp/c_fc/w" or \ |
|---|
| | | name[-13:] == "/mlp/c_proj/w": |
|---|
| | | print(" Transposing") |
|---|
| | | data = data.transpose() |
|---|
| | | |
|---|
| | | # header |
|---|
| | | str = name.encode('utf-8') |
|---|
| | | fout.write(struct.pack("iii", n_dims, len(str), ftype)) |
|---|
| | | for i in range(n_dims): |
|---|
| | | fout.write(struct.pack("i", data.shape[n_dims - 1 - i])) |
|---|
| | | fout.write(str); |
|---|
| | | |
|---|
| | | # data |
|---|
| | | data.tofile(fout) |
|---|
| | | |
|---|
| | | fout.close() |
|---|
| | | |
|---|
| | | print("Done. Output file: " + fname_out) |
|---|
| | | print("") |
|---|
| New file |
| | |
|---|
| | | # Convert a model checkpoint to a ggml compatible file |
|---|
| | | # |
|---|
| | | # Load the model using TensorFlow. |
|---|
| | | # Iterate over all variables and write them to a binary file. |
|---|
| | | # |
|---|
| | | # For each variable, write the following: |
|---|
| | | # - Number of dimensions (int) |
|---|
| | | # - Name length (int) |
|---|
| | | # - Dimensions (int[n_dims]) |
|---|
| | | # - Name (char[name_length]) |
|---|
| | | # - Data (float[n_dims]) |
|---|
| | | # |
|---|
| | | # By default, the bigger matrices are converted to 16-bit floats. |
|---|
| | | # This can be disabled by adding the "use-f32" CLI argument. |
|---|
| | | # |
|---|
| | | # At the start of the ggml file we write the model parameters |
|---|
| | | # and vocabulary. |
|---|
| | | # |
|---|
| | | |
|---|
| | | import sys |
|---|
| | | import json |
|---|
| | | import struct |
|---|
| | | import numpy as np |
|---|
| | | import tensorflow as tf |
|---|
| | | |
|---|
| | | # ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py |
|---|
| | | def bytes_to_unicode(): |
|---|
| | | """ |
|---|
| | | Returns list of utf-8 byte and a corresponding list of unicode strings. |
|---|
| | | The reversible bpe codes work on unicode strings. |
|---|
| | | This means you need a large # of unicode characters in your vocab if you want to avoid UNKs. |
|---|
| | | When you're at something like a 10B token dataset you end up needing around 5K for decent coverage. |
|---|
| | | This is a signficant percentage of your normal, say, 32K bpe vocab. |
|---|
| | | To avoid that, we want lookup tables between utf-8 bytes and unicode strings. |
|---|
| | | And avoids mapping to whitespace/control characters the bpe code barfs on. |
|---|
| | | """ |
|---|
| | | bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1)) |
|---|
| | | cs = bs[:] |
|---|
| | | n = 0 |
|---|
| | | for b in range(2**8): |
|---|
| | | if b not in bs: |
|---|
| | | bs.append(b) |
|---|
| | | cs.append(2**8+n) |
|---|
| | | n += 1 |
|---|
| | | cs = [chr(n) for n in cs] |
|---|
| | | return dict(zip(bs, cs)) |
|---|
| | | |
|---|
| | | # helper method to convert a numpy array to different float types |
|---|
| | | def convert_to_ftype(data, ftype): |
|---|
| | | # fp16 |
|---|
| | | if ftype == 1: |
|---|
| | | return data.astype(np.float16) |
|---|
| | | |
|---|
| | | assert False, "Invalid ftype: " + str(ftype) |
|---|
| | | |
|---|
| | | if len(sys.argv) < 3: |
|---|
| | | print("Usage: convert-ckpt-to-ggml.py dir-model ftype\n") |
|---|
| | | print(" ftype == 0 -> float32") |
|---|
| | | print(" ftype == 1 -> float16") |
|---|
| | | sys.exit(1) |
|---|
| | | |
|---|
| | | # output in the same directory as the model |
|---|
| | | dir_model = sys.argv[1] |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model.bin" |
|---|
| | | |
|---|
| | | with open(dir_model + "/encoder.json", "r", encoding="utf-8") as f: |
|---|
| | | encoder = json.load(f) |
|---|
| | | |
|---|
| | | with open(dir_model + "/hparams.json", "r", encoding="utf-8") as f: |
|---|
| | | hparams = json.load(f) |
|---|
| | | |
|---|
| | | # possible data types |
|---|
| | | # ftype == 0 -> float32 |
|---|
| | | # ftype == 1 -> float16 |
|---|
| | | # |
|---|
| | | # map from ftype to string |
|---|
| | | ftype_str = ["f32", "f16"] |
|---|
| | | |
|---|
| | | ftype = 1 |
|---|
| | | if len(sys.argv) > 2: |
|---|
| | | ftype = int(sys.argv[2]) |
|---|
| | | if ftype < 0 or ftype > 1: |
|---|
| | | print("Invalid ftype: " + str(ftype)) |
|---|
| | | sys.exit(1) |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model-" + ftype_str[ftype] + ".bin" |
|---|
| | | |
|---|
| | | list_vars = tf.train.list_variables(dir_model) |
|---|
| | | |
|---|
| | | fout = open(fname_out, "wb") |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex |
|---|
| | | fout.write(struct.pack("i", hparams["n_vocab"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_ctx"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_embd"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_head"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_layer"])) |
|---|
| | | fout.write(struct.pack("i", ftype)) |
|---|
| | | |
|---|
| | | byte_encoder = bytes_to_unicode() |
|---|
| | | byte_decoder = {v:k for k, v in byte_encoder.items()} |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", len(encoder))) |
|---|
| | | |
|---|
| | | for key in encoder: |
|---|
| | | text = bytearray([byte_decoder[c] for c in key]) |
|---|
| | | fout.write(struct.pack("i", len(text))) |
|---|
| | | fout.write(text) |
|---|
| | | |
|---|
| | | for name, shape in list_vars: |
|---|
| | | print("Processing variable: " + name + " with shape: ", shape) |
|---|
| | | |
|---|
| | | data = tf.train.load_variable(dir_model, name).squeeze() |
|---|
| | | n_dims = len(data.shape); |
|---|
| | | |
|---|
| | | # for efficiency - transpose the projection matrices |
|---|
| | | # "model/h.*/attn/c_attn/w" |
|---|
| | | # "model/h.*/attn/c_proj/w" |
|---|
| | | # "model/h.*/mlp/c_fc/w" |
|---|
| | | # "model/h.*/mlp/c_proj/w" |
|---|
| | | if name[-14:] == "/attn/c_attn/w" or \ |
|---|
| | | name[-14:] == "/attn/c_proj/w" or \ |
|---|
| | | name[-11:] == "/mlp/c_fc/w" or \ |
|---|
| | | name[-13:] == "/mlp/c_proj/w": |
|---|
| | | print(" Transposing") |
|---|
| | | data = data.transpose() |
|---|
| | | |
|---|
| | | dshape = data.shape |
|---|
| | | |
|---|
| | | ftype_cur = 0 |
|---|
| | | if ftype != 0: |
|---|
| | | # match name: |
|---|
| | | # "model/wte" |
|---|
| | | # "model/h.*/attn/c_attn/w" |
|---|
| | | # "model/h.*/attn/c_proj/w" |
|---|
| | | # "model/h.*/mlp/c_fc/w" |
|---|
| | | # "model/h.*/mlp/c_proj/w" |
|---|
| | | if name == "model/wte" or name[-2:] == "/w": |
|---|
| | | print(" Converting to " + ftype_str[ftype]) |
|---|
| | | data = convert_to_ftype(data, ftype) |
|---|
| | | ftype_cur = ftype |
|---|
| | | else: |
|---|
| | | print(" Converting to float32") |
|---|
| | | data = data.astype(np.float32) |
|---|
| | | ftype_cur = 0 |
|---|
| | | |
|---|
| | | # header |
|---|
| | | str = name.encode('utf-8') |
|---|
| | | fout.write(struct.pack("iii", n_dims, len(str), ftype_cur)) |
|---|
| | | for i in range(n_dims): |
|---|
| | | fout.write(struct.pack("i", dshape[n_dims - 1 - i])) |
|---|
| | | fout.write(str); |
|---|
| | | |
|---|
| | | # data |
|---|
| | | data.tofile(fout) |
|---|
| | | |
|---|
| | | fout.close() |
|---|
| | | |
|---|
| | | print("Done. Output file: " + fname_out) |
|---|
| | | print("") |
|---|
| New file |
| | |
|---|
| | | # Convert GPT-2 h5 transformer model to ggml format |
|---|
| | | # |
|---|
| | | # Load the model using GPT2Model. |
|---|
| | | # Iterate over all variables and write them to a binary file. |
|---|
| | | # |
|---|
| | | # For each variable, write the following: |
|---|
| | | # - Number of dimensions (int) |
|---|
| | | # - Name length (int) |
|---|
| | | # - Dimensions (int[n_dims]) |
|---|
| | | # - Name (char[name_length]) |
|---|
| | | # - Data (float[n_dims]) |
|---|
| | | # |
|---|
| | | # By default, the bigger matrices are converted to 16-bit floats. |
|---|
| | | # This can be disabled by adding the "use-f32" CLI argument. |
|---|
| | | # |
|---|
| | | # At the start of the ggml file we write the model parameters |
|---|
| | | # and vocabulary. |
|---|
| | | # |
|---|
| | | |
|---|
| | | import sys |
|---|
| | | import struct |
|---|
| | | import json |
|---|
| | | import numpy as np |
|---|
| | | import re |
|---|
| | | |
|---|
| | | from transformers import GPT2Model |
|---|
| | | |
|---|
| | | # ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py |
|---|
| | | def bytes_to_unicode(): |
|---|
| | | """ |
|---|
| | | Returns list of utf-8 byte and a corresponding list of unicode strings. |
|---|
| | | The reversible bpe codes work on unicode strings. |
|---|
| | | This means you need a large # of unicode characters in your vocab if you want to avoid UNKs. |
|---|
| | | When you're at something like a 10B token dataset you end up needing around 5K for decent coverage. |
|---|
| | | This is a signficant percentage of your normal, say, 32K bpe vocab. |
|---|
| | | To avoid that, we want lookup tables between utf-8 bytes and unicode strings. |
|---|
| | | And avoids mapping to whitespace/control characters the bpe code barfs on. |
|---|
| | | """ |
|---|
| | | bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1)) |
|---|
| | | cs = bs[:] |
|---|
| | | n = 0 |
|---|
| | | for b in range(2**8): |
|---|
| | | if b not in bs: |
|---|
| | | bs.append(b) |
|---|
| | | cs.append(2**8+n) |
|---|
| | | n += 1 |
|---|
| | | cs = [chr(n) for n in cs] |
|---|
| | | return dict(zip(bs, cs)) |
|---|
| | | |
|---|
| | | if len(sys.argv) < 2: |
|---|
| | | print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n") |
|---|
| | | sys.exit(1) |
|---|
| | | |
|---|
| | | # output in the same directory as the model |
|---|
| | | dir_model = sys.argv[1] |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model.bin" |
|---|
| | | |
|---|
| | | with open(dir_model + "/vocab.json", "r", encoding="utf-8") as f: |
|---|
| | | encoder = json.load(f) |
|---|
| | | |
|---|
| | | with open(dir_model + "/added_tokens.json", "r", encoding="utf-8") as f: |
|---|
| | | encoder_added = json.load(f) |
|---|
| | | |
|---|
| | | with open(dir_model + "/config.json", "r", encoding="utf-8") as f: |
|---|
| | | hparams = json.load(f) |
|---|
| | | |
|---|
| | | # use 16-bit or 32-bit floats |
|---|
| | | use_f16 = True |
|---|
| | | if len(sys.argv) > 2: |
|---|
| | | use_f16 = False |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model-f32.bin" |
|---|
| | | |
|---|
| | | model = GPT2Model.from_pretrained(dir_model, low_cpu_mem_usage=True) |
|---|
| | | #print (model) |
|---|
| | | |
|---|
| | | list_vars = model.state_dict() |
|---|
| | | #print (list_vars) |
|---|
| | | |
|---|
| | | fout = open(fname_out, "wb") |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex |
|---|
| | | fout.write(struct.pack("i", hparams["vocab_size"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_positions"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_embd"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_head"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_layer"])) |
|---|
| | | #fout.write(struct.pack("i", hparams["rotary_dim"])) |
|---|
| | | fout.write(struct.pack("i", use_f16)) |
|---|
| | | |
|---|
| | | byte_encoder = bytes_to_unicode() |
|---|
| | | byte_decoder = {v:k for k, v in byte_encoder.items()} |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", len(encoder) + len(encoder_added))) |
|---|
| | | |
|---|
| | | for key in encoder: |
|---|
| | | text = bytearray([byte_decoder[c] for c in key]) |
|---|
| | | fout.write(struct.pack("i", len(text))) |
|---|
| | | fout.write(text) |
|---|
| | | |
|---|
| | | for key in encoder_added: |
|---|
| | | text = bytearray([byte_decoder[c] for c in key]) |
|---|
| | | fout.write(struct.pack("i", len(text))) |
|---|
| | | fout.write(text) |
|---|
| | | |
|---|
| | | for name in list_vars.keys(): |
|---|
| | | data = list_vars[name].squeeze().numpy() |
|---|
| | | print("Processing variable: " + name + " with shape: ", data.shape) |
|---|
| | | |
|---|
| | | # we don't need these |
|---|
| | | if name.endswith("attn.masked_bias") or name.endswith(".attn.bias"): |
|---|
| | | print(" Skipping variable: " + name) |
|---|
| | | continue |
|---|
| | | |
|---|
| | | n_dims = len(data.shape); |
|---|
| | | |
|---|
| | | # ftype == 0 -> float32, ftype == 1 -> float16 |
|---|
| | | ftype = 0; |
|---|
| | | if use_f16: |
|---|
| | | if name[-7:] == ".weight" and n_dims == 2: |
|---|
| | | print(" Converting to float16") |
|---|
| | | data = data.astype(np.float16) |
|---|
| | | ftype = 1 |
|---|
| | | else: |
|---|
| | | print(" Converting to float32") |
|---|
| | | data = data.astype(np.float32) |
|---|
| | | ftype = 0 |
|---|
| | | |
|---|
| | | # for efficiency - transpose these matrices: |
|---|
| | | # "transformer.h.*.mlp.c_proj.weight |
|---|
| | | if name.endswith(".mlp.c_proj.weight"): |
|---|
| | | print(" Transposing") |
|---|
| | | data = data.transpose() |
|---|
| | | |
|---|
| | | # rename headers to keep compatibility |
|---|
| | | if name == "ln_f.weight": |
|---|
| | | name = "model/ln_f/g" |
|---|
| | | elif name == "ln_f.bias": |
|---|
| | | name = "model/ln_f/b" |
|---|
| | | elif name == "wte.weight": |
|---|
| | | name = "model/wte" |
|---|
| | | elif name == "wpe.weight": |
|---|
| | | name = "model/wpe" |
|---|
| | | elif re.match(r"h\.\d+\.ln_1\.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/ln_1/g" |
|---|
| | | elif re.match(r"h\.\d+\.ln_1\.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/ln_1/b" |
|---|
| | | elif re.match(r"h\.\d+\.attn\.c_attn\.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/attn/c_attn/w" |
|---|
| | | elif re.match(r"h\.\d+\.attn\.c_attn\.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/attn/c_attn/b" |
|---|
| | | elif re.match(r"h\.\d+\.attn\.c_proj\.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/attn/c_proj/w" |
|---|
| | | elif re.match(r"h.\d+.attn.c_proj.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/attn/c_proj/b" |
|---|
| | | elif re.match(r"h.\d+.ln_2.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/ln_2/g" |
|---|
| | | elif re.match(r"h.\d+.ln_2.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/ln_2/b" |
|---|
| | | elif re.match(r"h.\d+.mlp.c_fc.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/mlp/c_fc/w" |
|---|
| | | elif re.match(r"h.\d+.mlp.c_fc.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/mlp/c_fc/b" |
|---|
| | | elif re.match(r"h.\d+.mlp.c_proj.weight", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/mlp/c_proj/w" |
|---|
| | | elif re.match(r"h.\d+.mlp.c_proj.bias", name): |
|---|
| | | i = re.findall("\d+", name)[0] |
|---|
| | | name = f"model/h{i}/mlp/c_proj/b" |
|---|
| | | else: |
|---|
| | | print("Unrecognized variable name. %s", name) |
|---|
| | | |
|---|
| | | str = name.encode('utf-8') |
|---|
| | | |
|---|
| | | fout.write(struct.pack("iii", n_dims, len(str), ftype)) |
|---|
| | | for i in range(n_dims): |
|---|
| | | fout.write(struct.pack("i", data.shape[n_dims - 1 - i])) |
|---|
| | | fout.write(str); |
|---|
| | | |
|---|
| | | # data |
|---|
| | | data.tofile(fout) |
|---|
| | | |
|---|
| | | fout.close() |
|---|
| | | |
|---|
| | | print("Done. Output file: " + fname_out) |
|---|
| | | print("") |
|---|
| New file |
| | |
|---|
| | | #!/bin/bash |
|---|
| | | |
|---|
| | | # This script downloads GPT-2 model files that have already been converted to ggml format. |
|---|
| | | # This way you don't have to convert them yourself. |
|---|
| | | # |
|---|
| | | # If you want to download the original GPT-2 model files, use the "download-model.sh" script instead. |
|---|
| | | |
|---|
| | | #src="https://ggml.ggerganov.com" |
|---|
| | | #pfx="ggml-model-gpt-2" |
|---|
| | | |
|---|
| | | src="https://huggingface.co/ggerganov/ggml" |
|---|
| | | pfx="resolve/main/ggml-model-gpt-2" |
|---|
| | | |
|---|
| | | ggml_path=$(dirname $(realpath $0)) |
|---|
| | | |
|---|
| | | # GPT-2 models |
|---|
| | | models=( "117M" "345M" "774M" "1558M" ) |
|---|
| | | |
|---|
| | | # list available models |
|---|
| | | function list_models { |
|---|
| | | printf "\n" |
|---|
| | | printf " Available models:" |
|---|
| | | for model in "${models[@]}"; do |
|---|
| | | printf " $model" |
|---|
| | | done |
|---|
| | | printf "\n\n" |
|---|
| | | } |
|---|
| | | |
|---|
| | | if [ "$#" -ne 1 ]; then |
|---|
| | | printf "Usage: $0 <model>\n" |
|---|
| | | list_models |
|---|
| | | |
|---|
| | | exit 1 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | model=$1 |
|---|
| | | |
|---|
| | | if [[ ! " ${models[@]} " =~ " ${model} " ]]; then |
|---|
| | | printf "Invalid model: $model\n" |
|---|
| | | list_models |
|---|
| | | |
|---|
| | | exit 1 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | # download ggml model |
|---|
| | | |
|---|
| | | printf "Downloading ggml model $model ...\n" |
|---|
| | | |
|---|
| | | mkdir -p models/gpt-2-$model |
|---|
| | | |
|---|
| | | if [ -x "$(command -v wget)" ]; then |
|---|
| | | wget --quiet --show-progress -O models/gpt-2-$model/ggml-model.bin $src/$pfx-$model.bin |
|---|
| | | elif [ -x "$(command -v curl)" ]; then |
|---|
| | | curl -L --output models/gpt-2-$model/ggml-model.bin $src/$pfx-$model.bin |
|---|
| | | else |
|---|
| | | printf "Either wget or curl is required to download models.\n" |
|---|
| | | exit 1 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ $? -ne 0 ]; then |
|---|
| | | printf "Failed to download ggml model $model \n" |
|---|
| | | printf "Please try again later or download the original GPT-2 model files and convert them yourself.\n" |
|---|
| | | exit 1 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | printf "Done! Model '$model' saved in 'models/gpt-2-$model/ggml-model.bin'\n" |
|---|
| | | printf "You can now use it like this:\n\n" |
|---|
| | | printf " $ ./bin/gpt-2 -m models/gpt-2-$model/ggml-model.bin -p \"This is an example\"\n" |
|---|
| | | printf "\n" |
|---|
| New file |
| | |
|---|
| | | #!/bin/bash |
|---|
| | | |
|---|
| | | ggml_path=$(dirname $(realpath $0)) |
|---|
| | | |
|---|
| | | # GPT-2 models |
|---|
| | | models=( "117M" "345M" "774M" "1558M" ) |
|---|
| | | |
|---|
| | | # list available models |
|---|
| | | function list_models { |
|---|
| | | printf "\n" |
|---|
| | | printf " Available models:" |
|---|
| | | for model in "${models[@]}"; do |
|---|
| | | printf " $model" |
|---|
| | | done |
|---|
| | | printf "\n\n" |
|---|
| | | } |
|---|
| | | |
|---|
| | | if [ "$#" -ne 1 ]; then |
|---|
| | | printf "Usage: $0 <model>\n" |
|---|
| | | list_models |
|---|
| | | |
|---|
| | | exit 1 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | model=$1 |
|---|
| | | |
|---|
| | | if [[ ! " ${models[@]} " =~ " ${model} " ]]; then |
|---|
| | | printf "Invalid model: $model\n" |
|---|
| | | list_models |
|---|
| | | |
|---|
| | | exit 1 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | # download model |
|---|
| | | |
|---|
| | | printf "Downloading model $model ...\n" |
|---|
| | | |
|---|
| | | mkdir -p models/gpt-2-$model |
|---|
| | | |
|---|
| | | for file in checkpoint encoder.json hparams.json model.ckpt.data-00000-of-00001 model.ckpt.index model.ckpt.meta vocab.bpe; do |
|---|
| | | wget --quiet --show-progress -O models/gpt-2-$model/$file https://openaipublic.blob.core.windows.net/gpt-2/models/$model/$file |
|---|
| | | done |
|---|
| | | |
|---|
| | | printf "Done! Model '$model' saved in 'models/gpt-2-$model/'\n\n" |
|---|
| | | printf "Run the convert-ckpt-to-ggml.py script to convert the model to ggml format.\n" |
|---|
| | | printf "\n" |
|---|
| | | printf " python $ggml_path/convert-ckpt-to-ggml.py models/gpt-2-$model/\n" |
|---|
| | | printf "\n" |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | #include "ggml/ggml-alloc.h" |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | // default hparams (GPT-2 117M) |
|---|
| | | struct gpt2_hparams { |
|---|
| | | int32_t n_vocab = 50257; |
|---|
| | | int32_t n_ctx = 1024; |
|---|
| | | int32_t n_embd = 768; |
|---|
| | | int32_t n_head = 12; |
|---|
| | | int32_t n_layer = 12; |
|---|
| | | int32_t ftype = 1; |
|---|
| | | float eps = 1e-5f; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_layer { |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_1_g; |
|---|
| | | struct ggml_tensor * ln_1_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * ln_2_g; |
|---|
| | | struct ggml_tensor * ln_2_b; |
|---|
| | | |
|---|
| | | // attention |
|---|
| | | struct ggml_tensor * c_attn_attn_w; |
|---|
| | | struct ggml_tensor * c_attn_attn_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_attn_proj_w; |
|---|
| | | struct ggml_tensor * c_attn_proj_b; |
|---|
| | | |
|---|
| | | // mlp |
|---|
| | | struct ggml_tensor * c_mlp_fc_w; |
|---|
| | | struct ggml_tensor * c_mlp_fc_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_mlp_proj_w; |
|---|
| | | struct ggml_tensor * c_mlp_proj_b; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_model { |
|---|
| | | gpt2_hparams hparams; |
|---|
| | | |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_f_g; |
|---|
| | | struct ggml_tensor * ln_f_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * wte; // position embedding |
|---|
| | | struct ggml_tensor * wpe; // token embedding |
|---|
| | | struct ggml_tensor * lm_head; // language model head |
|---|
| | | |
|---|
| | | std::vector<gpt2_layer> layers; |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | struct ggml_tensor * memory_k; |
|---|
| | | struct ggml_tensor * memory_v; |
|---|
| | | |
|---|
| | | // |
|---|
| | | struct ggml_context * ctx; |
|---|
| | | std::map<std::string, struct ggml_tensor *> tensors; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // load the model's weights from a file |
|---|
| | | bool gpt2_model_load(const std::string & fname, gpt2_model & model, gpt_vocab & vocab) { |
|---|
| | | printf("%s: loading model from '%s'\n", __func__, fname.c_str()); |
|---|
| | | |
|---|
| | | auto fin = std::ifstream(fname, std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | fin.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fin.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fin.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: ftype = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr = %d\n", __func__, qntvr); |
|---|
| | | |
|---|
| | | hparams.ftype %= GGML_QNT_VERSION_FACTOR; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | int32_t n_vocab = 0; |
|---|
| | | fin.read((char *) &n_vocab, sizeof(n_vocab)); |
|---|
| | | |
|---|
| | | if (n_vocab != model.hparams.n_vocab) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n", |
|---|
| | | __func__, fname.c_str(), n_vocab, model.hparams.n_vocab); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | std::vector<char> buf(128); |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | fin.read((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | buf.resize(len); |
|---|
| | | fin.read((char *) buf.data(), len); |
|---|
| | | word.assign(buf.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for the big tensors, we have the option to store the data in 16-bit floats or quantized |
|---|
| | | // in order to save memory and also to speed up the computation |
|---|
| | | ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype)); |
|---|
| | | if (wtype == GGML_TYPE_COUNT) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n", |
|---|
| | | __func__, fname.c_str(), model.hparams.ftype); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto & ctx = model.ctx; |
|---|
| | | |
|---|
| | | size_t ctx_size = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_g |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_b |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(wtype, n_vocab*n_embd); // wte |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32 , n_ctx*n_embd); // wpe |
|---|
| | | ctx_size += ggml_row_size(wtype, n_vocab*n_embd); // lm_head |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_g |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_2_g |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_2_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 3*n_embd*n_embd)); // c_attn_attn_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 3*n_embd)); // c_attn_attn_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, n_embd*n_embd)); // c_attn_proj_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // c_attn_proj_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_fc_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 4*n_embd)); // c_mlp_fc_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_proj_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 4*n_embd)); // c_mlp_proj_b |
|---|
| | | |
|---|
| | | ctx_size += n_ctx*n_layer*ggml_row_size(GGML_TYPE_F32, n_embd); // memory_k |
|---|
| | | ctx_size += n_ctx*n_layer*ggml_row_size(GGML_TYPE_F32, n_embd); // memory_v |
|---|
| | | |
|---|
| | | ctx_size += (6 + 12*n_layer)*512; // object overhead |
|---|
| | | |
|---|
| | | printf("%s: ggml tensor size = %d bytes\n", __func__, (int) sizeof(ggml_tensor)); |
|---|
| | | printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // create the ggml context |
|---|
| | | { |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ ctx_size, |
|---|
| | | /*.mem_buffer =*/ NULL, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | model.ctx = ggml_init(params); |
|---|
| | | if (!model.ctx) { |
|---|
| | | fprintf(stderr, "%s: ggml_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // prepare memory for the weights |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | model.layers.resize(n_layer); |
|---|
| | | |
|---|
| | | model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | model.wpe = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_ctx); |
|---|
| | | model.lm_head = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["model/ln_f/g"] = model.ln_f_g; |
|---|
| | | model.tensors["model/ln_f/b"] = model.ln_f_b; |
|---|
| | | |
|---|
| | | model.tensors["model/wte"] = model.wte; |
|---|
| | | model.tensors["model/wpe"] = model.wpe; |
|---|
| | | model.tensors["model/lm_head"] = model.lm_head; |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_layer; ++i) { |
|---|
| | | auto & layer = model.layers[i]; |
|---|
| | | |
|---|
| | | layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.ln_2_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_2_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_attn_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 3*n_embd); |
|---|
| | | layer.c_attn_attn_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 3*n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | layer.c_attn_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd); |
|---|
| | | layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd); |
|---|
| | | layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_1/g"] = layer.ln_1_g; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_1/b"] = layer.ln_1_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_2/g"] = layer.ln_2_g; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_2/b"] = layer.ln_2_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/w"] = layer.c_attn_attn_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/b"] = layer.c_attn_attn_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/w"] = layer.c_attn_proj_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/b"] = layer.c_attn_proj_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/w"] = layer.c_mlp_fc_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/b"] = layer.c_mlp_fc_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/w"] = layer.c_mlp_proj_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/b"] = layer.c_mlp_proj_b; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | |
|---|
| | | const int n_mem = n_layer*n_ctx; |
|---|
| | | const int n_elements = n_embd*n_mem; |
|---|
| | | |
|---|
| | | model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements); |
|---|
| | | model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements); |
|---|
| | | |
|---|
| | | const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v); |
|---|
| | | |
|---|
| | | printf("%s: memory size = %8.2f MB, n_mem = %d\n", __func__, memory_size/1024.0/1024.0, n_mem); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load weights |
|---|
| | | { |
|---|
| | | size_t total_size = 0; |
|---|
| | | |
|---|
| | | bool has_lm_head = false; |
|---|
| | | |
|---|
| | | while (true) { |
|---|
| | | int32_t n_dims; |
|---|
| | | int32_t length; |
|---|
| | | int32_t ttype; |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&length), sizeof(length)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype)); |
|---|
| | | |
|---|
| | | if (fin.eof()) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int32_t nelements = 1; |
|---|
| | | int32_t ne[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i])); |
|---|
| | | nelements *= ne[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string name(length, 0); |
|---|
| | | fin.read(&name[0], length); |
|---|
| | | |
|---|
| | | if (model.tensors.find(name) == model.tensors.end()) { |
|---|
| | | fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto tensor = model.tensors[name]; |
|---|
| | | if (ggml_nelements(tensor) != nelements) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%d, %d], expected [%d, %d]\n", |
|---|
| | | __func__, name.c_str(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for debugging |
|---|
| | | if (0) { |
|---|
| | | printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.c_str(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const size_t bpe = ggml_type_size(ggml_type(ttype)); |
|---|
| | | |
|---|
| | | if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n", |
|---|
| | | __func__, name.c_str(), ggml_nbytes(tensor), nelements*bpe); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor)); |
|---|
| | | |
|---|
| | | // GPT-2 models share the WTE tensor as the LM head |
|---|
| | | if (name == "model/wte" && has_lm_head == false) { |
|---|
| | | memcpy(model.lm_head->data, tensor->data, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (name == "model/lm_head") { |
|---|
| | | has_lm_head = true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | total_size += ggml_nbytes(tensor); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: model size = %8.2f MB\n", __func__, total_size/1024.0/1024.0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // build the computation graph |
|---|
| | | struct ggml_cgraph * gpt2_graph( |
|---|
| | | const gpt2_model & model, |
|---|
| | | struct ggml_allocr * allocr, |
|---|
| | | const int n_past, |
|---|
| | | const std::vector<gpt_vocab::id> & embd_inp) { |
|---|
| | | const int N = embd_inp.size(); |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_head = hparams.n_head; |
|---|
| | | |
|---|
| | | // since we are using ggml-alloc, this buffer only needs enough space to hold the ggml_tensor and ggml_cgraph structs, but not the tensor data |
|---|
| | | static size_t buf_size = ggml_tensor_overhead()*GGML_DEFAULT_GRAPH_SIZE + ggml_graph_overhead(); |
|---|
| | | static std::vector<uint8_t> buf(buf_size); |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf.data(), |
|---|
| | | /*.no_alloc =*/ true, // the tensors will be allocated later by ggml_allocr_alloc_graph() |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx0 = ggml_init(params); |
|---|
| | | |
|---|
| | | struct ggml_cgraph * gf = ggml_new_graph(ctx0); |
|---|
| | | |
|---|
| | | struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | ggml_allocr_alloc(allocr, embd); |
|---|
| | | |
|---|
| | | // avoid writing to tensors if we are only measuring the memory usage |
|---|
| | | if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | memcpy(embd->data, embd_inp.data(), N*ggml_element_size(embd)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * position = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | ggml_allocr_alloc(allocr, position); |
|---|
| | | if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | for (int i = 0; i < N; ++i) { |
|---|
| | | ((int32_t *) position->data)[i] = n_past + i; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // wte + wpe |
|---|
| | | struct ggml_tensor * inpL = |
|---|
| | | ggml_add(ctx0, |
|---|
| | | ggml_get_rows(ctx0, model.wte, embd), |
|---|
| | | ggml_get_rows(ctx0, model.wpe, position)); |
|---|
| | | |
|---|
| | | for (int il = 0; il < n_layer; ++il) { |
|---|
| | | struct ggml_tensor * cur; |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // cur = ln_1_g*cur + ln_1_b |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_1_g, cur), |
|---|
| | | cur), |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_1_b, cur)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // attn |
|---|
| | | // [2304, 768] - model.layers[il].c_attn_attn_w |
|---|
| | | // [2304, 1] - model.layers[il].c_attn_attn_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [2304, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = attn_w*cur + attn_b |
|---|
| | | // [2304, N] |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_attn_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_attn_attn_b, cur), |
|---|
| | | cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // self-attention |
|---|
| | | { |
|---|
| | | struct ggml_tensor * Qcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 0*sizeof(float)*n_embd); |
|---|
| | | struct ggml_tensor * Kcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 1*sizeof(float)*n_embd); |
|---|
| | | struct ggml_tensor * Vcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 2*sizeof(float)*n_embd); |
|---|
| | | |
|---|
| | | // store key and value to memory |
|---|
| | | if (N >= 1) { |
|---|
| | | struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past)); |
|---|
| | | struct ggml_tensor * v = ggml_view_1d(ctx0, model.memory_v, N*n_embd, (ggml_element_size(model.memory_v)*n_embd)*(il*n_ctx + n_past)); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3) |
|---|
| | | // [64, N, 12] |
|---|
| | | struct ggml_tensor * Q = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_cpy(ctx0, |
|---|
| | | Qcur, |
|---|
| | | ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_embd/n_head, n_head, N)), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3) |
|---|
| | | // [64, n_past + N, 12] |
|---|
| | | struct ggml_tensor * K = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_past + N), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // GG: flash attention |
|---|
| | | //struct ggml_tensor * V = |
|---|
| | | // ggml_cpy(ctx0, |
|---|
| | | // ggml_permute(ctx0, |
|---|
| | | // ggml_reshape_3d(ctx0, |
|---|
| | | // ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd), |
|---|
| | | // n_embd/n_head, n_head, n_past + N), |
|---|
| | | // 1, 2, 0, 3), |
|---|
| | | // ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_past + N, n_embd/n_head, n_head)); |
|---|
| | | |
|---|
| | | //struct ggml_tensor * KQV = ggml_flash_attn(ctx0, Q, K, V, true); |
|---|
| | | |
|---|
| | | // K * Q |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); |
|---|
| | | |
|---|
| | | // KQ_scaled = KQ / sqrt(n_embd/n_head) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_scaled = |
|---|
| | | ggml_scale(ctx0, |
|---|
| | | KQ, |
|---|
| | | 1.0f/sqrtf(float(n_embd)/n_head)); |
|---|
| | | |
|---|
| | | // KQ_masked = mask_past(KQ_scaled) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_masked = ggml_diag_mask_inf(ctx0, KQ_scaled, n_past); |
|---|
| | | |
|---|
| | | // KQ = soft_max(KQ_masked) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_soft_max = ggml_soft_max(ctx0, KQ_masked); |
|---|
| | | |
|---|
| | | // V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous() |
|---|
| | | // [n_past + N, 64, 12] |
|---|
| | | struct ggml_tensor * V_trans = |
|---|
| | | ggml_cpy(ctx0, |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_past + N), |
|---|
| | | 1, 2, 0, 3), |
|---|
| | | ggml_new_tensor_3d(ctx0, model.memory_v->type, n_past + N, n_embd/n_head, n_head)); |
|---|
| | | |
|---|
| | | // KQV = transpose(V) * KQ_soft_max |
|---|
| | | // [64, N, 12] |
|---|
| | | struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V_trans, KQ_soft_max); |
|---|
| | | |
|---|
| | | // KQV_merged = KQV.permute(0, 2, 1, 3) |
|---|
| | | // [64, 12, N] |
|---|
| | | struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // cur = KQV_merged.contiguous().view(n_embd, N) |
|---|
| | | // [768, N] |
|---|
| | | cur = ggml_cpy(ctx0, |
|---|
| | | KQV_merged, |
|---|
| | | ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // [ 768, 768] - model.layers[il].c_attn_proj_w |
|---|
| | | // [ 768, 1] - model.layers[il].c_attn_proj_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [ 768, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | // [768, N] |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_attn_proj_b, cur), |
|---|
| | | cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add the input |
|---|
| | | cur = ggml_add(ctx0, cur, inpL); |
|---|
| | | |
|---|
| | | struct ggml_tensor * inpFF = cur; |
|---|
| | | |
|---|
| | | // feed-forward network |
|---|
| | | { |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | cur = ggml_norm(ctx0, inpFF, hparams.eps); |
|---|
| | | |
|---|
| | | // cur = ln_2_g*cur + ln_2_b |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_2_g, cur), |
|---|
| | | cur), |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_2_b, cur)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // fully connected |
|---|
| | | // [3072, 768] - model.layers[il].c_mlp_fc_w |
|---|
| | | // [3072, 1] - model.layers[il].c_mlp_fc_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [3072, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = fc_w*cur + fc_b |
|---|
| | | // [3072, N] |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_fc_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_mlp_fc_b, cur), |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | // GELU activation |
|---|
| | | // [3072, N] |
|---|
| | | cur = ggml_gelu(ctx0, cur); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // [ 768, 3072] - model.layers[il].c_mlp_proj_w |
|---|
| | | // [ 768, 1] - model.layers[il].c_mlp_proj_b |
|---|
| | | // [3072, N] - cur (in) |
|---|
| | | // [ 768, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | // [768, N] |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_mlp_proj_b, cur), |
|---|
| | | cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // input for next layer |
|---|
| | | inpL = ggml_add(ctx0, cur, inpFF); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | // [ 768, N] |
|---|
| | | inpL = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // inpL = ln_f_g*inpL + ln_f_b |
|---|
| | | // [ 768, N] |
|---|
| | | inpL = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.ln_f_g, inpL), |
|---|
| | | inpL), |
|---|
| | | ggml_repeat(ctx0, model.ln_f_b, inpL)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // inpL = WTE * inpL |
|---|
| | | // [ 768, 50257] - model.lm_head |
|---|
| | | // [ 768, N] - inpL |
|---|
| | | inpL = ggml_mul_mat(ctx0, model.lm_head, inpL); |
|---|
| | | |
|---|
| | | // logits -> probs |
|---|
| | | //inpL = ggml_soft_max(ctx0, inpL); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, inpL); |
|---|
| | | |
|---|
| | | ggml_free(ctx0); |
|---|
| | | |
|---|
| | | return gf; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // evaluate the transformer |
|---|
| | | // |
|---|
| | | // - model: the model |
|---|
| | | // - allocr: ggml_allocr to use to allocate the compute buffer |
|---|
| | | // - n_threads: number of threads to use |
|---|
| | | // - n_past: the context size so far |
|---|
| | | // - embd_inp: the embeddings of the tokens in the context |
|---|
| | | // - embd_w: the predicted logits for the next token |
|---|
| | | // |
|---|
| | | bool gpt2_eval( |
|---|
| | | const gpt2_model & model, |
|---|
| | | struct ggml_allocr * allocr, |
|---|
| | | const int n_threads, |
|---|
| | | const int n_past, |
|---|
| | | const std::vector<gpt_vocab::id> & embd_inp, |
|---|
| | | std::vector<float> & embd_w) { |
|---|
| | | const int N = embd_inp.size(); |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | // reset the allocator to free all the memory allocated during the previous inference |
|---|
| | | ggml_allocr_reset(allocr); |
|---|
| | | |
|---|
| | | struct ggml_cgraph * gf = gpt2_graph(model, allocr, n_past, embd_inp); |
|---|
| | | |
|---|
| | | // allocate tensors |
|---|
| | | ggml_allocr_alloc_graph(allocr, gf); |
|---|
| | | |
|---|
| | | // run the computation |
|---|
| | | struct ggml_cplan plan = ggml_graph_plan(gf, n_threads); |
|---|
| | | static std::vector<uint8_t> work_buffer; |
|---|
| | | work_buffer.resize(plan.work_size); |
|---|
| | | plan.work_data = work_buffer.data(); |
|---|
| | | ggml_graph_compute(gf, &plan); |
|---|
| | | |
|---|
| | | //if (n_past%100 == 0) { |
|---|
| | | // ggml_graph_print (&gf); |
|---|
| | | // ggml_graph_dump_dot(&gf, NULL, "gpt-2.dot"); |
|---|
| | | //} |
|---|
| | | |
|---|
| | | // in this case, the output tensor is the last one in the graph |
|---|
| | | struct ggml_tensor * inpL = gf->nodes[gf->n_nodes - 1]; |
|---|
| | | |
|---|
| | | //embd_w.resize(n_vocab*N); |
|---|
| | | //memcpy(embd_w.data(), ggml_get_data(inpL), sizeof(float)*n_vocab*N); |
|---|
| | | |
|---|
| | | // return result just for the last token |
|---|
| | | embd_w.resize(n_vocab); |
|---|
| | | memcpy(embd_w.data(), (float *) ggml_get_data(inpL) + (n_vocab*(N-1)), sizeof(float)*n_vocab); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | gpt_params params; |
|---|
| | | params.model = "models/gpt-2-117M/ggml-model.bin"; |
|---|
| | | |
|---|
| | | if (gpt_params_parse(argc, argv, params) == false) { |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.seed < 0) { |
|---|
| | | params.seed = time(NULL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: seed = %d\n", __func__, params.seed); |
|---|
| | | |
|---|
| | | std::mt19937 rng(params.seed); |
|---|
| | | if (params.prompt.empty()) { |
|---|
| | | params.prompt = gpt_random_prompt(rng); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int64_t t_load_us = 0; |
|---|
| | | |
|---|
| | | gpt_vocab vocab; |
|---|
| | | gpt2_model model; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt2_model_load(params.model, model, vocab)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | test_gpt_tokenizer(vocab, params.token_test); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // keep this buffer alive while evaluating the model |
|---|
| | | std::vector<uint8_t> compute_buffer; |
|---|
| | | |
|---|
| | | struct ggml_allocr * allocr = NULL; |
|---|
| | | // allocate the compute buffer |
|---|
| | | { |
|---|
| | | allocr = ggml_allocr_new_measure(GGML_MEM_ALIGN); |
|---|
| | | |
|---|
| | | // create the worst case graph for memory usage estimation |
|---|
| | | int n_tokens = std::min(model.hparams.n_ctx, params.n_batch); |
|---|
| | | int n_past = model.hparams.n_ctx - n_tokens; |
|---|
| | | struct ggml_cgraph * gf = gpt2_graph(model, allocr, n_past, std::vector<gpt_vocab::id>(n_tokens, 0)); |
|---|
| | | |
|---|
| | | // compute the required memory |
|---|
| | | size_t mem_size = ggml_allocr_alloc_graph(allocr, gf) + GGML_MEM_ALIGN; |
|---|
| | | |
|---|
| | | // recreate the allocator with the required memory |
|---|
| | | ggml_allocr_free(allocr); |
|---|
| | | compute_buffer.resize(mem_size); |
|---|
| | | allocr = ggml_allocr_new(compute_buffer.data(), mem_size, GGML_MEM_ALIGN); |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s: compute buffer size: %.2f MB\n", __func__, mem_size/1024.0/1024.0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int n_past = 0; |
|---|
| | | |
|---|
| | | int64_t t_sample_us = 0; |
|---|
| | | int64_t t_predict_us = 0; |
|---|
| | | |
|---|
| | | std::vector<float> logits; |
|---|
| | | |
|---|
| | | // tokenize the prompt |
|---|
| | | std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, params.prompt); |
|---|
| | | |
|---|
| | | params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size()); |
|---|
| | | |
|---|
| | | printf("%s: prompt: '%s'\n", __func__, params.prompt.c_str()); |
|---|
| | | printf("%s: number of tokens in prompt = %zu, first 8 tokens: ", __func__, embd_inp.size()); |
|---|
| | | for (int i = 0; i < std::min(8, (int) embd_inp.size()); i++) { |
|---|
| | | printf("%d ", embd_inp[i]); |
|---|
| | | } |
|---|
| | | printf("\n\n"); |
|---|
| | | |
|---|
| | | // submit the input prompt token-by-token |
|---|
| | | // this reduces the memory usage during inference, at the cost of a bit of speed at the beginning |
|---|
| | | std::vector<gpt_vocab::id> embd; |
|---|
| | | |
|---|
| | | for (size_t i = embd.size(); i < embd_inp.size() + params.n_predict; i++) { |
|---|
| | | // predict |
|---|
| | | if (embd.size() > 0) { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt2_eval(model, allocr, params.n_threads, n_past, embd, logits)) { |
|---|
| | | printf("Failed to predict\n"); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_predict_us += ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | n_past += embd.size(); |
|---|
| | | embd.clear(); |
|---|
| | | |
|---|
| | | if (i >= embd_inp.size()) { |
|---|
| | | // sample next token |
|---|
| | | const int top_k = params.top_k; |
|---|
| | | const float top_p = params.top_p; |
|---|
| | | const float temp = params.temp; |
|---|
| | | |
|---|
| | | const int n_vocab = model.hparams.n_vocab; |
|---|
| | | |
|---|
| | | gpt_vocab::id id = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const int64_t t_start_sample_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng); |
|---|
| | | |
|---|
| | | t_sample_us += ggml_time_us() - t_start_sample_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add it to the context |
|---|
| | | embd.push_back(id); |
|---|
| | | } else { |
|---|
| | | // if here, it means we are still processing the input prompt |
|---|
| | | for (size_t k = i; k < embd_inp.size(); k++) { |
|---|
| | | embd.push_back(embd_inp[k]); |
|---|
| | | if (int32_t(embd.size()) >= params.n_batch) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | i += embd.size() - 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // display text |
|---|
| | | for (auto id : embd) { |
|---|
| | | printf("%s", vocab.id_to_token[id].c_str()); |
|---|
| | | } |
|---|
| | | fflush(stdout); |
|---|
| | | |
|---|
| | | // end of text token |
|---|
| | | if (embd.back() == 50256) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n\n"); |
|---|
| | | printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f); |
|---|
| | | printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f); |
|---|
| | | printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us/1000.0f, t_predict_us/1000.0f/n_past); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | #include "ggml/ggml-alloc.h" |
|---|
| | | #include "ggml/ggml-backend.h" |
|---|
| | | |
|---|
| | | #ifdef GGML_USE_CUBLAS |
|---|
| | | #include "ggml-cuda.h" |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #ifdef GGML_USE_METAL |
|---|
| | | #include "ggml-metal.h" |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #define GPT2_MAX_NODES 4096 |
|---|
| | | |
|---|
| | | static void ggml_log_callback_default(ggml_log_level level, const char * text, void * user_data) { |
|---|
| | | (void) level; |
|---|
| | | (void) user_data; |
|---|
| | | fputs(text, stderr); |
|---|
| | | fflush(stderr); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // default hparams (GPT-2 117M) |
|---|
| | | struct gpt2_hparams { |
|---|
| | | int32_t n_vocab = 50257; |
|---|
| | | int32_t n_ctx = 1024; |
|---|
| | | int32_t n_embd = 768; |
|---|
| | | int32_t n_head = 12; |
|---|
| | | int32_t n_layer = 12; |
|---|
| | | int32_t ftype = 1; |
|---|
| | | float eps = 1e-5f; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_layer { |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_1_g; |
|---|
| | | struct ggml_tensor * ln_1_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * ln_2_g; |
|---|
| | | struct ggml_tensor * ln_2_b; |
|---|
| | | |
|---|
| | | // attention |
|---|
| | | struct ggml_tensor * c_attn_attn_w; |
|---|
| | | struct ggml_tensor * c_attn_attn_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_attn_proj_w; |
|---|
| | | struct ggml_tensor * c_attn_proj_b; |
|---|
| | | |
|---|
| | | // mlp |
|---|
| | | struct ggml_tensor * c_mlp_fc_w; |
|---|
| | | struct ggml_tensor * c_mlp_fc_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_mlp_proj_w; |
|---|
| | | struct ggml_tensor * c_mlp_proj_b; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_model { |
|---|
| | | gpt2_hparams hparams; |
|---|
| | | |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_f_g; |
|---|
| | | struct ggml_tensor * ln_f_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * wte; // position embedding |
|---|
| | | struct ggml_tensor * wpe; // token embedding |
|---|
| | | struct ggml_tensor * lm_head; // language model head |
|---|
| | | |
|---|
| | | std::vector<gpt2_layer> layers; |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | struct ggml_tensor * memory_k; |
|---|
| | | struct ggml_tensor * memory_v; |
|---|
| | | |
|---|
| | | // |
|---|
| | | struct ggml_context * ctx; |
|---|
| | | |
|---|
| | | ggml_backend_t backend = NULL; |
|---|
| | | |
|---|
| | | ggml_backend_buffer_t buffer_w; |
|---|
| | | ggml_backend_buffer_t buffer_kv; |
|---|
| | | |
|---|
| | | std::map<std::string, struct ggml_tensor *> tensors; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // load the model's weights from a file |
|---|
| | | bool gpt2_model_load(const std::string & fname, gpt2_model & model, gpt_vocab & vocab, int n_ctx, int n_gpu_layers) { |
|---|
| | | printf("%s: loading model from '%s'\n", __func__, fname.c_str()); |
|---|
| | | |
|---|
| | | auto fin = std::ifstream(fname, std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | fin.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fin.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fin.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: ftype = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr = %d\n", __func__, qntvr); |
|---|
| | | |
|---|
| | | hparams.ftype %= GGML_QNT_VERSION_FACTOR; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | int32_t n_vocab = 0; |
|---|
| | | fin.read((char *) &n_vocab, sizeof(n_vocab)); |
|---|
| | | |
|---|
| | | if (n_vocab != model.hparams.n_vocab) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n", |
|---|
| | | __func__, fname.c_str(), n_vocab, model.hparams.n_vocab); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | std::vector<char> buf(128); |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | fin.read((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | buf.resize(len); |
|---|
| | | fin.read((char *) buf.data(), len); |
|---|
| | | word.assign(buf.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for the big tensors, we have the option to store the data in 16-bit floats or quantized |
|---|
| | | // in order to save memory and also to speed up the computation |
|---|
| | | ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype)); |
|---|
| | | if (wtype == GGML_TYPE_COUNT) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n", |
|---|
| | | __func__, fname.c_str(), model.hparams.ftype); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto & ctx = model.ctx; |
|---|
| | | |
|---|
| | | // create the ggml context |
|---|
| | | { |
|---|
| | | size_t n_tensors = 2 + 6 + 12*model.hparams.n_layer; |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ ggml_tensor_overhead() * n_tensors, |
|---|
| | | /*.mem_buffer =*/ NULL, |
|---|
| | | /*.no_alloc =*/ true, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | ctx = ggml_init(params); |
|---|
| | | if (!ctx) { |
|---|
| | | fprintf(stderr, "%s: ggml_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // initialize the backend |
|---|
| | | #ifdef GGML_USE_CUBLAS |
|---|
| | | if (n_gpu_layers > 0) { |
|---|
| | | fprintf(stderr, "%s: using CUDA backend\n", __func__); |
|---|
| | | model.backend = ggml_backend_cuda_init(0); |
|---|
| | | if (!model.backend) { |
|---|
| | | fprintf(stderr, "%s: ggml_backend_cuda_init() failed\n", __func__); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #ifdef GGML_USE_METAL |
|---|
| | | if (n_gpu_layers > 0) { |
|---|
| | | fprintf(stderr, "%s: using Metal backend\n", __func__); |
|---|
| | | ggml_backend_metal_log_set_callback(ggml_log_callback_default, nullptr); |
|---|
| | | model.backend = ggml_backend_metal_init(); |
|---|
| | | if (!model.backend) { |
|---|
| | | fprintf(stderr, "%s: ggml_backend_metal_init() failed\n", __func__); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | if (!model.backend) { |
|---|
| | | // fallback to CPU backend |
|---|
| | | fprintf(stderr, "%s: using CPU backend\n", __func__); |
|---|
| | | model.backend = ggml_backend_cpu_init(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (!model.backend) { |
|---|
| | | fprintf(stderr, "%s: ggml_backend_cpu_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // create the tensors for the model |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | model.layers.resize(n_layer); |
|---|
| | | |
|---|
| | | model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | model.wpe = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_ctx); |
|---|
| | | model.lm_head = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["model/ln_f/g"] = model.ln_f_g; |
|---|
| | | model.tensors["model/ln_f/b"] = model.ln_f_b; |
|---|
| | | |
|---|
| | | model.tensors["model/wte"] = model.wte; |
|---|
| | | model.tensors["model/wpe"] = model.wpe; |
|---|
| | | model.tensors["model/lm_head"] = model.lm_head; |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_layer; ++i) { |
|---|
| | | auto & layer = model.layers[i]; |
|---|
| | | |
|---|
| | | layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.ln_2_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_2_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_attn_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 3*n_embd); |
|---|
| | | layer.c_attn_attn_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 3*n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | layer.c_attn_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd); |
|---|
| | | layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd); |
|---|
| | | layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_1/g"] = layer.ln_1_g; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_1/b"] = layer.ln_1_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_2/g"] = layer.ln_2_g; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_2/b"] = layer.ln_2_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/w"] = layer.c_attn_attn_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/b"] = layer.c_attn_attn_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/w"] = layer.c_attn_proj_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/b"] = layer.c_attn_proj_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/w"] = layer.c_mlp_fc_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/b"] = layer.c_mlp_fc_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/w"] = layer.c_mlp_proj_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/b"] = layer.c_mlp_proj_b; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // allocate the model tensors in a backend buffer |
|---|
| | | model.buffer_w = ggml_backend_alloc_ctx_tensors(ctx, model.backend); |
|---|
| | | |
|---|
| | | printf("%s: ggml tensor size = %d bytes\n", __func__, (int) sizeof(ggml_tensor)); |
|---|
| | | printf("%s: backend buffer size = %6.2f MB\n", __func__, ggml_backend_buffer_get_size(model.buffer_w)/(1024.0*1024.0)); |
|---|
| | | |
|---|
| | | // override the default training context with the user-provided |
|---|
| | | model.hparams.n_ctx = n_ctx; |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | |
|---|
| | | const int n_mem = n_layer*n_ctx; |
|---|
| | | const int n_elements = n_embd*n_mem; |
|---|
| | | |
|---|
| | | model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements); |
|---|
| | | model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements); |
|---|
| | | |
|---|
| | | const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v); |
|---|
| | | |
|---|
| | | printf("%s: memory size = %8.2f MB, n_mem = %d\n", __func__, memory_size/1024.0/1024.0, n_mem); |
|---|
| | | |
|---|
| | | // create a backend buffer (can be in host or device memory) |
|---|
| | | model.buffer_kv = ggml_backend_alloc_buffer(model.backend, memory_size + 256); |
|---|
| | | |
|---|
| | | // allocate the tensors into the backend buffer |
|---|
| | | { |
|---|
| | | ggml_allocr * alloc = ggml_allocr_new_from_buffer(model.buffer_kv); |
|---|
| | | |
|---|
| | | // this updates the pointers in the tensors to point to the correct location in the buffer |
|---|
| | | // this is necessary since the ggml_context is .no_alloc == true |
|---|
| | | // note that the buffer can actually be a device buffer, depending on the backend |
|---|
| | | ggml_allocr_alloc(alloc, model.memory_k); |
|---|
| | | ggml_allocr_alloc(alloc, model.memory_v); |
|---|
| | | |
|---|
| | | ggml_allocr_free(alloc); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load weights |
|---|
| | | { |
|---|
| | | size_t total_size = 0; |
|---|
| | | |
|---|
| | | bool has_lm_head = false; |
|---|
| | | |
|---|
| | | std::vector<char> read_buf; |
|---|
| | | |
|---|
| | | while (true) { |
|---|
| | | int32_t n_dims; |
|---|
| | | int32_t length; |
|---|
| | | int32_t ttype; |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&length), sizeof(length)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype)); |
|---|
| | | |
|---|
| | | if (fin.eof()) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int32_t nelements = 1; |
|---|
| | | int32_t ne[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i])); |
|---|
| | | nelements *= ne[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string name(length, 0); |
|---|
| | | fin.read(&name[0], length); |
|---|
| | | |
|---|
| | | if (model.tensors.find(name) == model.tensors.end()) { |
|---|
| | | fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto tensor = model.tensors[name]; |
|---|
| | | ggml_set_name(tensor, name.c_str()); |
|---|
| | | if (ggml_nelements(tensor) != nelements) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%d, %d], expected [%d, %d]\n", |
|---|
| | | __func__, name.c_str(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for debugging |
|---|
| | | if (0) { |
|---|
| | | printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.c_str(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const size_t bpe = ggml_type_size(ggml_type(ttype)); |
|---|
| | | |
|---|
| | | if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n", |
|---|
| | | __func__, name.c_str(), ggml_nbytes(tensor), nelements*bpe); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (ggml_backend_is_cpu (model.backend) |
|---|
| | | #ifdef GGML_USE_METAL |
|---|
| | | || ggml_backend_is_metal(model.backend) |
|---|
| | | #endif |
|---|
| | | ) { |
|---|
| | | // for the CPU and Metal backend, we can read directly into the tensor |
|---|
| | | fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor)); |
|---|
| | | } else { |
|---|
| | | // read into a temporary buffer first, then copy to device memory |
|---|
| | | read_buf.resize(ggml_nbytes(tensor)); |
|---|
| | | fin.read(read_buf.data(), ggml_nbytes(tensor)); |
|---|
| | | ggml_backend_tensor_set(tensor, read_buf.data(), 0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // GPT-2 models share the WTE tensor as the LM head |
|---|
| | | if (name == "model/wte" && has_lm_head == false) { |
|---|
| | | //ggml_allocr_alloc(alloc, model.lm_head); |
|---|
| | | //ggml_backend_tensor_copy(tensor, model.lm_head); |
|---|
| | | model.lm_head = tensor; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (name == "model/lm_head") { |
|---|
| | | has_lm_head = true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | total_size += ggml_nbytes(tensor); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: model size = %8.2f MB\n", __func__, total_size/1024.0/1024.0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // build the computation graph |
|---|
| | | struct ggml_cgraph * gpt2_graph( |
|---|
| | | const gpt2_model & model, |
|---|
| | | struct ggml_allocr * allocr, |
|---|
| | | const int n_past, |
|---|
| | | const std::vector<gpt_vocab::id> & embd_inp) { |
|---|
| | | const int N = embd_inp.size(); |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_head = hparams.n_head; |
|---|
| | | |
|---|
| | | // since we are using ggml-alloc, this buffer only needs enough space to hold the ggml_tensor and ggml_cgraph structs, but not the tensor data |
|---|
| | | static size_t buf_size = ggml_tensor_overhead()*GPT2_MAX_NODES + ggml_graph_overhead_custom(GPT2_MAX_NODES, false); |
|---|
| | | static std::vector<uint8_t> buf(buf_size); |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf.data(), |
|---|
| | | /*.no_alloc =*/ true, // the tensors will be allocated later by ggml_allocr_alloc_graph() |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx0 = ggml_init(params); |
|---|
| | | |
|---|
| | | struct ggml_cgraph * gf = ggml_new_graph_custom(ctx0, GPT2_MAX_NODES, false); |
|---|
| | | |
|---|
| | | struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | ggml_allocr_alloc(allocr, embd); |
|---|
| | | |
|---|
| | | // avoid writing to tensors if we are only measuring the memory usage |
|---|
| | | if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | ggml_backend_tensor_set(embd, embd_inp.data(), 0, N*ggml_element_size(embd)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * position = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | ggml_allocr_alloc(allocr, position); |
|---|
| | | if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | for (int i = 0; i < N; ++i) { |
|---|
| | | int32_t v = n_past + i; |
|---|
| | | ggml_backend_tensor_set(position, &v, i*sizeof(int32_t), sizeof(v)); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // wte + wpe |
|---|
| | | struct ggml_tensor * inpL = |
|---|
| | | ggml_add(ctx0, |
|---|
| | | ggml_get_rows(ctx0, model.wte, embd), |
|---|
| | | ggml_get_rows(ctx0, model.wpe, position)); |
|---|
| | | |
|---|
| | | for (int il = 0; il < n_layer; ++il) { |
|---|
| | | struct ggml_tensor * cur; |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // cur = ln_1_g*cur + ln_1_b |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].ln_1_g), |
|---|
| | | model.layers[il].ln_1_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // attn |
|---|
| | | // [2304, 768] - model.layers[il].c_attn_attn_w |
|---|
| | | // [2304, 1] - model.layers[il].c_attn_attn_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [2304, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = attn_w*cur + attn_b |
|---|
| | | // [2304, N] |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_attn_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_attn_attn_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // self-attention |
|---|
| | | { |
|---|
| | | struct ggml_tensor * Qcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 0*sizeof(float)*n_embd); |
|---|
| | | struct ggml_tensor * Kcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 1*sizeof(float)*n_embd); |
|---|
| | | struct ggml_tensor * Vcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 2*sizeof(float)*n_embd); |
|---|
| | | |
|---|
| | | // store key and value to memory |
|---|
| | | if (N >= 1) { |
|---|
| | | struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past)); |
|---|
| | | struct ggml_tensor * v = ggml_view_1d(ctx0, model.memory_v, N*n_embd, (ggml_element_size(model.memory_v)*n_embd)*(il*n_ctx + n_past)); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3) |
|---|
| | | // [64, N, 12] |
|---|
| | | struct ggml_tensor * Q = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_cpy(ctx0, |
|---|
| | | Qcur, |
|---|
| | | ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_embd/n_head, n_head, N)), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3) |
|---|
| | | // [64, n_past + N, 12] |
|---|
| | | struct ggml_tensor * K = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_past + N), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // GG: flash attention |
|---|
| | | //struct ggml_tensor * V = |
|---|
| | | // ggml_cpy(ctx0, |
|---|
| | | // ggml_permute(ctx0, |
|---|
| | | // ggml_reshape_3d(ctx0, |
|---|
| | | // ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd), |
|---|
| | | // n_embd/n_head, n_head, n_past + N), |
|---|
| | | // 1, 2, 0, 3), |
|---|
| | | // ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_past + N, n_embd/n_head, n_head)); |
|---|
| | | |
|---|
| | | //struct ggml_tensor * KQV = ggml_flash_attn(ctx0, Q, K, V, true); |
|---|
| | | |
|---|
| | | // K * Q |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); |
|---|
| | | |
|---|
| | | // KQ_scaled = KQ / sqrt(n_embd/n_head) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_scaled = |
|---|
| | | ggml_scale(ctx0, |
|---|
| | | KQ, |
|---|
| | | 1.0f/sqrtf(float(n_embd)/n_head)); |
|---|
| | | |
|---|
| | | // KQ_masked = mask_past(KQ_scaled) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_masked = ggml_diag_mask_inf(ctx0, KQ_scaled, n_past); |
|---|
| | | |
|---|
| | | // KQ = soft_max(KQ_masked) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_soft_max = ggml_soft_max(ctx0, KQ_masked); |
|---|
| | | |
|---|
| | | // V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous() |
|---|
| | | // [n_past + N, 64, 12] |
|---|
| | | struct ggml_tensor * V_trans = |
|---|
| | | ggml_cpy(ctx0, |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_past + N), |
|---|
| | | 1, 2, 0, 3), |
|---|
| | | ggml_new_tensor_3d(ctx0, model.memory_v->type, n_past + N, n_embd/n_head, n_head)); |
|---|
| | | |
|---|
| | | // KQV = transpose(V) * KQ_soft_max |
|---|
| | | // [64, N, 12] |
|---|
| | | struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V_trans, KQ_soft_max); |
|---|
| | | |
|---|
| | | // KQV_merged = KQV.permute(0, 2, 1, 3) |
|---|
| | | // [64, 12, N] |
|---|
| | | struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // cur = KQV_merged.contiguous().view(n_embd, N) |
|---|
| | | // [768, N] |
|---|
| | | cur = ggml_cpy(ctx0, |
|---|
| | | KQV_merged, |
|---|
| | | ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // [ 768, 768] - model.layers[il].c_attn_proj_w |
|---|
| | | // [ 768, 1] - model.layers[il].c_attn_proj_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [ 768, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | // [768, N] |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_attn_proj_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add the input |
|---|
| | | cur = ggml_add(ctx0, cur, inpL); |
|---|
| | | |
|---|
| | | struct ggml_tensor * inpFF = cur; |
|---|
| | | |
|---|
| | | // feed-forward network |
|---|
| | | { |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | cur = ggml_norm(ctx0, inpFF, hparams.eps); |
|---|
| | | |
|---|
| | | // cur = ln_2_g*cur + ln_2_b |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].ln_2_g), |
|---|
| | | model.layers[il].ln_2_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // fully connected |
|---|
| | | // [3072, 768] - model.layers[il].c_mlp_fc_w |
|---|
| | | // [3072, 1] - model.layers[il].c_mlp_fc_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [3072, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = fc_w*cur + fc_b |
|---|
| | | // [3072, N] |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_fc_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_mlp_fc_b); |
|---|
| | | |
|---|
| | | // GELU activation |
|---|
| | | // [3072, N] |
|---|
| | | cur = ggml_gelu(ctx0, cur); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // [ 768, 3072] - model.layers[il].c_mlp_proj_w |
|---|
| | | // [ 768, 1] - model.layers[il].c_mlp_proj_b |
|---|
| | | // [3072, N] - cur (in) |
|---|
| | | // [ 768, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | // [768, N] |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_mlp_proj_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // input for next layer |
|---|
| | | inpL = ggml_add(ctx0, cur, inpFF); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | // [ 768, N] |
|---|
| | | inpL = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // inpL = ln_f_g*inpL + ln_f_b |
|---|
| | | // [ 768, N] |
|---|
| | | inpL = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | inpL, |
|---|
| | | model.ln_f_g), |
|---|
| | | model.ln_f_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // inpL = WTE * inpL |
|---|
| | | // [ 768, 50257] - model.lm_head |
|---|
| | | // [ 768, N] - inpL |
|---|
| | | inpL = ggml_mul_mat(ctx0, model.lm_head, inpL); |
|---|
| | | |
|---|
| | | // logits -> probs |
|---|
| | | //inpL = ggml_soft_max(ctx0, inpL); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, inpL); |
|---|
| | | |
|---|
| | | ggml_free(ctx0); |
|---|
| | | |
|---|
| | | return gf; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // evaluate the transformer |
|---|
| | | // |
|---|
| | | // - model: the model |
|---|
| | | // - allocr: ggml_allocr to use to allocate the compute buffer |
|---|
| | | // - n_threads: number of threads to use |
|---|
| | | // - n_past: the context size so far |
|---|
| | | // - embd_inp: the embeddings of the tokens in the context |
|---|
| | | // - embd_w: the predicted logits for the next token |
|---|
| | | // |
|---|
| | | bool gpt2_eval( |
|---|
| | | const gpt2_model & model, |
|---|
| | | struct ggml_allocr * allocr, |
|---|
| | | const int n_threads, |
|---|
| | | const int n_past, |
|---|
| | | const std::vector<gpt_vocab::id> & embd_inp, |
|---|
| | | std::vector<float> & embd_w) { |
|---|
| | | const int N = embd_inp.size(); |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | // reset the allocator to free all the memory allocated during the previous inference |
|---|
| | | ggml_allocr_reset(allocr); |
|---|
| | | |
|---|
| | | struct ggml_cgraph * gf = gpt2_graph(model, allocr, n_past, embd_inp); |
|---|
| | | |
|---|
| | | // allocate tensors |
|---|
| | | ggml_allocr_alloc_graph(allocr, gf); |
|---|
| | | |
|---|
| | | // set backend options |
|---|
| | | if (ggml_backend_is_cpu(model.backend)) { |
|---|
| | | ggml_backend_cpu_set_n_threads(model.backend, n_threads); |
|---|
| | | } |
|---|
| | | |
|---|
| | | #ifdef GGML_USE_METAL |
|---|
| | | if (ggml_backend_is_metal(model.backend)) { |
|---|
| | | ggml_backend_metal_set_n_cb(model.backend, n_threads); |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | // test |
|---|
| | | #if 0 && defined(GGML_USE_CUBLAS) |
|---|
| | | if (ggml_backend_is_cuda(model.backend)) { |
|---|
| | | auto eval_callback = [](int index, struct ggml_tensor * t1, struct ggml_tensor * t2, void * user_data) { |
|---|
| | | auto tv1 = tensor_to_float(t1); |
|---|
| | | auto tv2 = tensor_to_float(t2); |
|---|
| | | |
|---|
| | | #if 1 |
|---|
| | | float sim = cosine_similarity(tv1, tv2); |
|---|
| | | float len1 = vec_len(tv1); |
|---|
| | | float len2 = vec_len(tv2); |
|---|
| | | float lenr = len1/len2; |
|---|
| | | float lenrd = std::abs(1.0f-lenr); |
|---|
| | | |
|---|
| | | float angle = acosf(sim)*180.0f/M_PI; |
|---|
| | | |
|---|
| | | if (angle > 0.5f || lenrd > 0.05f) { |
|---|
| | | printf("%3d [%15s] %s: sim = %f, a = %f, lenrd = %f\n", index, ggml_op_desc(t1), t1->name, sim, angle, lenrd); |
|---|
| | | } |
|---|
| | | assert(sim > 0.90f); |
|---|
| | | #else |
|---|
| | | float dist = distance(tv1, tv2) / vec_len(tv1); |
|---|
| | | if (dist > 0.01f) { |
|---|
| | | printf("%3d [%15s] %s: distance = %f\n", index, ggml_op_desc(t1), t1->name, dist); |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | }; |
|---|
| | | ggml_backend_t backend_cpu = ggml_backend_cpu_init(); |
|---|
| | | ggml_backend_compare_graph_backend(model.backend, backend_cpu, gf, eval_callback, nullptr); |
|---|
| | | ggml_backend_free(backend_cpu); |
|---|
| | | //printf("done\n"); |
|---|
| | | } else |
|---|
| | | #endif |
|---|
| | | { |
|---|
| | | // run the computation |
|---|
| | | ggml_backend_graph_compute(model.backend, gf); |
|---|
| | | } |
|---|
| | | |
|---|
| | | //if (n_past%100 == 0) { |
|---|
| | | // ggml_graph_print (&gf); |
|---|
| | | // ggml_graph_dump_dot(&gf, NULL, "gpt-2.dot"); |
|---|
| | | //} |
|---|
| | | |
|---|
| | | // in this case, the output tensor is the last one in the graph |
|---|
| | | struct ggml_tensor * inpL = gf->nodes[gf->n_nodes - 1]; |
|---|
| | | |
|---|
| | | //embd_w.resize(n_vocab*N); |
|---|
| | | //ggml_backend_tensor_get(inpL, embd_w.data(), 0, sizeof(float)*n_vocab*N); |
|---|
| | | |
|---|
| | | // return result just for the last token |
|---|
| | | embd_w.resize(n_vocab); |
|---|
| | | ggml_backend_tensor_get(inpL, embd_w.data(), (n_vocab*(N-1))*sizeof(float), sizeof(float)*n_vocab); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | gpt_params params; |
|---|
| | | params.model = "models/gpt-2-117M/ggml-model.bin"; |
|---|
| | | |
|---|
| | | if (gpt_params_parse(argc, argv, params) == false) { |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.seed < 0) { |
|---|
| | | params.seed = time(NULL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: seed = %d\n", __func__, params.seed); |
|---|
| | | |
|---|
| | | std::mt19937 rng(params.seed); |
|---|
| | | if (params.prompt.empty()) { |
|---|
| | | params.prompt = gpt_random_prompt(rng); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int64_t t_load_us = 0; |
|---|
| | | |
|---|
| | | gpt_vocab vocab; |
|---|
| | | gpt2_model model; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt2_model_load(params.model, model, vocab, params.n_ctx, params.n_gpu_layers)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | test_gpt_tokenizer(vocab, params.token_test); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // keep this buffer alive while evaluating the model |
|---|
| | | ggml_backend_buffer_t buf_compute; |
|---|
| | | |
|---|
| | | struct ggml_allocr * allocr = NULL; |
|---|
| | | // allocate the compute buffer |
|---|
| | | { |
|---|
| | | // create an allocator to measure the memory usage |
|---|
| | | allocr = ggml_allocr_new_measure_from_backend(model.backend); |
|---|
| | | |
|---|
| | | // create the worst case graph for memory usage estimation |
|---|
| | | int n_tokens = std::min(model.hparams.n_ctx, params.n_batch); |
|---|
| | | int n_past = model.hparams.n_ctx - n_tokens; |
|---|
| | | struct ggml_cgraph * gf = gpt2_graph(model, allocr, n_past, std::vector<gpt_vocab::id>(n_tokens, 0)); |
|---|
| | | |
|---|
| | | // compute the required memory |
|---|
| | | size_t mem_size = ggml_allocr_alloc_graph(allocr, gf); |
|---|
| | | |
|---|
| | | // recreate the allocator with the required memory |
|---|
| | | ggml_allocr_free(allocr); |
|---|
| | | buf_compute = ggml_backend_alloc_buffer(model.backend, mem_size); |
|---|
| | | allocr = ggml_allocr_new_from_buffer(buf_compute); |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s: compute buffer size: %.2f MB\n", __func__, mem_size/1024.0/1024.0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int n_past = 0; |
|---|
| | | |
|---|
| | | int64_t t_sample_us = 0; |
|---|
| | | int64_t t_predict_us = 0; |
|---|
| | | |
|---|
| | | std::vector<float> logits; |
|---|
| | | |
|---|
| | | // tokenize the prompt |
|---|
| | | std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, params.prompt); |
|---|
| | | |
|---|
| | | params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size()); |
|---|
| | | |
|---|
| | | printf("%s: prompt: '%s'\n", __func__, params.prompt.c_str()); |
|---|
| | | printf("%s: number of tokens in prompt = %zu, first 8 tokens: ", __func__, embd_inp.size()); |
|---|
| | | for (int i = 0; i < std::min(8, (int) embd_inp.size()); i++) { |
|---|
| | | printf("%d ", embd_inp[i]); |
|---|
| | | } |
|---|
| | | printf("\n\n"); |
|---|
| | | |
|---|
| | | // submit the input prompt token-by-token |
|---|
| | | // this reduces the memory usage during inference, at the cost of a bit of speed at the beginning |
|---|
| | | std::vector<gpt_vocab::id> embd; |
|---|
| | | |
|---|
| | | for (size_t i = embd.size(); i < embd_inp.size() + params.n_predict; i++) { |
|---|
| | | // predict |
|---|
| | | if (embd.size() > 0) { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt2_eval(model, allocr, params.n_threads, n_past, embd, logits)) { |
|---|
| | | printf("Failed to predict\n"); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_predict_us += ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | n_past += embd.size(); |
|---|
| | | embd.clear(); |
|---|
| | | |
|---|
| | | if (i >= embd_inp.size()) { |
|---|
| | | // sample next token |
|---|
| | | const int top_k = params.top_k; |
|---|
| | | const float top_p = params.top_p; |
|---|
| | | const float temp = params.temp; |
|---|
| | | |
|---|
| | | const int n_vocab = model.hparams.n_vocab; |
|---|
| | | |
|---|
| | | gpt_vocab::id id = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const int64_t t_start_sample_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng); |
|---|
| | | |
|---|
| | | t_sample_us += ggml_time_us() - t_start_sample_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add it to the context |
|---|
| | | embd.push_back(id); |
|---|
| | | } else { |
|---|
| | | // if here, it means we are still processing the input prompt |
|---|
| | | for (size_t k = i; k < embd_inp.size(); k++) { |
|---|
| | | embd.push_back(embd_inp[k]); |
|---|
| | | if (int32_t(embd.size()) >= params.n_batch) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | i += embd.size() - 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // display text |
|---|
| | | for (auto id : embd) { |
|---|
| | | printf("%s", vocab.id_to_token[id].c_str()); |
|---|
| | | } |
|---|
| | | fflush(stdout); |
|---|
| | | |
|---|
| | | // end of text token |
|---|
| | | if (!params.ignore_eos && embd.back() == 50256) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n\n"); |
|---|
| | | printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f); |
|---|
| | | printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f); |
|---|
| | | printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us/1000.0f, t_predict_us/1000.0f/n_past); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | ggml_backend_buffer_free(model.buffer_w); |
|---|
| | | ggml_backend_buffer_free(model.buffer_kv); |
|---|
| | | ggml_backend_buffer_free(buf_compute); |
|---|
| | | ggml_backend_free(model.backend); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | #include "ggml/ggml-alloc.h" |
|---|
| | | #include "ggml/ggml-backend.h" |
|---|
| | | |
|---|
| | | #ifdef GGML_USE_CUBLAS |
|---|
| | | #include "ggml-cuda.h" |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #ifdef GGML_USE_METAL |
|---|
| | | #include "ggml-metal.h" |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <map> |
|---|
| | | #include <set> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #define GPT2_MAX_NODES 4096 |
|---|
| | | |
|---|
| | | static void ggml_log_callback_default(ggml_log_level level, const char * text, void * user_data) { |
|---|
| | | (void) level; |
|---|
| | | (void) user_data; |
|---|
| | | fputs(text, stderr); |
|---|
| | | fflush(stderr); |
|---|
| | | } |
|---|
| | | |
|---|
| | | typedef int32_t gpt2_pos; |
|---|
| | | typedef int32_t gpt2_seq_id; |
|---|
| | | |
|---|
| | | // default hparams (GPT-2 117M) |
|---|
| | | struct gpt2_hparams { |
|---|
| | | int32_t n_vocab = 50257; |
|---|
| | | int32_t n_ctx = 1024; |
|---|
| | | int32_t n_embd = 768; |
|---|
| | | int32_t n_head = 12; |
|---|
| | | int32_t n_layer = 12; |
|---|
| | | int32_t ftype = 1; |
|---|
| | | float eps = 1e-5f; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_layer { |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_1_g; |
|---|
| | | struct ggml_tensor * ln_1_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * ln_2_g; |
|---|
| | | struct ggml_tensor * ln_2_b; |
|---|
| | | |
|---|
| | | // attention |
|---|
| | | struct ggml_tensor * c_attn_attn_w; |
|---|
| | | struct ggml_tensor * c_attn_attn_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_attn_proj_w; |
|---|
| | | struct ggml_tensor * c_attn_proj_b; |
|---|
| | | |
|---|
| | | // mlp |
|---|
| | | struct ggml_tensor * c_mlp_fc_w; |
|---|
| | | struct ggml_tensor * c_mlp_fc_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_mlp_proj_w; |
|---|
| | | struct ggml_tensor * c_mlp_proj_b; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_kv_cell { |
|---|
| | | gpt2_pos pos = -1; |
|---|
| | | gpt2_pos delta = 0; |
|---|
| | | |
|---|
| | | std::set<gpt2_seq_id> seq_id; |
|---|
| | | |
|---|
| | | bool has_seq_id(const gpt2_seq_id & id) const { |
|---|
| | | return seq_id.find(id) != seq_id.end(); |
|---|
| | | } |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_kv_cache { |
|---|
| | | // key + value memory |
|---|
| | | struct ggml_tensor * k; |
|---|
| | | struct ggml_tensor * v; |
|---|
| | | // |
|---|
| | | |
|---|
| | | uint32_t head = 0; |
|---|
| | | uint32_t size = 0; |
|---|
| | | |
|---|
| | | // computed before each graph build |
|---|
| | | uint32_t n = 0; |
|---|
| | | |
|---|
| | | std::vector<gpt2_kv_cell> cells; |
|---|
| | | |
|---|
| | | ggml_backend_buffer_t buffer; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_model { |
|---|
| | | gpt2_hparams hparams; |
|---|
| | | |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_f_g; |
|---|
| | | struct ggml_tensor * ln_f_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * wte; // position embedding |
|---|
| | | struct ggml_tensor * wpe; // token embedding |
|---|
| | | struct ggml_tensor * lm_head; // language model head |
|---|
| | | |
|---|
| | | std::vector<gpt2_layer> layers; |
|---|
| | | |
|---|
| | | gpt2_kv_cache kv_cache; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx; |
|---|
| | | |
|---|
| | | ggml_backend_t backend = NULL; |
|---|
| | | |
|---|
| | | ggml_backend_buffer_t buffer_w; |
|---|
| | | |
|---|
| | | std::map<std::string, struct ggml_tensor *> tensors; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // Input data for gpt2_decode |
|---|
| | | // A gpt2_batch object can contain input about one or many sequences |
|---|
| | | // The provided arrays (i.e. token, embd, pos, etc.) must have size of n_tokens |
|---|
| | | // |
|---|
| | | // - token : the token ids of the input (used when embd is NULL) |
|---|
| | | // - embd : token embeddings (i.e. float vector of size n_embd) (used when token is NULL) |
|---|
| | | // - pos : the positions of the respective token in the sequence |
|---|
| | | // - seq_id : the sequence to which the respective token belongs |
|---|
| | | // - logits : if zero, the logits for the respective token will not be output |
|---|
| | | // |
|---|
| | | struct gpt2_batch { |
|---|
| | | int32_t n_tokens = -1; |
|---|
| | | |
|---|
| | | gpt_vocab::id * token = {}; |
|---|
| | | float * embd = {}; |
|---|
| | | gpt2_pos * pos = {}; |
|---|
| | | gpt2_seq_id * seq_id = {}; |
|---|
| | | int8_t * logits = {}; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // load the model's weights from a file |
|---|
| | | bool gpt2_model_load(const std::string & fname, gpt2_model & model, gpt_vocab & vocab, int n_ctx, int n_gpu_layers) { |
|---|
| | | printf("%s: loading model from '%s'\n", __func__, fname.c_str()); |
|---|
| | | |
|---|
| | | auto fin = std::ifstream(fname, std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | fin.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fin.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fin.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: ftype = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr = %d\n", __func__, qntvr); |
|---|
| | | |
|---|
| | | hparams.ftype %= GGML_QNT_VERSION_FACTOR; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | int32_t n_vocab = 0; |
|---|
| | | fin.read((char *) &n_vocab, sizeof(n_vocab)); |
|---|
| | | |
|---|
| | | if (n_vocab != model.hparams.n_vocab) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n", |
|---|
| | | __func__, fname.c_str(), n_vocab, model.hparams.n_vocab); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | std::vector<char> buf(128); |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | fin.read((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | buf.resize(len); |
|---|
| | | fin.read((char *) buf.data(), len); |
|---|
| | | word.assign(buf.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for the big tensors, we have the option to store the data in 16-bit floats or quantized |
|---|
| | | // in order to save memory and also to speed up the computation |
|---|
| | | ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype)); |
|---|
| | | if (wtype == GGML_TYPE_COUNT) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n", |
|---|
| | | __func__, fname.c_str(), model.hparams.ftype); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto & ctx = model.ctx; |
|---|
| | | |
|---|
| | | size_t buffer_size = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | buffer_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_g |
|---|
| | | buffer_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_b |
|---|
| | | |
|---|
| | | buffer_size += ggml_row_size(wtype, n_vocab*n_embd); // wte |
|---|
| | | buffer_size += ggml_row_size(GGML_TYPE_F32, n_ctx*n_embd); // wpe |
|---|
| | | buffer_size += ggml_row_size(wtype, n_vocab*n_embd); // lm_head |
|---|
| | | |
|---|
| | | buffer_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_g |
|---|
| | | buffer_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_b |
|---|
| | | |
|---|
| | | buffer_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_2_g |
|---|
| | | buffer_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_2_b |
|---|
| | | |
|---|
| | | buffer_size += n_layer*(ggml_row_size(wtype, 3*n_embd*n_embd)); // c_attn_attn_w |
|---|
| | | buffer_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 3*n_embd)); // c_attn_attn_b |
|---|
| | | |
|---|
| | | buffer_size += n_layer*(ggml_row_size(wtype, n_embd*n_embd)); // c_attn_proj_w |
|---|
| | | buffer_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // c_attn_proj_b |
|---|
| | | |
|---|
| | | buffer_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_fc_w |
|---|
| | | buffer_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 4*n_embd)); // c_mlp_fc_b |
|---|
| | | |
|---|
| | | buffer_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_proj_w |
|---|
| | | buffer_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 4*n_embd)); // c_mlp_proj_b |
|---|
| | | |
|---|
| | | buffer_size += (6 + 12*n_layer)*128; // alignment overhead |
|---|
| | | |
|---|
| | | printf("%s: ggml tensor size = %d bytes\n", __func__, (int) sizeof(ggml_tensor)); |
|---|
| | | printf("%s: backend buffer size = %6.2f MB\n", __func__, buffer_size/(1024.0*1024.0)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // create the ggml context |
|---|
| | | { |
|---|
| | | size_t n_tensors = 2 + 6 + 12*model.hparams.n_layer; |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ ggml_tensor_overhead() * n_tensors, |
|---|
| | | /*.mem_buffer =*/ NULL, |
|---|
| | | /*.no_alloc =*/ true, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | model.ctx = ggml_init(params); |
|---|
| | | if (!model.ctx) { |
|---|
| | | fprintf(stderr, "%s: ggml_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // initialize the backend |
|---|
| | | #ifdef GGML_USE_CUBLAS |
|---|
| | | if (n_gpu_layers > 0) { |
|---|
| | | fprintf(stderr, "%s: using CUDA backend\n", __func__); |
|---|
| | | model.backend = ggml_backend_cuda_init(0); |
|---|
| | | if (!model.backend) { |
|---|
| | | fprintf(stderr, "%s: ggml_backend_cuda_init() failed\n", __func__); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #ifdef GGML_USE_METAL |
|---|
| | | if (n_gpu_layers > 0) { |
|---|
| | | fprintf(stderr, "%s: using Metal backend\n", __func__); |
|---|
| | | ggml_backend_metal_log_set_callback(ggml_log_callback_default, nullptr); |
|---|
| | | model.backend = ggml_backend_metal_init(); |
|---|
| | | if (!model.backend) { |
|---|
| | | fprintf(stderr, "%s: ggml_backend_metal_init() failed\n", __func__); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | if (!model.backend) { |
|---|
| | | // fallback to CPU backend |
|---|
| | | fprintf(stderr, "%s: using CPU backend\n", __func__); |
|---|
| | | model.backend = ggml_backend_cpu_init(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (!model.backend) { |
|---|
| | | fprintf(stderr, "%s: ggml_backend_cpu_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // allocate weights buffer |
|---|
| | | model.buffer_w = ggml_backend_alloc_buffer(model.backend, buffer_size); |
|---|
| | | |
|---|
| | | // prepare memory for the weights |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | model.layers.resize(n_layer); |
|---|
| | | |
|---|
| | | model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | model.wpe = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_ctx); |
|---|
| | | model.lm_head = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["model/ln_f/g"] = model.ln_f_g; |
|---|
| | | model.tensors["model/ln_f/b"] = model.ln_f_b; |
|---|
| | | |
|---|
| | | model.tensors["model/wte"] = model.wte; |
|---|
| | | model.tensors["model/wpe"] = model.wpe; |
|---|
| | | model.tensors["model/lm_head"] = model.lm_head; |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_layer; ++i) { |
|---|
| | | auto & layer = model.layers[i]; |
|---|
| | | |
|---|
| | | layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.ln_2_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_2_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_attn_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 3*n_embd); |
|---|
| | | layer.c_attn_attn_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 3*n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | layer.c_attn_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd); |
|---|
| | | layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd); |
|---|
| | | layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_1/g"] = layer.ln_1_g; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_1/b"] = layer.ln_1_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_2/g"] = layer.ln_2_g; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_2/b"] = layer.ln_2_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/w"] = layer.c_attn_attn_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/b"] = layer.c_attn_attn_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/w"] = layer.c_attn_proj_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/b"] = layer.c_attn_proj_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/w"] = layer.c_mlp_fc_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/b"] = layer.c_mlp_fc_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/w"] = layer.c_mlp_proj_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/b"] = layer.c_mlp_proj_b; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // override the default training context with the user-provided |
|---|
| | | model.hparams.n_ctx = n_ctx; |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | |
|---|
| | | const int n_mem = n_layer*n_ctx; |
|---|
| | | const int n_elements = n_embd*n_mem; |
|---|
| | | |
|---|
| | | model.kv_cache.k = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements); |
|---|
| | | model.kv_cache.v = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements); |
|---|
| | | |
|---|
| | | model.kv_cache.head = 0; |
|---|
| | | model.kv_cache.size = n_ctx; |
|---|
| | | |
|---|
| | | model.kv_cache.cells.resize(n_ctx); |
|---|
| | | |
|---|
| | | const size_t memory_size = ggml_nbytes(model.kv_cache.k) + ggml_nbytes(model.kv_cache.v); |
|---|
| | | |
|---|
| | | printf("%s: memory size = %8.2f MB, n_mem = %d\n", __func__, memory_size/1024.0/1024.0, n_mem); |
|---|
| | | |
|---|
| | | // create a backend buffer (can be in host or device memory) |
|---|
| | | model.kv_cache.buffer = ggml_backend_alloc_buffer(model.backend, memory_size + 256); |
|---|
| | | |
|---|
| | | // allocate the tensors into the backend buffer |
|---|
| | | { |
|---|
| | | ggml_allocr * alloc = ggml_allocr_new_from_buffer(model.kv_cache.buffer); |
|---|
| | | |
|---|
| | | // this updates the pointers in the tensors to point to the correct location in the buffer |
|---|
| | | // this is necessary since the ggml_context is .no_alloc == true |
|---|
| | | // note that the buffer can actually be a device buffer, depending on the backend |
|---|
| | | ggml_allocr_alloc(alloc, model.kv_cache.k); |
|---|
| | | ggml_allocr_alloc(alloc, model.kv_cache.v); |
|---|
| | | |
|---|
| | | ggml_allocr_free(alloc); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load weights |
|---|
| | | { |
|---|
| | | ggml_allocr * alloc = ggml_allocr_new_from_buffer(model.buffer_w); |
|---|
| | | |
|---|
| | | size_t total_size = 0; |
|---|
| | | |
|---|
| | | bool has_lm_head = false; |
|---|
| | | |
|---|
| | | std::vector<char> read_buf; |
|---|
| | | |
|---|
| | | while (true) { |
|---|
| | | int32_t n_dims; |
|---|
| | | int32_t length; |
|---|
| | | int32_t ttype; |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&length), sizeof(length)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype)); |
|---|
| | | |
|---|
| | | if (fin.eof()) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int32_t nelements = 1; |
|---|
| | | int32_t ne[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i])); |
|---|
| | | nelements *= ne[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string name(length, 0); |
|---|
| | | fin.read(&name[0], length); |
|---|
| | | |
|---|
| | | if (model.tensors.find(name) == model.tensors.end()) { |
|---|
| | | fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto tensor = model.tensors[name]; |
|---|
| | | ggml_set_name(tensor, name.c_str()); |
|---|
| | | if (ggml_nelements(tensor) != nelements) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%d, %d], expected [%d, %d]\n", |
|---|
| | | __func__, name.c_str(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for debugging |
|---|
| | | if (0) { |
|---|
| | | printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.c_str(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const size_t bpe = ggml_type_size(ggml_type(ttype)); |
|---|
| | | |
|---|
| | | if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n", |
|---|
| | | __func__, name.c_str(), ggml_nbytes(tensor), nelements*bpe); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_allocr_alloc(alloc, tensor); |
|---|
| | | |
|---|
| | | if (ggml_backend_is_cpu (model.backend) |
|---|
| | | #ifdef GGML_USE_METAL |
|---|
| | | || ggml_backend_is_metal(model.backend) |
|---|
| | | #endif |
|---|
| | | ) { |
|---|
| | | // for the CPU and Metal backend, we can read directly into the tensor |
|---|
| | | fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor)); |
|---|
| | | } else { |
|---|
| | | // read into a temporary buffer first, then copy to device memory |
|---|
| | | read_buf.resize(ggml_nbytes(tensor)); |
|---|
| | | fin.read(read_buf.data(), ggml_nbytes(tensor)); |
|---|
| | | ggml_backend_tensor_set(tensor, read_buf.data(), 0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // GPT-2 models share the WTE tensor as the LM head |
|---|
| | | if (name == "model/wte" && has_lm_head == false) { |
|---|
| | | //ggml_allocr_alloc(alloc, model.lm_head); |
|---|
| | | //ggml_backend_tensor_copy(tensor, model.lm_head); |
|---|
| | | model.lm_head = tensor; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (name == "model/lm_head") { |
|---|
| | | has_lm_head = true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | total_size += ggml_nbytes(tensor); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_allocr_free(alloc); |
|---|
| | | printf("%s: model size = %8.2f MB\n", __func__, total_size/1024.0/1024.0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // build the computation graph |
|---|
| | | struct ggml_cgraph * gpt2_graph( |
|---|
| | | const gpt2_model & model, |
|---|
| | | struct ggml_allocr * allocr, |
|---|
| | | const gpt2_batch & batch) { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_head = hparams.n_head; |
|---|
| | | |
|---|
| | | const auto & kv_cache = model.kv_cache; |
|---|
| | | |
|---|
| | | const int32_t n_tokens = batch.n_tokens; |
|---|
| | | const int32_t n_kv = ggml_allocr_is_measure(allocr) ? n_ctx : kv_cache.n; |
|---|
| | | const int32_t kv_head = ggml_allocr_is_measure(allocr) ? n_ctx - n_tokens : kv_cache.head; |
|---|
| | | |
|---|
| | | // since we are using ggml-alloc, this buffer only needs enough space to hold the ggml_tensor and ggml_cgraph structs, but not the tensor data |
|---|
| | | static size_t buf_size = ggml_tensor_overhead()*GPT2_MAX_NODES + ggml_graph_overhead_custom(GPT2_MAX_NODES, false); |
|---|
| | | static std::vector<uint8_t> buf(buf_size); |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf.data(), |
|---|
| | | /*.no_alloc =*/ true, // the tensors will be allocated later by ggml_allocr_alloc_graph() |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx0 = ggml_init(params); |
|---|
| | | |
|---|
| | | struct ggml_cgraph * gf = ggml_new_graph_custom(ctx0, GPT2_MAX_NODES, false); |
|---|
| | | |
|---|
| | | struct ggml_tensor * inpL; |
|---|
| | | if (batch.token) { |
|---|
| | | struct ggml_tensor * inp_tokens = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, n_tokens); |
|---|
| | | ggml_allocr_alloc(allocr, inp_tokens); |
|---|
| | | if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | ggml_backend_tensor_set(inp_tokens, batch.token, 0, n_tokens*ggml_element_size(inp_tokens)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * position = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, n_tokens); |
|---|
| | | ggml_allocr_alloc(allocr, position); |
|---|
| | | if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | for (int i = 0; i < n_tokens; ++i) { |
|---|
| | | int32_t v = batch.pos[i]; |
|---|
| | | ggml_backend_tensor_set(position, &v, i*sizeof(int32_t), sizeof(v)); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // wte + wpe |
|---|
| | | inpL = |
|---|
| | | ggml_add(ctx0, |
|---|
| | | ggml_get_rows(ctx0, model.wte, inp_tokens), |
|---|
| | | ggml_get_rows(ctx0, model.wpe, position)); |
|---|
| | | } else { |
|---|
| | | GGML_ASSERT(batch.embd); |
|---|
| | | |
|---|
| | | inpL = ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, n_tokens); |
|---|
| | | |
|---|
| | | ggml_allocr_alloc(allocr, inpL); |
|---|
| | | if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | ggml_backend_tensor_set(inpL, batch.embd, 0, n_tokens * n_embd * ggml_element_size(inpL)); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // KQ_mask (mask for 1 head, it will be broadcasted to all heads) |
|---|
| | | struct ggml_tensor * KQ_mask = ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_kv, n_tokens, 1); |
|---|
| | | ggml_set_name(KQ_mask, "KQ_mask"); |
|---|
| | | ggml_allocr_alloc(allocr, KQ_mask); |
|---|
| | | if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | std::vector<float> data_buf(n_kv*n_tokens); |
|---|
| | | const float neg_inf_v = -INFINITY; |
|---|
| | | |
|---|
| | | for (int h = 0; h < 1; ++h) { |
|---|
| | | int h_offset = h*(n_kv*n_tokens); |
|---|
| | | for (int j = 0; j < n_tokens; ++j) { |
|---|
| | | const gpt2_pos pos = batch.pos[j]; |
|---|
| | | const gpt2_seq_id seq_id = batch.seq_id[j]; |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_kv; ++i) { |
|---|
| | | if (!kv_cache.cells[i].has_seq_id(seq_id) || kv_cache.cells[i].pos > pos) { |
|---|
| | | data_buf[h_offset + j*n_kv + i] = neg_inf_v; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_backend_tensor_set(KQ_mask, data_buf.data(), 0, data_buf.size() * sizeof(float)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | for (int il = 0; il < n_layer; ++il) { |
|---|
| | | struct ggml_tensor * cur; |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // cur = ln_1_g*cur + ln_1_b |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].ln_1_g), |
|---|
| | | model.layers[il].ln_1_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // attn |
|---|
| | | // [2304, 768] - model.layers[il].c_attn_attn_w |
|---|
| | | // [2304, 1] - model.layers[il].c_attn_attn_b |
|---|
| | | // [ 768, n_tokens] - cur (in) |
|---|
| | | // [2304, n_tokens] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = attn_w*cur + attn_b |
|---|
| | | // [2304, n_tokens] |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_attn_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_attn_attn_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // self-attention |
|---|
| | | { |
|---|
| | | struct ggml_tensor * Qcur = ggml_view_2d(ctx0, cur, n_embd, n_tokens, cur->nb[1], 0*sizeof(float)*n_embd); |
|---|
| | | struct ggml_tensor * Kcur = ggml_view_2d(ctx0, cur, n_embd, n_tokens, cur->nb[1], 1*sizeof(float)*n_embd); |
|---|
| | | struct ggml_tensor * Vcur = ggml_view_2d(ctx0, cur, n_embd, n_tokens, cur->nb[1], 2*sizeof(float)*n_embd); |
|---|
| | | |
|---|
| | | // store key and value to memory |
|---|
| | | if (n_tokens >= 1) { |
|---|
| | | struct ggml_tensor * k = ggml_view_1d(ctx0, model.kv_cache.k, n_tokens*n_embd, (ggml_element_size(model.kv_cache.k)*n_embd)*(il*n_ctx + kv_head)); |
|---|
| | | struct ggml_tensor * v = ggml_view_1d(ctx0, model.kv_cache.v, n_tokens*n_embd, (ggml_element_size(model.kv_cache.v)*n_embd)*(il*n_ctx + kv_head)); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3) |
|---|
| | | // [64, N, 12] |
|---|
| | | struct ggml_tensor * Q = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_cpy(ctx0, |
|---|
| | | Qcur, |
|---|
| | | ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_embd/n_head, n_head, n_tokens)), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // K = Kmem.view(n_embd/n_head, n_head, n_kv).permute(0, 2, 1, 3) |
|---|
| | | // [64, n_kv, 12] |
|---|
| | | struct ggml_tensor * K = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.kv_cache.k, n_kv*n_embd, il*n_ctx*ggml_element_size(model.kv_cache.k)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_kv), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // GG: flash attention |
|---|
| | | //struct ggml_tensor * V = |
|---|
| | | // ggml_cpy(ctx0, |
|---|
| | | // ggml_permute(ctx0, |
|---|
| | | // ggml_reshape_3d(ctx0, |
|---|
| | | // ggml_view_1d(ctx0, model.kv_cache.v, n_kv*n_embd, il*n_ctx*ggml_element_size(model.kv_cache.v)*n_embd), |
|---|
| | | // n_embd/n_head, n_head, n_kv), |
|---|
| | | // 1, 2, 0, 3), |
|---|
| | | // ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_kv, n_embd/n_head, n_head)); |
|---|
| | | |
|---|
| | | //struct ggml_tensor * KQV = ggml_flash_attn(ctx0, Q, K, V, true); |
|---|
| | | |
|---|
| | | // K * Q |
|---|
| | | // [n_kv, n_tokens, 12] |
|---|
| | | struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); |
|---|
| | | |
|---|
| | | // KQ_scaled = KQ / sqrt(n_embd/n_head) |
|---|
| | | // [n_kv, n_tokens, 12] |
|---|
| | | struct ggml_tensor * KQ_scaled = |
|---|
| | | ggml_scale(ctx0, |
|---|
| | | KQ, |
|---|
| | | 1.0f/sqrtf(float(n_embd)/n_head)); |
|---|
| | | |
|---|
| | | // KQ_masked = mask_past(KQ_scaled) |
|---|
| | | // [n_kv, n_tokens, 12] |
|---|
| | | struct ggml_tensor * KQ_masked = ggml_add(ctx0, KQ_scaled, KQ_mask); |
|---|
| | | |
|---|
| | | // KQ = soft_max(KQ_masked) |
|---|
| | | // [n_kv, N, 12] |
|---|
| | | struct ggml_tensor * KQ_soft_max = ggml_soft_max(ctx0, KQ_masked); |
|---|
| | | |
|---|
| | | // V_trans = Vmem.view(n_embd/n_head, n_head, n_kv).permute(1, 2, 0, 3).contiguous() |
|---|
| | | // [n_kv, 64, 12] |
|---|
| | | struct ggml_tensor * V_trans = |
|---|
| | | ggml_cpy(ctx0, |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.kv_cache.v, n_kv*n_embd, il*n_ctx*ggml_element_size(model.kv_cache.v)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_kv), |
|---|
| | | 1, 2, 0, 3), |
|---|
| | | ggml_new_tensor_3d(ctx0, model.kv_cache.v->type, n_kv, n_embd/n_head, n_head)); |
|---|
| | | |
|---|
| | | // KQV = transpose(V) * KQ_soft_max |
|---|
| | | // [64, n_tokens, 12] |
|---|
| | | struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V_trans, KQ_soft_max); |
|---|
| | | |
|---|
| | | // KQV_merged = KQV.permute(0, 2, 1, 3) |
|---|
| | | // [64, 12, n_tokens] |
|---|
| | | struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // cur = KQV_merged.contiguous().view(n_embd, N) |
|---|
| | | // [768, n_tokens] |
|---|
| | | cur = ggml_cpy(ctx0, |
|---|
| | | KQV_merged, |
|---|
| | | ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, n_tokens)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // [ 768, 768] - model.layers[il].c_attn_proj_w |
|---|
| | | // [ 768, 1] - model.layers[il].c_attn_proj_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [ 768, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | // [768, N] |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_attn_proj_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add the input |
|---|
| | | cur = ggml_add(ctx0, cur, inpL); |
|---|
| | | |
|---|
| | | struct ggml_tensor * inpFF = cur; |
|---|
| | | |
|---|
| | | // feed-forward network |
|---|
| | | { |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | cur = ggml_norm(ctx0, inpFF, hparams.eps); |
|---|
| | | |
|---|
| | | // cur = ln_2_g*cur + ln_2_b |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].ln_2_g), |
|---|
| | | model.layers[il].ln_2_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // fully connected |
|---|
| | | // [3072, 768] - model.layers[il].c_mlp_fc_w |
|---|
| | | // [3072, 1] - model.layers[il].c_mlp_fc_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [3072, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = fc_w*cur + fc_b |
|---|
| | | // [3072, N] |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_fc_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_mlp_fc_b); |
|---|
| | | |
|---|
| | | // GELU activation |
|---|
| | | // [3072, N] |
|---|
| | | cur = ggml_gelu(ctx0, cur); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // [ 768, 3072] - model.layers[il].c_mlp_proj_w |
|---|
| | | // [ 768, 1] - model.layers[il].c_mlp_proj_b |
|---|
| | | // [3072, N] - cur (in) |
|---|
| | | // [ 768, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | // [768, N] |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_mlp_proj_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // input for next layer |
|---|
| | | inpL = ggml_add(ctx0, cur, inpFF); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | // [ 768, N] |
|---|
| | | inpL = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // inpL = ln_f_g*inpL + ln_f_b |
|---|
| | | // [ 768, N] |
|---|
| | | inpL = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | inpL, |
|---|
| | | model.ln_f_g), |
|---|
| | | model.ln_f_b); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // inpL = WTE * inpL |
|---|
| | | // [ 768, 50257] - model.lm_head |
|---|
| | | // [ 768, N] - inpL |
|---|
| | | inpL = ggml_mul_mat(ctx0, model.lm_head, inpL); |
|---|
| | | |
|---|
| | | // logits -> probs |
|---|
| | | //inpL = ggml_soft_max(ctx0, inpL); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, inpL); |
|---|
| | | |
|---|
| | | ggml_free(ctx0); |
|---|
| | | |
|---|
| | | return gf; |
|---|
| | | } |
|---|
| | | |
|---|
| | | static void gpt2_kv_cache_seq_cp( |
|---|
| | | struct gpt2_kv_cache & cache, |
|---|
| | | gpt2_seq_id seq_id_src, |
|---|
| | | gpt2_seq_id seq_id_dst, |
|---|
| | | gpt2_pos p0, |
|---|
| | | gpt2_pos p1) { |
|---|
| | | if (p0 < 0) p0 = 0; |
|---|
| | | if (p1 < 0) p1 = std::numeric_limits<gpt2_pos>::max(); |
|---|
| | | |
|---|
| | | for (uint32_t i = 0; i < cache.size; ++i) { |
|---|
| | | if (cache.cells[i].has_seq_id(seq_id_src) && cache.cells[i].pos >= p0 && cache.cells[i].pos < p1) { |
|---|
| | | cache.cells[i].seq_id.insert(seq_id_dst); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct gpt2_batch gpt2_batch_init(int32_t n_tokens, int32_t embd) { |
|---|
| | | gpt2_batch batch; |
|---|
| | | |
|---|
| | | if (embd) { |
|---|
| | | batch.embd = (float *) malloc(sizeof(float) * n_tokens * embd); |
|---|
| | | } else { |
|---|
| | | batch.token = (gpt_vocab::id *) malloc(sizeof(gpt_vocab::id) * n_tokens); |
|---|
| | | } |
|---|
| | | |
|---|
| | | batch.pos = (gpt2_pos *) malloc(sizeof(gpt2_pos) * n_tokens); |
|---|
| | | batch.seq_id = (gpt2_seq_id *) malloc(sizeof(gpt2_seq_id) * n_tokens); |
|---|
| | | batch.logits = (int8_t *) malloc(sizeof(int8_t) * n_tokens); |
|---|
| | | |
|---|
| | | return batch; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void gpt2_batch_free(struct gpt2_batch batch) { |
|---|
| | | if (batch.token) free(batch.token); |
|---|
| | | if (batch.embd) free(batch.embd); |
|---|
| | | if (batch.pos) free(batch.pos); |
|---|
| | | if (batch.seq_id) free(batch.seq_id); |
|---|
| | | if (batch.logits) free(batch.logits); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Positive return values does not mean a fatal error, but rather a warning. |
|---|
| | | // 0 - success |
|---|
| | | // < 0 - error |
|---|
| | | int gpt2_decode( |
|---|
| | | struct gpt2_model & model, |
|---|
| | | struct ggml_allocr * allocr, |
|---|
| | | struct gpt2_batch batch, |
|---|
| | | int n_threads, |
|---|
| | | std::vector<float> & logits) { |
|---|
| | | const int32_t n_tokens = batch.n_tokens; |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | if (n_tokens == 0) { |
|---|
| | | printf("%s: n_tokens == 0", __func__); |
|---|
| | | return -1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | GGML_ASSERT((!batch.token && batch.embd) || (batch.token && !batch.embd)); |
|---|
| | | |
|---|
| | | auto & cache = model.kv_cache; |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_tokens; i++) { |
|---|
| | | cache.cells[cache.head + i].pos = batch.pos[i]; |
|---|
| | | cache.cells[cache.head + i].seq_id.insert(batch.seq_id[i]); |
|---|
| | | } |
|---|
| | | |
|---|
| | | cache.n = cache.head + n_tokens; |
|---|
| | | |
|---|
| | | // reset the allocator to free all the memory allocated during the previous inference |
|---|
| | | ggml_allocr_reset(allocr); |
|---|
| | | |
|---|
| | | struct ggml_cgraph * gf = gpt2_graph(model, allocr, batch); |
|---|
| | | |
|---|
| | | // allocate tensors |
|---|
| | | ggml_allocr_alloc_graph(allocr, gf); |
|---|
| | | |
|---|
| | | // run the computation |
|---|
| | | if (ggml_backend_is_cpu(model.backend)) { |
|---|
| | | ggml_backend_cpu_set_n_threads(model.backend, n_threads); |
|---|
| | | } |
|---|
| | | #ifdef GGML_USE_METAL |
|---|
| | | if (ggml_backend_is_metal(model.backend)) { |
|---|
| | | ggml_backend_metal_set_n_cb(model.backend, n_threads); |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | ggml_backend_graph_compute(model.backend, gf); |
|---|
| | | |
|---|
| | | //if (n_past%100 == 0) { |
|---|
| | | // ggml_graph_print (&gf); |
|---|
| | | // ggml_graph_dump_dot(&gf, NULL, "gpt-2.dot"); |
|---|
| | | //} |
|---|
| | | |
|---|
| | | // in this case, the output tensor is the last one in the graph |
|---|
| | | struct ggml_tensor * inpL = gf->nodes[gf->n_nodes - 1]; |
|---|
| | | |
|---|
| | | if (batch.logits) { |
|---|
| | | // return logits for all tokens |
|---|
| | | logits.resize(n_vocab*n_tokens); |
|---|
| | | for (int32_t i = 0; i < n_tokens; i++) { |
|---|
| | | if (batch.logits[i] == 0) { |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | ggml_backend_tensor_get(inpL, logits.data() + n_vocab*i, n_vocab*i*sizeof(float), sizeof(float)*n_vocab); |
|---|
| | | } |
|---|
| | | } else { |
|---|
| | | // return result just for the last token |
|---|
| | | logits.resize(n_vocab); |
|---|
| | | ggml_backend_tensor_get(inpL, logits.data(), (n_vocab*(n_tokens-1))*sizeof(float), sizeof(float)*n_vocab); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // update the kv ring buffer |
|---|
| | | cache.head += n_tokens; |
|---|
| | | |
|---|
| | | // ensure kv cache head points to a valid index. |
|---|
| | | if (cache.head >= cache.size) { |
|---|
| | | printf("%s: cache.head >= cache.size\n", __func__); |
|---|
| | | return -2; |
|---|
| | | } |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | gpt_params params; |
|---|
| | | |
|---|
| | | if (gpt_params_parse(argc, argv, params) == false) { |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.seed < 0) { |
|---|
| | | params.seed = time(NULL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: seed = %d\n", __func__, params.seed); |
|---|
| | | |
|---|
| | | std::mt19937 rng(params.seed); |
|---|
| | | if (params.prompt.empty()) { |
|---|
| | | params.prompt = gpt_random_prompt(rng); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int64_t t_load_us = 0; |
|---|
| | | |
|---|
| | | gpt_vocab vocab; |
|---|
| | | gpt2_model model; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt2_model_load(params.model, model, vocab, params.n_ctx, params.n_gpu_layers)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | test_gpt_tokenizer(vocab, params.token_test); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // tokenize the prompt |
|---|
| | | std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, params.prompt); |
|---|
| | | |
|---|
| | | // keep this buffer alive while evaluating the model |
|---|
| | | ggml_backend_buffer_t buf_compute; |
|---|
| | | |
|---|
| | | const int n_parallel = params.n_parallel; |
|---|
| | | const int n_batch_max = std::max(embd_inp.size(), (size_t)n_parallel); |
|---|
| | | |
|---|
| | | // create a gpt2_batch |
|---|
| | | // we use this object to submit token data for decoding |
|---|
| | | gpt2_batch batch = gpt2_batch_init(n_batch_max, 0); |
|---|
| | | |
|---|
| | | // prepare required memory and allocate the compute buffer |
|---|
| | | struct ggml_allocr * allocr = NULL; |
|---|
| | | { |
|---|
| | | // create an allocator to measure the memory usage |
|---|
| | | allocr = ggml_allocr_new_measure_from_backend(model.backend); |
|---|
| | | |
|---|
| | | batch.n_tokens = n_batch_max; |
|---|
| | | |
|---|
| | | // create the worst case graph for memory usage estimation |
|---|
| | | struct ggml_cgraph * gf = gpt2_graph(model, allocr, batch); |
|---|
| | | |
|---|
| | | // compute the required memory |
|---|
| | | size_t mem_size = ggml_allocr_alloc_graph(allocr, gf); |
|---|
| | | |
|---|
| | | // recreate the allocator with the required memory |
|---|
| | | ggml_allocr_free(allocr); |
|---|
| | | buf_compute = ggml_backend_alloc_buffer(model.backend, mem_size); |
|---|
| | | allocr = ggml_allocr_new_from_buffer(buf_compute); |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s: compute buffer size: %.2f MB\n", __func__, mem_size/1024.0/1024.0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int64_t t_sample_us = 0; |
|---|
| | | int64_t t_predict_us = 0; |
|---|
| | | |
|---|
| | | std::vector<float> logits; |
|---|
| | | |
|---|
| | | // evaluate the initial prompt |
|---|
| | | batch.n_tokens = embd_inp.size(); |
|---|
| | | |
|---|
| | | for (int32_t i = 0; i < batch.n_tokens; i++) { |
|---|
| | | batch.token[i] = embd_inp[i]; |
|---|
| | | batch.pos[i] = i; |
|---|
| | | batch.seq_id[i] = 0; |
|---|
| | | batch.logits[i] = false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // gpt2_decode will output logits only for the last token of the prompt |
|---|
| | | batch.logits[batch.n_tokens - 1] = true; |
|---|
| | | |
|---|
| | | if (gpt2_decode(model, allocr, batch, params.n_threads, logits) != 0) { |
|---|
| | | printf("%s: gpt2_decode() failed\n", __func__); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // assign the system KV cache to all parallel sequences |
|---|
| | | // this way, the parallel sequences will "reuse" the prompt tokens without having to copy them |
|---|
| | | for (int32_t i = 1; i < n_parallel; ++i) { |
|---|
| | | gpt2_kv_cache_seq_cp(model.kv_cache, 0, i, 0, batch.n_tokens); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (n_parallel > 1) { |
|---|
| | | printf("\n\n%s: generating %d sequences ...\n", __func__, n_parallel); |
|---|
| | | } |
|---|
| | | |
|---|
| | | params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size()); |
|---|
| | | |
|---|
| | | printf("%s: prompt: '%s'\n", __func__, params.prompt.c_str()); |
|---|
| | | printf("%s: number of tokens in prompt = %zu, first 8 tokens: ", __func__, embd_inp.size()); |
|---|
| | | for (int i = 0; i < std::min(8, (int) embd_inp.size()); i++) { |
|---|
| | | printf("%d ", embd_inp[i]); |
|---|
| | | } |
|---|
| | | printf("\n\n"); |
|---|
| | | |
|---|
| | | std::vector<gpt_vocab::token> streams(n_parallel); |
|---|
| | | |
|---|
| | | // remember the batch index of the last token for each parallel sequence |
|---|
| | | // we need this to determine which logits to sample from |
|---|
| | | std::vector<int32_t> i_batch(n_parallel, batch.n_tokens - 1); |
|---|
| | | |
|---|
| | | int n_cur = batch.n_tokens; |
|---|
| | | int n_len = batch.n_tokens + params.n_predict; |
|---|
| | | int n_decoded = 0; |
|---|
| | | |
|---|
| | | const int n_vocab = model.hparams.n_vocab; |
|---|
| | | const int top_k = params.top_k; |
|---|
| | | const float top_p = params.top_p; |
|---|
| | | const float temp = params.temp; |
|---|
| | | |
|---|
| | | while (n_cur < n_len) { |
|---|
| | | batch.n_tokens = 0; |
|---|
| | | |
|---|
| | | for (int32_t i = 0; i < n_parallel; ++i) { |
|---|
| | | if (i_batch[i] < 0) { |
|---|
| | | // the stream has already finished |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto * logits_i = logits.data() + i_batch[i]*n_vocab; |
|---|
| | | |
|---|
| | | gpt_vocab::id id = 0; |
|---|
| | | { |
|---|
| | | const int64_t t_start_sample_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | id = gpt_sample_top_k_top_p(vocab, logits_i, top_k, top_p, temp, rng); |
|---|
| | | |
|---|
| | | t_sample_us += ggml_time_us() - t_start_sample_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // is it an end of stream? -> mark the stream as finished |
|---|
| | | if ((!params.ignore_eos && id == 50256) || n_cur == n_len - 1) { |
|---|
| | | i_batch[i] = -1; |
|---|
| | | printf("\n"); |
|---|
| | | if (n_parallel > 1) { |
|---|
| | | printf("%s: stream %d finished at n_cur = %d", __func__, i, n_cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | continue; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto& token = vocab.id_to_token[id]; |
|---|
| | | if (n_parallel == 1) { |
|---|
| | | printf("%s", token.c_str()); |
|---|
| | | fflush(stdout); |
|---|
| | | } |
|---|
| | | |
|---|
| | | streams[i] += token; |
|---|
| | | |
|---|
| | | // push this new token for next evaluation |
|---|
| | | batch.token [batch.n_tokens] = id; |
|---|
| | | batch.pos [batch.n_tokens] = n_cur; |
|---|
| | | batch.seq_id[batch.n_tokens] = i; |
|---|
| | | batch.logits[batch.n_tokens] = true; |
|---|
| | | |
|---|
| | | i_batch[i] = batch.n_tokens; |
|---|
| | | |
|---|
| | | batch.n_tokens += 1; |
|---|
| | | |
|---|
| | | n_decoded += 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // all streams are finished |
|---|
| | | if (batch.n_tokens == 0) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | n_cur += 1; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | // evaluate the current batch with the transformer model |
|---|
| | | int ret_code = gpt2_decode(model, allocr, batch, params.n_threads, logits); |
|---|
| | | if (ret_code != 0) { |
|---|
| | | fprintf(stderr, "%s : failed to eval, return code %d\n", __func__, ret_code); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_predict_us += ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (n_parallel > 1) { |
|---|
| | | printf("\n"); |
|---|
| | | |
|---|
| | | for (int32_t i = 0; i < n_parallel; ++i) { |
|---|
| | | printf("sequence %d:\n\n%s%s\n\n", i, params.prompt.c_str(), streams[i].c_str()); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n\n"); |
|---|
| | | printf("%s: n_decoded = %8d\n", __func__, n_decoded); |
|---|
| | | printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f); |
|---|
| | | printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f); |
|---|
| | | printf("%s: predict time = %8.2f ms\n", __func__, t_predict_us/1000.0f); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | gpt2_batch_free(batch); |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | ggml_backend_buffer_free(model.buffer_w); |
|---|
| | | ggml_backend_buffer_free(model.kv_cache.buffer); |
|---|
| | | ggml_backend_buffer_free(buf_compute); |
|---|
| | | ggml_backend_free(model.backend); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | // default hparams (GPT-2 117M) |
|---|
| | | struct gpt2_hparams { |
|---|
| | | int32_t n_vocab = 50257; |
|---|
| | | int32_t n_ctx = 1024; |
|---|
| | | int32_t n_embd = 768; |
|---|
| | | int32_t n_head = 12; |
|---|
| | | int32_t n_layer = 12; |
|---|
| | | int32_t ftype = 1; |
|---|
| | | float eps = 1e-5f; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_layer { |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_1_g; |
|---|
| | | struct ggml_tensor * ln_1_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * ln_2_g; |
|---|
| | | struct ggml_tensor * ln_2_b; |
|---|
| | | |
|---|
| | | // attention |
|---|
| | | struct ggml_tensor * c_attn_attn_w; |
|---|
| | | struct ggml_tensor * c_attn_attn_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_attn_proj_w; |
|---|
| | | struct ggml_tensor * c_attn_proj_b; |
|---|
| | | |
|---|
| | | // mlp |
|---|
| | | struct ggml_tensor * c_mlp_fc_w; |
|---|
| | | struct ggml_tensor * c_mlp_fc_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_mlp_proj_w; |
|---|
| | | struct ggml_tensor * c_mlp_proj_b; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_model { |
|---|
| | | gpt2_hparams hparams; |
|---|
| | | |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_f_g; |
|---|
| | | struct ggml_tensor * ln_f_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * wte; // position embedding |
|---|
| | | struct ggml_tensor * wpe; // token embedding |
|---|
| | | struct ggml_tensor * lm_head; // language model head |
|---|
| | | |
|---|
| | | std::vector<gpt2_layer> layers; |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | struct ggml_tensor * memory_k; |
|---|
| | | struct ggml_tensor * memory_v; |
|---|
| | | |
|---|
| | | // |
|---|
| | | struct ggml_context * ctx; |
|---|
| | | std::map<std::string, struct ggml_tensor *> tensors; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // load the model's weights from a file |
|---|
| | | bool gpt2_model_load(const std::string & fname, gpt2_model & model, gpt_vocab & vocab) { |
|---|
| | | printf("%s: loading model from '%s'\n", __func__, fname.c_str()); |
|---|
| | | |
|---|
| | | auto fin = std::ifstream(fname, std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | fin.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fin.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fin.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: ftype = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr = %d\n", __func__, qntvr); |
|---|
| | | |
|---|
| | | hparams.ftype %= GGML_QNT_VERSION_FACTOR; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | int32_t n_vocab = 0; |
|---|
| | | fin.read((char *) &n_vocab, sizeof(n_vocab)); |
|---|
| | | |
|---|
| | | if (n_vocab != model.hparams.n_vocab) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n", |
|---|
| | | __func__, fname.c_str(), n_vocab, model.hparams.n_vocab); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | std::vector<char> buf(128); |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | fin.read((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | buf.resize(len); |
|---|
| | | fin.read((char *) buf.data(), len); |
|---|
| | | word.assign(buf.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for the big tensors, we have the option to store the data in 16-bit floats or quantized |
|---|
| | | // in order to save memory and also to speed up the computation |
|---|
| | | ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype)); |
|---|
| | | if (wtype == GGML_TYPE_COUNT) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n", |
|---|
| | | __func__, fname.c_str(), model.hparams.ftype); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto & ctx = model.ctx; |
|---|
| | | |
|---|
| | | size_t ctx_size = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_g |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_b |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(wtype, n_vocab*n_embd); // wte |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_ctx*n_embd); // wpe |
|---|
| | | ctx_size += ggml_row_size(wtype, n_vocab*n_embd); // lm_head |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_g |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_2_g |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_2_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 3*n_embd*n_embd)); // c_attn_attn_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 3*n_embd)); // c_attn_attn_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, n_embd*n_embd)); // c_attn_proj_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // c_attn_proj_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_fc_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 4*n_embd)); // c_mlp_fc_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_proj_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 4*n_embd)); // c_mlp_proj_b |
|---|
| | | |
|---|
| | | ctx_size += n_ctx*n_layer*ggml_row_size(GGML_TYPE_F32, n_embd); // memory_k |
|---|
| | | ctx_size += n_ctx*n_layer*ggml_row_size(GGML_TYPE_F32, n_embd); // memory_v |
|---|
| | | |
|---|
| | | ctx_size += (6 + 12*n_layer)*512; // object overhead |
|---|
| | | |
|---|
| | | printf("%s: ggml tensor size = %d bytes\n", __func__, (int) sizeof(ggml_tensor)); |
|---|
| | | printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // create the ggml context |
|---|
| | | { |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ ctx_size, |
|---|
| | | /*.mem_buffer =*/ NULL, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | model.ctx = ggml_init(params); |
|---|
| | | if (!model.ctx) { |
|---|
| | | fprintf(stderr, "%s: ggml_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // prepare memory for the weights |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | model.layers.resize(n_layer); |
|---|
| | | |
|---|
| | | model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | model.wpe = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_ctx); |
|---|
| | | model.lm_head = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["model/ln_f/g"] = model.ln_f_g; |
|---|
| | | model.tensors["model/ln_f/b"] = model.ln_f_b; |
|---|
| | | |
|---|
| | | model.tensors["model/wte"] = model.wte; |
|---|
| | | model.tensors["model/wpe"] = model.wpe; |
|---|
| | | model.tensors["model/lm_head"] = model.lm_head; |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_layer; ++i) { |
|---|
| | | auto & layer = model.layers[i]; |
|---|
| | | |
|---|
| | | layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.ln_2_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_2_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_attn_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 3*n_embd); |
|---|
| | | layer.c_attn_attn_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 3*n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | layer.c_attn_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd); |
|---|
| | | layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd); |
|---|
| | | layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_1/g"] = layer.ln_1_g; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_1/b"] = layer.ln_1_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_2/g"] = layer.ln_2_g; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_2/b"] = layer.ln_2_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/w"] = layer.c_attn_attn_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/b"] = layer.c_attn_attn_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/w"] = layer.c_attn_proj_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/b"] = layer.c_attn_proj_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/w"] = layer.c_mlp_fc_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/b"] = layer.c_mlp_fc_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/w"] = layer.c_mlp_proj_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/b"] = layer.c_mlp_proj_b; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | |
|---|
| | | const int n_mem = n_layer*n_ctx; |
|---|
| | | const int n_elements = n_embd*n_mem; |
|---|
| | | |
|---|
| | | model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements); |
|---|
| | | model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements); |
|---|
| | | |
|---|
| | | const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v); |
|---|
| | | |
|---|
| | | printf("%s: memory size = %8.2f MB, n_mem = %d\n", __func__, memory_size/1024.0/1024.0, n_mem); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load weights |
|---|
| | | { |
|---|
| | | size_t total_size = 0; |
|---|
| | | |
|---|
| | | bool has_lm_head = false; |
|---|
| | | |
|---|
| | | while (true) { |
|---|
| | | int32_t n_dims; |
|---|
| | | int32_t length; |
|---|
| | | int32_t ttype; |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&length), sizeof(length)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype)); |
|---|
| | | |
|---|
| | | if (fin.eof()) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int32_t nelements = 1; |
|---|
| | | int32_t ne[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i])); |
|---|
| | | nelements *= ne[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string name(length, 0); |
|---|
| | | fin.read(&name[0], length); |
|---|
| | | |
|---|
| | | if (model.tensors.find(name) == model.tensors.end()) { |
|---|
| | | fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto tensor = model.tensors[name]; |
|---|
| | | if (ggml_nelements(tensor) != nelements) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%d, %d], expected [%d, %d]\n", |
|---|
| | | __func__, name.c_str(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for debugging |
|---|
| | | if (0) { |
|---|
| | | printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.c_str(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const size_t bpe = ggml_type_size(ggml_type(ttype)); |
|---|
| | | |
|---|
| | | if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n", |
|---|
| | | __func__, name.c_str(), ggml_nbytes(tensor), nelements*bpe); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor)); |
|---|
| | | |
|---|
| | | // GPT-2 models share the WTE tensor as the LM head |
|---|
| | | if (name == "model/wte" && has_lm_head == false) { |
|---|
| | | memcpy(model.lm_head->data, tensor->data, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (name == "model/lm_head") { |
|---|
| | | has_lm_head = true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | total_size += ggml_nbytes(tensor); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: model size = %8.2f MB\n", __func__, total_size/1024.0/1024.0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // evaluate the transformer |
|---|
| | | // |
|---|
| | | // - model: the model |
|---|
| | | // - n_threads: number of threads to use |
|---|
| | | // - n_past: the context size so far |
|---|
| | | // - embd_inp: the embeddings of the tokens in the context |
|---|
| | | // - embd_w: the predicted logits for the next token |
|---|
| | | // |
|---|
| | | bool gpt2_eval( |
|---|
| | | const gpt2_model & model, |
|---|
| | | const int n_threads, |
|---|
| | | const int n_past, |
|---|
| | | const std::vector<gpt_vocab::id> & embd_inp, |
|---|
| | | std::vector<float> & embd_w, |
|---|
| | | size_t & mem_per_token) { |
|---|
| | | const int N = embd_inp.size(); |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_head = hparams.n_head; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | static size_t buf_size = 256u*1024*1024; |
|---|
| | | static void * buf = malloc(buf_size); |
|---|
| | | |
|---|
| | | if (mem_per_token > 0 && mem_per_token*N > buf_size) { |
|---|
| | | const size_t buf_size_new = 1.1*(mem_per_token*N); // add 10% to account for ggml object overhead |
|---|
| | | //printf("\n%s: reallocating buffer from %zu to %zu bytes\n", __func__, buf_size, buf_size_new); |
|---|
| | | |
|---|
| | | // reallocate |
|---|
| | | buf_size = buf_size_new; |
|---|
| | | buf = realloc(buf, buf_size); |
|---|
| | | if (buf == nullptr) { |
|---|
| | | fprintf(stderr, "%s: failed to allocate %zu bytes\n", __func__, buf_size); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx0 = ggml_init(params); |
|---|
| | | struct ggml_cgraph * gf = ggml_new_graph(ctx0); |
|---|
| | | |
|---|
| | | struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | memcpy(embd->data, embd_inp.data(), N*ggml_element_size(embd)); |
|---|
| | | |
|---|
| | | struct ggml_tensor * position = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | for (int i = 0; i < N; ++i) { |
|---|
| | | ((int32_t *) position->data)[i] = n_past + i; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // wte + wpe |
|---|
| | | struct ggml_tensor * inpL = |
|---|
| | | ggml_add(ctx0, |
|---|
| | | ggml_get_rows(ctx0, model.wte, embd), |
|---|
| | | ggml_get_rows(ctx0, model.wpe, position)); |
|---|
| | | |
|---|
| | | for (int il = 0; il < n_layer; ++il) { |
|---|
| | | struct ggml_tensor * cur; |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // cur = ln_1_g*cur + ln_1_b |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_1_g, cur), |
|---|
| | | cur), |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_1_b, cur)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // attn |
|---|
| | | // [2304, 768] - model.layers[il].c_attn_attn_w |
|---|
| | | // [2304, 1] - model.layers[il].c_attn_attn_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [2304, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = attn_w*cur + attn_b |
|---|
| | | // [2304, N] |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_attn_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_attn_attn_b, cur), |
|---|
| | | cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // self-attention |
|---|
| | | { |
|---|
| | | struct ggml_tensor * Qcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 0*sizeof(float)*n_embd); |
|---|
| | | struct ggml_tensor * Kcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 1*sizeof(float)*n_embd); |
|---|
| | | struct ggml_tensor * Vcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 2*sizeof(float)*n_embd); |
|---|
| | | |
|---|
| | | // store key and value to memory |
|---|
| | | if (N >= 1) { |
|---|
| | | struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past)); |
|---|
| | | struct ggml_tensor * v = ggml_view_1d(ctx0, model.memory_v, N*n_embd, (ggml_element_size(model.memory_v)*n_embd)*(il*n_ctx + n_past)); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3) |
|---|
| | | // [64, N, 12] |
|---|
| | | struct ggml_tensor * Q = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_cpy(ctx0, |
|---|
| | | Qcur, |
|---|
| | | ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_embd/n_head, n_head, N)), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3) |
|---|
| | | // [64, n_past + N, 12] |
|---|
| | | struct ggml_tensor * K = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_past + N), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // GG: flash attention |
|---|
| | | //struct ggml_tensor * V = |
|---|
| | | // ggml_cpy(ctx0, |
|---|
| | | // ggml_permute(ctx0, |
|---|
| | | // ggml_reshape_3d(ctx0, |
|---|
| | | // ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd), |
|---|
| | | // n_embd/n_head, n_head, n_past + N), |
|---|
| | | // 1, 2, 0, 3), |
|---|
| | | // ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_past + N, n_embd/n_head, n_head)); |
|---|
| | | |
|---|
| | | //struct ggml_tensor * KQV = ggml_flash_attn(ctx0, Q, K, V, true); |
|---|
| | | |
|---|
| | | // K * Q |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); |
|---|
| | | |
|---|
| | | // KQ_scaled = KQ / sqrt(n_embd/n_head) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_scaled = ggml_scale_inplace(ctx0, KQ, 1.0f/sqrt(float(n_embd)/n_head)); |
|---|
| | | |
|---|
| | | // KQ_masked = mask_past(KQ_scaled) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_masked = ggml_diag_mask_inf_inplace(ctx0, KQ_scaled, n_past); |
|---|
| | | |
|---|
| | | // KQ = soft_max(KQ_masked) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked); |
|---|
| | | |
|---|
| | | // V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous() |
|---|
| | | // [n_past + N, 64, 12] |
|---|
| | | struct ggml_tensor * V_trans = |
|---|
| | | ggml_cpy(ctx0, |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_past + N), |
|---|
| | | 1, 2, 0, 3), |
|---|
| | | ggml_new_tensor_3d(ctx0, model.memory_v->type, n_past + N, n_embd/n_head, n_head)); |
|---|
| | | |
|---|
| | | // KQV = transpose(V) * KQ_soft_max |
|---|
| | | // [64, N, 12] |
|---|
| | | struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V_trans, KQ_soft_max); |
|---|
| | | |
|---|
| | | // KQV_merged = KQV.permute(0, 2, 1, 3) |
|---|
| | | // [64, 12, N] |
|---|
| | | struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // cur = KQV_merged.contiguous().view(n_embd, N) |
|---|
| | | // [768, N] |
|---|
| | | cur = ggml_cpy(ctx0, |
|---|
| | | KQV_merged, |
|---|
| | | ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // [ 768, 768] - model.layers[il].c_attn_proj_w |
|---|
| | | // [ 768, 1] - model.layers[il].c_attn_proj_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [ 768, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | // [768, N] |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_attn_proj_b, cur), |
|---|
| | | cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add the input |
|---|
| | | cur = ggml_add(ctx0, cur, inpL); |
|---|
| | | |
|---|
| | | struct ggml_tensor * inpFF = cur; |
|---|
| | | |
|---|
| | | // feed-forward network |
|---|
| | | { |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | cur = ggml_norm(ctx0, inpFF, hparams.eps); |
|---|
| | | |
|---|
| | | // cur = ln_2_g*cur + ln_2_b |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_2_g, cur), |
|---|
| | | cur), |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_2_b, cur)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // fully connected |
|---|
| | | // [3072, 768] - model.layers[il].c_mlp_fc_w |
|---|
| | | // [3072, 1] - model.layers[il].c_mlp_fc_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [3072, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = fc_w*cur + fc_b |
|---|
| | | // [3072, N] |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_fc_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_mlp_fc_b, cur), |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | // GELU activation |
|---|
| | | // [3072, N] |
|---|
| | | cur = ggml_gelu(ctx0, cur); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // [ 768, 3072] - model.layers[il].c_mlp_proj_w |
|---|
| | | // [ 768, 1] - model.layers[il].c_mlp_proj_b |
|---|
| | | // [3072, N] - cur (in) |
|---|
| | | // [ 768, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | // [768, N] |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_mlp_proj_b, cur), |
|---|
| | | cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // input for next layer |
|---|
| | | inpL = ggml_add(ctx0, cur, inpFF); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | // [ 768, N] |
|---|
| | | inpL = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // inpL = ln_f_g*inpL + ln_f_b |
|---|
| | | // [ 768, N] |
|---|
| | | inpL = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.ln_f_g, inpL), |
|---|
| | | inpL), |
|---|
| | | ggml_repeat(ctx0, model.ln_f_b, inpL)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // inpL = WTE * inpL |
|---|
| | | // [ 768, 50257] - model.lm_head |
|---|
| | | // [ 768, N] - inpL |
|---|
| | | inpL = ggml_mul_mat(ctx0, model.lm_head, inpL); |
|---|
| | | |
|---|
| | | // logits -> probs |
|---|
| | | //inpL = ggml_soft_max_inplace(ctx0, inpL); |
|---|
| | | |
|---|
| | | // run the computation |
|---|
| | | ggml_build_forward_expand(gf, inpL); |
|---|
| | | ggml_graph_compute_with_ctx(ctx0, gf, n_threads); |
|---|
| | | |
|---|
| | | //if (n_past%100 == 0) { |
|---|
| | | // ggml_graph_print (&gf); |
|---|
| | | // ggml_graph_dump_dot(&gf, NULL, "gpt-2.dot"); |
|---|
| | | //} |
|---|
| | | |
|---|
| | | //embd_w.resize(n_vocab*N); |
|---|
| | | //memcpy(embd_w.data(), ggml_get_data(inpL), sizeof(float)*n_vocab*N); |
|---|
| | | |
|---|
| | | // return result just for the last token |
|---|
| | | embd_w.resize(n_vocab); |
|---|
| | | memcpy(embd_w.data(), (float *) ggml_get_data(inpL) + (n_vocab*(N-1)), sizeof(float)*n_vocab); |
|---|
| | | |
|---|
| | | if (mem_per_token == 0) { |
|---|
| | | mem_per_token = ggml_used_mem(ctx0)/N; |
|---|
| | | } |
|---|
| | | //printf("used_mem = %zu\n", ggml_used_mem(ctx0)); |
|---|
| | | |
|---|
| | | ggml_free(ctx0); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | gpt_params params; |
|---|
| | | params.model = "models/gpt-2-117M/ggml-model.bin"; |
|---|
| | | |
|---|
| | | if (gpt_params_parse(argc, argv, params) == false) { |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.seed < 0) { |
|---|
| | | params.seed = time(NULL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: seed = %d\n", __func__, params.seed); |
|---|
| | | |
|---|
| | | std::mt19937 rng(params.seed); |
|---|
| | | if (params.prompt.empty()) { |
|---|
| | | params.prompt = gpt_random_prompt(rng); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int64_t t_load_us = 0; |
|---|
| | | |
|---|
| | | gpt_vocab vocab; |
|---|
| | | gpt2_model model; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt2_model_load(params.model, model, vocab)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | test_gpt_tokenizer(vocab, params.token_test); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int n_past = 0; |
|---|
| | | |
|---|
| | | int64_t t_sample_us = 0; |
|---|
| | | int64_t t_predict_us = 0; |
|---|
| | | |
|---|
| | | std::vector<float> logits; |
|---|
| | | |
|---|
| | | // tokenize the prompt |
|---|
| | | std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, params.prompt); |
|---|
| | | |
|---|
| | | params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size()); |
|---|
| | | |
|---|
| | | printf("%s: prompt: '%s'\n", __func__, params.prompt.c_str()); |
|---|
| | | printf("%s: number of tokens in prompt = %zu, first 8 tokens: ", __func__, embd_inp.size()); |
|---|
| | | for (int i = 0; i < std::min(8, (int) embd_inp.size()); i++) { |
|---|
| | | printf("%d ", embd_inp[i]); |
|---|
| | | } |
|---|
| | | printf("\n\n"); |
|---|
| | | |
|---|
| | | // submit the input prompt token-by-token |
|---|
| | | // this reduces the memory usage during inference, at the cost of a bit of speed at the beginning |
|---|
| | | std::vector<gpt_vocab::id> embd; |
|---|
| | | |
|---|
| | | // determine the required inference memory per token: |
|---|
| | | size_t mem_per_token = 0; |
|---|
| | | gpt2_eval(model, params.n_threads, 0, { 0, 1, 2, 3 }, logits, mem_per_token); |
|---|
| | | |
|---|
| | | for (size_t i = embd.size(); i < embd_inp.size() + params.n_predict; i++) { |
|---|
| | | // predict |
|---|
| | | if (embd.size() > 0) { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt2_eval(model, params.n_threads, n_past, embd, logits, mem_per_token)) { |
|---|
| | | printf("Failed to predict\n"); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_predict_us += ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | n_past += embd.size(); |
|---|
| | | embd.clear(); |
|---|
| | | |
|---|
| | | if (i >= embd_inp.size()) { |
|---|
| | | // sample next token |
|---|
| | | const int top_k = params.top_k; |
|---|
| | | const float top_p = params.top_p; |
|---|
| | | const float temp = params.temp; |
|---|
| | | |
|---|
| | | const int n_vocab = model.hparams.n_vocab; |
|---|
| | | |
|---|
| | | gpt_vocab::id id = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const int64_t t_start_sample_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng); |
|---|
| | | |
|---|
| | | t_sample_us += ggml_time_us() - t_start_sample_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add it to the context |
|---|
| | | embd.push_back(id); |
|---|
| | | } else { |
|---|
| | | // if here, it means we are still processing the input prompt |
|---|
| | | for (size_t k = i; k < embd_inp.size(); k++) { |
|---|
| | | embd.push_back(embd_inp[k]); |
|---|
| | | if (int32_t(embd.size()) >= params.n_batch) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | i += embd.size() - 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // display text |
|---|
| | | for (auto id : embd) { |
|---|
| | | printf("%s", vocab.id_to_token[id].c_str()); |
|---|
| | | } |
|---|
| | | fflush(stdout); |
|---|
| | | |
|---|
| | | // end of text token |
|---|
| | | if (embd.back() == 50256) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n\n"); |
|---|
| | | printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token); |
|---|
| | | printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f); |
|---|
| | | printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f); |
|---|
| | | printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us/1000.0f, t_predict_us/1000.0f/n_past); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | #include "ggml/ggml-alloc.h" |
|---|
| | | #include "ggml/ggml-backend.h" |
|---|
| | | |
|---|
| | | #ifdef GGML_USE_CUBLAS |
|---|
| | | #include "ggml-cuda.h" |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #ifdef GGML_USE_METAL |
|---|
| | | #include "ggml-metal.h" |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #define GPT2_MAX_NODES 4096 |
|---|
| | | |
|---|
| | | static void ggml_log_callback_default(ggml_log_level level, const char * text, void * user_data) { |
|---|
| | | (void) level; |
|---|
| | | (void) user_data; |
|---|
| | | fputs(text, stderr); |
|---|
| | | fflush(stderr); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // default hparams (GPT-2 117M) |
|---|
| | | struct gpt2_hparams { |
|---|
| | | int32_t n_vocab = 50257; |
|---|
| | | int32_t n_ctx = 1024; |
|---|
| | | int32_t n_embd = 768; |
|---|
| | | int32_t n_head = 12; |
|---|
| | | int32_t n_layer = 12; |
|---|
| | | int32_t ftype = 1; |
|---|
| | | float eps = 1e-5f; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_layer { |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_1_g; |
|---|
| | | struct ggml_tensor * ln_1_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * ln_2_g; |
|---|
| | | struct ggml_tensor * ln_2_b; |
|---|
| | | |
|---|
| | | // attention |
|---|
| | | struct ggml_tensor * c_attn_attn_w; |
|---|
| | | struct ggml_tensor * c_attn_attn_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_attn_proj_w; |
|---|
| | | struct ggml_tensor * c_attn_proj_b; |
|---|
| | | |
|---|
| | | // mlp |
|---|
| | | struct ggml_tensor * c_mlp_fc_w; |
|---|
| | | struct ggml_tensor * c_mlp_fc_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_mlp_proj_w; |
|---|
| | | struct ggml_tensor * c_mlp_proj_b; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt2_model { |
|---|
| | | gpt2_hparams hparams; |
|---|
| | | |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_f_g; |
|---|
| | | struct ggml_tensor * ln_f_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * wte; // position embedding |
|---|
| | | struct ggml_tensor * wpe; // token embedding |
|---|
| | | struct ggml_tensor * lm_head; // language model head |
|---|
| | | |
|---|
| | | std::vector<gpt2_layer> layers; |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | struct ggml_tensor * memory_k; |
|---|
| | | struct ggml_tensor * memory_v; |
|---|
| | | |
|---|
| | | // |
|---|
| | | struct ggml_context * ctx; |
|---|
| | | |
|---|
| | | std::vector<ggml_backend_t> backends; |
|---|
| | | std::vector<ggml_backend_buffer_t> buffers_w; |
|---|
| | | ggml_backend_buffer_t buffer_kv; |
|---|
| | | ggml_backend_buffer_t buffer_input; |
|---|
| | | |
|---|
| | | std::map<std::string, struct ggml_tensor *> tensors; |
|---|
| | | |
|---|
| | | // inputs/constants |
|---|
| | | struct ggml_tensor * embd; |
|---|
| | | struct ggml_tensor * position; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | void init_backends(gpt2_model & model, const gpt_params & params) { |
|---|
| | | ggml_backend_t gpu_backend = NULL; |
|---|
| | | |
|---|
| | | // initialize the backends |
|---|
| | | #ifdef GGML_USE_CUBLAS |
|---|
| | | if (params.n_gpu_layers > 0) { |
|---|
| | | fprintf(stderr, "%s: using CUDA backend\n", __func__); |
|---|
| | | gpu_backend = ggml_backend_cuda_init(0); |
|---|
| | | if (!gpu_backend) { |
|---|
| | | fprintf(stderr, "%s: ggml_backend_cuda_init() failed\n", __func__); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | #ifdef GGML_USE_METAL |
|---|
| | | if (params.n_gpu_layers > 0) { |
|---|
| | | fprintf(stderr, "%s: using Metal backend\n", __func__); |
|---|
| | | ggml_backend_metal_log_set_callback(ggml_log_callback_default, nullptr); |
|---|
| | | gpu_backend = ggml_backend_metal_init(); |
|---|
| | | if (!gpu_backend) { |
|---|
| | | fprintf(stderr, "%s: ggml_backend_metal_init() failed\n", __func__); |
|---|
| | | } else { |
|---|
| | | ggml_backend_metal_set_n_cb(gpu_backend, params.n_threads); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | if (gpu_backend) { |
|---|
| | | model.backends.push_back(gpu_backend); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // always add the CPU backend as a fallback |
|---|
| | | ggml_backend_t cpu_backend = ggml_backend_cpu_init(); |
|---|
| | | ggml_backend_cpu_set_n_threads(cpu_backend, params.n_threads); |
|---|
| | | model.backends.push_back(cpu_backend); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load the model's weights from a file |
|---|
| | | bool gpt2_model_load(const std::string & fname, gpt2_model & model, gpt_vocab & vocab, const gpt_params & params) { |
|---|
| | | printf("%s: loading model from '%s'\n", __func__, fname.c_str()); |
|---|
| | | |
|---|
| | | auto fin = std::ifstream(fname, std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | fin.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fin.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fin.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: ftype = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr = %d\n", __func__, qntvr); |
|---|
| | | |
|---|
| | | hparams.ftype %= GGML_QNT_VERSION_FACTOR; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | int32_t n_vocab = 0; |
|---|
| | | fin.read((char *) &n_vocab, sizeof(n_vocab)); |
|---|
| | | |
|---|
| | | if (n_vocab != model.hparams.n_vocab) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n", |
|---|
| | | __func__, fname.c_str(), n_vocab, model.hparams.n_vocab); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | std::vector<char> buf(128); |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | fin.read((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | buf.resize(len); |
|---|
| | | fin.read((char *) buf.data(), len); |
|---|
| | | word.assign(buf.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for the big tensors, we have the option to store the data in 16-bit floats or quantized |
|---|
| | | // in order to save memory and also to speed up the computation |
|---|
| | | ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype)); |
|---|
| | | if (wtype == GGML_TYPE_COUNT) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n", |
|---|
| | | __func__, fname.c_str(), model.hparams.ftype); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto & ctx = model.ctx; |
|---|
| | | |
|---|
| | | // create the ggml context |
|---|
| | | { |
|---|
| | | size_t n_tensors = 3 /* input */ + 2 /* kv */ + 6 + 12*model.hparams.n_layer; |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ ggml_tensor_overhead() * n_tensors, |
|---|
| | | /*.mem_buffer =*/ NULL, |
|---|
| | | /*.no_alloc =*/ true, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | model.ctx = ggml_init(params); |
|---|
| | | if (!model.ctx) { |
|---|
| | | fprintf(stderr, "%s: ggml_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // create tensors for the weights |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | model.layers.resize(n_layer); |
|---|
| | | |
|---|
| | | model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | model.wpe = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_embd, n_ctx); |
|---|
| | | model.lm_head = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["model/ln_f/g"] = model.ln_f_g; |
|---|
| | | model.tensors["model/ln_f/b"] = model.ln_f_b; |
|---|
| | | |
|---|
| | | model.tensors["model/wte"] = model.wte; |
|---|
| | | model.tensors["model/wpe"] = model.wpe; |
|---|
| | | model.tensors["model/lm_head"] = model.lm_head; |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_layer; ++i) { |
|---|
| | | auto & layer = model.layers[i]; |
|---|
| | | |
|---|
| | | layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.ln_2_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_2_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_attn_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 3*n_embd); |
|---|
| | | layer.c_attn_attn_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 3*n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | layer.c_attn_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd); |
|---|
| | | layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd); |
|---|
| | | layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_1/g"] = layer.ln_1_g; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_1/b"] = layer.ln_1_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_2/g"] = layer.ln_2_g; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/ln_2/b"] = layer.ln_2_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/w"] = layer.c_attn_attn_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_attn/b"] = layer.c_attn_attn_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/w"] = layer.c_attn_proj_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/attn/c_proj/b"] = layer.c_attn_proj_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/w"] = layer.c_mlp_fc_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_fc/b"] = layer.c_mlp_fc_b; |
|---|
| | | |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/w"] = layer.c_mlp_proj_w; |
|---|
| | | model.tensors["model/h" + std::to_string(i) + "/mlp/c_proj/b"] = layer.c_mlp_proj_b; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // assign tensors to backends |
|---|
| | | init_backends(model, params); |
|---|
| | | ggml_backend_t backend_gpu = model.backends.front(); |
|---|
| | | ggml_backend_t backend_cpu = model.backends.back(); |
|---|
| | | std::map<std::string, ggml_backend_t> tensor_backends; |
|---|
| | | { |
|---|
| | | const int i_gpu_first_layer = model.hparams.n_layer - params.n_gpu_layers; |
|---|
| | | for (auto it : model.tensors) { |
|---|
| | | const std::string & name = it.first; |
|---|
| | | // input tensors |
|---|
| | | if (name == "model/wte" || name == "model/wpe") { |
|---|
| | | if (params.n_gpu_layers > model.hparams.n_layer) { |
|---|
| | | tensor_backends[name] = backend_gpu; |
|---|
| | | } else { |
|---|
| | | tensor_backends[name] = backend_cpu; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | // output tensors |
|---|
| | | if (name == "model/ln_f/g" || name == "model/ln_f/b" || name == "model/lm_head") { |
|---|
| | | if (params.n_gpu_layers > 0) { |
|---|
| | | tensor_backends[name] = backend_gpu; |
|---|
| | | } else { |
|---|
| | | tensor_backends[name] = backend_cpu; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | // layer tensors |
|---|
| | | if (name.substr(0, 7) == "model/h") { |
|---|
| | | // parse layer number |
|---|
| | | int layer = std::stoi(name.substr(7, 2)); |
|---|
| | | if (layer >= i_gpu_first_layer) { |
|---|
| | | tensor_backends[name] = backend_gpu; |
|---|
| | | } else { |
|---|
| | | tensor_backends[name] = backend_cpu; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // allocate buffers |
|---|
| | | std::map<ggml_backend_t, std::unique_ptr<ggml_allocr, decltype(&ggml_allocr_free)>> backend_buffers; |
|---|
| | | for (auto backend : model.backends) { |
|---|
| | | // compute the size of the buffer |
|---|
| | | size_t size = 0; |
|---|
| | | for (auto it : model.tensors) { |
|---|
| | | if (tensor_backends[it.first] == backend) { |
|---|
| | | size += ggml_nbytes(it.second) + 512; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | if (size > 0) { |
|---|
| | | printf("%s: %8s buffer size = %8.2f MB\n", __func__, ggml_backend_name(backend), size/1024.0/1024.0); |
|---|
| | | // allocate the buffer |
|---|
| | | ggml_backend_buffer_t buffer = ggml_backend_alloc_buffer(backend, size); |
|---|
| | | model.buffers_w.push_back(buffer); |
|---|
| | | |
|---|
| | | // create an allocator for the buffer to allocate the tensors |
|---|
| | | auto alloc = std::unique_ptr<ggml_allocr, decltype(&ggml_allocr_free)>(ggml_allocr_new_from_buffer(buffer), ggml_allocr_free); |
|---|
| | | backend_buffers.insert(std::make_pair(backend, std::move(alloc))); |
|---|
| | | } else { |
|---|
| | | model.buffers_w.push_back(NULL); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // allocate key + value memory |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | |
|---|
| | | const int n_mem = n_layer*n_ctx; |
|---|
| | | const int n_elements = n_embd*n_mem; |
|---|
| | | |
|---|
| | | model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements); |
|---|
| | | model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_elements); |
|---|
| | | |
|---|
| | | ggml_set_name(model.memory_k, "model/memory_k"); |
|---|
| | | ggml_set_name(model.memory_v, "model/memory_v"); |
|---|
| | | |
|---|
| | | const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v); |
|---|
| | | |
|---|
| | | printf("%s: memory size = %8.2f MB, n_mem = %d\n", __func__, memory_size/1024.0/1024.0, n_mem); |
|---|
| | | |
|---|
| | | // create a backend buffer (can be in host or device memory) |
|---|
| | | ggml_backend_t backend_kv = params.n_gpu_layers >= hparams.n_layer/2 ? backend_gpu : backend_cpu; |
|---|
| | | printf("%s: backend_kv = %s\n", __func__, ggml_backend_name(backend_kv)); |
|---|
| | | model.buffer_kv = ggml_backend_alloc_buffer(backend_kv, memory_size + 512*2); |
|---|
| | | |
|---|
| | | // allocate the tensors into the backend buffer |
|---|
| | | { |
|---|
| | | ggml_allocr * alloc = ggml_allocr_new_from_buffer(model.buffer_kv); |
|---|
| | | |
|---|
| | | // this updates the pointers in the tensors to point to the correct location in the buffer |
|---|
| | | // this is necessary since the ggml_context is .no_alloc == true |
|---|
| | | // note that the buffer can actually be a device buffer, depending on the backend |
|---|
| | | ggml_allocr_alloc(alloc, model.memory_k); |
|---|
| | | ggml_allocr_alloc(alloc, model.memory_v); |
|---|
| | | |
|---|
| | | ggml_allocr_free(alloc); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load weights |
|---|
| | | { |
|---|
| | | size_t total_size = 0; |
|---|
| | | |
|---|
| | | bool has_lm_head = false; |
|---|
| | | |
|---|
| | | std::vector<char> read_buf; |
|---|
| | | |
|---|
| | | while (true) { |
|---|
| | | int32_t n_dims; |
|---|
| | | int32_t length; |
|---|
| | | int32_t ttype; |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&length), sizeof(length)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype)); |
|---|
| | | |
|---|
| | | if (fin.eof()) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int32_t nelements = 1; |
|---|
| | | int32_t ne[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i])); |
|---|
| | | nelements *= ne[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string name(length, 0); |
|---|
| | | fin.read(&name[0], length); |
|---|
| | | |
|---|
| | | if (model.tensors.find(name) == model.tensors.end()) { |
|---|
| | | fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto tensor = model.tensors[name]; |
|---|
| | | ggml_set_name(tensor, name.c_str()); |
|---|
| | | if (ggml_nelements(tensor) != nelements) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%d, %d], expected [%d, %d]\n", |
|---|
| | | __func__, name.c_str(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for debugging |
|---|
| | | if (0) { |
|---|
| | | printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.c_str(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const size_t bpe = ggml_type_size(ggml_type(ttype)); |
|---|
| | | |
|---|
| | | if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n", |
|---|
| | | __func__, name.c_str(), ggml_nbytes(tensor), nelements*bpe); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // allocate the tensor |
|---|
| | | ggml_backend_t backend = tensor_backends[name]; |
|---|
| | | ggml_allocr * alloc = backend_buffers.find(backend)->second.get(); |
|---|
| | | ggml_allocr_alloc(alloc, tensor); |
|---|
| | | //printf("%s: [%5.5s] %s\n", __func__, ggml_backend_name(backend), name.c_str()); |
|---|
| | | |
|---|
| | | if (ggml_backend_is_cpu(backend) |
|---|
| | | #ifdef GGML_USE_METAL |
|---|
| | | || ggml_backend_is_metal(backend) |
|---|
| | | #endif |
|---|
| | | ) { |
|---|
| | | // for the CPU and Metal backend, we can read directly into the tensor |
|---|
| | | fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor)); |
|---|
| | | } else { |
|---|
| | | // read into a temporary buffer first, then copy to device memory |
|---|
| | | read_buf.resize(ggml_nbytes(tensor)); |
|---|
| | | fin.read(read_buf.data(), ggml_nbytes(tensor)); |
|---|
| | | ggml_backend_tensor_set(tensor, read_buf.data(), 0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // GPT-2 models share the WTE tensor as the LM head |
|---|
| | | if (name == "model/wte" && has_lm_head == false) { |
|---|
| | | ggml_allocr_alloc(backend_buffers.find(tensor_backends["model/lm_head"])->second.get(), model.lm_head); |
|---|
| | | //printf("%s: [%5.5s] %s (copied)\n", __func__, ggml_backend_name(tensor_backends["model/lm_head"]), "model/lm_head"); |
|---|
| | | ggml_backend_tensor_copy(tensor, model.lm_head); |
|---|
| | | total_size += ggml_nbytes(model.lm_head); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (name == "model/lm_head") { |
|---|
| | | has_lm_head = true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | total_size += ggml_nbytes(tensor); |
|---|
| | | } |
|---|
| | | printf("%s: model size = %8.2f MB\n", __func__, total_size/1024.0/1024.0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.close(); |
|---|
| | | |
|---|
| | | // allocate input tensors |
|---|
| | | { |
|---|
| | | model.embd = ggml_new_tensor_1d(ctx, GGML_TYPE_I32, model.hparams.n_ctx); |
|---|
| | | model.position = ggml_new_tensor_1d(ctx, GGML_TYPE_I32, model.hparams.n_ctx); |
|---|
| | | |
|---|
| | | ggml_set_name(model.embd, "in/embd"); |
|---|
| | | ggml_set_name(model.position, "in/position"); |
|---|
| | | |
|---|
| | | // add input tensors to cpu backend |
|---|
| | | size_t input_size = ggml_nbytes(model.embd) + ggml_nbytes(model.position); |
|---|
| | | |
|---|
| | | // FIXME: use cpu backend after sched impl |
|---|
| | | ggml_backend_t backend_input = params.n_gpu_layers >= model.hparams.n_layer ? backend_gpu : backend_cpu; |
|---|
| | | model.buffer_input = ggml_backend_alloc_buffer(backend_input, input_size + 512*3); |
|---|
| | | printf("%s: backend_in = %s (%zu bytes)\n", __func__, ggml_backend_name(backend_input), input_size); |
|---|
| | | |
|---|
| | | // allocate the tensors into the backend buffer |
|---|
| | | ggml_allocr * alloc = ggml_allocr_new_from_buffer(model.buffer_input); |
|---|
| | | ggml_allocr_alloc(alloc, model.embd); |
|---|
| | | ggml_allocr_alloc(alloc, model.position); |
|---|
| | | ggml_allocr_free(alloc); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // build the computation graph |
|---|
| | | struct ggml_cgraph * gpt2_graph( |
|---|
| | | const gpt2_model & model, |
|---|
| | | const int n_past, |
|---|
| | | const std::vector<gpt_vocab::id> & embd_inp) { |
|---|
| | | const int N = embd_inp.size(); |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_head = hparams.n_head; |
|---|
| | | |
|---|
| | | // since we are using ggml-alloc, this buffer only needs enough space to hold the ggml_tensor and ggml_cgraph structs, but not the tensor data |
|---|
| | | static size_t buf_size = ggml_tensor_overhead()*GPT2_MAX_NODES + ggml_graph_overhead_custom(GPT2_MAX_NODES, false); |
|---|
| | | static std::vector<uint8_t> buf(buf_size); |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf.data(), |
|---|
| | | /*.no_alloc =*/ true, // the tensors will be allocated later by ggml_allocr_alloc_graph() |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx0 = ggml_init(params); |
|---|
| | | |
|---|
| | | struct ggml_cgraph * gf = ggml_new_graph_custom(ctx0, GPT2_MAX_NODES, false); |
|---|
| | | |
|---|
| | | struct ggml_tensor * embd = ggml_view_1d(ctx0, model.embd, N, 0); |
|---|
| | | |
|---|
| | | // TODO: avoid writing to tensors if we are only measuring the memory usage |
|---|
| | | // not critical, just a minor optimization |
|---|
| | | |
|---|
| | | //if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | //ggml_backend_tensor_set(embd, embd_inp.data(), 0, N*ggml_element_size(embd)); |
|---|
| | | ggml_backend_tensor_set(model.embd, embd_inp.data(), 0, N*ggml_element_size(embd)); // FIXME: cannot use the view here because it's not initialized yet (buffer not set), but we should |
|---|
| | | //} |
|---|
| | | //memcpy(embd->data, embd_inp.data(), N*ggml_element_size(embd)); |
|---|
| | | |
|---|
| | | struct ggml_tensor * position = ggml_view_1d(ctx0, model.position, N, 0); |
|---|
| | | //if (!ggml_allocr_is_measure(allocr)) { |
|---|
| | | for (int i = 0; i < N; ++i) { |
|---|
| | | int32_t v = n_past + i; |
|---|
| | | ggml_backend_tensor_set(model.position, &v, i*sizeof(int32_t), sizeof(v)); // FIXME: same |
|---|
| | | //((int32_t *) position->data)[i] = n_past + i; |
|---|
| | | } |
|---|
| | | //} |
|---|
| | | |
|---|
| | | const float KQ_scale = 1.0f/sqrtf(float(model.hparams.n_embd)/model.hparams.n_head); |
|---|
| | | |
|---|
| | | // wte + wpe |
|---|
| | | struct ggml_tensor * inpL = |
|---|
| | | ggml_add(ctx0, |
|---|
| | | ggml_get_rows(ctx0, model.wte, embd), |
|---|
| | | ggml_get_rows(ctx0, model.wpe, position)); |
|---|
| | | ggml_set_name(inpL, "inpL"); |
|---|
| | | ggml_set_name(inpL->src[0], "wte"); |
|---|
| | | ggml_set_name(inpL->src[1], "wpe"); |
|---|
| | | |
|---|
| | | for (int il = 0; il < n_layer; ++il) { |
|---|
| | | struct ggml_tensor * cur; |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | ggml_format_name(cur, "l%d.norm", il); |
|---|
| | | |
|---|
| | | // cur = ln_1_g*cur + ln_1_b |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].ln_1_g), |
|---|
| | | model.layers[il].ln_1_b); |
|---|
| | | ggml_format_name(cur, "l%d.ln_1_b", il); |
|---|
| | | ggml_format_name(cur->src[0], "l%d.ln_1_g", il); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // attn |
|---|
| | | // [2304, 768] - model.layers[il].c_attn_attn_w |
|---|
| | | // [2304, 1] - model.layers[il].c_attn_attn_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [2304, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = attn_w*cur + attn_b |
|---|
| | | // [2304, N] |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_attn_w, |
|---|
| | | cur); |
|---|
| | | ggml_format_name(cur, "l%d.attn_w", il); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_attn_attn_b); |
|---|
| | | ggml_format_name(cur, "l%d.attn_b", il); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // self-attention |
|---|
| | | { |
|---|
| | | struct ggml_tensor * Qcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 0*sizeof(float)*n_embd); |
|---|
| | | struct ggml_tensor * Kcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 1*sizeof(float)*n_embd); |
|---|
| | | struct ggml_tensor * Vcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 2*sizeof(float)*n_embd); |
|---|
| | | |
|---|
| | | ggml_format_name(Qcur, "l%d.Qcur", il); |
|---|
| | | ggml_format_name(Kcur, "l%d.Kcur", il); |
|---|
| | | ggml_format_name(Vcur, "l%d.Vcur", il); |
|---|
| | | |
|---|
| | | // store key and value to memory |
|---|
| | | if (N >= 1) { |
|---|
| | | struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past)); |
|---|
| | | struct ggml_tensor * v = ggml_view_1d(ctx0, model.memory_v, N*n_embd, (ggml_element_size(model.memory_v)*n_embd)*(il*n_ctx + n_past)); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3) |
|---|
| | | // [64, N, 12] |
|---|
| | | struct ggml_tensor * Q = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_cpy(ctx0, |
|---|
| | | Qcur, |
|---|
| | | ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_embd/n_head, n_head, N)), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | ggml_format_name(Q, "l%d.Q", il); |
|---|
| | | |
|---|
| | | // K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3) |
|---|
| | | // [64, n_past + N, 12] |
|---|
| | | struct ggml_tensor * K = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_past + N), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | ggml_format_name(K, "l%d.K", il); |
|---|
| | | |
|---|
| | | // GG: flash attention |
|---|
| | | //struct ggml_tensor * V = |
|---|
| | | // ggml_cpy(ctx0, |
|---|
| | | // ggml_permute(ctx0, |
|---|
| | | // ggml_reshape_3d(ctx0, |
|---|
| | | // ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd), |
|---|
| | | // n_embd/n_head, n_head, n_past + N), |
|---|
| | | // 1, 2, 0, 3), |
|---|
| | | // ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_past + N, n_embd/n_head, n_head)); |
|---|
| | | |
|---|
| | | //struct ggml_tensor * KQV = ggml_flash_attn(ctx0, Q, K, V, true); |
|---|
| | | |
|---|
| | | // K * Q |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); |
|---|
| | | ggml_format_name(KQ, "l%d.KQ", il); |
|---|
| | | |
|---|
| | | // KQ_scaled = KQ / sqrt(n_embd/n_head) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_scaled = ggml_scale(ctx0, KQ, KQ_scale); |
|---|
| | | ggml_format_name(KQ_scaled, "l%d.KQ_scaled", il); |
|---|
| | | |
|---|
| | | // KQ_masked = mask_past(KQ_scaled) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_masked = ggml_diag_mask_inf(ctx0, KQ_scaled, n_past); |
|---|
| | | ggml_format_name(KQ_masked, "l%d.KQ_masked", il); |
|---|
| | | |
|---|
| | | // KQ = soft_max(KQ_masked) |
|---|
| | | // [n_past + N, N, 12] |
|---|
| | | struct ggml_tensor * KQ_soft_max = ggml_soft_max(ctx0, KQ_masked); |
|---|
| | | ggml_format_name(KQ_soft_max, "l%d.KQ_soft_max", il); |
|---|
| | | |
|---|
| | | // V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous() |
|---|
| | | // [n_past + N, 64, 12] |
|---|
| | | struct ggml_tensor * V_trans = |
|---|
| | | ggml_cpy(ctx0, |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_past + N), |
|---|
| | | 1, 2, 0, 3), |
|---|
| | | ggml_new_tensor_3d(ctx0, model.memory_v->type, n_past + N, n_embd/n_head, n_head)); |
|---|
| | | ggml_format_name(V_trans, "l%d.V_trans", il); |
|---|
| | | |
|---|
| | | // KQV = transpose(V) * KQ_soft_max |
|---|
| | | // [64, N, 12] |
|---|
| | | struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V_trans, KQ_soft_max); |
|---|
| | | ggml_format_name(KQV, "l%d.KQV", il); |
|---|
| | | |
|---|
| | | // KQV_merged = KQV.permute(0, 2, 1, 3) |
|---|
| | | // [64, 12, N] |
|---|
| | | struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); |
|---|
| | | ggml_format_name(KQV_merged, "l%d.KQV_merged", il); |
|---|
| | | |
|---|
| | | // cur = KQV_merged.contiguous().view(n_embd, N) |
|---|
| | | // [768, N] |
|---|
| | | cur = ggml_cpy(ctx0, |
|---|
| | | KQV_merged, |
|---|
| | | ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N)); |
|---|
| | | ggml_format_name(cur, "l%d.KQV_merged_contiguous", il); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // [ 768, 768] - model.layers[il].c_attn_proj_w |
|---|
| | | // [ 768, 1] - model.layers[il].c_attn_proj_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [ 768, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | // [768, N] |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_proj_w, |
|---|
| | | cur); |
|---|
| | | ggml_format_name(cur, "l%d.attn_proj_w", il); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_attn_proj_b); |
|---|
| | | ggml_format_name(cur, "l%d.attn_proj_b", il); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add the input |
|---|
| | | cur = ggml_add(ctx0, cur, inpL); |
|---|
| | | ggml_format_name(cur, "l%d.add", il); |
|---|
| | | |
|---|
| | | struct ggml_tensor * inpFF = cur; |
|---|
| | | |
|---|
| | | // feed-forward network |
|---|
| | | { |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | cur = ggml_norm(ctx0, inpFF, hparams.eps); |
|---|
| | | ggml_format_name(cur, "l%d.FFnorm", il); |
|---|
| | | |
|---|
| | | // cur = ln_2_g*cur + ln_2_b |
|---|
| | | // [ 768, N] |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].ln_2_g), |
|---|
| | | model.layers[il].ln_2_b); |
|---|
| | | ggml_format_name(cur, "l%d.ln_2_b", il); |
|---|
| | | ggml_format_name(cur->src[0], "l%d.ln_2_g", il); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // fully connected |
|---|
| | | // [3072, 768] - model.layers[il].c_mlp_fc_w |
|---|
| | | // [3072, 1] - model.layers[il].c_mlp_fc_b |
|---|
| | | // [ 768, N] - cur (in) |
|---|
| | | // [3072, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = fc_w*cur + fc_b |
|---|
| | | // [3072, N] |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_fc_w, |
|---|
| | | cur); |
|---|
| | | ggml_format_name(cur, "l%d.mlp_fc_w", il); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_mlp_fc_b); |
|---|
| | | ggml_format_name(cur, "l%d.mlp_fc_b", il); |
|---|
| | | |
|---|
| | | // GELU activation |
|---|
| | | // [3072, N] |
|---|
| | | cur = ggml_gelu(ctx0, cur); |
|---|
| | | ggml_format_name(cur, "l%d.gelu", il); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // [ 768, 3072] - model.layers[il].c_mlp_proj_w |
|---|
| | | // [ 768, 1] - model.layers[il].c_mlp_proj_b |
|---|
| | | // [3072, N] - cur (in) |
|---|
| | | // [ 768, N] - cur (out) |
|---|
| | | // |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | // [768, N] |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_proj_w, |
|---|
| | | cur); |
|---|
| | | ggml_format_name(cur, "l%d.mlp_proj_w", il); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | cur, |
|---|
| | | model.layers[il].c_mlp_proj_b); |
|---|
| | | ggml_format_name(cur, "l%d.mlp_proj_b", il); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // input for next layer |
|---|
| | | inpL = ggml_add(ctx0, cur, inpFF); |
|---|
| | | ggml_format_name(inpL, "l%d.add2", il); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | // [ 768, N] |
|---|
| | | inpL = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | ggml_format_name(inpL, "out_norm"); |
|---|
| | | |
|---|
| | | // inpL = ln_f_g*inpL + ln_f_b |
|---|
| | | // [ 768, N] |
|---|
| | | inpL = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | inpL, |
|---|
| | | model.ln_f_g), |
|---|
| | | model.ln_f_b); |
|---|
| | | ggml_format_name(inpL, "out_ln_f_b"); |
|---|
| | | ggml_format_name(inpL->src[0], "out_ln_f_g"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // inpL = WTE * inpL |
|---|
| | | // [ 768, 50257] - model.lm_head |
|---|
| | | // [ 768, N] - inpL |
|---|
| | | inpL = ggml_mul_mat(ctx0, model.lm_head, inpL); |
|---|
| | | ggml_format_name(inpL, "out_lm_head"); |
|---|
| | | |
|---|
| | | // logits -> probs |
|---|
| | | //inpL = ggml_soft_max(ctx0, inpL); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, inpL); |
|---|
| | | |
|---|
| | | ggml_free(ctx0); |
|---|
| | | |
|---|
| | | return gf; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // evaluate the transformer |
|---|
| | | // |
|---|
| | | // - model: the model |
|---|
| | | // - allocr: ggml_allocr to use to allocate the compute buffer |
|---|
| | | // - n_threads: number of threads to use |
|---|
| | | // - n_past: the context size so far |
|---|
| | | // - embd_inp: the embeddings of the tokens in the context |
|---|
| | | // - embd_w: the predicted logits for the next token |
|---|
| | | // |
|---|
| | | bool gpt2_eval( |
|---|
| | | const gpt2_model & model, |
|---|
| | | ggml_backend_sched_t sched, |
|---|
| | | const int n_past, |
|---|
| | | const std::vector<gpt_vocab::id> & embd_inp, |
|---|
| | | std::vector<float> & embd_w) { |
|---|
| | | const int N = embd_inp.size(); |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | struct ggml_cgraph * gf = gpt2_graph(model, n_past, embd_inp); |
|---|
| | | |
|---|
| | | // run the computation |
|---|
| | | ggml_backend_sched_graph_compute(sched, gf); |
|---|
| | | |
|---|
| | | //if (n_past%100 == 0) { |
|---|
| | | // ggml_graph_print (&gf); |
|---|
| | | // ggml_graph_dump_dot(&gf, NULL, "gpt-2.dot"); |
|---|
| | | //} |
|---|
| | | |
|---|
| | | // in this case, the output tensor is the last one in the graph |
|---|
| | | struct ggml_tensor * inpL = gf->nodes[gf->n_nodes - 1]; |
|---|
| | | |
|---|
| | | //embd_w.resize(n_vocab*N); |
|---|
| | | //ggml_backend_tensor_get(inpL, embd_w.data(), 0, sizeof(float)*n_vocab*N); |
|---|
| | | |
|---|
| | | // return result just for the last token |
|---|
| | | embd_w.resize(n_vocab); |
|---|
| | | ggml_backend_tensor_get(inpL, embd_w.data(), (n_vocab*(N-1))*sizeof(float), sizeof(float)*n_vocab); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | gpt_params params; |
|---|
| | | params.model = "models/gpt-2-117M/ggml-model.bin"; |
|---|
| | | |
|---|
| | | if (gpt_params_parse(argc, argv, params) == false) { |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.seed < 0) { |
|---|
| | | params.seed = time(NULL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: seed = %d\n", __func__, params.seed); |
|---|
| | | |
|---|
| | | std::mt19937 rng(params.seed); |
|---|
| | | if (params.prompt.empty()) { |
|---|
| | | params.prompt = gpt_random_prompt(rng); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int64_t t_load_us = 0; |
|---|
| | | |
|---|
| | | gpt_vocab vocab; |
|---|
| | | gpt2_model model; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt2_model_load(params.model, model, vocab, params)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | test_gpt_tokenizer(vocab, params.token_test); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // create the backend scheduler |
|---|
| | | // the scheduler handles the allocation of the compute buffers and the scheduling of the computation between the different backends |
|---|
| | | ggml_backend_sched_t sched; |
|---|
| | | { |
|---|
| | | // initialize the scheduler |
|---|
| | | sched = ggml_backend_sched_new(model.backends.data(), NULL, model.backends.size(), GPT2_MAX_NODES); |
|---|
| | | |
|---|
| | | // create the worst case graph for memory usage estimation |
|---|
| | | int n_tokens = std::min(model.hparams.n_ctx, params.n_batch); |
|---|
| | | int n_past = model.hparams.n_ctx - n_tokens; |
|---|
| | | struct ggml_cgraph * gf = gpt2_graph(model, n_past, std::vector<gpt_vocab::id>(n_tokens, 0)); |
|---|
| | | |
|---|
| | | ggml_backend_sched_init_measure(sched, gf); |
|---|
| | | |
|---|
| | | |
|---|
| | | // compute the required memory |
|---|
| | | size_t mem_size = 0; |
|---|
| | | for (size_t i = 0; i < model.backends.size(); i++) { |
|---|
| | | ggml_backend_buffer_t buf = ggml_backend_sched_get_buffer(sched, model.backends[i]); |
|---|
| | | size_t size = ggml_backend_buffer_get_size(buf); |
|---|
| | | if (size > 0) { |
|---|
| | | mem_size += size; |
|---|
| | | printf("%s: %8s compute buffer size = %8.2f MB\n", __func__, ggml_backend_name(model.backends[i]), size/1024.0/1024.0); |
|---|
| | | //printf("%s: %8s compute buffer size = %zu bytes\n", __func__, ggml_backend_name(model.backends[i]), size); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: total compute buffer size: %.2f MB\n", __func__, mem_size/1024.0/1024.0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int n_past = 0; |
|---|
| | | |
|---|
| | | int64_t t_sample_us = 0; |
|---|
| | | int64_t t_predict_us = 0; |
|---|
| | | |
|---|
| | | std::vector<float> logits; |
|---|
| | | |
|---|
| | | // tokenize the prompt |
|---|
| | | std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, params.prompt); |
|---|
| | | |
|---|
| | | params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size()); |
|---|
| | | |
|---|
| | | printf("%s: prompt: '%s'\n", __func__, params.prompt.c_str()); |
|---|
| | | printf("%s: number of tokens in prompt = %zu, first 8 tokens: ", __func__, embd_inp.size()); |
|---|
| | | for (int i = 0; i < std::min(8, (int) embd_inp.size()); i++) { |
|---|
| | | printf("%d ", embd_inp[i]); |
|---|
| | | } |
|---|
| | | printf("\n\n"); |
|---|
| | | |
|---|
| | | // submit the input prompt token-by-token |
|---|
| | | // this reduces the memory usage during inference, at the cost of a bit of speed at the beginning |
|---|
| | | std::vector<gpt_vocab::id> embd; |
|---|
| | | |
|---|
| | | for (size_t i = embd.size(); i < embd_inp.size() + params.n_predict; i++) { |
|---|
| | | // predict |
|---|
| | | if (embd.size() > 0) { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt2_eval(model, sched, n_past, embd, logits)) { |
|---|
| | | printf("Failed to predict\n"); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_predict_us += ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | n_past += embd.size(); |
|---|
| | | embd.clear(); |
|---|
| | | |
|---|
| | | if (i >= embd_inp.size()) { |
|---|
| | | // sample next token |
|---|
| | | const int top_k = params.top_k; |
|---|
| | | const float top_p = params.top_p; |
|---|
| | | const float temp = params.temp; |
|---|
| | | |
|---|
| | | const int n_vocab = model.hparams.n_vocab; |
|---|
| | | |
|---|
| | | gpt_vocab::id id = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const int64_t t_start_sample_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng); |
|---|
| | | |
|---|
| | | t_sample_us += ggml_time_us() - t_start_sample_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add it to the context |
|---|
| | | embd.push_back(id); |
|---|
| | | } else { |
|---|
| | | // if here, it means we are still processing the input prompt |
|---|
| | | for (size_t k = i; k < embd_inp.size(); k++) { |
|---|
| | | embd.push_back(embd_inp[k]); |
|---|
| | | if (int32_t(embd.size()) >= params.n_batch) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | i += embd.size() - 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // display text |
|---|
| | | for (auto id : embd) { |
|---|
| | | printf("%s", vocab.id_to_token[id].c_str()); |
|---|
| | | } |
|---|
| | | fflush(stdout); |
|---|
| | | |
|---|
| | | // end of text token |
|---|
| | | if (embd.back() == 50256) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n\n"); |
|---|
| | | printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f); |
|---|
| | | printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f); |
|---|
| | | printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us/1000.0f, t_predict_us/1000.0f/n_past); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | ggml_backend_sched_free(sched); |
|---|
| | | ggml_backend_buffer_free(model.buffer_kv); |
|---|
| | | for (auto & buf : model.buffers_w) { |
|---|
| | | ggml_backend_buffer_free(buf); |
|---|
| | | } |
|---|
| | | for (auto backend : model.backends) { |
|---|
| | | ggml_backend_free(backend); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | #include <regex> |
|---|
| | | |
|---|
| | | // default hparams (GPT-2 117M) |
|---|
| | | struct gpt2_hparams { |
|---|
| | | int32_t n_vocab = 50257; |
|---|
| | | int32_t n_ctx = 1024; |
|---|
| | | int32_t n_embd = 768; |
|---|
| | | int32_t n_head = 12; |
|---|
| | | int32_t n_layer = 12; |
|---|
| | | int32_t ftype = 1; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // quantize a model |
|---|
| | | bool gpt2_model_quantize(const std::string & fname_inp, const std::string & fname_out, ggml_ftype ftype) { |
|---|
| | | gpt_vocab vocab; |
|---|
| | | |
|---|
| | | printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | |
|---|
| | | auto finp = std::ifstream(fname_inp, std::ios::binary); |
|---|
| | | if (!finp) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto fout = std::ofstream(fname_out, std::ios::binary); |
|---|
| | | if (!fout) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname_out.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | finp.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | fout.write((char *) &magic, sizeof(magic)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | gpt2_hparams hparams; |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | finp.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | finp.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | finp.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | finp.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | finp.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: ftype (src) = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr (src) = %d\n", __func__, qntvr_src); |
|---|
| | | printf("%s: ftype (dst) = %d\n", __func__, ftype_dst); |
|---|
| | | printf("%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION); |
|---|
| | | |
|---|
| | | fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fout.write((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fout.write((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fout.write((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fout.write((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fout.write((char *) &ftype_dst, sizeof(ftype_dst)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | int32_t n_vocab = 0; |
|---|
| | | finp.read ((char *) &n_vocab, sizeof(n_vocab)); |
|---|
| | | fout.write((char *) &n_vocab, sizeof(n_vocab)); |
|---|
| | | |
|---|
| | | if (n_vocab != hparams.n_vocab) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n", |
|---|
| | | __func__, fname_inp.c_str(), n_vocab, hparams.n_vocab); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | finp.read ((char *) &len, sizeof(len)); |
|---|
| | | fout.write((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | word.resize(len); |
|---|
| | | finp.read ((char *) word.data(), len); |
|---|
| | | fout.write((char *) word.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // regexes of tensor names to be quantized |
|---|
| | | const std::vector<std::string> to_quant = { |
|---|
| | | "model/wte", |
|---|
| | | "model/lm_head", |
|---|
| | | "model/h.*/attn/c_attn/w", |
|---|
| | | "model/h.*/attn/c_proj/w", |
|---|
| | | "model/h.*/mlp/c_fc/w", |
|---|
| | | "model/h.*/mlp/c_proj/w", |
|---|
| | | }; |
|---|
| | | |
|---|
| | | if (!ggml_common_quantize_0(finp, fout, ftype, to_quant, {})) { |
|---|
| | | fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | finp.close(); |
|---|
| | | fout.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // usage: |
|---|
| | | // ./gpt-2-quantize models/gpt-2-117M/ggml-model.bin models/gpt-2-117M/ggml-model-quant.bin type |
|---|
| | | // |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | if (argc != 4) { |
|---|
| | | fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n", argv[0]); |
|---|
| | | ggml_print_ftypes(stderr); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // needed to initialize f16 tables |
|---|
| | | { |
|---|
| | | struct ggml_init_params params = { 0, NULL, false }; |
|---|
| | | struct ggml_context * ctx = ggml_init(params); |
|---|
| | | ggml_free(ctx); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const std::string fname_inp = argv[1]; |
|---|
| | | const std::string fname_out = argv[2]; |
|---|
| | | |
|---|
| | | const ggml_ftype ftype = ggml_parse_ftype(argv[3]); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | int64_t t_quantize_us = 0; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt2_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) { |
|---|
| | | fprintf(stderr, "%s: failed to quantize model from '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_quantize_us = ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n"); |
|---|
| | | printf("%s: quantize time = %8.2f ms\n", __func__, t_quantize_us/1000.0f); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | # |
|---|
| | | # gpt-j |
|---|
| | | |
|---|
| | | set(TEST_TARGET gpt-j) |
|---|
| | | add_executable(${TEST_TARGET} main.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| | | |
|---|
| | | # |
|---|
| | | # gpt-j-quantize |
|---|
| | | |
|---|
| | | set(TEST_TARGET gpt-j-quantize) |
|---|
| | | add_executable(${TEST_TARGET} quantize.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| New file |
| | |
|---|
| | | # gpt-j |
|---|
| | | |
|---|
| | | Local GPT-J inference on your computer using C/C++ |
|---|
| | | |
|---|
| | | No video card required. You just need to have 16 GB of RAM. |
|---|
| | | |
|---|
| | | ## Motivation |
|---|
| | | |
|---|
| | | The GPT-J 6B model is the open-source alternative to OpenAI's GPT-3. It's basically a neural network that allows you to |
|---|
| | | generate coherent, human-like text given a certain context (prompt). |
|---|
| | | |
|---|
| | | The GPT-J model is quite big - the compact version of the model uses 16-bit floating point representation of the weights |
|---|
| | | and is still 12 GB big. This means that in order to run inference on your computer, you would need to have a video card |
|---|
| | | with at least 12 GB of video RAM. Alternatively, you can try to run the python implementations on the CPU, but that |
|---|
| | | would probably not be very efficient as they are primarily optimized for running on a GPU (or at least this is my guess - |
|---|
| | | I don't have much experience with python). |
|---|
| | | |
|---|
| | | I wanted to try and run the model on my MacBook, so I decided to implement the model inference from scratch using my own |
|---|
| | | custom build tensor library. The tensor library (called [ggml](https://github.com/ggerganov/ggml), written in C) is in |
|---|
| | | early development stage, but it already allows me to run the GPT-J model. |
|---|
| | | |
|---|
| | | On my 32GB MacBook M1 Pro, I achieve an inference speed of about `125 ms/token` or about ~6 words per second (1 word |
|---|
| | | typically consists of 1 or 2 tokens). |
|---|
| | | |
|---|
| | | Here is a sample run with prompt `int main(int argc, char ** argv) {`: |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | $ time ./bin/gpt-j -p "int main(int argc, char ** argv) {" |
|---|
| | | |
|---|
| | | gptj_model_load: loading model from 'models/gpt-j-6B/ggml-model.bin' - please wait ... |
|---|
| | | gptj_model_load: n_vocab = 50400 |
|---|
| | | gptj_model_load: n_ctx = 2048 |
|---|
| | | gptj_model_load: n_embd = 4096 |
|---|
| | | gptj_model_load: n_head = 16 |
|---|
| | | gptj_model_load: n_layer = 28 |
|---|
| | | gptj_model_load: n_rot = 64 |
|---|
| | | gptj_model_load: f16 = 1 |
|---|
| | | gptj_model_load: ggml ctx size = 13334.86 MB |
|---|
| | | gptj_model_load: memory_size = 1792.00 MB, n_mem = 57344 |
|---|
| | | gptj_model_load: ................................... done |
|---|
| | | gptj_model_load: model size = 11542.79 MB / num tensors = 285 |
|---|
| | | main: number of tokens in prompt = 13 |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | (void)argc; |
|---|
| | | (void)argv; |
|---|
| | | |
|---|
| | | { |
|---|
| | | struct sockaddr_in addr; |
|---|
| | | int addrlen; |
|---|
| | | char * ip = "192.168.1.4"; |
|---|
| | | int i; |
|---|
| | | |
|---|
| | | if ( (addrlen = sizeof(addr)) == -1 ) |
|---|
| | | return -1; |
|---|
| | | |
|---|
| | | for (i = 0; i < 10; ++i) { |
|---|
| | | addr.sin_family = AF_INET; |
|---|
| | | addr.sin_addr.s_addr = inet_addr(ip); |
|---|
| | | |
|---|
| | | main: mem per token = 16430420 bytes |
|---|
| | | main: load time = 6211.48 ms |
|---|
| | | main: sample time = 13.74 ms |
|---|
| | | main: predict time = 26420.34 ms / 124.62 ms per token |
|---|
| | | main: total time = 33035.37 ms |
|---|
| | | |
|---|
| | | real 0m33.171s |
|---|
| | | user 3m32.269s |
|---|
| | | sys 0m3.686s |
|---|
| | | |
|---|
| | | $ |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | It took ~6.2 seconds to load the model to memory. After that, it took ~26.4 seconds to generate 200 tokens of what |
|---|
| | | looks like to be the beginning of a networking program in C. Pretty cool! |
|---|
| | | |
|---|
| | | Here is another run, just for fun: |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | time ./bin/gpt-j -n 500 -t 8 -p "Ask HN: Inherited the worst code and tech team I have ever seen. How to fix it? |
|---|
| | | " |
|---|
| | | |
|---|
| | | gptj_model_load: loading model from 'models/gpt-j-6B/ggml-model.bin' - please wait ... |
|---|
| | | gptj_model_load: n_vocab = 50400 |
|---|
| | | gptj_model_load: n_ctx = 2048 |
|---|
| | | gptj_model_load: n_embd = 4096 |
|---|
| | | gptj_model_load: n_head = 16 |
|---|
| | | gptj_model_load: n_layer = 28 |
|---|
| | | gptj_model_load: n_rot = 64 |
|---|
| | | gptj_model_load: f16 = 1 |
|---|
| | | gptj_model_load: ggml ctx size = 13334.86 MB |
|---|
| | | gptj_model_load: memory_size = 1792.00 MB, n_mem = 57344 |
|---|
| | | gptj_model_load: ................................... done |
|---|
| | | gptj_model_load: model size = 11542.79 MB / num tensors = 285 |
|---|
| | | main: number of tokens in prompt = 24 |
|---|
| | | |
|---|
| | | Ask HN: Inherited the worst code and tech team I have ever seen. How to fix it? |
|---|
| | | |
|---|
| | | I've inherited a team with some very strange and un-documented practices, one of them is that they use an old custom |
|---|
| | | application with a very slow tech stack written in Python that the team doesn't want to touch but also doesn't want to |
|---|
| | | throw away as it has some "legacy" code in it. |
|---|
| | | |
|---|
| | | The problem is, the tech stack is very very slow. |
|---|
| | | |
|---|
| | | They have a single web server on a VM that is slow. |
|---|
| | | The server is a little bit busy (not very busy though) and they have a lot of processes (30+ that are constantly being |
|---|
| | | spawned by the application) |
|---|
| | | They have an application that is single threaded and was written in Python and the team don't want to touch this, and |
|---|
| | | the application is very slow. |
|---|
| | | |
|---|
| | | My task as a new member of the team is to fix this. |
|---|
| | | |
|---|
| | | I'm a senior dev on the team (3 years on the project) and have been told that I will take the lead on this task. I know |
|---|
| | | next to nothing about Python. So here is what I have so far. |
|---|
| | | |
|---|
| | | What I have done is I've been trying to debug the processes with the "ps" command. This way I can see what is running |
|---|
| | | and where. From what I see, the application spawns 10 processes a minute and some of them are used for nothing. |
|---|
| | | |
|---|
| | | I have also started to look for the code. The application source is not in GitHub or any other repository, it is only on |
|---|
| | | our internal GitLab. |
|---|
| | | |
|---|
| | | What I've found so far: |
|---|
| | | |
|---|
| | | The application uses a custom SQLAlchemy implementation to interact with the data. I've looked at the source, it looks |
|---|
| | | like an object cache or something like that. But from what I've seen, the cache gets full every 20 minutes and then gets |
|---|
| | | cleared with a special command. |
|---|
| | | |
|---|
| | | Another strange thing is that the application creates a file for every entry in the database (even if the entry already |
|---|
| | | exists). I've looked at the file to see if it contains something, but it seems to be a JSON file with lots of records. |
|---|
| | | |
|---|
| | | The other strange thing is that I can only find the database tables in the GitLab repository and not the code. So I |
|---|
| | | can't really understand how the application is supposed to interact with the database. |
|---|
| | | |
|---|
| | | I also found a "log" directory, but the code is encrypted with AES. From what I've found, it is in |
|---|
| | | |
|---|
| | | main: mem per token = 16430420 bytes |
|---|
| | | main: load time = 3900.10 ms |
|---|
| | | main: sample time = 32.58 ms |
|---|
| | | main: predict time = 68049.91 ms / 130.11 ms per token |
|---|
| | | main: total time = 73020.05 ms |
|---|
| | | |
|---|
| | | real 1m13.156s |
|---|
| | | user 9m1.328s |
|---|
| | | sys. 0m7.103s |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Implementation details |
|---|
| | | |
|---|
| | | The high level implementation of the model is contained in the [main.cpp](main.cpp) file. The core computations are |
|---|
| | | performed by the [ggml](https://github.com/ggerganov/ggml/blob/master/include/ggml/ggml.h) library. |
|---|
| | | |
|---|
| | | |
|---|
| | | #### Matrix multiplication |
|---|
| | | |
|---|
| | | The most performance critical part of the implementation is of course the matrix multiplication routine. 99% of the time |
|---|
| | | is spent here, so it was important to optimize this as much as possible. |
|---|
| | | |
|---|
| | | On Arm64, I utilize the 128-bit NEON intrinsics for 16-bit floating point operations: |
|---|
| | | |
|---|
| | | https://github.com/ggerganov/ggml/blob/fb558f78d905f85c54813602649ddd628ffe0f3a/src/ggml.c#L187-L243 |
|---|
| | | |
|---|
| | | These instructions allow each core to operate simultaneously on 64 16-bit floats. I'm no expert in SIMD, but after quite |
|---|
| | | some trials this was the most efficient code for dot product of a row and column that I could come up with. Combined |
|---|
| | | with the parallel computation on 8 CPU threads, I believe I'm close to the maximum performance that one could possibly |
|---|
| | | get on the M1 CPU. Still, I'm curious to know if there is a more efficient way to implement this. |
|---|
| | | |
|---|
| | | |
|---|
| | | #### Attempt to use the M1 GPU |
|---|
| | | |
|---|
| | | One interesting property of the GPT-J transformer architecture is that it allows you to perform part of the inference in |
|---|
| | | parallel - i.e. the Feed-forward network can be computed in parallel to the Self-attention layer: |
|---|
| | | |
|---|
| | | https://github.com/ggerganov/ggml/blob/fb558f78d905f85c54813602649ddd628ffe0f3a/examples/gpt-j/main.cpp#L507-L531 |
|---|
| | | |
|---|
| | | So I thought why not try and bring in the M1 GPU to compute half of the neural network in parallel to the CPU and |
|---|
| | | potentially gain some extra performance. Thanks to the M1's shared memory model, it was relatively easy to offload part |
|---|
| | | of the computation to the GPU using Apple's [Metal Performance |
|---|
| | | Shaders](https://developer.apple.com/documentation/metalperformanceshaders). The GPU shares the host memory, so there is |
|---|
| | | no need to copy the data back and forth as you would normally do with Cuda or OpenCL. The weight matrices are directly |
|---|
| | | available to be used by the GPU. |
|---|
| | | |
|---|
| | | However, to my surprise, using MPS together with the CPU did not lead to any performance improvement at all. My |
|---|
| | | conclusion was that the 8-thread NEON CPU computation is already saturating the memory bandwidth of the M1 and since |
|---|
| | | the CPU and the GPU on the MacBook are sharing that bandwidth, it does not help to offload the computation to the GPU. |
|---|
| | | Another observation was that the MPS GPU matrix multiplication using 16-bit floats had the same performance as the |
|---|
| | | 8-thread NEON CPU implementation. Again, I explain this with a saturated memory channel. But of course, my explanation |
|---|
| | | could be totally wrong and somehow the implementation wasn't utilizing the resources correctly. |
|---|
| | | |
|---|
| | | In the end, I decided to not use MPS or the GPU all together. |
|---|
| | | |
|---|
| | | ### Zero memory allocations |
|---|
| | | |
|---|
| | | Another property of my implementation is that it does not perform any memory allocations once the model is loaded into |
|---|
| | | memory. All required memory is allocated at the start of the program with a single `malloc` (technically 2 calls, but |
|---|
| | | that is not important). |
|---|
| | | |
|---|
| | | ## Usage |
|---|
| | | |
|---|
| | | If you want to give this a try and you are on Linux or Mac OS, simply follow these instructions: |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | # Clone the ggml library and build the gpt-j example |
|---|
| | | git clone https://github.com/ggerganov/ggml |
|---|
| | | cd ggml |
|---|
| | | mkdir build && cd build |
|---|
| | | cmake .. |
|---|
| | | make -j4 gpt-j |
|---|
| | | |
|---|
| | | # Download the ggml-compatible GPT-J 6B model (requires 12GB disk space) |
|---|
| | | ../examples/gpt-j/download-ggml-model.sh 6B |
|---|
| | | |
|---|
| | | # Run the inference (requires 16GB of CPU RAM) |
|---|
| | | ./bin/gpt-j -m models/gpt-j-6B/ggml-model.bin -p "This is an example" |
|---|
| | | |
|---|
| | | # Input prompt through pipe and run the inference. |
|---|
| | | echo "This is an example" > prompt.txt |
|---|
| | | cat prompt.txt | ./bin/gpt-j -m models/gpt-j-6B/ggml-model.bin |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | To run the `gpt-j` tool, you need the 12GB `ggml-model.bin` file which contains the GPT-J model in |
|---|
| | | [ggml](https://github.com/ggerganov/ggml) compatible format. In the instructions above, the binary file |
|---|
| | | is downloaded from my repository on Hugging Face using the [download-ggml-model.sh](download-ggml-model.sh) script. |
|---|
| | | You can also, download the file manually from this link: |
|---|
| | | |
|---|
| | | https://huggingface.co/ggerganov/ggml/tree/main |
|---|
| | | |
|---|
| | | --- |
|---|
| | | |
|---|
| | | Alternatively, if you don't want to download the 12GB ggml model file, you can perform the conversion yourself using |
|---|
| | | python. |
|---|
| | | |
|---|
| | | First, you need to download the full GPT-J model from here: https://huggingface.co/EleutherAI/gpt-j-6B |
|---|
| | | |
|---|
| | | Note that the full model is quite big - about 72 GB. After you download it, you need to convert it to ggml format using |
|---|
| | | the [convert-h5-to-ggml.py](convert-h5-to-ggml.py) script. This will generate the `ggml-model.bin` file, which you can |
|---|
| | | then use with the `gpt-j` program. |
|---|
| | | |
|---|
| | | |
|---|
| | | ## GPT-2 |
|---|
| | | |
|---|
| | | I also implemented a tool for CPU inference using the smaller GPT-2 models. They have worse quality compared to GPT-J, |
|---|
| | | but are much faster to execute. |
|---|
| | | |
|---|
| | | For example, the Small GPT-2 model is only 240 MB big and the inference speed on my MacBook is about 200 tokens/sec. |
|---|
| | | |
|---|
| | | For more details, checkout the GPT-2 example here: [gpt-2](https://github.com/ggerganov/ggml/tree/master/examples/gpt-2) |
|---|
| New file |
| | |
|---|
| | | # Convert GPT-J-6B h5 transformer model to ggml format |
|---|
| | | # |
|---|
| | | # Load the model using GPTJForCausalLM. |
|---|
| | | # Iterate over all variables and write them to a binary file. |
|---|
| | | # |
|---|
| | | # For each variable, write the following: |
|---|
| | | # - Number of dimensions (int) |
|---|
| | | # - Name length (int) |
|---|
| | | # - Dimensions (int[n_dims]) |
|---|
| | | # - Name (char[name_length]) |
|---|
| | | # - Data (float[n_dims]) |
|---|
| | | # |
|---|
| | | # By default, the bigger matrices are converted to 16-bit floats. |
|---|
| | | # This can be disabled by adding the "use-f32" CLI argument. |
|---|
| | | # |
|---|
| | | # At the start of the ggml file we write the model parameters |
|---|
| | | # and vocabulary. |
|---|
| | | # |
|---|
| | | |
|---|
| | | import sys |
|---|
| | | import struct |
|---|
| | | import json |
|---|
| | | import torch |
|---|
| | | import numpy as np |
|---|
| | | |
|---|
| | | from transformers import GPTJForCausalLM |
|---|
| | | |
|---|
| | | # ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py |
|---|
| | | def bytes_to_unicode(): |
|---|
| | | """ |
|---|
| | | Returns list of utf-8 byte and a corresponding list of unicode strings. |
|---|
| | | The reversible bpe codes work on unicode strings. |
|---|
| | | This means you need a large # of unicode characters in your vocab if you want to avoid UNKs. |
|---|
| | | When you're at something like a 10B token dataset you end up needing around 5K for decent coverage. |
|---|
| | | This is a signficant percentage of your normal, say, 32K bpe vocab. |
|---|
| | | To avoid that, we want lookup tables between utf-8 bytes and unicode strings. |
|---|
| | | And avoids mapping to whitespace/control characters the bpe code barfs on. |
|---|
| | | """ |
|---|
| | | bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1)) |
|---|
| | | cs = bs[:] |
|---|
| | | n = 0 |
|---|
| | | for b in range(2**8): |
|---|
| | | if b not in bs: |
|---|
| | | bs.append(b) |
|---|
| | | cs.append(2**8+n) |
|---|
| | | n += 1 |
|---|
| | | cs = [chr(n) for n in cs] |
|---|
| | | return dict(zip(bs, cs)) |
|---|
| | | |
|---|
| | | if len(sys.argv) < 3: |
|---|
| | | print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n") |
|---|
| | | print(" ftype == 0 -> float32") |
|---|
| | | print(" ftype == 1 -> float16") |
|---|
| | | sys.exit(1) |
|---|
| | | |
|---|
| | | # output in the same directory as the model |
|---|
| | | dir_model = sys.argv[1] |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model.bin" |
|---|
| | | |
|---|
| | | with open(dir_model + "/vocab.json", "r", encoding="utf-8") as f: |
|---|
| | | encoder = json.load(f) |
|---|
| | | |
|---|
| | | with open(dir_model + "/added_tokens.json", "r", encoding="utf-8") as f: |
|---|
| | | encoder_added = json.load(f) |
|---|
| | | |
|---|
| | | with open(dir_model + "/config.json", "r", encoding="utf-8") as f: |
|---|
| | | hparams = json.load(f) |
|---|
| | | |
|---|
| | | # possible data types |
|---|
| | | # ftype == 0 -> float32 |
|---|
| | | # ftype == 1 -> float16 |
|---|
| | | # |
|---|
| | | # map from ftype to string |
|---|
| | | ftype_str = ["f32", "f16"] |
|---|
| | | |
|---|
| | | ftype = 1 |
|---|
| | | if len(sys.argv) > 2: |
|---|
| | | ftype = int(sys.argv[2]) |
|---|
| | | if ftype < 0 or ftype > 1: |
|---|
| | | print("Invalid ftype: " + str(ftype)) |
|---|
| | | sys.exit(1) |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model-" + ftype_str[ftype] + ".bin" |
|---|
| | | |
|---|
| | | |
|---|
| | | model = GPTJForCausalLM.from_pretrained(dir_model, low_cpu_mem_usage=True) |
|---|
| | | #print (model) |
|---|
| | | |
|---|
| | | list_vars = model.state_dict() |
|---|
| | | #print (list_vars) |
|---|
| | | |
|---|
| | | fout = open(fname_out, "wb") |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex |
|---|
| | | fout.write(struct.pack("i", hparams["vocab_size"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_positions"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_embd"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_head"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_layer"])) |
|---|
| | | fout.write(struct.pack("i", hparams["rotary_dim"])) |
|---|
| | | fout.write(struct.pack("i", ftype)) |
|---|
| | | |
|---|
| | | byte_encoder = bytes_to_unicode() |
|---|
| | | byte_decoder = {v:k for k, v in byte_encoder.items()} |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", len(encoder) + len(encoder_added))) |
|---|
| | | |
|---|
| | | for key in encoder: |
|---|
| | | text = bytearray([byte_decoder[c] for c in key]) |
|---|
| | | fout.write(struct.pack("i", len(text))) |
|---|
| | | fout.write(text) |
|---|
| | | |
|---|
| | | for key in encoder_added: |
|---|
| | | text = bytearray([byte_decoder[c] for c in key]) |
|---|
| | | fout.write(struct.pack("i", len(text))) |
|---|
| | | fout.write(text) |
|---|
| | | |
|---|
| | | for name in list_vars.keys(): |
|---|
| | | data = list_vars[name].squeeze().numpy() |
|---|
| | | print("Processing variable: " + name + " with shape: ", data.shape) |
|---|
| | | |
|---|
| | | # we don't need these |
|---|
| | | if name.endswith("attn.masked_bias") or name.endswith(".attn.bias"): |
|---|
| | | print(" Skipping variable: " + name) |
|---|
| | | continue |
|---|
| | | |
|---|
| | | n_dims = len(data.shape); |
|---|
| | | |
|---|
| | | # ftype == 0 -> float32, ftype == 1 -> float16 |
|---|
| | | ftype_cur = 0; |
|---|
| | | if ftype != 0: |
|---|
| | | if name[-7:] == ".weight" and n_dims == 2: |
|---|
| | | print(" Converting to float16") |
|---|
| | | data = data.astype(np.float16) |
|---|
| | | ftype_cur = 1 |
|---|
| | | else: |
|---|
| | | print(" Converting to float32") |
|---|
| | | data = data.astype(np.float32) |
|---|
| | | ftype_cur = 0 |
|---|
| | | else: |
|---|
| | | if data.dtype != np.float32: |
|---|
| | | print(" Converting to float32") |
|---|
| | | data = data.astype(np.float32) |
|---|
| | | ftype_cur = 0 |
|---|
| | | |
|---|
| | | # for efficiency - transpose these matrices: |
|---|
| | | # (note - with latest ggml this is no longer more efficient, so disabling it) |
|---|
| | | # "transformer.h.*.mlp.fc_in.weight" |
|---|
| | | # "transformer.h.*.attn.out_proj.weight" |
|---|
| | | # "transformer.h.*.attn.q_proj.weight" |
|---|
| | | # "transformer.h.*.attn.k_proj.weight" |
|---|
| | | # "transformer.h.*.attn.v_proj.weight" |
|---|
| | | #if name.endswith(".mlp.fc_in.weight") or \ |
|---|
| | | # name.endswith(".attn.out_proj.weight") or \ |
|---|
| | | # name.endswith(".attn.q_proj.weight") or \ |
|---|
| | | # name.endswith(".attn.k_proj.weight") or \ |
|---|
| | | # name.endswith(".attn.v_proj.weight"): |
|---|
| | | # print(" Transposing") |
|---|
| | | # data = data.transpose() |
|---|
| | | |
|---|
| | | # header |
|---|
| | | str = name.encode('utf-8') |
|---|
| | | fout.write(struct.pack("iii", n_dims, len(str), ftype_cur)) |
|---|
| | | for i in range(n_dims): |
|---|
| | | fout.write(struct.pack("i", data.shape[n_dims - 1 - i])) |
|---|
| | | fout.write(str); |
|---|
| | | |
|---|
| | | # data |
|---|
| | | data.tofile(fout) |
|---|
| | | |
|---|
| | | fout.close() |
|---|
| | | |
|---|
| | | print("Done. Output file: " + fname_out) |
|---|
| | | print("") |
|---|
| New file |
| | |
|---|
| | | #!/bin/bash |
|---|
| | | |
|---|
| | | # This script downloads GPT-J model files that have already been converted to ggml format. |
|---|
| | | # This way you don't have to convert them yourself. |
|---|
| | | # |
|---|
| | | # If you want to download the original GPT-J model files, use the "download-model.sh" script instead. |
|---|
| | | |
|---|
| | | #src="https://ggml.ggerganov.com" |
|---|
| | | #pfx="ggml-model-gpt-j" |
|---|
| | | |
|---|
| | | src="https://huggingface.co/ggerganov/ggml" |
|---|
| | | pfx="resolve/main/ggml-model-gpt-j" |
|---|
| | | |
|---|
| | | ggml_path=$(dirname $(realpath $0)) |
|---|
| | | |
|---|
| | | # GPT-J models |
|---|
| | | models=( "6B" ) |
|---|
| | | |
|---|
| | | # list available models |
|---|
| | | function list_models { |
|---|
| | | printf "\n" |
|---|
| | | printf " Available models:" |
|---|
| | | for model in "${models[@]}"; do |
|---|
| | | printf " $model" |
|---|
| | | done |
|---|
| | | printf "\n\n" |
|---|
| | | } |
|---|
| | | |
|---|
| | | if [ "$#" -ne 1 ]; then |
|---|
| | | printf "Usage: $0 <model>\n" |
|---|
| | | list_models |
|---|
| | | |
|---|
| | | exit 1 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | model=$1 |
|---|
| | | |
|---|
| | | if [[ ! " ${models[@]} " =~ " ${model} " ]]; then |
|---|
| | | printf "Invalid model: $model\n" |
|---|
| | | list_models |
|---|
| | | |
|---|
| | | exit 1 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | # download ggml model |
|---|
| | | |
|---|
| | | printf "Downloading ggml model $model ...\n" |
|---|
| | | |
|---|
| | | mkdir -p models/gpt-j-$model |
|---|
| | | |
|---|
| | | if [ -x "$(command -v wget)" ]; then |
|---|
| | | wget --quiet --show-progress -O models/gpt-j-$model/ggml-model.bin $src/$pfx-$model.bin |
|---|
| | | elif [ -x "$(command -v curl)" ]; then |
|---|
| | | curl -L --output models/gpt-j-$model/ggml-model.bin $src/$pfx-$model.bin |
|---|
| | | else |
|---|
| | | printf "Either wget or curl is required to download models.\n" |
|---|
| | | exit 1 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | if [ $? -ne 0 ]; then |
|---|
| | | printf "Failed to download ggml model $model \n" |
|---|
| | | printf "Please try again later or download the original GPT-J model files and convert them yourself.\n" |
|---|
| | | exit 1 |
|---|
| | | fi |
|---|
| | | |
|---|
| | | printf "Done! Model '$model' saved in 'models/gpt-j-$model/ggml-model.bin'\n" |
|---|
| | | printf "You can now use it like this:\n\n" |
|---|
| | | printf " $ ./bin/gpt-j -m models/gpt-j-$model/ggml-model.bin -p \"This is an example\"\n" |
|---|
| | | printf "\n" |
|---|
| New file |
| | |
|---|
| | | #!/bin/bash |
|---|
| | | |
|---|
| | | printf "To obtain the GPT-J 6B model files, please visit: https://huggingface.co/EleutherAI/gpt-j-6B\n\n" |
|---|
| | | |
|---|
| | | printf "The model is very big. For example, the reposirory above is 72GB in size.\n" |
|---|
| | | printf "If you are sure that you want to clone it, simply run the following command:\n\n" |
|---|
| | | |
|---|
| | | printf " $ git clone https://huggingface.co/EleutherAI/gpt-j-6B models/gpt-j-6B\n\n" |
|---|
| | | |
|---|
| | | printf "Alternatively, use the 'download-ggml-model.sh' script to download a 12GB ggml version of the model.\n" |
|---|
| | | printf "This version is enough to run inference using the ggml library.\n\n" |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | |
|---|
| | | // default hparams (GPT-J 6B) |
|---|
| | | struct gptj_hparams { |
|---|
| | | int32_t n_vocab = 50400; |
|---|
| | | int32_t n_ctx = 2048; |
|---|
| | | int32_t n_embd = 4096; |
|---|
| | | int32_t n_head = 16; |
|---|
| | | int32_t n_layer = 28; |
|---|
| | | int32_t n_rot = 64; |
|---|
| | | int32_t ftype = 1; |
|---|
| | | float eps = 1e-5f; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gptj_layer { |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_1_g; |
|---|
| | | struct ggml_tensor * ln_1_b; |
|---|
| | | |
|---|
| | | // attention |
|---|
| | | struct ggml_tensor * c_attn_q_proj_w; |
|---|
| | | struct ggml_tensor * c_attn_k_proj_w; |
|---|
| | | struct ggml_tensor * c_attn_v_proj_w; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_attn_proj_w; |
|---|
| | | |
|---|
| | | // ff |
|---|
| | | struct ggml_tensor * c_mlp_fc_w; |
|---|
| | | struct ggml_tensor * c_mlp_fc_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_mlp_proj_w; |
|---|
| | | struct ggml_tensor * c_mlp_proj_b; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gptj_model { |
|---|
| | | gptj_hparams hparams; |
|---|
| | | |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_f_g; |
|---|
| | | struct ggml_tensor * ln_f_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * wte; // position embedding |
|---|
| | | |
|---|
| | | struct ggml_tensor * lmh_g; // language model head |
|---|
| | | struct ggml_tensor * lmh_b; // language model bias |
|---|
| | | |
|---|
| | | std::vector<gptj_layer> layers; |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | struct ggml_tensor * memory_k; |
|---|
| | | struct ggml_tensor * memory_v; |
|---|
| | | |
|---|
| | | // |
|---|
| | | struct ggml_context * ctx; |
|---|
| | | std::map<std::string, struct ggml_tensor *> tensors; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // load the model's weights from a file |
|---|
| | | bool gptj_model_load(const std::string & fname, gptj_model & model, gpt_vocab & vocab) { |
|---|
| | | printf("%s: loading model from '%s' - please wait ...\n", __func__, fname.c_str()); |
|---|
| | | |
|---|
| | | auto fin = std::ifstream(fname, std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | fin.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fin.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fin.read((char *) &hparams.n_rot, sizeof(hparams.n_rot)); |
|---|
| | | fin.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: n_rot = %d\n", __func__, hparams.n_rot); |
|---|
| | | printf("%s: ftype = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr = %d\n", __func__, qntvr); |
|---|
| | | |
|---|
| | | hparams.ftype %= GGML_QNT_VERSION_FACTOR; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | int32_t n_vocab = 0; |
|---|
| | | fin.read((char *) &n_vocab, sizeof(n_vocab)); |
|---|
| | | |
|---|
| | | if (n_vocab != model.hparams.n_vocab) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n", |
|---|
| | | __func__, fname.c_str(), n_vocab, model.hparams.n_vocab); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | std::vector<char> buf(128); |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | fin.read((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | buf.resize(len); |
|---|
| | | fin.read((char *) buf.data(), len); |
|---|
| | | word.assign(buf.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for the big tensors, we have the option to store the data in 16-bit floats or quantized |
|---|
| | | // in order to save memory and also to speed up the computation |
|---|
| | | ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype)); |
|---|
| | | if (wtype == GGML_TYPE_COUNT) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n", |
|---|
| | | __func__, fname.c_str(), model.hparams.ftype); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto & ctx = model.ctx; |
|---|
| | | |
|---|
| | | size_t ctx_size = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_g |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_b |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(wtype, n_embd*n_vocab); // wte |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(wtype, n_embd*n_vocab); // lmh_g |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_vocab); // lmh_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_g |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, n_embd*n_embd)); // c_attn_q_proj_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, n_embd*n_embd)); // c_attn_k_proj_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, n_embd*n_embd)); // c_attn_v_proj_w |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, n_embd*n_embd)); // c_attn_proj_w |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_fc_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 4*n_embd)); // c_mlp_fc_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_proj_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // c_mlp_proj_b |
|---|
| | | |
|---|
| | | ctx_size += n_ctx*n_layer*ggml_row_size(GGML_TYPE_F16, n_embd); // memory_k |
|---|
| | | ctx_size += n_ctx*n_layer*ggml_row_size(GGML_TYPE_F16, n_embd); // memory_v |
|---|
| | | |
|---|
| | | ctx_size += (5 + 10*n_layer)*512; // object overhead |
|---|
| | | |
|---|
| | | printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // create the ggml context |
|---|
| | | { |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ ctx_size, |
|---|
| | | /*.mem_buffer =*/ NULL, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | model.ctx = ggml_init(params); |
|---|
| | | if (!model.ctx) { |
|---|
| | | fprintf(stderr, "%s: ggml_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // prepare memory for the weights |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | model.layers.resize(n_layer); |
|---|
| | | |
|---|
| | | model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | |
|---|
| | | model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | model.lmh_g = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | model.lmh_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_vocab); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["transformer.wte.weight"] = model.wte; |
|---|
| | | |
|---|
| | | model.tensors["transformer.ln_f.weight"] = model.ln_f_g; |
|---|
| | | model.tensors["transformer.ln_f.bias"] = model.ln_f_b; |
|---|
| | | |
|---|
| | | model.tensors["lm_head.weight"] = model.lmh_g; |
|---|
| | | model.tensors["lm_head.bias"] = model.lmh_b; |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_layer; ++i) { |
|---|
| | | auto & layer = model.layers[i]; |
|---|
| | | |
|---|
| | | layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_q_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | layer.c_attn_k_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | layer.c_attn_v_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd); |
|---|
| | | layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd); |
|---|
| | | layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["transformer.h." + std::to_string(i) + ".ln_1.weight"] = layer.ln_1_g; |
|---|
| | | model.tensors["transformer.h." + std::to_string(i) + ".ln_1.bias"] = layer.ln_1_b; |
|---|
| | | |
|---|
| | | model.tensors["transformer.h." + std::to_string(i) + ".attn.q_proj.weight"] = layer.c_attn_q_proj_w; |
|---|
| | | model.tensors["transformer.h." + std::to_string(i) + ".attn.k_proj.weight"] = layer.c_attn_k_proj_w; |
|---|
| | | model.tensors["transformer.h." + std::to_string(i) + ".attn.v_proj.weight"] = layer.c_attn_v_proj_w; |
|---|
| | | |
|---|
| | | model.tensors["transformer.h." + std::to_string(i) + ".attn.out_proj.weight"] = layer.c_attn_proj_w; |
|---|
| | | |
|---|
| | | model.tensors["transformer.h." + std::to_string(i) + ".mlp.fc_in.weight"] = layer.c_mlp_fc_w; |
|---|
| | | model.tensors["transformer.h." + std::to_string(i) + ".mlp.fc_in.bias"] = layer.c_mlp_fc_b; |
|---|
| | | |
|---|
| | | model.tensors["transformer.h." + std::to_string(i) + ".mlp.fc_out.weight"] = layer.c_mlp_proj_w; |
|---|
| | | model.tensors["transformer.h." + std::to_string(i) + ".mlp.fc_out.bias"] = layer.c_mlp_proj_b; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | |
|---|
| | | const int n_mem = n_layer*n_ctx; |
|---|
| | | const int n_elements = n_embd*n_mem; |
|---|
| | | |
|---|
| | | model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements); |
|---|
| | | model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements); |
|---|
| | | |
|---|
| | | const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v); |
|---|
| | | |
|---|
| | | printf("%s: memory_size = %8.2f MB, n_mem = %d\n", __func__, memory_size/1024.0/1024.0, n_mem); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load weights |
|---|
| | | { |
|---|
| | | int n_tensors = 0; |
|---|
| | | size_t total_size = 0; |
|---|
| | | |
|---|
| | | printf("%s: ", __func__); |
|---|
| | | |
|---|
| | | while (true) { |
|---|
| | | int32_t n_dims; |
|---|
| | | int32_t length; |
|---|
| | | int32_t ttype; |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&length), sizeof(length)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype)); |
|---|
| | | |
|---|
| | | if (fin.eof()) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int32_t nelements = 1; |
|---|
| | | int32_t ne[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i])); |
|---|
| | | nelements *= ne[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string name(length, 0); |
|---|
| | | fin.read(&name[0], length); |
|---|
| | | |
|---|
| | | if (model.tensors.find(name) == model.tensors.end()) { |
|---|
| | | fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto tensor = model.tensors[name]; |
|---|
| | | if (ggml_nelements(tensor) != nelements) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%d, %d], expected [%d, %d]\n", |
|---|
| | | __func__, name.c_str(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for debugging |
|---|
| | | if (0) { |
|---|
| | | printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.c_str(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const size_t bpe = ggml_type_size(ggml_type(ttype)); |
|---|
| | | |
|---|
| | | if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n", |
|---|
| | | __func__, name.c_str(), ggml_nbytes(tensor), nelements*bpe); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor)); |
|---|
| | | |
|---|
| | | //printf("%42s - [%5d, %5d], type = %6s, %6.2f MB\n", name.c_str(), ne[0], ne[1], ttype == 0 ? "float" : "f16", ggml_nbytes(tensor)/1024.0/1024.0); |
|---|
| | | total_size += ggml_nbytes(tensor); |
|---|
| | | if (++n_tensors % 8 == 0) { |
|---|
| | | printf("."); |
|---|
| | | fflush(stdout); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf(" done\n"); |
|---|
| | | |
|---|
| | | printf("%s: model size = %8.2f MB / num tensors = %d\n", __func__, total_size/1024.0/1024.0, n_tensors); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // evaluate the transformer |
|---|
| | | // |
|---|
| | | // - model: the model |
|---|
| | | // - n_threads: number of threads to use |
|---|
| | | // - n_past: the context size so far |
|---|
| | | // - embd_inp: the embeddings of the tokens in the context |
|---|
| | | // - embd_w: the predicted logits for the next token |
|---|
| | | // |
|---|
| | | // The GPT-J model requires about 16MB of memory per input token. |
|---|
| | | // |
|---|
| | | bool gptj_eval( |
|---|
| | | const gptj_model & model, |
|---|
| | | const int n_threads, |
|---|
| | | const int n_past, |
|---|
| | | const std::vector<gpt_vocab::id> & embd_inp, |
|---|
| | | std::vector<float> & embd_w, |
|---|
| | | size_t & mem_per_token) { |
|---|
| | | const int N = embd_inp.size(); |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_head = hparams.n_head; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | const int n_rot = hparams.n_rot; |
|---|
| | | |
|---|
| | | static size_t buf_size = 256u*1024*1024; |
|---|
| | | static void * buf = malloc(buf_size); |
|---|
| | | |
|---|
| | | if (mem_per_token > 0 && mem_per_token*N > buf_size) { |
|---|
| | | const size_t buf_size_new = 1.1*(mem_per_token*N); // add 10% to account for ggml object overhead |
|---|
| | | //printf("\n%s: reallocating buffer from %zu to %zu bytes\n", __func__, buf_size, buf_size_new); |
|---|
| | | |
|---|
| | | // reallocate |
|---|
| | | buf_size = buf_size_new; |
|---|
| | | buf = realloc(buf, buf_size); |
|---|
| | | if (buf == nullptr) { |
|---|
| | | fprintf(stderr, "%s: failed to allocate %zu bytes\n", __func__, buf_size); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx0 = ggml_init(params); |
|---|
| | | struct ggml_cgraph * gf = ggml_new_graph(ctx0); |
|---|
| | | |
|---|
| | | // KQ_pos - contains the positions |
|---|
| | | struct ggml_tensor * KQ_pos = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | int * data = (int *) KQ_pos->data; |
|---|
| | | for (int i = 0; i < N; ++i) { |
|---|
| | | data[i] = n_past + i; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | memcpy(embd->data, embd_inp.data(), N*ggml_element_size(embd)); |
|---|
| | | |
|---|
| | | // wte |
|---|
| | | struct ggml_tensor * inpL = ggml_get_rows(ctx0, model.wte, embd); |
|---|
| | | |
|---|
| | | for (int il = 0; il < n_layer; ++il) { |
|---|
| | | struct ggml_tensor * cur; |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | cur = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // cur = ln_1_g*cur + ln_1_b |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_1_g, cur), |
|---|
| | | cur), |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_1_b, cur)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * inpSA = cur; |
|---|
| | | |
|---|
| | | // self-attention |
|---|
| | | { |
|---|
| | | struct ggml_tensor * Qcur = ggml_rope_inplace(ctx0, ggml_reshape_3d(ctx0, ggml_mul_mat(ctx0, model.layers[il].c_attn_q_proj_w, cur), n_embd/n_head, n_head, N), KQ_pos, n_rot, 0, 0); |
|---|
| | | struct ggml_tensor * Kcur = ggml_rope_inplace(ctx0, ggml_reshape_3d(ctx0, ggml_mul_mat(ctx0, model.layers[il].c_attn_k_proj_w, cur), n_embd/n_head, n_head, N), KQ_pos, n_rot, 0, 0); |
|---|
| | | |
|---|
| | | // store key and value to memory |
|---|
| | | { |
|---|
| | | struct ggml_tensor * Vcur = ggml_transpose(ctx0, ggml_mul_mat(ctx0, model.layers[il].c_attn_v_proj_w, cur)); |
|---|
| | | |
|---|
| | | struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past)); |
|---|
| | | struct ggml_tensor * v = ggml_view_2d(ctx0, model.memory_v, N, n_embd, |
|---|
| | | ( n_ctx)*ggml_element_size(model.memory_v), |
|---|
| | | (il*n_ctx)*ggml_element_size(model.memory_v)*n_embd + n_past*ggml_element_size(model.memory_v)); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3) |
|---|
| | | struct ggml_tensor * Q = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | Qcur, |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3) |
|---|
| | | struct ggml_tensor * K = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_past + N), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // K * Q |
|---|
| | | struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); |
|---|
| | | |
|---|
| | | // KQ_scaled = KQ / sqrt(n_embd/n_head) |
|---|
| | | struct ggml_tensor * KQ_scaled = |
|---|
| | | ggml_scale_inplace(ctx0, |
|---|
| | | KQ, |
|---|
| | | 1.0f/sqrt(float(n_embd)/n_head)); |
|---|
| | | |
|---|
| | | // KQ_masked = mask_past(KQ_scaled) |
|---|
| | | struct ggml_tensor * KQ_masked = ggml_diag_mask_inf_inplace(ctx0, KQ_scaled, n_past); |
|---|
| | | |
|---|
| | | // KQ = soft_max(KQ_masked) |
|---|
| | | struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked); |
|---|
| | | |
|---|
| | | // V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous() |
|---|
| | | struct ggml_tensor * V = |
|---|
| | | ggml_view_3d(ctx0, model.memory_v, |
|---|
| | | n_past + N, n_embd/n_head, n_head, |
|---|
| | | n_ctx*ggml_element_size(model.memory_v), |
|---|
| | | n_ctx*ggml_element_size(model.memory_v)*n_embd/n_head, |
|---|
| | | il*n_ctx*ggml_element_size(model.memory_v)*n_embd); |
|---|
| | | |
|---|
| | | // KQV = transpose(V) * KQ_soft_max |
|---|
| | | struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max); |
|---|
| | | |
|---|
| | | // KQV_merged = KQV.permute(0, 2, 1, 3) |
|---|
| | | struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // cur = KQV_merged.contiguous().view(n_embd, N) |
|---|
| | | cur = ggml_cpy(ctx0, |
|---|
| | | KQV_merged, |
|---|
| | | ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N)); |
|---|
| | | |
|---|
| | | // projection (no bias) |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_proj_w, |
|---|
| | | cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * inpFF = cur; |
|---|
| | | |
|---|
| | | // feed-forward network |
|---|
| | | // this is independent of the self-attention result, so it could be done in parallel to the self-attention |
|---|
| | | { |
|---|
| | | // note here we pass inpSA instead of cur |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_fc_w, |
|---|
| | | inpSA); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_mlp_fc_b, cur), |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | // GELU activation |
|---|
| | | cur = ggml_gelu(ctx0, cur); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_mlp_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_mlp_proj_b, cur), |
|---|
| | | cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // self-attention + FF |
|---|
| | | cur = ggml_add(ctx0, cur, inpFF); |
|---|
| | | |
|---|
| | | // input for next layer |
|---|
| | | inpL = ggml_add(ctx0, cur, inpL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | inpL = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // inpL = ln_f_g*inpL + ln_f_b |
|---|
| | | inpL = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.ln_f_g, inpL), |
|---|
| | | inpL), |
|---|
| | | ggml_repeat(ctx0, model.ln_f_b, inpL)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // lm_head |
|---|
| | | { |
|---|
| | | inpL = ggml_mul_mat(ctx0, model.lmh_g, inpL); |
|---|
| | | |
|---|
| | | inpL = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.lmh_b, inpL), |
|---|
| | | inpL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // logits -> probs |
|---|
| | | //inpL = ggml_soft_max_inplace(ctx0, inpL); |
|---|
| | | |
|---|
| | | // run the computation |
|---|
| | | ggml_build_forward_expand(gf, inpL); |
|---|
| | | ggml_graph_compute_with_ctx(ctx0, gf, n_threads); |
|---|
| | | |
|---|
| | | //if (n_past%100 == 0) { |
|---|
| | | // ggml_graph_print (&gf); |
|---|
| | | // ggml_graph_dump_dot(&gf, NULL, "gpt-j.dot"); |
|---|
| | | //} |
|---|
| | | |
|---|
| | | //embd_w.resize(n_vocab*N); |
|---|
| | | //memcpy(embd_w.data(), ggml_get_data(inpL), sizeof(float)*n_vocab*N); |
|---|
| | | |
|---|
| | | // return result for just the last token |
|---|
| | | embd_w.resize(n_vocab); |
|---|
| | | memcpy(embd_w.data(), (float *) ggml_get_data(inpL) + (n_vocab*(N-1)), sizeof(float)*n_vocab); |
|---|
| | | |
|---|
| | | if (mem_per_token == 0) { |
|---|
| | | mem_per_token = ggml_used_mem(ctx0)/N; |
|---|
| | | } |
|---|
| | | //printf("used_mem = %zu\n", ggml_used_mem(ctx0)); |
|---|
| | | |
|---|
| | | ggml_free(ctx0); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | gpt_params params; |
|---|
| | | params.model = "models/gpt-j-6B/ggml-model.bin"; |
|---|
| | | |
|---|
| | | if (gpt_params_parse(argc, argv, params) == false) { |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.seed < 0) { |
|---|
| | | params.seed = time(NULL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: seed = %d\n", __func__, params.seed); |
|---|
| | | |
|---|
| | | std::mt19937 rng(params.seed); |
|---|
| | | if (params.prompt.empty()) { |
|---|
| | | params.prompt = gpt_random_prompt(rng); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int64_t t_load_us = 0; |
|---|
| | | |
|---|
| | | gpt_vocab vocab; |
|---|
| | | gptj_model model; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gptj_model_load(params.model, model, vocab)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | test_gpt_tokenizer(vocab, params.token_test); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int n_past = 0; |
|---|
| | | |
|---|
| | | int64_t t_sample_us = 0; |
|---|
| | | int64_t t_predict_us = 0; |
|---|
| | | |
|---|
| | | std::vector<float> logits; |
|---|
| | | |
|---|
| | | // tokenize the prompt |
|---|
| | | std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, params.prompt); |
|---|
| | | |
|---|
| | | params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size()); |
|---|
| | | |
|---|
| | | printf("%s: number of tokens in prompt = %zu\n", __func__, embd_inp.size()); |
|---|
| | | printf("\n"); |
|---|
| | | |
|---|
| | | std::vector<gpt_vocab::id> embd; |
|---|
| | | |
|---|
| | | // determine the required inference memory per token: |
|---|
| | | size_t mem_per_token = 0; |
|---|
| | | gptj_eval(model, params.n_threads, 0, { 0, 1, 2, 3 }, logits, mem_per_token); |
|---|
| | | |
|---|
| | | for (size_t i = embd.size(); i < embd_inp.size() + params.n_predict; i++) { |
|---|
| | | // predict |
|---|
| | | if (embd.size() > 0) { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gptj_eval(model, params.n_threads, n_past, embd, logits, mem_per_token)) { |
|---|
| | | printf("Failed to predict\n"); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_predict_us += ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | n_past += embd.size(); |
|---|
| | | embd.clear(); |
|---|
| | | |
|---|
| | | if (i >= embd_inp.size()) { |
|---|
| | | // sample next token |
|---|
| | | const int top_k = params.top_k; |
|---|
| | | const float top_p = params.top_p; |
|---|
| | | const float temp = params.temp; |
|---|
| | | |
|---|
| | | const int n_vocab = model.hparams.n_vocab; |
|---|
| | | |
|---|
| | | gpt_vocab::id id = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const int64_t t_start_sample_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng); |
|---|
| | | |
|---|
| | | t_sample_us += ggml_time_us() - t_start_sample_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add it to the context |
|---|
| | | embd.push_back(id); |
|---|
| | | } else { |
|---|
| | | // if here, it means we are still processing the input prompt |
|---|
| | | for (size_t k = i; k < embd_inp.size(); k++) { |
|---|
| | | embd.push_back(embd_inp[k]); |
|---|
| | | if (int32_t(embd.size()) > params.n_batch) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | i += embd.size() - 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // display text |
|---|
| | | for (auto id : embd) { |
|---|
| | | printf("%s", vocab.id_to_token[id].c_str()); |
|---|
| | | } |
|---|
| | | fflush(stdout); |
|---|
| | | |
|---|
| | | // end of text token |
|---|
| | | if (embd.back() == 50256) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n\n"); |
|---|
| | | printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token); |
|---|
| | | printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f); |
|---|
| | | printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f); |
|---|
| | | printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us/1000.0f, t_predict_us/1000.0f/n_past); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | #include <regex> |
|---|
| | | |
|---|
| | | // default hparams (GPT-J 6B) |
|---|
| | | struct gptj_hparams { |
|---|
| | | int32_t n_vocab = 50400; |
|---|
| | | int32_t n_ctx = 2048; |
|---|
| | | int32_t n_embd = 4096; |
|---|
| | | int32_t n_head = 16; |
|---|
| | | int32_t n_layer = 28; |
|---|
| | | int32_t n_rot = 64; |
|---|
| | | int32_t ftype = 1; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // quantize a model |
|---|
| | | bool gptj_model_quantize(const std::string & fname_inp, const std::string & fname_out, ggml_ftype ftype) { |
|---|
| | | gpt_vocab vocab; |
|---|
| | | |
|---|
| | | printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | |
|---|
| | | auto finp = std::ifstream(fname_inp, std::ios::binary); |
|---|
| | | if (!finp) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto fout = std::ofstream(fname_out, std::ios::binary); |
|---|
| | | if (!fout) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname_out.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | finp.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | fout.write((char *) &magic, sizeof(magic)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | gptj_hparams hparams; |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | finp.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | finp.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | finp.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | finp.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | finp.read((char *) &hparams.n_rot, sizeof(hparams.n_rot)); |
|---|
| | | finp.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: ftype (src) = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr (src) = %d\n", __func__, qntvr_src); |
|---|
| | | printf("%s: ftype (dst) = %d\n", __func__, ftype_dst); |
|---|
| | | printf("%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION); |
|---|
| | | |
|---|
| | | fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fout.write((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fout.write((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fout.write((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fout.write((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fout.write((char *) &hparams.n_rot, sizeof(hparams.n_rot)); |
|---|
| | | fout.write((char *) &ftype_dst, sizeof(ftype_dst)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | int32_t n_vocab = 0; |
|---|
| | | finp.read ((char *) &n_vocab, sizeof(n_vocab)); |
|---|
| | | fout.write((char *) &n_vocab, sizeof(n_vocab)); |
|---|
| | | |
|---|
| | | if (n_vocab != hparams.n_vocab) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad vocab size %d != %d)\n", |
|---|
| | | __func__, fname_inp.c_str(), n_vocab, hparams.n_vocab); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | finp.read ((char *) &len, sizeof(len)); |
|---|
| | | fout.write((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | word.resize(len); |
|---|
| | | finp.read ((char *) word.data(), len); |
|---|
| | | fout.write((char *) word.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // regexes of tensor names to be quantized |
|---|
| | | const std::vector<std::string> to_quant = { |
|---|
| | | ".*weight", |
|---|
| | | }; |
|---|
| | | |
|---|
| | | if (!ggml_common_quantize_0(finp, fout, ftype, to_quant, {})) { |
|---|
| | | fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | finp.close(); |
|---|
| | | fout.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // usage: |
|---|
| | | // ./gpt-2-quantize models/gpt-2-117M/ggml-model.bin models/gpt-2-117M/ggml-model-quant.bin type |
|---|
| | | // |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | if (argc != 4) { |
|---|
| | | fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n", argv[0]); |
|---|
| | | ggml_print_ftypes(stderr); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // needed to initialize f16 tables |
|---|
| | | { |
|---|
| | | struct ggml_init_params params = { 0, NULL, false }; |
|---|
| | | struct ggml_context * ctx = ggml_init(params); |
|---|
| | | ggml_free(ctx); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const std::string fname_inp = argv[1]; |
|---|
| | | const std::string fname_out = argv[2]; |
|---|
| | | |
|---|
| | | const ggml_ftype ftype = ggml_parse_ftype(argv[3]); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | int64_t t_quantize_us = 0; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gptj_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) { |
|---|
| | | fprintf(stderr, "%s: failed to quantize model from '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_quantize_us = ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n"); |
|---|
| | | printf("%s: quantize time = %8.2f ms\n", __func__, t_quantize_us/1000.0f); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | # |
|---|
| | | # gpt-neox |
|---|
| | | |
|---|
| | | set(TEST_TARGET gpt-neox) |
|---|
| | | add_executable(${TEST_TARGET} main.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| | | |
|---|
| | | # |
|---|
| | | # gpt-neox-quantize |
|---|
| | | |
|---|
| | | set(TEST_TARGET gpt-neox-quantize) |
|---|
| | | add_executable(${TEST_TARGET} quantize.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| New file |
| | |
|---|
| | | # GPT-NeoX |
|---|
| | | |
|---|
| | | Transformer architecture: GPT-NeoX |
|---|
| | | |
|---|
| | | Ref: https://github.com/stability-AI/stableLM/#stablelm-alpha |
|---|
| | | |
|---|
| | | ## Usage |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | # get the repo and build it |
|---|
| | | git clone https://github.com/ggerganov/ggml |
|---|
| | | cd ggml |
|---|
| | | mkdir build && cd build |
|---|
| | | cmake .. |
|---|
| | | make -j |
|---|
| | | |
|---|
| | | # get the StableLM 3B Alpha model |
|---|
| | | git clone https://huggingface.co/stabilityai/gpt_neox-base-alpha-3b |
|---|
| | | |
|---|
| | | # install Python dependencies |
|---|
| | | python3 -m pip install -r ../requirements.txt |
|---|
| | | |
|---|
| | | # convert model to FP16 |
|---|
| | | python3 ../examples/gpt-neox/convert-h5-to-ggml.py ./stablelm-base-alpha-3b/ 1 |
|---|
| | | |
|---|
| | | # run inference using FP16 precision |
|---|
| | | make -j && ./bin/gpt-neox -m ./stablelm-base-alpha-3b/ggml-model-f16.bin -p "I believe the meaning of life is" -t 8 -n 64 |
|---|
| | | |
|---|
| | | main: seed = 1681940611 |
|---|
| | | gpt_neox_model_load: loading model from 'models/stablelm-base-alpha-3b/ggml-model-f16.bin' - please wait ... |
|---|
| | | gpt_neox_model_load: n_vocab = 50688 |
|---|
| | | gpt_neox_model_load: n_ctx = 4096 |
|---|
| | | gpt_neox_model_load: n_embd = 4096 |
|---|
| | | gpt_neox_model_load: n_head = 32 |
|---|
| | | gpt_neox_model_load: n_layer = 16 |
|---|
| | | gpt_neox_model_load: n_rot = 32 |
|---|
| | | gpt_neox_model_load: ftype = 1 |
|---|
| | | gpt_neox_model_load: ggml ctx size = 10011.10 MB |
|---|
| | | gpt_neox_model_load: memory_size = 2048.00 MB, n_mem = 65536 |
|---|
| | | gpt_neox_model_load: ................................ done |
|---|
| | | gpt_neox_model_load: model size = 6939.28 MB / num tensors = 260 |
|---|
| | | main: number of tokens in prompt = 7 |
|---|
| | | main: token[0] = 42, I |
|---|
| | | main: token[1] = 2868, believe |
|---|
| | | main: token[2] = 253, the |
|---|
| | | main: token[3] = 4495, meaning |
|---|
| | | main: token[4] = 273, of |
|---|
| | | main: token[5] = 1495, life |
|---|
| | | main: token[6] = 310, is |
|---|
| | | |
|---|
| | | I believe the meaning of life is to grow, to find a way, to love, to find an appreciation for life, and to live it with all of its beauty. |
|---|
| | | |
|---|
| | | For I am the child of God. I am the offspring of God's love. I am the offspring of the light of the world. I am the offspring of the |
|---|
| | | |
|---|
| | | main: mem per token = 12186760 bytes |
|---|
| | | main: load time = 2118.55 ms |
|---|
| | | main: sample time = 9.59 ms |
|---|
| | | main: predict time = 4474.07 ms / 63.92 ms per token |
|---|
| | | main: total time = 6911.26 ms |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## 5-bit integer quantization mode |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | # quantize the model to 5-bits using Q5_0 quantization |
|---|
| | | ./bin/gpt-neox-quantize ./stablelm-base-alpha-3b/ggml-model-f16.bin ./stablelm-base-alpha-3b/ggml-model-q5_0.bin q5_0 |
|---|
| | | |
|---|
| | | # run the quantized model |
|---|
| | | ./bin/gpt-neox -m ./stablelm-base-alpha-3b/ggml-model-q5_0.bin -p "I believe the meaning of life is" -t 8 -n 64 |
|---|
| | | |
|---|
| | | main: seed = 1682021489 |
|---|
| | | gpt_neox_model_load: loading model from 'models/stablelm-base-alpha-3b/ggml-model-q5_0.bin' - please wait ... |
|---|
| | | gpt_neox_model_load: n_vocab = 50688 |
|---|
| | | gpt_neox_model_load: n_ctx = 4096 |
|---|
| | | gpt_neox_model_load: n_embd = 4096 |
|---|
| | | gpt_neox_model_load: n_head = 32 |
|---|
| | | gpt_neox_model_load: n_layer = 16 |
|---|
| | | gpt_neox_model_load: n_rot = 32 |
|---|
| | | gpt_neox_model_load: ftype = 6 |
|---|
| | | gpt_neox_model_load: ggml ctx size = 5676.10 MB |
|---|
| | | gpt_neox_model_load: memory_size = 1024.00 MB, n_mem = 65536 |
|---|
| | | gpt_neox_model_load: ........................ done |
|---|
| | | gpt_neox_model_load: model size = 2604.28 MB / num tensors = 196 |
|---|
| | | main: number of tokens in prompt = 7 |
|---|
| | | main: token[0] = 42, I |
|---|
| | | main: token[1] = 2868, believe |
|---|
| | | main: token[2] = 253, the |
|---|
| | | main: token[3] = 4495, meaning |
|---|
| | | main: token[4] = 273, of |
|---|
| | | main: token[5] = 1495, life |
|---|
| | | main: token[6] = 310, is |
|---|
| | | |
|---|
| | | I believe the meaning of life is to love and be loved. The last three verses were enough to tie us all together. If you love someone you love them all. There are some things in this world that are just not equal in Heaven. - Be here in this moment. |
|---|
| | | |
|---|
| | | This world is not what is outside of us. It is what |
|---|
| | | |
|---|
| | | main: mem per token = 12958024 bytes |
|---|
| | | main: load time = 850.51 ms |
|---|
| | | main: sample time = 9.95 ms |
|---|
| | | main: predict time = 3103.81 ms / 44.34 ms per token |
|---|
| | | main: total time = 4177.68 ms |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## Notes |
|---|
| | | |
|---|
| | | - No guarantees for correctness |
|---|
| | | - The tokenizer is currently hacked - probably works only for English |
|---|
| | | - Non-parallel residual is not supported |
|---|
| | | - Contributions and improvements are welcome |
|---|
| New file |
| | |
|---|
| | | import sys |
|---|
| | | import struct |
|---|
| | | import json |
|---|
| | | import numpy as np |
|---|
| | | |
|---|
| | | from transformers import AutoModelForCausalLM, AutoTokenizer |
|---|
| | | |
|---|
| | | if len(sys.argv) < 3: |
|---|
| | | print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n") |
|---|
| | | print(" ftype == 0 -> float32") |
|---|
| | | print(" ftype == 1 -> float16") |
|---|
| | | sys.exit(1) |
|---|
| | | |
|---|
| | | # output in the same directory as the model |
|---|
| | | dir_model = sys.argv[1] |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model.bin" |
|---|
| | | |
|---|
| | | with open(dir_model + "/config.json", "r", encoding="utf-8") as f: |
|---|
| | | hparams = json.load(f) |
|---|
| | | |
|---|
| | | # possible data types |
|---|
| | | # ftype == 0 -> float32 |
|---|
| | | # ftype == 1 -> float16 |
|---|
| | | # |
|---|
| | | # map from ftype to string |
|---|
| | | ftype_str = ["f32", "f16"] |
|---|
| | | |
|---|
| | | ftype = 1 |
|---|
| | | if len(sys.argv) > 2: |
|---|
| | | ftype = int(sys.argv[2]) |
|---|
| | | if ftype < 0 or ftype > 1: |
|---|
| | | print("Invalid ftype: " + str(ftype)) |
|---|
| | | sys.exit(1) |
|---|
| | | fname_out = sys.argv[1] + "/ggml-model-" + ftype_str[ftype] + ".bin" |
|---|
| | | |
|---|
| | | |
|---|
| | | tokenizer = AutoTokenizer.from_pretrained(dir_model) |
|---|
| | | model = AutoModelForCausalLM.from_pretrained(dir_model, low_cpu_mem_usage=True) |
|---|
| | | |
|---|
| | | list_vars = model.state_dict() |
|---|
| | | for name in list_vars.keys(): |
|---|
| | | print(name, list_vars[name].shape, list_vars[name].dtype) |
|---|
| | | |
|---|
| | | fout = open(fname_out, "wb") |
|---|
| | | |
|---|
| | | print(hparams) |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex |
|---|
| | | fout.write(struct.pack("i", hparams["vocab_size"])) |
|---|
| | | fout.write(struct.pack("i", hparams["max_position_embeddings"])) |
|---|
| | | fout.write(struct.pack("i", hparams["hidden_size"])) |
|---|
| | | fout.write(struct.pack("i", hparams["num_attention_heads"])) |
|---|
| | | fout.write(struct.pack("i", hparams["num_hidden_layers"])) |
|---|
| | | fout.write(struct.pack("i", int(hparams["rotary_pct"]*(hparams["hidden_size"]//hparams["num_attention_heads"])))) |
|---|
| | | fout.write(struct.pack("i", hparams["use_parallel_residual"] if "use_parallel_residual" in hparams else True)) |
|---|
| | | fout.write(struct.pack("i", ftype)) |
|---|
| | | |
|---|
| | | # TODO: temporary hack to not deal with implementing the tokenizer |
|---|
| | | for i in range(hparams["vocab_size"]): |
|---|
| | | text = tokenizer.decode([i]).encode('utf-8') |
|---|
| | | fout.write(struct.pack("i", len(text))) |
|---|
| | | fout.write(text) |
|---|
| | | |
|---|
| | | for name in list_vars.keys(): |
|---|
| | | data = list_vars[name].squeeze().numpy() |
|---|
| | | print("Processing variable: " + name + " with shape: ", data.shape) |
|---|
| | | |
|---|
| | | # we don't need these |
|---|
| | | if name.endswith(".attention.masked_bias") or \ |
|---|
| | | name.endswith(".attention.bias") or \ |
|---|
| | | name.endswith(".attention.rotary_emb.inv_freq"): |
|---|
| | | print(" Skipping variable: " + name) |
|---|
| | | continue |
|---|
| | | |
|---|
| | | n_dims = len(data.shape) |
|---|
| | | |
|---|
| | | # ftype == 0 -> float32, ftype == 1 -> float16 |
|---|
| | | ftype_cur = 0 |
|---|
| | | if ftype != 0: |
|---|
| | | if name[-7:] == ".weight" and n_dims == 2: |
|---|
| | | print(" Converting to float16") |
|---|
| | | data = data.astype(np.float16) |
|---|
| | | ftype_cur = 1 |
|---|
| | | else: |
|---|
| | | print(" Converting to float32") |
|---|
| | | data = data.astype(np.float32) |
|---|
| | | ftype_cur = 0 |
|---|
| | | else: |
|---|
| | | if data.dtype != np.float32: |
|---|
| | | print(" Converting to float32") |
|---|
| | | data = data.astype(np.float32) |
|---|
| | | ftype_cur = 0 |
|---|
| | | |
|---|
| | | # header |
|---|
| | | str = name.encode('utf-8') |
|---|
| | | fout.write(struct.pack("iii", n_dims, len(str), ftype_cur)) |
|---|
| | | for i in range(n_dims): |
|---|
| | | fout.write(struct.pack("i", data.shape[n_dims - 1 - i])) |
|---|
| | | fout.write(str) |
|---|
| | | |
|---|
| | | # data |
|---|
| | | data.tofile(fout) |
|---|
| | | |
|---|
| | | fout.close() |
|---|
| | | |
|---|
| | | print("Done. Output file: " + fname_out) |
|---|
| | | print("") |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <cinttypes> |
|---|
| | | #include <fstream> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | // default hparams (StableLM 3B) |
|---|
| | | struct gpt_neox_hparams { |
|---|
| | | int32_t n_vocab = 50257; |
|---|
| | | int32_t n_ctx = 4096; |
|---|
| | | int32_t n_embd = 4096; |
|---|
| | | int32_t n_head = 32; |
|---|
| | | int32_t n_layer = 16; |
|---|
| | | int32_t n_rot = 32; // rotary_pct * (n_embd / n_head) |
|---|
| | | int32_t par_res = 1; // 1 = true, 0 = false |
|---|
| | | int32_t ftype = 1; |
|---|
| | | float eps = 1e-5f; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt_neox_layer { |
|---|
| | | // pre normalization |
|---|
| | | struct ggml_tensor * ln_1_g; |
|---|
| | | struct ggml_tensor * ln_1_b; |
|---|
| | | |
|---|
| | | // attention |
|---|
| | | struct ggml_tensor * c_attn_attn_w; |
|---|
| | | struct ggml_tensor * c_attn_attn_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_attn_proj_w; |
|---|
| | | struct ggml_tensor * c_attn_proj_b; |
|---|
| | | |
|---|
| | | // post normalization |
|---|
| | | struct ggml_tensor * ln_2_g; |
|---|
| | | struct ggml_tensor * ln_2_b; |
|---|
| | | |
|---|
| | | // ff |
|---|
| | | struct ggml_tensor * c_mlp_fc_w; |
|---|
| | | struct ggml_tensor * c_mlp_fc_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * c_mlp_proj_w; |
|---|
| | | struct ggml_tensor * c_mlp_proj_b; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct gpt_neox_model { |
|---|
| | | gpt_neox_hparams hparams; |
|---|
| | | |
|---|
| | | // normalization |
|---|
| | | struct ggml_tensor * ln_f_g; |
|---|
| | | struct ggml_tensor * ln_f_b; |
|---|
| | | |
|---|
| | | struct ggml_tensor * wte; // position embedding |
|---|
| | | |
|---|
| | | struct ggml_tensor * lmh_g; // language model head |
|---|
| | | //struct ggml_tensor * lmh_b; // language model bias |
|---|
| | | |
|---|
| | | std::vector<gpt_neox_layer> layers; |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | struct ggml_tensor * memory_k; |
|---|
| | | struct ggml_tensor * memory_v; |
|---|
| | | |
|---|
| | | // |
|---|
| | | struct ggml_context * ctx; |
|---|
| | | std::map<std::string, struct ggml_tensor *> tensors; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // load the model's weights from a file |
|---|
| | | bool gpt_neox_model_load(const std::string & fname, gpt_neox_model & model, gpt_vocab & vocab) { |
|---|
| | | printf("%s: loading model from '%s' - please wait ...\n", __func__, fname.c_str()); |
|---|
| | | |
|---|
| | | auto fin = std::ifstream(fname, std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | fin.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fin.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fin.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fin.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fin.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fin.read((char *) &hparams.n_rot, sizeof(hparams.n_rot)); |
|---|
| | | fin.read((char *) &hparams.par_res, sizeof(hparams.par_res)); |
|---|
| | | fin.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: n_rot = %d\n", __func__, hparams.n_rot); |
|---|
| | | printf("%s: par_res = %d\n", __func__, hparams.par_res); |
|---|
| | | printf("%s: ftype = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr = %d\n", __func__, qntvr); |
|---|
| | | |
|---|
| | | hparams.ftype %= GGML_QNT_VERSION_FACTOR; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | const int32_t n_vocab = model.hparams.n_vocab; |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | std::vector<char> buf(128); |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | fin.read((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | buf.resize(len); |
|---|
| | | fin.read((char *) buf.data(), len); |
|---|
| | | word.assign(buf.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for the big tensors, we have the option to store the data in 16-bit floats or quantized |
|---|
| | | // in order to save memory and also to speed up the computation |
|---|
| | | ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype)); |
|---|
| | | if (wtype == GGML_TYPE_COUNT) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n", |
|---|
| | | __func__, fname.c_str(), model.hparams.ftype); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto & ctx = model.ctx; |
|---|
| | | |
|---|
| | | size_t ctx_size = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const size_t n_embd = hparams.n_embd; |
|---|
| | | const size_t n_layer = hparams.n_layer; |
|---|
| | | const size_t n_ctx = hparams.n_ctx; |
|---|
| | | const size_t n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_g |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_b |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(wtype, n_embd*n_vocab); // wte |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(wtype, n_embd*n_vocab); // lmh_g |
|---|
| | | //ctx_size += ggml_row_size(GGML_TYPE_F32, n_vocab); // lmh_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_g |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 3*n_embd*n_embd)); // c_attn_attn_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 3*n_embd)); // c_attn_attn_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, n_embd*n_embd)); // c_attn_proj_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd*n_embd)); // c_attn_proj_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_2_g |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_2_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_fc_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, 4*n_embd)); // c_mlp_fc_b |
|---|
| | | |
|---|
| | | ctx_size += n_layer*(ggml_row_size(wtype, 4*n_embd*n_embd)); // c_mlp_proj_w |
|---|
| | | ctx_size += n_layer*(ggml_row_size(GGML_TYPE_F32, n_embd)); // c_mlp_proj_b |
|---|
| | | |
|---|
| | | ctx_size += n_ctx*n_layer*ggml_row_size(GGML_TYPE_F32, n_embd); // memory_k |
|---|
| | | ctx_size += n_ctx*n_layer*ggml_row_size(GGML_TYPE_F32, n_embd); // memory_v |
|---|
| | | |
|---|
| | | ctx_size += (6 + 16*n_layer)*1024; // object overhead |
|---|
| | | |
|---|
| | | printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // create the ggml context |
|---|
| | | { |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ ctx_size, |
|---|
| | | /*.mem_buffer =*/ NULL, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | model.ctx = ggml_init(params); |
|---|
| | | if (!model.ctx) { |
|---|
| | | fprintf(stderr, "%s: ggml_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // prepare memory for the weights |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | model.layers.resize(n_layer); |
|---|
| | | |
|---|
| | | model.wte = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | |
|---|
| | | model.ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | model.ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | model.lmh_g = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | //model.lmh_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_vocab); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["gpt_neox.embed_in.weight"] = model.wte; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.final_layer_norm.weight"] = model.ln_f_g; |
|---|
| | | model.tensors["gpt_neox.final_layer_norm.bias"] = model.ln_f_b; |
|---|
| | | |
|---|
| | | model.tensors["embed_out.weight"] = model.lmh_g; |
|---|
| | | //model.tensors["lm_head.bias"] = model.lmh_b; |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_layer; ++i) { |
|---|
| | | auto & layer = model.layers[i]; |
|---|
| | | |
|---|
| | | layer.ln_1_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_attn_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 3*n_embd); |
|---|
| | | layer.c_attn_attn_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 3*n_embd); |
|---|
| | | |
|---|
| | | layer.c_attn_proj_w = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | layer.c_attn_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.ln_2_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ln_2_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_fc_w = ggml_new_tensor_2d(ctx, wtype, n_embd, 4*n_embd); |
|---|
| | | layer.c_mlp_fc_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_embd); |
|---|
| | | |
|---|
| | | layer.c_mlp_proj_w = ggml_new_tensor_2d(ctx, wtype, 4*n_embd, n_embd); |
|---|
| | | layer.c_mlp_proj_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".input_layernorm.weight"] = layer.ln_1_g; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".input_layernorm.bias"] = layer.ln_1_b; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.query_key_value.weight"] = layer.c_attn_attn_w; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.query_key_value.bias"] = layer.c_attn_attn_b; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.dense.weight"] = layer.c_attn_proj_w; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".attention.dense.bias"] = layer.c_attn_proj_b; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".post_attention_layernorm.weight"] = layer.ln_2_g; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".post_attention_layernorm.bias"] = layer.ln_2_b; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_h_to_4h.weight"] = layer.c_mlp_fc_w; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_h_to_4h.bias"] = layer.c_mlp_fc_b; |
|---|
| | | |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_4h_to_h.weight"] = layer.c_mlp_proj_w; |
|---|
| | | model.tensors["gpt_neox.layers." + std::to_string(i) + ".mlp.dense_4h_to_h.bias"] = layer.c_mlp_proj_b; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | |
|---|
| | | const int64_t n_mem = n_layer*n_ctx; |
|---|
| | | const int64_t n_elements = n_embd*n_mem; |
|---|
| | | |
|---|
| | | model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements); |
|---|
| | | model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements); |
|---|
| | | |
|---|
| | | const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v); |
|---|
| | | |
|---|
| | | printf("%s: memory_size = %8.2f MB, n_mem = %" PRId64 "\n", __func__, memory_size/1024.0/1024.0, n_mem); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load weights |
|---|
| | | { |
|---|
| | | int n_tensors = 0; |
|---|
| | | size_t total_size = 0; |
|---|
| | | |
|---|
| | | printf("%s: ", __func__); |
|---|
| | | |
|---|
| | | while (true) { |
|---|
| | | int32_t n_dims; |
|---|
| | | int32_t length; |
|---|
| | | int32_t ttype; |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&length), sizeof(length)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype)); |
|---|
| | | |
|---|
| | | if (fin.eof()) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int32_t nelements = 1; |
|---|
| | | int32_t ne[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i])); |
|---|
| | | nelements *= ne[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string name(length, 0); |
|---|
| | | fin.read(&name[0], length); |
|---|
| | | |
|---|
| | | if (model.tensors.find(name) == model.tensors.end()) { |
|---|
| | | fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto tensor = model.tensors[name]; |
|---|
| | | if (ggml_nelements(tensor) != nelements) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong shape in model file: got [%5d, %5d], expected [%5d, %5d]\n", |
|---|
| | | __func__, name.c_str(), (int) tensor->ne[0], (int) tensor->ne[1], ne[0], ne[1]); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for debugging |
|---|
| | | if (0) { |
|---|
| | | printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.c_str(), ne[0], ne[1], ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor)/1024.0/1024.0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const size_t bpe = ggml_type_size(ggml_type(ttype)); |
|---|
| | | |
|---|
| | | if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n", |
|---|
| | | __func__, name.c_str(), ggml_nbytes(tensor), nelements*bpe); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor)); |
|---|
| | | |
|---|
| | | total_size += ggml_nbytes(tensor); |
|---|
| | | if (++n_tensors % 8 == 0) { |
|---|
| | | printf("."); |
|---|
| | | fflush(stdout); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf(" done\n"); |
|---|
| | | |
|---|
| | | printf("%s: model size = %8.2f MB / num tensors = %d\n", __func__, total_size/1024.0/1024.0, n_tensors); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | |
|---|
| | | // feed-forward network |
|---|
| | | ggml_tensor * gpt_neox_ff( |
|---|
| | | const gpt_neox_layer & layer, |
|---|
| | | ggml_context * ctx0, |
|---|
| | | ggml_tensor * inp, |
|---|
| | | float eps) { |
|---|
| | | ggml_tensor * cur = ggml_norm(ctx0, inp, eps); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, layer.ln_2_g, cur), |
|---|
| | | cur), |
|---|
| | | ggml_repeat(ctx0, layer.ln_2_b, cur)); |
|---|
| | | |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | layer.c_mlp_fc_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, layer.c_mlp_fc_b, cur), |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | // GELU activation |
|---|
| | | cur = ggml_gelu(ctx0, cur); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | layer.c_mlp_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, layer.c_mlp_proj_b, cur), |
|---|
| | | cur); |
|---|
| | | return cur; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // evaluate the transformer |
|---|
| | | // |
|---|
| | | // - model: the model |
|---|
| | | // - n_threads: number of threads to use |
|---|
| | | // - n_past: the context size so far |
|---|
| | | // - embd_inp: the embeddings of the tokens in the context |
|---|
| | | // - embd_w: the predicted logits for the next token |
|---|
| | | // |
|---|
| | | bool gpt_neox_eval( |
|---|
| | | const gpt_neox_model & model, |
|---|
| | | const int n_threads, |
|---|
| | | const int n_past, |
|---|
| | | const std::vector<gpt_vocab::id> & embd_inp, |
|---|
| | | std::vector<float> & embd_w, |
|---|
| | | size_t & mem_per_token) { |
|---|
| | | const int N = embd_inp.size(); |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.n_embd; |
|---|
| | | const int n_layer = hparams.n_layer; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const int n_head = hparams.n_head; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | const int n_rot = hparams.n_rot; |
|---|
| | | |
|---|
| | | static size_t buf_size = 256u*1024*1024; |
|---|
| | | static void * buf = malloc(buf_size); |
|---|
| | | |
|---|
| | | // use 2 scratch buffers |
|---|
| | | // TODO: very hacky solution - reimplement in a more elegant way |
|---|
| | | static size_t scr0_size = 256u*1024*1024; |
|---|
| | | static void * scr0 = malloc(scr0_size); |
|---|
| | | |
|---|
| | | static size_t scr1_size = 256u*1024*1024; |
|---|
| | | static void * scr1 = malloc(scr1_size); |
|---|
| | | |
|---|
| | | if (mem_per_token > 0 && mem_per_token*N > buf_size) { |
|---|
| | | const size_t buf_size_new = 1.1*(mem_per_token*N); // add 10% to account for ggml object overhead |
|---|
| | | //printf("\n%s: reallocating buffer from %zu to %zu bytes\n", __func__, buf_size, buf_size_new); |
|---|
| | | |
|---|
| | | // reallocate |
|---|
| | | buf_size = buf_size_new; |
|---|
| | | buf = realloc(buf, buf_size); |
|---|
| | | if (buf == nullptr) { |
|---|
| | | fprintf(stderr, "%s: failed to allocate %zu bytes\n", __func__, buf_size); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx0 = ggml_init(params); |
|---|
| | | struct ggml_cgraph * gf = ggml_new_graph(ctx0); |
|---|
| | | |
|---|
| | | // KQ_pos - contains the positions |
|---|
| | | struct ggml_tensor * KQ_pos = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | int * data = (int *) KQ_pos->data; |
|---|
| | | for (int i = 0; i < N; ++i) { |
|---|
| | | data[i] = n_past + i; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | memcpy(embd->data, embd_inp.data(), N*ggml_element_size(embd)); |
|---|
| | | |
|---|
| | | // wte |
|---|
| | | struct ggml_tensor * inpL = ggml_get_rows(ctx0, model.wte, embd); |
|---|
| | | |
|---|
| | | for (int il = 0; il < n_layer; ++il) { |
|---|
| | | struct ggml_tensor * cur; |
|---|
| | | |
|---|
| | | ggml_set_scratch(ctx0, { 0, scr0_size, scr0, }); |
|---|
| | | |
|---|
| | | // self-attention |
|---|
| | | { |
|---|
| | | { |
|---|
| | | cur = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_1_g, cur), |
|---|
| | | cur), |
|---|
| | | ggml_repeat(ctx0, model.layers[il].ln_1_b, cur)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // compute QKV |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_attn_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.layers[il].c_attn_attn_b, cur), |
|---|
| | | cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * Qcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 0*sizeof(float)*n_embd/n_head)); |
|---|
| | | struct ggml_tensor * Kcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 1*sizeof(float)*n_embd/n_head)); |
|---|
| | | struct ggml_tensor * Vcur = ggml_cont(ctx0, ggml_view_3d(ctx0, cur, n_embd/n_head, n_head, N, cur->nb[1]/n_head, cur->nb[1], 2*sizeof(float)*n_embd/n_head)); |
|---|
| | | |
|---|
| | | // using mode = 2 for GPT-NeoX mode |
|---|
| | | Qcur = ggml_rope_inplace(ctx0, Qcur, KQ_pos, n_rot, 2, 0); |
|---|
| | | Kcur = ggml_rope_inplace(ctx0, Kcur, KQ_pos, n_rot, 2, 0); |
|---|
| | | |
|---|
| | | // store key and value to memory |
|---|
| | | { |
|---|
| | | Vcur = ggml_transpose(ctx0, ggml_reshape_2d(ctx0, Vcur, n_embd, N)); |
|---|
| | | |
|---|
| | | struct ggml_tensor * k = ggml_view_1d(ctx0, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past)); |
|---|
| | | struct ggml_tensor * v = ggml_view_2d(ctx0, model.memory_v, N, n_embd, |
|---|
| | | ( n_ctx)*ggml_element_size(model.memory_v), |
|---|
| | | (il*n_ctx)*ggml_element_size(model.memory_v)*n_embd + n_past*ggml_element_size(model.memory_v)); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, 2, 1, 3) |
|---|
| | | struct ggml_tensor * Q = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | Qcur, |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, 3) |
|---|
| | | struct ggml_tensor * K = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd), |
|---|
| | | n_embd/n_head, n_head, n_past + N), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // K * Q |
|---|
| | | struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); |
|---|
| | | |
|---|
| | | // KQ_scaled = KQ / sqrt(n_embd/n_head) |
|---|
| | | struct ggml_tensor * KQ_scaled = |
|---|
| | | ggml_scale_inplace(ctx0, |
|---|
| | | KQ, |
|---|
| | | 1.0f/sqrt(float(n_embd)/n_head)); |
|---|
| | | |
|---|
| | | // KQ_masked = mask_past(KQ_scaled) |
|---|
| | | struct ggml_tensor * KQ_masked = ggml_diag_mask_inf_inplace(ctx0, KQ_scaled, n_past); |
|---|
| | | |
|---|
| | | // KQ = soft_max(KQ_masked) |
|---|
| | | struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked); |
|---|
| | | |
|---|
| | | // V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, 2, 0, 3).contiguous() |
|---|
| | | struct ggml_tensor * V = |
|---|
| | | ggml_view_3d(ctx0, model.memory_v, |
|---|
| | | n_past + N, n_embd/n_head, n_head, |
|---|
| | | n_ctx*ggml_element_size(model.memory_v), |
|---|
| | | n_ctx*ggml_element_size(model.memory_v)*n_embd/n_head, |
|---|
| | | il*n_ctx*ggml_element_size(model.memory_v)*n_embd); |
|---|
| | | |
|---|
| | | // KQV = transpose(V) * KQ_soft_max |
|---|
| | | struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max); |
|---|
| | | |
|---|
| | | // KQV_merged = KQV.permute(0, 2, 1, 3) |
|---|
| | | struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // cur = KQV_merged.contiguous().view(n_embd, N) |
|---|
| | | cur = ggml_cpy(ctx0, |
|---|
| | | KQV_merged, |
|---|
| | | ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N)); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | { |
|---|
| | | cur = ggml_mul_mat(ctx0, |
|---|
| | | model.layers[il].c_attn_proj_w, |
|---|
| | | cur); |
|---|
| | | |
|---|
| | | cur = ggml_add(ctx0, ggml_repeat(ctx0, model.layers[il].c_attn_proj_b, cur), cur); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_set_scratch(ctx0, { 0, scr1_size, scr1, }); |
|---|
| | | |
|---|
| | | if (hparams.par_res == 0) { |
|---|
| | | struct ggml_tensor * inpFF = ggml_add(ctx0, cur, inpL); |
|---|
| | | |
|---|
| | | cur = gpt_neox_ff(model.layers[il], ctx0, inpFF, hparams.eps); |
|---|
| | | |
|---|
| | | // input for next layer |
|---|
| | | inpL = ggml_add(ctx0, cur, inpFF); |
|---|
| | | } else { |
|---|
| | | struct ggml_tensor * inpFF = cur; |
|---|
| | | |
|---|
| | | // this is independent of the self-attention result, so it could be done in parallel to the self-attention |
|---|
| | | // note here we pass inpL instead of cur |
|---|
| | | cur = gpt_neox_ff(model.layers[il], ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // layer input + FF |
|---|
| | | cur = ggml_add(ctx0, cur, inpFF); |
|---|
| | | |
|---|
| | | // input for next layer |
|---|
| | | inpL = ggml_add(ctx0, cur, inpL); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_set_scratch(ctx0, { 0, scr0_size, scr0, }); |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | inpL = ggml_norm(ctx0, inpL, hparams.eps); |
|---|
| | | |
|---|
| | | // inpL = ln_f_g*inpL + ln_f_b |
|---|
| | | inpL = ggml_add(ctx0, |
|---|
| | | ggml_mul(ctx0, |
|---|
| | | ggml_repeat(ctx0, model.ln_f_g, inpL), |
|---|
| | | inpL), |
|---|
| | | ggml_repeat(ctx0, model.ln_f_b, inpL)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_set_scratch(ctx0, { 0, 0, nullptr, }); |
|---|
| | | |
|---|
| | | // lm_head |
|---|
| | | { |
|---|
| | | inpL = ggml_mul_mat(ctx0, model.lmh_g, inpL); |
|---|
| | | |
|---|
| | | //inpL = ggml_add(ctx0, |
|---|
| | | // ggml_repeat(ctx0, model.lmh_b, inpL), |
|---|
| | | // inpL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // logits -> probs |
|---|
| | | //inpL = ggml_soft_max_inplace(ctx0, inpL); |
|---|
| | | |
|---|
| | | // run the computation |
|---|
| | | ggml_build_forward_expand(gf, inpL); |
|---|
| | | ggml_graph_compute_with_ctx(ctx0, gf, n_threads); |
|---|
| | | |
|---|
| | | //if (n_past%100 == 0) { |
|---|
| | | // ggml_graph_print (&gf); |
|---|
| | | // ggml_graph_dump_dot(&gf, NULL, "gpt-2.dot"); |
|---|
| | | //} |
|---|
| | | |
|---|
| | | //embd_w.resize(n_vocab*N); |
|---|
| | | //memcpy(embd_w.data(), ggml_get_data(inpL), sizeof(float)*n_vocab*N); |
|---|
| | | |
|---|
| | | // return result for just the last token |
|---|
| | | embd_w.resize(n_vocab); |
|---|
| | | memcpy(embd_w.data(), (float *) ggml_get_data(inpL) + (n_vocab*(N-1)), sizeof(float)*n_vocab); |
|---|
| | | |
|---|
| | | if (mem_per_token == 0) { |
|---|
| | | mem_per_token = ggml_used_mem(ctx0)/N; |
|---|
| | | } |
|---|
| | | //printf("used_mem = %zu\n", ggml_used_mem(ctx0)); |
|---|
| | | |
|---|
| | | ggml_free(ctx0); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | gpt_params params; |
|---|
| | | params.model = "models/stablelm-base-alpha-3b/ggml-model-f16.bin"; |
|---|
| | | |
|---|
| | | if (gpt_params_parse(argc, argv, params) == false) { |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.seed < 0) { |
|---|
| | | params.seed = time(NULL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: seed = %d\n", __func__, params.seed); |
|---|
| | | |
|---|
| | | std::mt19937 rng(params.seed); |
|---|
| | | if (params.prompt.empty()) { |
|---|
| | | params.prompt = gpt_random_prompt(rng); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int64_t t_load_us = 0; |
|---|
| | | |
|---|
| | | gpt_vocab vocab; |
|---|
| | | gpt_neox_model model; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt_neox_model_load(params.model, model, vocab)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | test_gpt_tokenizer(vocab, params.token_test); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int n_past = 0; |
|---|
| | | |
|---|
| | | int64_t t_sample_us = 0; |
|---|
| | | int64_t t_predict_us = 0; |
|---|
| | | |
|---|
| | | std::vector<float> logits; |
|---|
| | | |
|---|
| | | // tokenize the prompt |
|---|
| | | std::vector<gpt_vocab::id> embd_inp = ::gpt_tokenize(vocab, params.prompt); |
|---|
| | | |
|---|
| | | params.n_predict = std::min(params.n_predict, model.hparams.n_ctx - (int) embd_inp.size()); |
|---|
| | | |
|---|
| | | printf("%s: number of tokens in prompt = %zu\n", __func__, embd_inp.size()); |
|---|
| | | for (size_t i = 0; i < embd_inp.size(); i++) { |
|---|
| | | printf("%s: token[%zu] = %6d, %s\n", __func__, i, embd_inp[i], vocab.id_to_token.at(embd_inp[i]).c_str()); |
|---|
| | | } |
|---|
| | | printf("\n"); |
|---|
| | | |
|---|
| | | std::vector<gpt_vocab::id> embd; |
|---|
| | | |
|---|
| | | // determine the required inference memory per token: |
|---|
| | | size_t mem_per_token = 0; |
|---|
| | | gpt_neox_eval(model, params.n_threads, 0, { 0, 1, 2, 3 }, logits, mem_per_token); |
|---|
| | | |
|---|
| | | for (size_t i = embd.size(); i < embd_inp.size() + params.n_predict; i++) { |
|---|
| | | // predict |
|---|
| | | if (embd.size() > 0) { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt_neox_eval(model, params.n_threads, n_past, embd, logits, mem_per_token)) { |
|---|
| | | printf("Failed to predict\n"); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_predict_us += ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | n_past += embd.size(); |
|---|
| | | embd.clear(); |
|---|
| | | |
|---|
| | | if (i >= embd_inp.size()) { |
|---|
| | | // sample next token |
|---|
| | | const int top_k = params.top_k; |
|---|
| | | const float top_p = params.top_p; |
|---|
| | | const float temp = params.temp; |
|---|
| | | |
|---|
| | | const int n_vocab = model.hparams.n_vocab; |
|---|
| | | |
|---|
| | | gpt_vocab::id id = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const int64_t t_start_sample_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | id = gpt_sample_top_k_top_p(vocab, logits.data() + (logits.size() - n_vocab), top_k, top_p, temp, rng); |
|---|
| | | |
|---|
| | | t_sample_us += ggml_time_us() - t_start_sample_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add it to the context |
|---|
| | | embd.push_back(id); |
|---|
| | | } else { |
|---|
| | | // if here, it means we are still processing the input prompt |
|---|
| | | for (size_t k = i; k < embd_inp.size(); k++) { |
|---|
| | | embd.push_back(embd_inp[k]); |
|---|
| | | if (int32_t(embd.size()) > params.n_batch) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | i += embd.size() - 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // display text |
|---|
| | | for (auto id : embd) { |
|---|
| | | printf("%s", vocab.id_to_token[id].c_str()); |
|---|
| | | } |
|---|
| | | fflush(stdout); |
|---|
| | | |
|---|
| | | // end of text token |
|---|
| | | if (embd.back() == 0) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n\n"); |
|---|
| | | printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token); |
|---|
| | | printf("%s: load time = %8.2f ms\n", __func__, t_load_us/1000.0f); |
|---|
| | | printf("%s: sample time = %8.2f ms\n", __func__, t_sample_us/1000.0f); |
|---|
| | | printf("%s: predict time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us/1000.0f, t_predict_us/1000.0f/n_past); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | #include "common-ggml.h" |
|---|
| | | |
|---|
| | | #include <cassert> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | #include <regex> |
|---|
| | | |
|---|
| | | // default hparams (StableLM 3B) |
|---|
| | | struct gpt_neox_hparams { |
|---|
| | | int32_t n_vocab = 50257; |
|---|
| | | int32_t n_ctx = 4096; |
|---|
| | | int32_t n_embd = 4096; |
|---|
| | | int32_t n_head = 32; |
|---|
| | | int32_t n_layer = 16; |
|---|
| | | int32_t n_rot = 32; // 0.25 * (n_embd / n_head) |
|---|
| | | int32_t par_res = 1; // 1 = true, 0 = false |
|---|
| | | int32_t ftype = 1; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // quantize a model |
|---|
| | | bool gpt_neox_model_quantize(const std::string & fname_inp, const std::string & fname_out, ggml_ftype ftype) { |
|---|
| | | gpt_vocab vocab; |
|---|
| | | |
|---|
| | | printf("%s: loading model from '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | |
|---|
| | | auto finp = std::ifstream(fname_inp, std::ios::binary); |
|---|
| | | if (!finp) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s' for reading\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto fout = std::ofstream(fname_out, std::ios::binary); |
|---|
| | | if (!fout) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s' for writing\n", __func__, fname_out.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | finp.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | fout.write((char *) &magic, sizeof(magic)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | gpt_neox_hparams hparams; |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | finp.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | finp.read((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | finp.read((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | finp.read((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | finp.read((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | finp.read((char *) &hparams.n_rot, sizeof(hparams.n_rot)); |
|---|
| | | finp.read((char *) &hparams.par_res, sizeof(hparams.par_res)); |
|---|
| | | finp.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | const int32_t qntvr_src = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | const int32_t ftype_dst = GGML_QNT_VERSION * GGML_QNT_VERSION_FACTOR + ftype; |
|---|
| | | |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_embd = %d\n", __func__, hparams.n_embd); |
|---|
| | | printf("%s: n_head = %d\n", __func__, hparams.n_head); |
|---|
| | | printf("%s: n_layer = %d\n", __func__, hparams.n_layer); |
|---|
| | | printf("%s: par_res = %d\n", __func__, hparams.par_res); |
|---|
| | | printf("%s: ftype (src) = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr (src) = %d\n", __func__, qntvr_src); |
|---|
| | | printf("%s: ftype (dst) = %d\n", __func__, ftype_dst); |
|---|
| | | printf("%s: qntvr (dst) = %d\n", __func__, GGML_QNT_VERSION); |
|---|
| | | |
|---|
| | | fout.write((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fout.write((char *) &hparams.n_ctx, sizeof(hparams.n_ctx)); |
|---|
| | | fout.write((char *) &hparams.n_embd, sizeof(hparams.n_embd)); |
|---|
| | | fout.write((char *) &hparams.n_head, sizeof(hparams.n_head)); |
|---|
| | | fout.write((char *) &hparams.n_layer, sizeof(hparams.n_layer)); |
|---|
| | | fout.write((char *) &hparams.n_rot, sizeof(hparams.n_rot)); |
|---|
| | | fout.write((char *) &hparams.par_res, sizeof(hparams.par_res)); |
|---|
| | | fout.write((char *) &ftype_dst, sizeof(ftype_dst)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | const int32_t n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | finp.read ((char *) &len, sizeof(len)); |
|---|
| | | fout.write((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | word.resize(len); |
|---|
| | | finp.read ((char *) word.data(), len); |
|---|
| | | fout.write((char *) word.data(), len); |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // regexes of tensor names to be quantized |
|---|
| | | const std::vector<std::string> to_quant = { |
|---|
| | | ".*weight", |
|---|
| | | }; |
|---|
| | | |
|---|
| | | if (!ggml_common_quantize_0(finp, fout, ftype, to_quant, {})) { |
|---|
| | | fprintf(stderr, "%s: failed to quantize model '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | finp.close(); |
|---|
| | | fout.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // usage: |
|---|
| | | // ./gpt-neox-quantize models/stalellm2-117M/ggml-model.bin models/stablelm2-117M/ggml-model-quant.bin type |
|---|
| | | // |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | if (argc != 4) { |
|---|
| | | fprintf(stderr, "usage: %s model-f32.bin model-quant.bin type\n", argv[0]); |
|---|
| | | ggml_print_ftypes(stderr); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // needed to initialize f16 tables |
|---|
| | | { |
|---|
| | | struct ggml_init_params params = { 0, NULL, false }; |
|---|
| | | struct ggml_context * ctx = ggml_init(params); |
|---|
| | | ggml_free(ctx); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const std::string fname_inp = argv[1]; |
|---|
| | | const std::string fname_out = argv[2]; |
|---|
| | | |
|---|
| | | const ggml_ftype ftype = ggml_parse_ftype(argv[3]); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | int64_t t_quantize_us = 0; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!gpt_neox_model_quantize(fname_inp, fname_out, ggml_ftype(ftype))) { |
|---|
| | | fprintf(stderr, "%s: failed to quantize model from '%s'\n", __func__, fname_inp.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_quantize_us = ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n"); |
|---|
| | | printf("%s: quantize time = %8.2f ms\n", __func__, t_quantize_us/1000.0f); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us)/1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | # |
|---|
| | | # mnist |
|---|
| | | |
|---|
| | | set(TEST_TARGET mnist) |
|---|
| | | add_executable(${TEST_TARGET} main.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common) |
|---|
| | | |
|---|
| | | # |
|---|
| | | # mnist-cnn |
|---|
| | | |
|---|
| | | set(TEST_TARGET mnist-cnn) |
|---|
| | | add_executable(${TEST_TARGET} main-cnn.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common) |
|---|
| | | |
|---|
| | | # |
|---|
| | | # mnist-cpu |
|---|
| | | |
|---|
| | | set(TEST_TARGET mnist-cpu) |
|---|
| | | add_executable(${TEST_TARGET} main-cpu.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml) |
|---|
| | | |
|---|
| | | if (APPLE) |
|---|
| | | # |
|---|
| | | # mnist-mtl |
|---|
| | | |
|---|
| | | find_library(FOUNDATION_LIBRARY Foundation REQUIRED) |
|---|
| | | find_library(METAL_FRAMEWORK Metal REQUIRED) |
|---|
| | | find_library(METALKIT_FRAMEWORK MetalKit REQUIRED) |
|---|
| | | find_library(METALPERFORMANCE_FRAMEWORK MetalPerformanceShaders REQUIRED) |
|---|
| | | |
|---|
| | | set(TEST_TARGET mnist-mtl) |
|---|
| | | add_executable(${TEST_TARGET} main-mtl.cpp main-mtl.h main-mtl.m) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE |
|---|
| | | ggml |
|---|
| | | ${FOUNDATION_LIBRARY} |
|---|
| | | ${METAL_FRAMEWORK} |
|---|
| | | ${METALKIT_FRAMEWORK} |
|---|
| | | ${METALPERFORMANCE_FRAMEWORK} |
|---|
| | | ) |
|---|
| | | endif() |
|---|
| New file |
| | |
|---|
| | | # MNIST Examples for GGML |
|---|
| | | |
|---|
| | | These are simple examples of how to use GGML for inferencing. |
|---|
| | | The first example uses convolutional neural network (CNN), the second one uses fully connected neural network. |
|---|
| | | |
|---|
| | | ## Building the examples |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | git clone https://github.com/ggerganov/ggml |
|---|
| | | cd ggml |
|---|
| | | mkdir build && cd build |
|---|
| | | cmake .. |
|---|
| | | make -j4 mnist-cnn mnist |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ## MNIST with CNN |
|---|
| | | |
|---|
| | | This implementation achieves ~99% accuracy on the MNIST test set. |
|---|
| | | |
|---|
| | | ### Training the model |
|---|
| | | |
|---|
| | | Use the `mnist-cnn.py` script to train the model and convert it to GGUF format: |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | $ python3 ../examples/mnist/mnist-cnn.py train mnist-cnn-model |
|---|
| | | ... |
|---|
| | | Keras model saved to 'mnist-cnn-model' |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | Convert the model to GGUF format: |
|---|
| | | |
|---|
| | | ``` |
|---|
| | | $ python3 ../examples/mnist/mnist-cnn.py convert mnist-cnn-model |
|---|
| | | ... |
|---|
| | | Model converted and saved to 'mnist-cnn-model.gguf' |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ### Running the example |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | $ ./bin/mnist-cnn mnist-cnn-model.gguf ../examples/mnist/models/mnist/t10k-images.idx3-ubyte |
|---|
| | | main: loaded model in 5.17 ms |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ * * * * * _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ _ _ * * * * * * * * _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ * * * * * _ _ _ * * _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ * _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ * * _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ * * _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ * * * _ _ _ _ * * * * * _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ * * * * * * * * * _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ * * * * * * * * * * _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ * * * * * * _ _ * * * _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ * * * _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ * * _ _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ * * * _ _ _ _ _ _ * * * _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ * * * * * * * * * * _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ * * * * * * _ _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ |
|---|
| | | _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ |
|---|
| | | |
|---|
| | | ggml_graph_dump_dot: dot -Tpng mnist-cnn.dot -o mnist-cnn.dot.png && open mnist-cnn.dot.png |
|---|
| | | main: predicted digit is 8 |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | Computation graph: |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| | | ## MNIST with fully connected network |
|---|
| | | |
|---|
| | | A fully connected layer + relu, followed by a fully connected layer + softmax. |
|---|
| | | |
|---|
| | | ### Training the Model |
|---|
| | | |
|---|
| | | A Google Colab notebook for training a simple two-layer network to recognize digits is located here. You can |
|---|
| | | use this to save a pytorch model to be converted to ggml format. |
|---|
| | | |
|---|
| | | [Colab](https://colab.research.google.com/drive/12n_8VNJnolBnX5dVS0HNWubnOjyEaFSb?usp=sharing) |
|---|
| | | |
|---|
| | | GGML "format" is whatever you choose for efficient loading. In our case, we just save the hyperparameters used |
|---|
| | | plus the model weights and biases. Run convert-h5-to-ggml.py to convert your pytorch model. The output format is: |
|---|
| | | |
|---|
| | | - magic constant (int32) |
|---|
| | | - repeated list of tensors |
|---|
| | | - number of dimensions of tensor (int32) |
|---|
| | | - tensor dimension (int32 repeated) |
|---|
| | | - values of tensor (int32) |
|---|
| | | |
|---|
| | | Run ```convert-h5-to-ggml.py mnist_model.state_dict``` where `mnist_model.state_dict` is the saved pytorch model from the Google Colab. For |
|---|
| | | quickstart, it is included in the mnist/models directory. |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | mkdir -p models/mnist |
|---|
| | | python3 ../examples/mnist/convert-h5-to-ggml.py ../examples/mnist/models/mnist/mnist_model.state_dict |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | ### Running the example |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | ./bin/mnist ./models/mnist/ggml-model-f32.bin ../examples/mnist/models/mnist/t10k-images.idx3-ubyte |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | Computation graph: |
|---|
| | | |
|---|
| | |  |
|---|
| | | |
|---|
| | | |
|---|
| | | ## Web demo |
|---|
| | | |
|---|
| | | The example can be compiled with Emscripten like this: |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | cd examples/mnist |
|---|
| | | emcc -I../../include -I../../include/ggml -I../../examples ../../src/ggml.c main.cpp -o web/mnist.js -s EXPORTED_FUNCTIONS='["_wasm_eval","_wasm_random_digit","_malloc","_free"]' -s EXPORTED_RUNTIME_METHODS='["ccall"]' -s ALLOW_MEMORY_GROWTH=1 --preload-file models/mnist |
|---|
| | | ``` |
|---|
| | | |
|---|
| | | Online demo: https://mnist.ggerganov.com |
|---|
| New file |
| | |
|---|
| | | # Convert MNIS h5 transformer model to ggml format |
|---|
| | | # |
|---|
| | | # Load the (state_dict) saved model using PyTorch |
|---|
| | | # Iterate over all variables and write them to a binary file. |
|---|
| | | # |
|---|
| | | # For each variable, write the following: |
|---|
| | | # - Number of dimensions (int) |
|---|
| | | # - Name length (int) |
|---|
| | | # - Dimensions (int[n_dims]) |
|---|
| | | # - Name (char[name_length]) |
|---|
| | | # - Data (float[n_dims]) |
|---|
| | | # |
|---|
| | | # At the start of the ggml file we write the model parameters |
|---|
| | | |
|---|
| | | import sys |
|---|
| | | import struct |
|---|
| | | import json |
|---|
| | | import numpy as np |
|---|
| | | import re |
|---|
| | | |
|---|
| | | |
|---|
| | | import torch |
|---|
| | | import torch.nn as nn |
|---|
| | | import torchvision.datasets as dsets |
|---|
| | | import torchvision.transforms as transforms |
|---|
| | | from torch.autograd import Variable |
|---|
| | | |
|---|
| | | if len(sys.argv) != 2: |
|---|
| | | print("Usage: convert-h5-to-ggml.py model\n") |
|---|
| | | sys.exit(1) |
|---|
| | | |
|---|
| | | state_dict_file = sys.argv[1] |
|---|
| | | fname_out = "models/mnist/ggml-model-f32.bin" |
|---|
| | | |
|---|
| | | state_dict = torch.load(state_dict_file, map_location=torch.device('cpu')) |
|---|
| | | #print (model) |
|---|
| | | |
|---|
| | | list_vars = state_dict |
|---|
| | | print (list_vars) |
|---|
| | | |
|---|
| | | fout = open(fname_out, "wb") |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", 0x67676d6c)) # magic: ggml in hex |
|---|
| | | |
|---|
| | | |
|---|
| | | for name in list_vars.keys(): |
|---|
| | | data = list_vars[name].squeeze().numpy() |
|---|
| | | print("Processing variable: " + name + " with shape: ", data.shape) |
|---|
| | | n_dims = len(data.shape); |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", n_dims)) |
|---|
| | | |
|---|
| | | data = data.astype(np.float32) |
|---|
| | | for i in range(n_dims): |
|---|
| | | fout.write(struct.pack("i", data.shape[n_dims - 1 - i])) |
|---|
| | | |
|---|
| | | # data |
|---|
| | | data.tofile(fout) |
|---|
| | | |
|---|
| | | fout.close() |
|---|
| | | |
|---|
| | | print("Done. Output file: " + fname_out) |
|---|
| | | print("") |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <ctime> |
|---|
| | | #include <fstream> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | #include <algorithm> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | struct mnist_model { |
|---|
| | | struct ggml_tensor * conv2d_1_kernel; |
|---|
| | | struct ggml_tensor * conv2d_1_bias; |
|---|
| | | struct ggml_tensor * conv2d_2_kernel; |
|---|
| | | struct ggml_tensor * conv2d_2_bias; |
|---|
| | | struct ggml_tensor * dense_weight; |
|---|
| | | struct ggml_tensor * dense_bias; |
|---|
| | | struct ggml_context * ctx; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | bool mnist_model_load(const std::string & fname, mnist_model & model) { |
|---|
| | | struct gguf_init_params params = { |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | /*.ctx =*/ &model.ctx, |
|---|
| | | }; |
|---|
| | | gguf_context * ctx = gguf_init_from_file(fname.c_str(), params); |
|---|
| | | if (!ctx) { |
|---|
| | | fprintf(stderr, "%s: gguf_init_from_file() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | model.conv2d_1_kernel = ggml_get_tensor(model.ctx, "kernel1"); |
|---|
| | | model.conv2d_1_bias = ggml_get_tensor(model.ctx, "bias1"); |
|---|
| | | model.conv2d_2_kernel = ggml_get_tensor(model.ctx, "kernel2"); |
|---|
| | | model.conv2d_2_bias = ggml_get_tensor(model.ctx, "bias2"); |
|---|
| | | model.dense_weight = ggml_get_tensor(model.ctx, "dense_w"); |
|---|
| | | model.dense_bias = ggml_get_tensor(model.ctx, "dense_b"); |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int mnist_eval( |
|---|
| | | const mnist_model & model, |
|---|
| | | const int n_threads, |
|---|
| | | std::vector<float> digit, |
|---|
| | | const char * fname_cgraph |
|---|
| | | ) |
|---|
| | | { |
|---|
| | | static size_t buf_size = 100000 * sizeof(float) * 4; |
|---|
| | | static void * buf = malloc(buf_size); |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx0 = ggml_init(params); |
|---|
| | | struct ggml_cgraph * gf = ggml_new_graph(ctx0); |
|---|
| | | |
|---|
| | | struct ggml_tensor * input = ggml_new_tensor_4d(ctx0, GGML_TYPE_F32, 28, 28, 1, 1); |
|---|
| | | memcpy(input->data, digit.data(), ggml_nbytes(input)); |
|---|
| | | ggml_set_name(input, "input"); |
|---|
| | | ggml_tensor * cur = ggml_conv_2d(ctx0, model.conv2d_1_kernel, input, 1, 1, 0, 0, 1, 1); |
|---|
| | | cur = ggml_add(ctx0, cur, model.conv2d_1_bias); |
|---|
| | | cur = ggml_relu(ctx0, cur); |
|---|
| | | // Output shape after Conv2D: (26 26 32 1) |
|---|
| | | cur = ggml_pool_2d(ctx0, cur, GGML_OP_POOL_MAX, 2, 2, 2, 2, 0, 0); |
|---|
| | | // Output shape after MaxPooling2D: (13 13 32 1) |
|---|
| | | cur = ggml_conv_2d(ctx0, model.conv2d_2_kernel, cur, 1, 1, 0, 0, 1, 1); |
|---|
| | | cur = ggml_add(ctx0, cur, model.conv2d_2_bias); |
|---|
| | | cur = ggml_relu(ctx0, cur); |
|---|
| | | // Output shape after Conv2D: (11 11 64 1) |
|---|
| | | cur = ggml_pool_2d(ctx0, cur, GGML_OP_POOL_MAX, 2, 2, 2, 2, 0, 0); |
|---|
| | | // Output shape after MaxPooling2D: (5 5 64 1) |
|---|
| | | cur = ggml_cont(ctx0, ggml_permute(ctx0, cur, 1, 2, 0, 3)); |
|---|
| | | // Output shape after permute: (64 5 5 1) |
|---|
| | | cur = ggml_reshape_2d(ctx0, cur, 1600, 1); |
|---|
| | | // Final Dense layer |
|---|
| | | cur = ggml_add(ctx0, ggml_mul_mat(ctx0, model.dense_weight, cur), model.dense_bias); |
|---|
| | | ggml_tensor * probs = ggml_soft_max(ctx0, cur); |
|---|
| | | ggml_set_name(probs, "probs"); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, probs); |
|---|
| | | ggml_graph_compute_with_ctx(ctx0, gf, n_threads); |
|---|
| | | |
|---|
| | | //ggml_graph_print(&gf); |
|---|
| | | ggml_graph_dump_dot(gf, NULL, "mnist-cnn.dot"); |
|---|
| | | |
|---|
| | | if (fname_cgraph) { |
|---|
| | | // export the compute graph for later use |
|---|
| | | // see the "mnist-cpu" example |
|---|
| | | ggml_graph_export(gf, fname_cgraph); |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s: exported compute graph to '%s'\n", __func__, fname_cgraph); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const float * probs_data = ggml_get_data_f32(probs); |
|---|
| | | const int prediction = std::max_element(probs_data, probs_data + 10) - probs_data; |
|---|
| | | ggml_free(ctx0); |
|---|
| | | return prediction; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | srand(time(NULL)); |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | if (argc != 3) { |
|---|
| | | fprintf(stderr, "Usage: %s models/mnist/mnist-cnn.gguf models/mnist/t10k-images.idx3-ubyte\n", argv[0]); |
|---|
| | | exit(0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | uint8_t buf[784]; |
|---|
| | | mnist_model model; |
|---|
| | | std::vector<float> digit; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!mnist_model_load(argv[1], model)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, argv[1]); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | const int64_t t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | fprintf(stdout, "%s: loaded model in %8.2f ms\n", __func__, t_load_us / 1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // read a random digit from the test set |
|---|
| | | { |
|---|
| | | std::ifstream fin(argv[2], std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, argv[2]); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000) |
|---|
| | | fin.seekg(16 + 784 * (rand() % 10000)); |
|---|
| | | fin.read((char *) &buf, sizeof(buf)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // render the digit in ASCII |
|---|
| | | { |
|---|
| | | digit.resize(sizeof(buf)); |
|---|
| | | |
|---|
| | | for (int row = 0; row < 28; row++) { |
|---|
| | | for (int col = 0; col < 28; col++) { |
|---|
| | | fprintf(stderr, "%c ", (float)buf[row*28 + col] > 230 ? '*' : '_'); |
|---|
| | | digit[row*28 + col] = ((float)buf[row*28 + col] / 255.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const int prediction = mnist_eval(model, 1, digit, nullptr); |
|---|
| | | fprintf(stdout, "%s: predicted digit is %d\n", __func__, prediction); |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | // Use a pre-generated MNIST compute graph for inference on the CPU |
|---|
| | | // |
|---|
| | | // You can generate a compute graph using the "mnist" tool: |
|---|
| | | // |
|---|
| | | // $ ./bin/mnist ./models/mnist/ggml-model-f32.bin ../examples/mnist/models/mnist/t10k-images.idx3-ubyte |
|---|
| | | // |
|---|
| | | // This command creates the "mnist.ggml" file, which contains the generated compute graph. |
|---|
| | | // Now, you can re-use the compute graph with the "mnist-cpu" tool: |
|---|
| | | // |
|---|
| | | // $ ./bin/mnist-cpu ./models/mnist/mnist.ggml ../examples/mnist/models/mnist/t10k-images.idx3-ubyte |
|---|
| | | // |
|---|
| | | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include <algorithm> |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <ctime> |
|---|
| | | #include <fstream> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | // evaluate the MNIST compute graph |
|---|
| | | // |
|---|
| | | // - fname_cgraph: path to the compute graph |
|---|
| | | // - n_threads: number of threads to use |
|---|
| | | // - digit: 784 pixel values |
|---|
| | | // |
|---|
| | | // returns 0 - 9 prediction |
|---|
| | | int mnist_eval( |
|---|
| | | const char * fname_cgraph, |
|---|
| | | const int n_threads, |
|---|
| | | std::vector<float> digit) { |
|---|
| | | // load the compute graph |
|---|
| | | struct ggml_context * ctx_data = NULL; |
|---|
| | | struct ggml_context * ctx_eval = NULL; |
|---|
| | | |
|---|
| | | struct ggml_cgraph * gfi = ggml_graph_import(fname_cgraph, &ctx_data, &ctx_eval); |
|---|
| | | |
|---|
| | | // param export/import test |
|---|
| | | GGML_ASSERT(ggml_graph_get_tensor(gfi, "fc1_bias")->op_params[0] == int(0xdeadbeef)); |
|---|
| | | |
|---|
| | | // allocate work context |
|---|
| | | // needed during ggml_graph_compute() to allocate a work tensor |
|---|
| | | static size_t buf_size = 128ull*1024*1024; // TODO |
|---|
| | | static void * buf = malloc(buf_size); |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx_work = ggml_init(params); |
|---|
| | | |
|---|
| | | struct ggml_tensor * input = ggml_graph_get_tensor(gfi, "input"); |
|---|
| | | memcpy(input->data, digit.data(), ggml_nbytes(input)); |
|---|
| | | |
|---|
| | | ggml_graph_compute_with_ctx(ctx_work, gfi, n_threads); |
|---|
| | | |
|---|
| | | const float * probs_data = ggml_get_data_f32(ggml_graph_get_tensor(gfi, "probs")); |
|---|
| | | |
|---|
| | | const int prediction = std::max_element(probs_data, probs_data + 10) - probs_data; |
|---|
| | | |
|---|
| | | ggml_free(ctx_work); |
|---|
| | | ggml_free(ctx_data); |
|---|
| | | ggml_free(ctx_eval); |
|---|
| | | |
|---|
| | | return prediction; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | srand(time(NULL)); |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | if (argc != 3) { |
|---|
| | | fprintf(stderr, "Usage: %s models/mnist/mnist.ggml models/mnist/t10k-images.idx3-ubyte\n", argv[0]); |
|---|
| | | exit(0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | uint8_t buf[784]; |
|---|
| | | std::vector<float> digit; |
|---|
| | | |
|---|
| | | // read a random digit from the test set |
|---|
| | | { |
|---|
| | | std::ifstream fin(argv[2], std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, argv[2]); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000) |
|---|
| | | fin.seekg(16 + 784 * (rand() % 10000)); |
|---|
| | | fin.read((char *) &buf, sizeof(buf)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // render the digit in ASCII |
|---|
| | | { |
|---|
| | | digit.resize(sizeof(buf)); |
|---|
| | | |
|---|
| | | for (int row = 0; row < 28; row++) { |
|---|
| | | for (int col = 0; col < 28; col++) { |
|---|
| | | fprintf(stderr, "%c ", (float)buf[row*28 + col] > 230 ? '*' : '_'); |
|---|
| | | digit[row*28 + col] = ((float)buf[row*28 + col]); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const int prediction = mnist_eval(argv[1], 1, digit); |
|---|
| | | |
|---|
| | | fprintf(stdout, "%s: predicted digit is %d\n", __func__, prediction); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | // Use a pre-generated MNIST compute graph for inference on the M1 GPU via MPS |
|---|
| | | // |
|---|
| | | // You can generate a compute graph using the "mnist" tool: |
|---|
| | | // |
|---|
| | | // $ ./bin/mnist ./models/mnist/ggml-model-f32.bin ../examples/mnist/models/mnist/t10k-images.idx3-ubyte |
|---|
| | | // |
|---|
| | | // This command creates the "mnist.ggml" file, which contains the generated compute graph. |
|---|
| | | // Now, you can re-use the compute graph on the GPU with the "mnist-mtl" tool: |
|---|
| | | // |
|---|
| | | // $ ./bin/mnist-mtl ./models/mnist/mnist.ggml ../examples/mnist/models/mnist/t10k-images.idx3-ubyte |
|---|
| | | // |
|---|
| | | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "main-mtl.h" |
|---|
| | | |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <ctime> |
|---|
| | | #include <fstream> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | // evaluate the MNIST compute graph |
|---|
| | | // |
|---|
| | | // - fname_cgraph: path to the compute graph |
|---|
| | | // - digit: 784 pixel values |
|---|
| | | // |
|---|
| | | // returns 0 - 9 prediction |
|---|
| | | int mnist_eval( |
|---|
| | | const char * fname_cgraph, |
|---|
| | | std::vector<float> digit |
|---|
| | | ) { |
|---|
| | | // load the compute graph |
|---|
| | | struct ggml_context * ctx_data = NULL; |
|---|
| | | struct ggml_context * ctx_eval = NULL; |
|---|
| | | |
|---|
| | | struct ggml_cgraph * gf = ggml_graph_import(fname_cgraph, &ctx_data, &ctx_eval); |
|---|
| | | |
|---|
| | | // allocate work context |
|---|
| | | static size_t buf_size = 128ull*1024*1024; // TODO |
|---|
| | | static void * buf = malloc(buf_size); |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx_work = ggml_init(params); |
|---|
| | | |
|---|
| | | // this allocates all Metal resources and memory buffers |
|---|
| | | auto ctx_mtl = mnist_mtl_init(ctx_data, ctx_eval, ctx_work, gf); |
|---|
| | | |
|---|
| | | int prediction = -1; |
|---|
| | | |
|---|
| | | for (int i = 0; i < 1; ++i) { |
|---|
| | | struct ggml_tensor * input = ggml_graph_get_tensor(gf, "input"); |
|---|
| | | |
|---|
| | | if (i % 2 == 0) { |
|---|
| | | memcpy(input->data, digit.data(), ggml_nbytes(input)); |
|---|
| | | } else { |
|---|
| | | memset(input->data, 0, ggml_nbytes(input)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // the actual inference happens here |
|---|
| | | prediction = mnist_mtl_eval(ctx_mtl, gf); |
|---|
| | | } |
|---|
| | | |
|---|
| | | mnist_mtl_free(ctx_mtl); |
|---|
| | | |
|---|
| | | ggml_free(ctx_work); |
|---|
| | | ggml_free(ctx_data); |
|---|
| | | ggml_free(ctx_eval); |
|---|
| | | |
|---|
| | | return prediction; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | srand(time(NULL)); |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | if (argc != 3) { |
|---|
| | | fprintf(stderr, "Usage: %s models/mnist/mnist.ggml models/mnist/t10k-images.idx3-ubyte\n", argv[0]); |
|---|
| | | exit(0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | uint8_t buf[784]; |
|---|
| | | std::vector<float> digit; |
|---|
| | | |
|---|
| | | // read a random digit from the test set |
|---|
| | | { |
|---|
| | | std::ifstream fin(argv[2], std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, argv[2]); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000) |
|---|
| | | fin.seekg(16 + 784 * (rand() % 10000)); |
|---|
| | | fin.read((char *) &buf, sizeof(buf)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // render the digit in ASCII |
|---|
| | | { |
|---|
| | | digit.resize(sizeof(buf)); |
|---|
| | | |
|---|
| | | for (int row = 0; row < 28; row++) { |
|---|
| | | for (int col = 0; col < 28; col++) { |
|---|
| | | fprintf(stderr, "%c ", (float)buf[row*28 + col] > 230 ? '*' : '_'); |
|---|
| | | digit[row*28 + col] = ((float)buf[row*28 + col]); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const int prediction = mnist_eval(argv[1], digit); |
|---|
| | | |
|---|
| | | fprintf(stdout, "%s: predicted digit is %d\n", __func__, prediction); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #pragma once |
|---|
| | | |
|---|
| | | struct ggml_context; |
|---|
| | | struct ggml_cgraph; |
|---|
| | | |
|---|
| | | #ifdef __cplusplus |
|---|
| | | extern "C" { |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | struct ggml_mtl_context; |
|---|
| | | |
|---|
| | | struct ggml_mtl_context * mnist_mtl_init( |
|---|
| | | struct ggml_context * ctx_data, |
|---|
| | | struct ggml_context * ctx_eval, |
|---|
| | | struct ggml_context * ctx_work, |
|---|
| | | struct ggml_cgraph * gf); |
|---|
| | | |
|---|
| | | void mnist_mtl_free(struct ggml_mtl_context * ctx); |
|---|
| | | |
|---|
| | | int mnist_mtl_eval( |
|---|
| | | struct ggml_mtl_context * ctx, |
|---|
| | | struct ggml_cgraph * gf); |
|---|
| | | |
|---|
| | | #ifdef __cplusplus |
|---|
| | | } |
|---|
| | | #endif |
|---|
| New file |
| | |
|---|
| | | #import "main-mtl.h" |
|---|
| | | |
|---|
| | | #import "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #import <Foundation/Foundation.h> |
|---|
| | | #import <Metal/Metal.h> |
|---|
| | | #import <MetalPerformanceShaders/MetalPerformanceShaders.h> |
|---|
| | | |
|---|
| | | // TODO: couldn't get this to work |
|---|
| | | //#define GGML_MTL_HEAP |
|---|
| | | |
|---|
| | | struct ggml_mtl_context { |
|---|
| | | struct ggml_context * ctx_data; |
|---|
| | | struct ggml_context * ctx_eval; |
|---|
| | | struct ggml_context * ctx_work; |
|---|
| | | |
|---|
| | | id<MTLDevice> device; |
|---|
| | | id<MTLCommandQueue> queue; |
|---|
| | | id<MTLLibrary> library; |
|---|
| | | |
|---|
| | | #ifdef GGML_MTL_HEAP |
|---|
| | | id<MTLHeap> heap_data; |
|---|
| | | id<MTLHeap> heap_eval; |
|---|
| | | #else |
|---|
| | | id<MTLBuffer> buffer_data; |
|---|
| | | id<MTLBuffer> buffer_eval; |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | id<MTLBuffer> out; |
|---|
| | | |
|---|
| | | // custom kernels |
|---|
| | | id<MTLFunction> function_add; |
|---|
| | | id<MTLComputePipelineState> pipeline_add; |
|---|
| | | |
|---|
| | | id<MTLFunction> function_relu; |
|---|
| | | id<MTLComputePipelineState> pipeline_relu; |
|---|
| | | |
|---|
| | | id<MTLFunction> function_soft_max; |
|---|
| | | id<MTLComputePipelineState> pipeline_soft_max; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // MSL code |
|---|
| | | NSString * const msl_library_mnist = @"\ |
|---|
| | | #include <metal_stdlib> \n\ |
|---|
| | | using namespace metal; \n\ |
|---|
| | | \n\ |
|---|
| | | #define MAX(x, y) ((x) > (y) ? (x) : (y)) \n\ |
|---|
| | | \n\ |
|---|
| | | constant int k_digits [[function_constant(0)]]; \n\ |
|---|
| | | \n\ |
|---|
| | | kernel void kernel_add( \n\ |
|---|
| | | device const float * src0, \n\ |
|---|
| | | device const float * src1, \n\ |
|---|
| | | device float * dst, \n\ |
|---|
| | | uint gid[[thread_position_in_grid]]) { \n\ |
|---|
| | | dst[gid] = src0[gid] + src1[gid]; \n\ |
|---|
| | | } \n\ |
|---|
| | | \n\ |
|---|
| | | kernel void kernel_relu( \n\ |
|---|
| | | device const float * src, \n\ |
|---|
| | | device float * dst, \n\ |
|---|
| | | uint gid[[thread_position_in_grid]]) { \n\ |
|---|
| | | dst[gid] = max(0.0f, src[gid]); \n\ |
|---|
| | | } \n\ |
|---|
| | | \n\ |
|---|
| | | kernel void kernel_soft_max( \n\ |
|---|
| | | device const float * src, \n\ |
|---|
| | | device float * dst, \n\ |
|---|
| | | uint gid[[thread_position_in_grid]]) { \n\ |
|---|
| | | float max = 0.0f; \n\ |
|---|
| | | for (int i = 0; i < k_digits; i++) { \n\ |
|---|
| | | max = MAX(max, src[i]); \n\ |
|---|
| | | } \n\ |
|---|
| | | float sum = 0.0f; \n\ |
|---|
| | | for (int i = 0; i < k_digits; i++) { \n\ |
|---|
| | | dst[i] = exp(src[i] - max); \n\ |
|---|
| | | sum += dst[i]; \n\ |
|---|
| | | } \n\ |
|---|
| | | for (int i = 0; i < k_digits; i++) { \n\ |
|---|
| | | dst[i] /= sum; \n\ |
|---|
| | | } \n\ |
|---|
| | | } \n\ |
|---|
| | | "; |
|---|
| | | |
|---|
| | | struct ggml_mtl_context * mnist_mtl_init( |
|---|
| | | struct ggml_context * ctx_data, |
|---|
| | | struct ggml_context * ctx_eval, |
|---|
| | | struct ggml_context * ctx_work, |
|---|
| | | struct ggml_cgraph * gf) { |
|---|
| | | fprintf(stderr, "%s: allocating\n", __func__); |
|---|
| | | |
|---|
| | | struct ggml_mtl_context * ctx = malloc(sizeof(struct ggml_mtl_context)); |
|---|
| | | |
|---|
| | | ctx->ctx_data = ctx_data; |
|---|
| | | ctx->ctx_eval = ctx_eval; |
|---|
| | | ctx->ctx_work = ctx_work; |
|---|
| | | |
|---|
| | | ctx->device = MTLCreateSystemDefaultDevice(); |
|---|
| | | ctx->queue = [ctx->device newCommandQueue]; |
|---|
| | | |
|---|
| | | // determine if we can use MPS |
|---|
| | | if (MPSSupportsMTLDevice(ctx->device)) { |
|---|
| | | fprintf(stderr, "%s: using MPS\n", __func__); |
|---|
| | | } else { |
|---|
| | | fprintf(stderr, "%s: not using MPS\n", __func__); |
|---|
| | | GGML_ASSERT(false && "MPS not supported"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // compile from source string and show compile log |
|---|
| | | { |
|---|
| | | NSError * error = nil; |
|---|
| | | ctx->library = [ctx->device newLibraryWithSource:msl_library_mnist options:nil error:&error]; |
|---|
| | | if (error) { |
|---|
| | | fprintf(stderr, "%s: error: %s\n", __func__, [[error description] UTF8String]); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load kernels |
|---|
| | | { |
|---|
| | | const int k_digits = ggml_graph_get_tensor(gf, "probs")->ne[0]; |
|---|
| | | |
|---|
| | | MTLFunctionConstantValues * constants = [MTLFunctionConstantValues new]; |
|---|
| | | [constants setConstantValue:&k_digits type:MTLDataTypeInt withName:@"k_digits"]; |
|---|
| | | |
|---|
| | | ctx->function_add = [ctx->library newFunctionWithName:@"kernel_add"]; |
|---|
| | | ctx->pipeline_add = [ctx->device newComputePipelineStateWithFunction:ctx->function_add error:nil]; |
|---|
| | | fprintf(stderr, "%s: loaded kernel_add: %p\n", __func__, (void *) ctx->pipeline_add); |
|---|
| | | |
|---|
| | | ctx->function_relu = [ctx->library newFunctionWithName:@"kernel_relu"]; |
|---|
| | | ctx->pipeline_relu = [ctx->device newComputePipelineStateWithFunction:ctx->function_relu error:nil]; |
|---|
| | | fprintf(stderr, "%s: loaded kernel_relu: %p\n", __func__, (void *) ctx->pipeline_relu); |
|---|
| | | |
|---|
| | | ctx->function_soft_max = [ctx->library newFunctionWithName:@"kernel_soft_max" constantValues:constants error:nil]; |
|---|
| | | ctx->pipeline_soft_max = [ctx->device newComputePipelineStateWithFunction:ctx->function_soft_max error:nil]; |
|---|
| | | fprintf(stderr, "%s: loaded kernel_soft_max: %p\n", __func__, (void *) ctx->pipeline_soft_max); |
|---|
| | | } |
|---|
| | | |
|---|
| | | #ifdef GGML_MTL_HEAP |
|---|
| | | // MTLHeap approach |
|---|
| | | |
|---|
| | | // pin ctx_data memory to GPU |
|---|
| | | // use MTLStorageModeShared to allow us to initialize the weights from the CPU |
|---|
| | | // TODO: how to use MTLStorageModeManaged? |
|---|
| | | // TODO: see if we can avoid this copy somehow |
|---|
| | | { |
|---|
| | | const void * mem_buffer = ggml_get_mem_buffer(ctx_data); |
|---|
| | | const size_t mem_size = ggml_get_mem_size(ctx_data); |
|---|
| | | |
|---|
| | | MTLHeapDescriptor * heap_desc = [MTLHeapDescriptor new]; |
|---|
| | | heap_desc.storageMode = MTLStorageModeShared; |
|---|
| | | heap_desc.size = mem_size; |
|---|
| | | |
|---|
| | | printf("heap_desc.size = %zu\n", mem_size); |
|---|
| | | |
|---|
| | | ctx->heap_data = [ctx->device newHeapWithDescriptor:heap_desc]; |
|---|
| | | [ctx->heap_data setPurgeableState:MTLPurgeableStateNonVolatile]; // TODO: is this needed? |
|---|
| | | ctx->heap_data.label = @"heap_data"; |
|---|
| | | |
|---|
| | | printf("ctx->heap_data.size = %zu\n", [ctx->heap_data size]); |
|---|
| | | |
|---|
| | | id<MTLBuffer> buffer = [ctx->heap_data newBufferWithLength:mem_size options:MTLResourceStorageModeShared]; |
|---|
| | | if (!buffer) { |
|---|
| | | fprintf(stderr, "%s: error: failed to allocate buffer\n", __func__); |
|---|
| | | exit(1); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // copy data from CPU to GPU |
|---|
| | | memcpy([buffer contents], mem_buffer, mem_size); |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s: allocated data heap, size = %zu\n", __func__, mem_size); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // pin ctx_eval memory to GPU |
|---|
| | | // this heap will be used for the intermediate results of the evaluation |
|---|
| | | { |
|---|
| | | const size_t mem_size = ggml_get_mem_size(ctx_eval); |
|---|
| | | |
|---|
| | | MTLHeapDescriptor * heap_desc = [MTLHeapDescriptor new]; |
|---|
| | | heap_desc.storageMode = MTLStorageModePrivate; // GPU only |
|---|
| | | heap_desc.size = mem_size; |
|---|
| | | |
|---|
| | | ctx->heap_eval = [ctx->device newHeapWithDescriptor:heap_desc]; |
|---|
| | | [ctx->heap_eval setPurgeableState:MTLPurgeableStateNonVolatile]; // TODO: is this needed? |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s: allocated eval heap, size = %zu\n", __func__, mem_size); |
|---|
| | | } |
|---|
| | | #else |
|---|
| | | // MTLBuffer approach |
|---|
| | | |
|---|
| | | // pin ctx_data memory to GPU |
|---|
| | | // use MTLStorageModeShared to allow us to initialize the weights from the CPU |
|---|
| | | // TODO: how to use MTLStorageModeManaged? |
|---|
| | | // TODO: see if we can avoid this copy somehow |
|---|
| | | { |
|---|
| | | const void * mem_buffer = ggml_get_mem_buffer(ctx_data); |
|---|
| | | const size_t mem_size = ggml_get_mem_size(ctx_data); |
|---|
| | | |
|---|
| | | ctx->buffer_data = [ctx->device newBufferWithBytes:mem_buffer length:mem_size options:MTLResourceStorageModeShared]; |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s: allocated data buffer, size = %zu\n", __func__, mem_size); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // pin ctx_eval memory to GPU |
|---|
| | | // this buffer will be used for the intermediate results of the evaluation |
|---|
| | | { |
|---|
| | | const size_t mem_size = ggml_get_mem_size(ctx_eval); |
|---|
| | | |
|---|
| | | ctx->buffer_eval = [ctx->device newBufferWithLength:mem_size options:MTLResourceStorageModePrivate]; |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s: allocated eval buffer, size = %zu\n", __func__, mem_size); |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | // allocate buffer for result extraction |
|---|
| | | { |
|---|
| | | const size_t mem_size = ggml_nbytes(gf->nodes[gf->n_nodes - 1]); |
|---|
| | | |
|---|
| | | ctx->out = [ctx->device newBufferWithLength:mem_size options:MTLResourceStorageModeShared]; |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s: allocated out buffer, size = %zu\n", __func__, mem_size); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return ctx; |
|---|
| | | } |
|---|
| | | |
|---|
| | | void mnist_mtl_free(struct ggml_mtl_context * ctx) { |
|---|
| | | fprintf(stderr, "%s: deallocating\n", __func__); |
|---|
| | | |
|---|
| | | free(ctx); |
|---|
| | | } |
|---|
| | | |
|---|
| | | #ifdef GGML_MTL_HEAP |
|---|
| | | |
|---|
| | | // make a view of the respective MTL heap |
|---|
| | | id<MTLBuffer> mnist_mtl_get_buffer_on_heap(struct ggml_mtl_context * ctx, struct ggml_tensor * t) { |
|---|
| | | const int64_t offs_data = (int64_t) t->data - (int64_t) ggml_get_mem_buffer(ctx->ctx_data); |
|---|
| | | const int64_t offs_eval = (int64_t) t->data - (int64_t) ggml_get_mem_buffer(ctx->ctx_eval); |
|---|
| | | |
|---|
| | | const bool is_data = (offs_eval < 0) || (offs_data >= 0 && offs_data < offs_eval); |
|---|
| | | |
|---|
| | | const size_t t_size = ggml_nbytes(t); |
|---|
| | | const size_t t_offs = is_data ? offs_data : offs_eval; |
|---|
| | | |
|---|
| | | id<MTLBuffer> result; |
|---|
| | | |
|---|
| | | if (is_data) { |
|---|
| | | fprintf(stderr, "%s: data tensor '%16s', offs = %8ld, size = %8ld\n", __func__, t->name, t_offs, t_size); |
|---|
| | | result = [ctx->heap_data newBufferWithLength:t_size options:MTLResourceStorageModeShared offset:t_offs]; |
|---|
| | | } else { |
|---|
| | | fprintf(stderr, "%s: eval tensor '%16s', offs = %8ld, size = %8ld\n", __func__, t->name, t_offs, t_size); |
|---|
| | | result = [ctx->heap_eval newBufferWithLength:t_size options:MTLResourceStorageModePrivate offset:t_offs]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (result == nil) { |
|---|
| | | fprintf(stderr, "%s: error: buffer is nil\n", __func__); |
|---|
| | | GGML_ASSERT(false); |
|---|
| | | } |
|---|
| | | |
|---|
| | | return result; |
|---|
| | | } |
|---|
| | | |
|---|
| | | #else |
|---|
| | | |
|---|
| | | // get data / eval buffer + offset |
|---|
| | | id<MTLBuffer> mnist_mtl_get_buffer(struct ggml_mtl_context * ctx, struct ggml_tensor * t, size_t * offs) { |
|---|
| | | const int64_t offs_data = (int64_t) t->data - (int64_t) ggml_get_mem_buffer(ctx->ctx_data); |
|---|
| | | const int64_t offs_eval = (int64_t) t->data - (int64_t) ggml_get_mem_buffer(ctx->ctx_eval); |
|---|
| | | |
|---|
| | | const bool is_data = (offs_eval < 0) || (offs_data >= 0 && offs_data < offs_eval); |
|---|
| | | |
|---|
| | | const size_t t_size = ggml_nbytes(t); |
|---|
| | | const size_t t_offs = is_data ? offs_data : offs_eval; |
|---|
| | | |
|---|
| | | id<MTLBuffer> result; |
|---|
| | | |
|---|
| | | if (is_data) { |
|---|
| | | fprintf(stderr, "%s: data tensor '%16s', offs = %8ld, size = %8ld\n", __func__, t->name, t_offs, t_size); |
|---|
| | | result = ctx->buffer_data; |
|---|
| | | } else { |
|---|
| | | fprintf(stderr, "%s: eval tensor '%16s', offs = %8ld, size = %8ld\n", __func__, t->name, t_offs, t_size); |
|---|
| | | result = ctx->buffer_eval; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (result == nil) { |
|---|
| | | fprintf(stderr, "%s: error: buffer is nil\n", __func__); |
|---|
| | | GGML_ASSERT(false); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (offs != nil) { |
|---|
| | | *offs = t_offs; |
|---|
| | | } |
|---|
| | | |
|---|
| | | return result; |
|---|
| | | } |
|---|
| | | |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | int mnist_mtl_eval( |
|---|
| | | struct ggml_mtl_context * ctx, |
|---|
| | | struct ggml_cgraph * gf) { |
|---|
| | | fprintf(stderr, "%s: evaluating\n", __func__); |
|---|
| | | |
|---|
| | | id<MTLCommandBuffer> command_buffer = [ctx->queue commandBuffer]; |
|---|
| | | id<MTLComputeCommandEncoder> encoder = nil; |
|---|
| | | |
|---|
| | | size_t offs_src0; |
|---|
| | | size_t offs_src1; |
|---|
| | | size_t offs_dst; |
|---|
| | | |
|---|
| | | // copy the input data to the GPU |
|---|
| | | { |
|---|
| | | struct ggml_tensor * inp = ggml_graph_get_tensor(gf, "input"); |
|---|
| | | |
|---|
| | | id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, inp, &offs_src0); |
|---|
| | | |
|---|
| | | memcpy((char *) id_dst.contents + offs_src0, inp->data, ggml_nbytes(inp)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | for (int i = 0; i < gf->n_nodes; ++i) { |
|---|
| | | fprintf(stderr, "%s: encoding node %3d, op = %8s\n", __func__, i, ggml_op_name(gf->nodes[i]->op)); |
|---|
| | | |
|---|
| | | switch (gf->nodes[i]->op) { |
|---|
| | | case GGML_OP_ADD: |
|---|
| | | { |
|---|
| | | if (encoder == nil) { |
|---|
| | | encoder = [command_buffer computeCommandEncoder]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | id<MTLBuffer> id_src0 = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[0], &offs_src0); |
|---|
| | | id<MTLBuffer> id_src1 = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[1], &offs_src1); |
|---|
| | | id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, gf->nodes[i], &offs_dst); |
|---|
| | | |
|---|
| | | [encoder setComputePipelineState:ctx->pipeline_add]; |
|---|
| | | [encoder setBuffer:id_src0 offset:offs_src0 atIndex:0]; |
|---|
| | | [encoder setBuffer:id_src1 offset:offs_src1 atIndex:1]; |
|---|
| | | [encoder setBuffer:id_dst offset:offs_dst atIndex:2]; |
|---|
| | | |
|---|
| | | const int64_t n = ggml_nelements(gf->nodes[i]); |
|---|
| | | |
|---|
| | | [encoder dispatchThreadgroups:MTLSizeMake(n, 1, 1) threadsPerThreadgroup:MTLSizeMake(1, 1, 1)]; |
|---|
| | | } break; |
|---|
| | | case GGML_OP_UNARY: |
|---|
| | | switch (ggml_get_unary_op(gf->nodes[i])) { |
|---|
| | | case GGML_UNARY_OP_RELU: |
|---|
| | | { |
|---|
| | | if (encoder == nil) { |
|---|
| | | encoder = [command_buffer computeCommandEncoder]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | id<MTLBuffer> id_src = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[0], &offs_src0); |
|---|
| | | id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, gf->nodes[i], &offs_dst); |
|---|
| | | |
|---|
| | | [encoder setComputePipelineState:ctx->pipeline_relu]; |
|---|
| | | [encoder setBuffer:id_src offset:offs_src0 atIndex:0]; |
|---|
| | | [encoder setBuffer:id_dst offset:offs_dst atIndex:1]; |
|---|
| | | |
|---|
| | | const int64_t n = ggml_nelements(gf->nodes[i]); |
|---|
| | | |
|---|
| | | [encoder dispatchThreadgroups:MTLSizeMake(n, 1, 1) threadsPerThreadgroup:MTLSizeMake(1, 1, 1)]; |
|---|
| | | } break; |
|---|
| | | default: |
|---|
| | | { |
|---|
| | | fprintf(stderr, "%s: node %3d, op = %8s, unary op %d not implemented\n", __func__, i, ggml_op_name(gf->nodes[i]->op), (int) ggml_get_unary_op(gf->nodes[i])); |
|---|
| | | GGML_ASSERT(false); |
|---|
| | | return -1; |
|---|
| | | } |
|---|
| | | break; |
|---|
| | | } break; |
|---|
| | | case GGML_OP_SOFT_MAX: |
|---|
| | | { |
|---|
| | | #if 0 |
|---|
| | | // NOTE: MPSMatrixSoftMax is not working properly, probably there is a bug |
|---|
| | | |
|---|
| | | if (encoder != nil) { |
|---|
| | | [encoder endEncoding]; |
|---|
| | | encoder = nil; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // use MPSMatrixSoftMax |
|---|
| | | id<MTLBuffer> id_src = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src0, &offs_src0); |
|---|
| | | id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, gf->nodes[i], &offs_dst); |
|---|
| | | |
|---|
| | | MPSMatrixDescriptor * desc = [MPSMatrixDescriptor |
|---|
| | | matrixDescriptorWithRows:1 columns:gf->nodes[i]->ne[0] rowBytes:gf->nodes[i]->nb[1] dataType:MPSDataTypeFloat32]; |
|---|
| | | |
|---|
| | | MPSMatrix * mat_src = [[MPSMatrix alloc] initWithBuffer:id_src offset:offs_src0 descriptor:desc]; |
|---|
| | | MPSMatrix * mat_dst = [[MPSMatrix alloc] initWithBuffer:id_dst offset:offs_dst descriptor:desc]; |
|---|
| | | |
|---|
| | | MPSMatrixSoftMax * softmax = [[MPSMatrixSoftMax alloc] initWithDevice:ctx->device]; |
|---|
| | | |
|---|
| | | [softmax encodeToCommandBuffer:command_buffer inputMatrix:mat_src resultMatrix:mat_dst]; |
|---|
| | | #else |
|---|
| | | if (encoder == nil) { |
|---|
| | | encoder = [command_buffer computeCommandEncoder]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | id<MTLBuffer> id_src = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[0], &offs_src0); |
|---|
| | | id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, gf->nodes[i], &offs_dst); |
|---|
| | | |
|---|
| | | [encoder setComputePipelineState:ctx->pipeline_soft_max]; |
|---|
| | | [encoder setBuffer:id_src offset:offs_src0 atIndex:0]; |
|---|
| | | [encoder setBuffer:id_dst offset:offs_dst atIndex:1]; |
|---|
| | | |
|---|
| | | [encoder dispatchThreadgroups:MTLSizeMake(1, 1, 1) threadsPerThreadgroup:MTLSizeMake(1, 1, 1)]; |
|---|
| | | #endif |
|---|
| | | } break; |
|---|
| | | case GGML_OP_MUL_MAT: |
|---|
| | | { |
|---|
| | | if (encoder != nil) { |
|---|
| | | [encoder endEncoding]; |
|---|
| | | encoder = nil; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // use MPSMatrixMultiplication |
|---|
| | | id<MTLBuffer> id_src0 = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[0], &offs_src0); |
|---|
| | | id<MTLBuffer> id_src1 = mnist_mtl_get_buffer(ctx, gf->nodes[i]->src[1], &offs_src1); |
|---|
| | | id<MTLBuffer> id_dst = mnist_mtl_get_buffer(ctx, gf->nodes[i], &offs_dst); |
|---|
| | | |
|---|
| | | const int64_t ncols0 = gf->nodes[i]->src[0]->ne[0]; |
|---|
| | | const int64_t nrows0 = gf->nodes[i]->src[0]->ne[1]; |
|---|
| | | |
|---|
| | | const int64_t ncols1 = gf->nodes[i]->src[1]->ne[0]; |
|---|
| | | const int64_t nrows1 = gf->nodes[i]->src[1]->ne[1]; |
|---|
| | | |
|---|
| | | const int64_t ncols2 = gf->nodes[i]->ne[0]; |
|---|
| | | const int64_t nrows2 = gf->nodes[i]->ne[1]; |
|---|
| | | |
|---|
| | | GGML_ASSERT(ncols0 == ncols1); |
|---|
| | | |
|---|
| | | MPSMatrixDescriptor * desc0 = [MPSMatrixDescriptor |
|---|
| | | matrixDescriptorWithRows:nrows0 columns:ncols0 rowBytes:gf->nodes[i]->src[0]->nb[1] dataType:MPSDataTypeFloat32]; |
|---|
| | | MPSMatrixDescriptor * desc1 = [MPSMatrixDescriptor |
|---|
| | | matrixDescriptorWithRows:nrows1 columns:ncols1 rowBytes:gf->nodes[i]->src[1]->nb[1] dataType:MPSDataTypeFloat32]; |
|---|
| | | MPSMatrixDescriptor * desc2 = [MPSMatrixDescriptor |
|---|
| | | matrixDescriptorWithRows:nrows2 columns:ncols2 rowBytes:gf->nodes[i]->nb[1] dataType:MPSDataTypeFloat32]; |
|---|
| | | |
|---|
| | | MPSMatrix * mat_src0 = [[MPSMatrix alloc] initWithBuffer:id_src0 offset:offs_src0 descriptor:desc0]; |
|---|
| | | MPSMatrix * mat_src1 = [[MPSMatrix alloc] initWithBuffer:id_src1 offset:offs_src1 descriptor:desc1]; |
|---|
| | | MPSMatrix * mat_dst = [[MPSMatrix alloc] initWithBuffer:id_dst offset:offs_dst descriptor:desc2]; |
|---|
| | | |
|---|
| | | MPSMatrixMultiplication * mul = [[MPSMatrixMultiplication alloc] initWithDevice:ctx->device |
|---|
| | | transposeLeft:false transposeRight:true resultRows:nrows1 resultColumns:nrows0 interiorColumns:ncols0 alpha:1.0 beta:0.0]; |
|---|
| | | |
|---|
| | | [mul encodeToCommandBuffer:command_buffer leftMatrix:mat_src1 rightMatrix:mat_src0 resultMatrix:mat_dst]; |
|---|
| | | } break; |
|---|
| | | default: |
|---|
| | | { |
|---|
| | | fprintf(stderr, "%s: node %3d, op = %8s not implemented\n", __func__, i, ggml_op_name(gf->nodes[i]->op)); |
|---|
| | | GGML_ASSERT(false); |
|---|
| | | return -1; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // extract results from the GPU |
|---|
| | | { |
|---|
| | | if (encoder != nil) { |
|---|
| | | [encoder endEncoding]; |
|---|
| | | encoder = nil; |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * out = gf->nodes[gf->n_nodes - 1]; |
|---|
| | | |
|---|
| | | id<MTLBuffer> id_src = mnist_mtl_get_buffer(ctx, out, &offs_src0); |
|---|
| | | id<MTLBuffer> id_dst = ctx->out; |
|---|
| | | |
|---|
| | | id<MTLBlitCommandEncoder> encoder_blit = [command_buffer blitCommandEncoder]; |
|---|
| | | [encoder_blit copyFromBuffer:id_src sourceOffset:offs_src0 toBuffer:id_dst destinationOffset:0 size:ggml_nbytes(out)]; |
|---|
| | | [encoder_blit endEncoding]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | [command_buffer commit]; |
|---|
| | | [command_buffer waitUntilCompleted]; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const double time_elapsed = [command_buffer GPUEndTime] - [command_buffer GPUStartTime]; |
|---|
| | | fprintf(stderr, "%s: time elapsed = %f\n", __func__, time_elapsed); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // select the most probable digit |
|---|
| | | int result = -1; |
|---|
| | | { |
|---|
| | | const float * probs = ctx->out.contents; |
|---|
| | | |
|---|
| | | float prob = probs[0]; |
|---|
| | | |
|---|
| | | for (int i = 0; i < 10; ++i) { |
|---|
| | | fprintf(stderr, "%s: probs[%2d] = %f\n", __func__, i, probs[i]); |
|---|
| | | |
|---|
| | | if (probs[i] > prob) { |
|---|
| | | result = i; |
|---|
| | | prob = probs[i]; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | return result; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "common.h" |
|---|
| | | |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <ctime> |
|---|
| | | #include <fstream> |
|---|
| | | #include <string> |
|---|
| | | #include <vector> |
|---|
| | | #include <algorithm> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | // default hparams |
|---|
| | | struct mnist_hparams { |
|---|
| | | int32_t n_input = 784; |
|---|
| | | int32_t n_hidden = 500; |
|---|
| | | int32_t n_classes = 10; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct mnist_model { |
|---|
| | | mnist_hparams hparams; |
|---|
| | | |
|---|
| | | struct ggml_tensor * fc1_weight; |
|---|
| | | struct ggml_tensor * fc1_bias; |
|---|
| | | |
|---|
| | | struct ggml_tensor * fc2_weight; |
|---|
| | | struct ggml_tensor * fc2_bias; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | // load the model's weights from a file |
|---|
| | | bool mnist_model_load(const std::string & fname, mnist_model & model) { |
|---|
| | | printf("%s: loading model from '%s'\n", __func__, fname.c_str()); |
|---|
| | | |
|---|
| | | auto fin = std::ifstream(fname, std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | fin.read((char *) &magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto & ctx = model.ctx; |
|---|
| | | |
|---|
| | | size_t ctx_size = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_input = hparams.n_input; |
|---|
| | | const int n_hidden = hparams.n_hidden; |
|---|
| | | const int n_classes = hparams.n_classes; |
|---|
| | | |
|---|
| | | ctx_size += n_input * n_hidden * ggml_type_size(GGML_TYPE_F32); // fc1 weight |
|---|
| | | ctx_size += n_hidden * ggml_type_size(GGML_TYPE_F32); // fc1 bias |
|---|
| | | |
|---|
| | | ctx_size += n_hidden * n_classes * ggml_type_size(GGML_TYPE_F32); // fc2 weight |
|---|
| | | ctx_size += n_classes * ggml_type_size(GGML_TYPE_F32); // fc2 bias |
|---|
| | | |
|---|
| | | printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size/(1024.0*1024.0)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // create the ggml context |
|---|
| | | { |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ ctx_size + 1024*1024, |
|---|
| | | /*.mem_buffer =*/ NULL, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | model.ctx = ggml_init(params); |
|---|
| | | if (!model.ctx) { |
|---|
| | | fprintf(stderr, "%s: ggml_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Read FC1 layer 1 |
|---|
| | | { |
|---|
| | | // Read dimensions |
|---|
| | | int32_t n_dims; |
|---|
| | | fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | |
|---|
| | | { |
|---|
| | | int32_t ne_weight[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne_weight[i]), sizeof(ne_weight[i])); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // FC1 dimensions taken from file, eg. 768x500 |
|---|
| | | model.hparams.n_input = ne_weight[0]; |
|---|
| | | model.hparams.n_hidden = ne_weight[1]; |
|---|
| | | |
|---|
| | | model.fc1_weight = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, model.hparams.n_input, model.hparams.n_hidden); |
|---|
| | | fin.read(reinterpret_cast<char *>(model.fc1_weight->data), ggml_nbytes(model.fc1_weight)); |
|---|
| | | ggml_set_name(model.fc1_weight, "fc1_weight"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | { |
|---|
| | | int32_t ne_bias[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne_bias[i]), sizeof(ne_bias[i])); |
|---|
| | | } |
|---|
| | | |
|---|
| | | model.fc1_bias = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, model.hparams.n_hidden); |
|---|
| | | fin.read(reinterpret_cast<char *>(model.fc1_bias->data), ggml_nbytes(model.fc1_bias)); |
|---|
| | | ggml_set_name(model.fc1_bias, "fc1_bias"); |
|---|
| | | |
|---|
| | | // just for testing purposes, set some parameters to non-zero |
|---|
| | | model.fc1_bias->op_params[0] = 0xdeadbeef; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Read FC2 layer 2 |
|---|
| | | { |
|---|
| | | // Read dimensions |
|---|
| | | int32_t n_dims; |
|---|
| | | fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | |
|---|
| | | { |
|---|
| | | int32_t ne_weight[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne_weight[i]), sizeof(ne_weight[i])); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // FC1 dimensions taken from file, eg. 10x500 |
|---|
| | | model.hparams.n_classes = ne_weight[1]; |
|---|
| | | |
|---|
| | | model.fc2_weight = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, model.hparams.n_hidden, model.hparams.n_classes); |
|---|
| | | fin.read(reinterpret_cast<char *>(model.fc2_weight->data), ggml_nbytes(model.fc2_weight)); |
|---|
| | | ggml_set_name(model.fc2_weight, "fc2_weight"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | { |
|---|
| | | int32_t ne_bias[2] = { 1, 1 }; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne_bias[i]), sizeof(ne_bias[i])); |
|---|
| | | } |
|---|
| | | |
|---|
| | | model.fc2_bias = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, model.hparams.n_classes); |
|---|
| | | fin.read(reinterpret_cast<char *>(model.fc2_bias->data), ggml_nbytes(model.fc2_bias)); |
|---|
| | | ggml_set_name(model.fc2_bias, "fc2_bias"); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // evaluate the model |
|---|
| | | // |
|---|
| | | // - model: the model |
|---|
| | | // - n_threads: number of threads to use |
|---|
| | | // - digit: 784 pixel values |
|---|
| | | // |
|---|
| | | // returns 0 - 9 prediction |
|---|
| | | int mnist_eval( |
|---|
| | | const mnist_model & model, |
|---|
| | | const int n_threads, |
|---|
| | | std::vector<float> digit, |
|---|
| | | const char * fname_cgraph |
|---|
| | | ) { |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | static size_t buf_size = hparams.n_input * sizeof(float) * 32; |
|---|
| | | static void * buf = malloc(buf_size); |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx0 = ggml_init(params); |
|---|
| | | struct ggml_cgraph * gf = ggml_new_graph(ctx0); |
|---|
| | | |
|---|
| | | struct ggml_tensor * input = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, hparams.n_input); |
|---|
| | | memcpy(input->data, digit.data(), ggml_nbytes(input)); |
|---|
| | | ggml_set_name(input, "input"); |
|---|
| | | |
|---|
| | | // fc1 MLP = Ax + b |
|---|
| | | ggml_tensor * fc1 = ggml_add(ctx0, ggml_mul_mat(ctx0, model.fc1_weight, input), model.fc1_bias); |
|---|
| | | ggml_tensor * fc2 = ggml_add(ctx0, ggml_mul_mat(ctx0, model.fc2_weight, ggml_relu(ctx0, fc1)), model.fc2_bias); |
|---|
| | | |
|---|
| | | // soft max |
|---|
| | | ggml_tensor * probs = ggml_soft_max(ctx0, fc2); |
|---|
| | | ggml_set_name(probs, "probs"); |
|---|
| | | |
|---|
| | | // build / export / run the computation graph |
|---|
| | | ggml_build_forward_expand(gf, probs); |
|---|
| | | ggml_graph_compute_with_ctx(ctx0, gf, n_threads); |
|---|
| | | |
|---|
| | | //ggml_graph_print (&gf); |
|---|
| | | ggml_graph_dump_dot(gf, NULL, "mnist.dot"); |
|---|
| | | |
|---|
| | | if (fname_cgraph) { |
|---|
| | | // export the compute graph for later use |
|---|
| | | // see the "mnist-cpu" example |
|---|
| | | ggml_graph_export(gf, "mnist.ggml"); |
|---|
| | | |
|---|
| | | fprintf(stderr, "%s: exported compute graph to '%s'\n", __func__, fname_cgraph); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const float * probs_data = ggml_get_data_f32(probs); |
|---|
| | | |
|---|
| | | const int prediction = std::max_element(probs_data, probs_data + 10) - probs_data; |
|---|
| | | |
|---|
| | | ggml_free(ctx0); |
|---|
| | | |
|---|
| | | return prediction; |
|---|
| | | } |
|---|
| | | |
|---|
| | | #ifdef __cplusplus |
|---|
| | | extern "C" { |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | int wasm_eval(uint8_t * digitPtr) { |
|---|
| | | mnist_model model; |
|---|
| | | if (!mnist_model_load("models/mnist/ggml-model-f32.bin", model)) { |
|---|
| | | fprintf(stderr, "error loading model\n"); |
|---|
| | | return -1; |
|---|
| | | } |
|---|
| | | std::vector<float> digit(digitPtr, digitPtr + 784); |
|---|
| | | int result = mnist_eval(model, 1, digit, nullptr); |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | return result; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int wasm_random_digit(char * digitPtr) { |
|---|
| | | auto fin = std::ifstream("models/mnist/t10k-images.idx3-ubyte", std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "failed to open digits file\n"); |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| | | srand(time(NULL)); |
|---|
| | | |
|---|
| | | // Seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000) |
|---|
| | | fin.seekg(16 + 784 * (rand() % 10000)); |
|---|
| | | fin.read(digitPtr, 784); |
|---|
| | | |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | #ifdef __cplusplus |
|---|
| | | } |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | srand(time(NULL)); |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | if (argc != 3) { |
|---|
| | | fprintf(stderr, "Usage: %s models/mnist/ggml-model-f32.bin models/mnist/t10k-images.idx3-ubyte\n", argv[0]); |
|---|
| | | exit(0); |
|---|
| | | } |
|---|
| | | |
|---|
| | | uint8_t buf[784]; |
|---|
| | | mnist_model model; |
|---|
| | | std::vector<float> digit; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!mnist_model_load(argv[1], model)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, "models/ggml-model-f32.bin"); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | const int64_t t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | fprintf(stdout, "%s: loaded model in %8.2f ms\n", __func__, t_load_us / 1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // read a random digit from the test set |
|---|
| | | { |
|---|
| | | std::ifstream fin(argv[2], std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, argv[2]); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // seek to a random digit: 16-byte header + 28*28 * (random 0 - 10000) |
|---|
| | | fin.seekg(16 + 784 * (rand() % 10000)); |
|---|
| | | fin.read((char *) &buf, sizeof(buf)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // render the digit in ASCII |
|---|
| | | { |
|---|
| | | digit.resize(sizeof(buf)); |
|---|
| | | |
|---|
| | | for (int row = 0; row < 28; row++) { |
|---|
| | | for (int col = 0; col < 28; col++) { |
|---|
| | | fprintf(stderr, "%c ", (float)buf[row*28 + col] > 230 ? '*' : '_'); |
|---|
| | | digit[row*28 + col] = ((float)buf[row*28 + col]); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const int prediction = mnist_eval(model, 1, digit, "mnist.ggml"); |
|---|
| | | |
|---|
| | | fprintf(stdout, "%s: predicted digit is %d\n", __func__, prediction); |
|---|
| | | |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| New file |
| | |
|---|
| | | #!/usr/bin/env python3 |
|---|
| | | import sys |
|---|
| | | import gguf |
|---|
| | | import numpy as np |
|---|
| | | from tensorflow import keras |
|---|
| | | from tensorflow.keras import layers |
|---|
| | | |
|---|
| | | def train(model_name): |
|---|
| | | # Model / data parameters |
|---|
| | | num_classes = 10 |
|---|
| | | input_shape = (28, 28, 1) |
|---|
| | | |
|---|
| | | # Load the data and split it between train and test sets |
|---|
| | | (x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data() |
|---|
| | | |
|---|
| | | # Scale images to the [0, 1] range |
|---|
| | | x_train = x_train.astype("float32") / 255 |
|---|
| | | x_test = x_test.astype("float32") / 255 |
|---|
| | | # Make sure images have shape (28, 28, 1) |
|---|
| | | x_train = np.expand_dims(x_train, -1) |
|---|
| | | x_test = np.expand_dims(x_test, -1) |
|---|
| | | print("x_train shape:", x_train.shape) |
|---|
| | | print(x_train.shape[0], "train samples") |
|---|
| | | print(x_test.shape[0], "test samples") |
|---|
| | | |
|---|
| | | # convert class vectors to binary class matrices |
|---|
| | | y_train = keras.utils.to_categorical(y_train, num_classes) |
|---|
| | | y_test = keras.utils.to_categorical(y_test, num_classes) |
|---|
| | | |
|---|
| | | model = keras.Sequential( |
|---|
| | | [ |
|---|
| | | keras.Input(shape=input_shape), |
|---|
| | | layers.Conv2D(32, kernel_size=(3, 3), activation="relu"), |
|---|
| | | layers.MaxPooling2D(pool_size=(2, 2)), |
|---|
| | | layers.Conv2D(64, kernel_size=(3, 3), activation="relu"), |
|---|
| | | layers.MaxPooling2D(pool_size=(2, 2)), |
|---|
| | | layers.Flatten(), |
|---|
| | | layers.Dropout(0.5), |
|---|
| | | layers.Dense(num_classes, activation="softmax"), |
|---|
| | | ] |
|---|
| | | ) |
|---|
| | | |
|---|
| | | model.summary() |
|---|
| | | batch_size = 128 |
|---|
| | | epochs = 15 |
|---|
| | | model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) |
|---|
| | | model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1) |
|---|
| | | |
|---|
| | | score = model.evaluate(x_test, y_test, verbose=0) |
|---|
| | | print("Test loss:", score[0]) |
|---|
| | | print("Test accuracy:", score[1]) |
|---|
| | | model.save(model_name) |
|---|
| | | print("Keras model saved to '" + model_name + "'") |
|---|
| | | |
|---|
| | | def convert(model_name): |
|---|
| | | model = keras.models.load_model(model_name) |
|---|
| | | gguf_model_name = model_name + ".gguf" |
|---|
| | | gguf_writer = gguf.GGUFWriter(gguf_model_name, "mnist-cnn") |
|---|
| | | |
|---|
| | | kernel1 = model.layers[0].weights[0].numpy() |
|---|
| | | kernel1 = np.moveaxis(kernel1, [2,3], [0,1]) |
|---|
| | | kernel1 = kernel1.astype(np.float16) |
|---|
| | | gguf_writer.add_tensor("kernel1", kernel1, raw_shape=(32, 1, 3, 3)) |
|---|
| | | |
|---|
| | | bias1 = model.layers[0].weights[1].numpy() |
|---|
| | | bias1 = np.repeat(bias1, 26*26) |
|---|
| | | gguf_writer.add_tensor("bias1", bias1, raw_shape=(1, 32, 26, 26)) |
|---|
| | | |
|---|
| | | kernel2 = model.layers[2].weights[0].numpy() |
|---|
| | | kernel2 = np.moveaxis(kernel2, [0,1,2,3], [2,3,1,0]) |
|---|
| | | kernel2 = kernel2.astype(np.float16) |
|---|
| | | gguf_writer.add_tensor("kernel2", kernel2, raw_shape=(64, 32, 3, 3)) |
|---|
| | | |
|---|
| | | bias2 = model.layers[2].weights[1].numpy() |
|---|
| | | bias2 = np.repeat(bias2, 11*11) |
|---|
| | | gguf_writer.add_tensor("bias2", bias2, raw_shape=(1, 64, 11, 11)) |
|---|
| | | |
|---|
| | | dense_w = model.layers[-1].weights[0].numpy() |
|---|
| | | dense_w = dense_w.transpose() |
|---|
| | | gguf_writer.add_tensor("dense_w", dense_w, raw_shape=(10, 1600)) |
|---|
| | | |
|---|
| | | dense_b = model.layers[-1].weights[1].numpy() |
|---|
| | | gguf_writer.add_tensor("dense_b", dense_b) |
|---|
| | | |
|---|
| | | gguf_writer.write_header_to_file() |
|---|
| | | gguf_writer.write_kv_data_to_file() |
|---|
| | | gguf_writer.write_tensors_to_file() |
|---|
| | | gguf_writer.close() |
|---|
| | | print("Model converted and saved to '{}'".format(gguf_model_name)) |
|---|
| | | |
|---|
| | | if __name__ == '__main__': |
|---|
| | | if len(sys.argv) < 3: |
|---|
| | | print("Usage: %s <train|convert> <model_name>".format(sys.argv[0])) |
|---|
| | | sys.exit(1) |
|---|
| | | if sys.argv[1] == 'train': |
|---|
| | | train(sys.argv[2]) |
|---|
| | | elif sys.argv[1] == 'convert': |
|---|
| | | convert(sys.argv[2]) |
|---|
| | | else: |
|---|
| | | print("Usage: %s <train|convert> <model_name>".format(sys.argv[0])) |
|---|
| | | sys.exit(1) |
|---|
| New file |
| | |
|---|
| | | # |
|---|
| | | # mpt |
|---|
| | | |
|---|
| | | set(TEST_TARGET mpt) |
|---|
| | | add_executable(${TEST_TARGET} main.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| | | |
|---|
| | | # |
|---|
| | | # mpt-quantize |
|---|
| | | |
|---|
| | | set(TEST_TARGET mpt-quantize) |
|---|
| | | add_executable(${TEST_TARGET} quantize.cpp) |
|---|
| | | target_link_libraries(${TEST_TARGET} PRIVATE ggml common common-ggml) |
|---|
| New file |
| | |
|---|
| | | # MPT |
|---|
| | | |
|---|
| | | Ref: https://github.com/mosaicml/llm-foundry#mpt |
|---|
| | | |
|---|
| | | ## Usage |
|---|
| | | |
|---|
| | | ```bash |
|---|
| | | # get the repo and build it |
|---|
| | | git clone https://github.com/ggerganov/ggml |
|---|
| | | cd ggml |
|---|
| | | mkdir build && cd build |
|---|
| | | cmake .. |
|---|
| | | make -j |
|---|
| | | |
|---|
| | | # get the model from HuggingFace |
|---|
| | | # be sure to have git-lfs installed |
|---|
| | | git clone https://huggingface.co/mosaicml/mpt-30b |
|---|
| | | |
|---|
| | | # convert model to FP16 |
|---|
| | | python3 ../examples/mpt/convert-h5-to-ggml.py ./mpt-30b 1 |
|---|
| | | |
|---|
| | | # run inference using FP16 precision |
|---|
| | | ./bin/mpt -m ./mpt-30b/ggml-model-f16.bin -p "I believe the meaning of life is" -t 8 -n 64 |
|---|
| | | |
|---|
| | | # quantize the model to 5-bits using Q5_0 quantization |
|---|
| | | ./bin/mpt-quantize ./mpt-30b/ggml-model-f16.bin ./mpt-30b/ggml-model-q5_0.bin q5_0 |
|---|
| | | ``` |
|---|
| New file |
| | |
|---|
| | | import os |
|---|
| | | import struct |
|---|
| | | import sys |
|---|
| | | |
|---|
| | | import torch |
|---|
| | | from transformers import AutoConfig, AutoTokenizer |
|---|
| | | |
|---|
| | | |
|---|
| | | # ref: https://github.com/openai/gpt-2/blob/master/src/encoder.py |
|---|
| | | def bytes_to_unicode(): |
|---|
| | | """ |
|---|
| | | Returns list of utf-8 byte and a corresponding list of unicode strings. |
|---|
| | | The reversible bpe codes work on unicode strings. |
|---|
| | | This means you need a large # of unicode characters in your vocab if you want to avoid UNKs. |
|---|
| | | When you're at something like a 10B token dataset you end up needing around 5K for decent coverage. |
|---|
| | | This is a signficant percentage of your normal, say, 32K bpe vocab. |
|---|
| | | To avoid that, we want lookup tables between utf-8 bytes and unicode strings. |
|---|
| | | And avoids mapping to whitespace/control characters the bpe code barfs on. |
|---|
| | | """ |
|---|
| | | bs = ( |
|---|
| | | list(range(ord("!"), ord("~") + 1)) |
|---|
| | | + list(range(ord("¡"), ord("¬") + 1)) |
|---|
| | | + list(range(ord("®"), ord("ÿ") + 1)) |
|---|
| | | ) |
|---|
| | | cs = bs[:] |
|---|
| | | n = 0 |
|---|
| | | for b in range(2**8): |
|---|
| | | if b not in bs: |
|---|
| | | bs.append(b) |
|---|
| | | cs.append(2**8 + n) |
|---|
| | | n += 1 |
|---|
| | | |
|---|
| | | cs = [chr(n) for n in cs] |
|---|
| | | |
|---|
| | | return dict(zip(bs, cs)) |
|---|
| | | |
|---|
| | | |
|---|
| | | def count_model_parts(dir_model: str) -> int: |
|---|
| | | """Returns the number of model parts in the model directory.""" |
|---|
| | | num_parts = 0 |
|---|
| | | for filename in os.listdir(dir_model): |
|---|
| | | if filename.startswith("pytorch_model-"): |
|---|
| | | num_parts += 1 |
|---|
| | | |
|---|
| | | if num_parts > 0: |
|---|
| | | print(f"Found {num_parts} model parts in {dir_model}") |
|---|
| | | return num_parts |
|---|
| | | |
|---|
| | | |
|---|
| | | if len(sys.argv) < 3: |
|---|
| | | print("Usage: convert-h5-to-ggml.py dir-model [use-f32]\n") |
|---|
| | | print(" ftype == 0 -> float32") |
|---|
| | | print(" ftype == 1 -> float16") |
|---|
| | | sys.exit(1) |
|---|
| | | |
|---|
| | | |
|---|
| | | # output in the same directory as the model |
|---|
| | | dir_model = sys.argv[1] |
|---|
| | | # get number of model parts |
|---|
| | | num_parts = count_model_parts(dir_model) |
|---|
| | | |
|---|
| | | # possible data types |
|---|
| | | # ftype == 0 -> float32 |
|---|
| | | # ftype == 1 -> float16 |
|---|
| | | # |
|---|
| | | # map from ftype to string |
|---|
| | | ftype_str = ["f32", "f16"] |
|---|
| | | |
|---|
| | | ftype = 1 |
|---|
| | | if len(sys.argv) > 2: |
|---|
| | | ftype = int(sys.argv[2]) |
|---|
| | | if ftype < 0 or ftype > 1: |
|---|
| | | print("Invalid ftype: " + str(ftype)) |
|---|
| | | sys.exit(1) |
|---|
| | | fname_out = dir_model + "/ggml-model-" + ftype_str[ftype] + ".bin" |
|---|
| | | |
|---|
| | | |
|---|
| | | tokenizer = AutoTokenizer.from_pretrained(dir_model, trust_remote_code=True) |
|---|
| | | config = AutoConfig.from_pretrained(dir_model, trust_remote_code=True) |
|---|
| | | hparams = config.to_dict() |
|---|
| | | |
|---|
| | | fout = open(fname_out, "wb") |
|---|
| | | |
|---|
| | | fout.write(struct.pack("i", 0x67676D6C)) # magic: ggml in hex |
|---|
| | | fout.write(struct.pack("i", hparams["d_model"])) |
|---|
| | | fout.write(struct.pack("i", hparams["max_seq_len"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_heads"])) |
|---|
| | | fout.write(struct.pack("i", hparams["n_layers"])) |
|---|
| | | fout.write(struct.pack("i", hparams["vocab_size"])) |
|---|
| | | fout.write(struct.pack("f", hparams["attn_config"]["alibi_bias_max"])) |
|---|
| | | fout.write(struct.pack("f", hparams["attn_config"]["clip_qkv"] or 0.0)) |
|---|
| | | fout.write(struct.pack("i", ftype)) |
|---|
| | | |
|---|
| | | vocab_size = hparams["vocab_size"] |
|---|
| | | |
|---|
| | | encoder = tokenizer.vocab |
|---|
| | | # Add added_tokens (special tokens) to the encoder |
|---|
| | | encoder.update(tokenizer.get_added_vocab()) |
|---|
| | | |
|---|
| | | byte_encoder = bytes_to_unicode() |
|---|
| | | byte_decoder = {v: k for k, v in byte_encoder.items()} |
|---|
| | | |
|---|
| | | counter = 0 |
|---|
| | | # sort by value |
|---|
| | | for key in sorted(encoder, key=encoder.get): |
|---|
| | | # workaround for key error when c not found |
|---|
| | | text = "" |
|---|
| | | for c in key: |
|---|
| | | if c not in byte_decoder: |
|---|
| | | text += c |
|---|
| | | else: |
|---|
| | | text += chr(byte_decoder[c]) |
|---|
| | | text = bytearray(text, encoding="utf-8") |
|---|
| | | fout.write(struct.pack("i", len(text))) |
|---|
| | | fout.write(text) |
|---|
| | | counter += 1 |
|---|
| | | |
|---|
| | | # Repeat last token until vocab_size |
|---|
| | | while counter < vocab_size: |
|---|
| | | fout.write(struct.pack("i", len(text))) |
|---|
| | | fout.write(text) |
|---|
| | | counter += 1 |
|---|
| | | |
|---|
| | | if num_parts == 0: |
|---|
| | | part_names = ("pytorch_model.bin",) |
|---|
| | | else: |
|---|
| | | part_names = ( |
|---|
| | | f"pytorch_model-{n:05}-of-{num_parts:05}.bin" for n in range(1, num_parts + 1) |
|---|
| | | ) |
|---|
| | | |
|---|
| | | for part_name in part_names: |
|---|
| | | print(f"\n* Loading part: {part_name}") |
|---|
| | | model_part = torch.load(f"{dir_model}/{part_name}", map_location="cpu") |
|---|
| | | |
|---|
| | | for name in model_part.keys(): |
|---|
| | | data = model_part[name].squeeze() |
|---|
| | | n_dims = len(data.shape) |
|---|
| | | |
|---|
| | | # ftype == 0 -> float32, ftype == 1 -> float16 |
|---|
| | | # default type is fp32 |
|---|
| | | ftype_cur = 0 |
|---|
| | | if ftype == 1 and name[-7:] == ".weight" and n_dims > 1: |
|---|
| | | ftype_cur = 1 |
|---|
| | | data = data.to(dtype=torch.float16 if ftype_cur == 1 else torch.float32).numpy() |
|---|
| | | |
|---|
| | | print( |
|---|
| | | "Processing variable: " + name + " with shape: ", |
|---|
| | | data.shape, |
|---|
| | | "->", |
|---|
| | | data.dtype, |
|---|
| | | ) |
|---|
| | | |
|---|
| | | # header |
|---|
| | | str = name.encode("utf-8") |
|---|
| | | fout.write(struct.pack("iii", n_dims, len(str), ftype_cur)) |
|---|
| | | for i in range(n_dims): |
|---|
| | | fout.write(struct.pack("i", data.shape[n_dims - 1 - i])) |
|---|
| | | fout.write(str) |
|---|
| | | |
|---|
| | | # data |
|---|
| | | data.tofile(fout) |
|---|
| | | |
|---|
| | | # release memory |
|---|
| | | del model_part |
|---|
| | | |
|---|
| | | fout.close() |
|---|
| | | |
|---|
| | | print("Done. Output file: " + fname_out) |
|---|
| | | print("") |
|---|
| New file |
| | |
|---|
| | | #include "ggml/ggml.h" |
|---|
| | | |
|---|
| | | #include "common-ggml.h" |
|---|
| | | #include "common.h" |
|---|
| | | |
|---|
| | | #include <cmath> |
|---|
| | | #include <cstddef> |
|---|
| | | #include <cstdio> |
|---|
| | | #include <cstring> |
|---|
| | | #include <fstream> |
|---|
| | | #include <cinttypes> |
|---|
| | | #include <map> |
|---|
| | | #include <string> |
|---|
| | | #include <utility> |
|---|
| | | #include <vector> |
|---|
| | | |
|---|
| | | #if defined(_MSC_VER) |
|---|
| | | #pragma warning(disable: 4244 4267) // possible loss of data |
|---|
| | | #endif |
|---|
| | | |
|---|
| | | // no defaults for now |
|---|
| | | struct mpt_hparams { |
|---|
| | | int32_t d_model = 0; |
|---|
| | | int32_t max_seq_len = 0; |
|---|
| | | int32_t n_heads = 0; |
|---|
| | | int32_t n_layers = 0; |
|---|
| | | int32_t n_vocab = 0; |
|---|
| | | float alibi_bias_max = 0; |
|---|
| | | float clip_qkv = 0; |
|---|
| | | int32_t ftype = 0; |
|---|
| | | int32_t n_ctx = 0; |
|---|
| | | |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct mpt_layer { |
|---|
| | | // pre normalization |
|---|
| | | struct ggml_tensor * norm_1_weight; |
|---|
| | | |
|---|
| | | // attention |
|---|
| | | struct ggml_tensor * c_attn_wqkv_weight; |
|---|
| | | struct ggml_tensor * c_attn_out_proj_weight; |
|---|
| | | |
|---|
| | | // post normalization |
|---|
| | | struct ggml_tensor * norm_2_weight; |
|---|
| | | |
|---|
| | | // ff |
|---|
| | | struct ggml_tensor * ffn_up_proj; |
|---|
| | | struct ggml_tensor * ffn_down_proj; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct mpt_model { |
|---|
| | | mpt_hparams hparams; |
|---|
| | | |
|---|
| | | struct ggml_tensor * wte_weight; // position embedding |
|---|
| | | struct ggml_tensor * norm_f_weight; // language model head |
|---|
| | | |
|---|
| | | std::vector<mpt_layer> layers; |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | struct ggml_tensor * memory_k; |
|---|
| | | struct ggml_tensor * memory_v; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx; |
|---|
| | | std::map<std::string, struct ggml_tensor *> tensors; |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct mpt_params { |
|---|
| | | int32_t n_threads = std::min(4, (int32_t) std::thread::hardware_concurrency()); |
|---|
| | | |
|---|
| | | int32_t seed = -1; // RNG seed |
|---|
| | | int32_t n_predict = 200; // new tokens to predict |
|---|
| | | int32_t n_batch = 8; // batch size for prompt processing |
|---|
| | | int32_t n_ctx = 512; |
|---|
| | | |
|---|
| | | std::string model = ""; // model path |
|---|
| | | std::string prompt = ""; |
|---|
| | | std::string token_test = ""; |
|---|
| | | |
|---|
| | | bool perplexity = false; |
|---|
| | | |
|---|
| | | // sampling parameters |
|---|
| | | int32_t top_k = 0; |
|---|
| | | float top_p = 1.0f; |
|---|
| | | float temp = 0.8f; |
|---|
| | | int32_t repeat_last_n = 64; |
|---|
| | | float repeat_penalty = 1.02f; |
|---|
| | | |
|---|
| | | }; |
|---|
| | | |
|---|
| | | void mpt_print_usage(int /*argc*/, char ** argv, const mpt_params & params) { |
|---|
| | | fprintf(stderr, "usage: %s [options]\n", argv[0]); |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | fprintf(stderr, "options:\n"); |
|---|
| | | fprintf(stderr, " -h, --help show this help message and exit\n"); |
|---|
| | | fprintf(stderr, " -s SEED, --seed SEED RNG seed (default: -1)\n"); |
|---|
| | | fprintf(stderr, " -t N, --threads N number of threads to use during computation (default: %d)\n", params.n_threads); |
|---|
| | | fprintf(stderr, " -p PROMPT, --prompt PROMPT\n"); |
|---|
| | | fprintf(stderr, " prompt to start generation with (default: random)\n"); |
|---|
| | | fprintf(stderr, " -f FNAME, --file FNAME\n"); |
|---|
| | | fprintf(stderr, " load prompt from a file\n"); |
|---|
| | | fprintf(stderr, " -tt TOKEN_TEST, --token_test TOKEN_TEST\n"); |
|---|
| | | fprintf(stderr, " test tokenization\n"); |
|---|
| | | fprintf(stderr, " -n N, --n_predict N number of tokens to predict (default: %d)\n", params.n_predict); |
|---|
| | | fprintf(stderr, " --top_k N top-k sampling (default: %d, 0 = n_vocab)\n", params.top_k); |
|---|
| | | fprintf(stderr, " --top_p N top-p sampling (default: %.2f)\n", params.top_p); |
|---|
| | | fprintf(stderr, " --temp N temperature (default: %.2f)\n", params.temp); |
|---|
| | | fprintf(stderr, " --repeat-last-n N last n tokens to consider for penalize (default: %d, 0 = disabled, -1 = ctx_size)\n", params.repeat_last_n); |
|---|
| | | fprintf(stderr, " --repeat-penalty N penalize repeat sequence of tokens (default: %.2f, 1.0 = disabled)\n", (double)params.repeat_penalty); |
|---|
| | | fprintf(stderr, " --perplexity compute perplexity over the prompt\n"); |
|---|
| | | fprintf(stderr, " -c N, --ctx-size N size of the prompt context (default: %d)\n", params.n_ctx); |
|---|
| | | fprintf(stderr, " -b N, --batch_size N batch size for prompt processing (default: %d)\n", params.n_batch); |
|---|
| | | fprintf(stderr, " -m FNAME, --model FNAME\n"); |
|---|
| | | fprintf(stderr, " model path (default: %s)\n", params.model.c_str()); |
|---|
| | | fprintf(stderr, "\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | bool mpt_params_parse(int argc, char ** argv, mpt_params & params) { |
|---|
| | | for (int i = 1; i < argc; i++) { |
|---|
| | | std::string arg = argv[i]; |
|---|
| | | |
|---|
| | | if (arg == "-s" || arg == "--seed") { |
|---|
| | | params.seed = std::stoi(argv[++i]); |
|---|
| | | } else if (arg == "-t" || arg == "--threads") { |
|---|
| | | params.n_threads = std::stoi(argv[++i]); |
|---|
| | | } else if (arg == "-p" || arg == "--prompt") { |
|---|
| | | params.prompt = argv[++i]; |
|---|
| | | } else if (arg == "-n" || arg == "--n_predict") { |
|---|
| | | params.n_predict = std::stoi(argv[++i]); |
|---|
| | | } else if (arg == "--top_k") { |
|---|
| | | params.top_k = std::max(1, std::stoi(argv[++i])); |
|---|
| | | } else if (arg == "--top_p") { |
|---|
| | | params.top_p = std::stof(argv[++i]); |
|---|
| | | } else if (arg == "--temp") { |
|---|
| | | params.temp = std::stof(argv[++i]); |
|---|
| | | } else if (arg == "--repeat-last-n") { |
|---|
| | | params.repeat_last_n = std::stof(argv[++i]); |
|---|
| | | } else if (arg == "--repeat-penalty") { |
|---|
| | | params.repeat_penalty = std::stof(argv[++i]); |
|---|
| | | } else if (arg == "--perplexity") { |
|---|
| | | params.perplexity = true; |
|---|
| | | } else if (arg == "-c" || arg == "--ctx-size") { |
|---|
| | | params.n_ctx = std::stoi(argv[++i]); |
|---|
| | | } else if (arg == "-b" || arg == "--batch_size") { |
|---|
| | | params.n_batch = std::stoi(argv[++i]); |
|---|
| | | } else if (arg == "-m" || arg == "--model") { |
|---|
| | | params.model = argv[++i]; |
|---|
| | | } else if (arg == "-h" || arg == "--help") { |
|---|
| | | mpt_print_usage(argc, argv, params); |
|---|
| | | exit(0); |
|---|
| | | } else if (arg == "-f" || arg == "--file") { |
|---|
| | | if (++i > argc) { |
|---|
| | | fprintf(stderr, "Invalid file param"); |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | std::ifstream file(argv[i]); |
|---|
| | | if (!file) { |
|---|
| | | fprintf(stderr, "error: failed to open file '%s'\n", argv[i]); |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | params.prompt.clear(); |
|---|
| | | std::copy(std::istreambuf_iterator<char>(file), std::istreambuf_iterator<char>(), back_inserter(params.prompt)); |
|---|
| | | if (params.prompt.back() == '\n') { |
|---|
| | | params.prompt.pop_back(); |
|---|
| | | } |
|---|
| | | } else if (arg == "-tt" || arg == "--token_test") { |
|---|
| | | params.token_test = argv[++i]; |
|---|
| | | } else { |
|---|
| | | fprintf(stderr, "error: unknown argument: %s\n", arg.c_str()); |
|---|
| | | mpt_print_usage(argc, argv, params); |
|---|
| | | exit(0); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load the model's weights from a file |
|---|
| | | bool mpt_model_load(const std::string & fname, mpt_model & model, gpt_vocab & vocab) { |
|---|
| | | printf("%s: loading model from '%s' - please wait ...\n", __func__, fname.c_str()); |
|---|
| | | |
|---|
| | | auto fin = std::ifstream(fname, std::ios::binary); |
|---|
| | | if (!fin) { |
|---|
| | | fprintf(stderr, "%s: failed to open '%s'\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // verify magic |
|---|
| | | { |
|---|
| | | uint32_t magic; |
|---|
| | | fin.read((char *)&magic, sizeof(magic)); |
|---|
| | | if (magic != GGML_FILE_MAGIC) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad magic)\n", __func__, fname.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load hparams |
|---|
| | | { |
|---|
| | | auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | fin.read((char *) &hparams.d_model, sizeof(hparams.d_model)); |
|---|
| | | fin.read((char *) &hparams.max_seq_len, sizeof(hparams.max_seq_len)); |
|---|
| | | fin.read((char *) &hparams.n_heads, sizeof(hparams.n_heads)); |
|---|
| | | fin.read((char *) &hparams.n_layers, sizeof(hparams.n_layers)); |
|---|
| | | fin.read((char *) &hparams.n_vocab, sizeof(hparams.n_vocab)); |
|---|
| | | fin.read((char *) &hparams.alibi_bias_max, sizeof(hparams.alibi_bias_max)); |
|---|
| | | fin.read((char *) &hparams.clip_qkv, sizeof(hparams.clip_qkv)); |
|---|
| | | fin.read((char *) &hparams.ftype, sizeof(hparams.ftype)); |
|---|
| | | |
|---|
| | | hparams.n_ctx = std::min(hparams.max_seq_len, hparams.n_ctx); |
|---|
| | | |
|---|
| | | const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR; |
|---|
| | | |
|---|
| | | printf("%s: d_model = %d\n", __func__, hparams.d_model); |
|---|
| | | printf("%s: max_seq_len = %d\n", __func__, hparams.max_seq_len); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, hparams.n_ctx); |
|---|
| | | printf("%s: n_heads = %d\n", __func__, hparams.n_heads); |
|---|
| | | printf("%s: n_layers = %d\n", __func__, hparams.n_layers); |
|---|
| | | printf("%s: n_vocab = %d\n", __func__, hparams.n_vocab); |
|---|
| | | printf("%s: alibi_bias_max = %f\n", __func__, hparams.alibi_bias_max); |
|---|
| | | printf("%s: clip_qkv = %f\n", __func__, hparams.clip_qkv); |
|---|
| | | printf("%s: ftype = %d\n", __func__, hparams.ftype); |
|---|
| | | printf("%s: qntvr = %d\n", __func__, qntvr); |
|---|
| | | |
|---|
| | | hparams.ftype %= GGML_QNT_VERSION_FACTOR; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load vocab |
|---|
| | | { |
|---|
| | | const int32_t n_vocab = model.hparams.n_vocab; |
|---|
| | | |
|---|
| | | std::string word; |
|---|
| | | std::vector<char> buf(128); |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_vocab; i++) { |
|---|
| | | uint32_t len; |
|---|
| | | fin.read((char *) &len, sizeof(len)); |
|---|
| | | |
|---|
| | | buf.resize(len); |
|---|
| | | fin.read((char *) buf.data(), len); |
|---|
| | | word.assign(buf.data(), len); |
|---|
| | | |
|---|
| | | // Convert token from utf-8 |
|---|
| | | std::wstring word_multibytes = convert_to_wstring(word); |
|---|
| | | word.resize(word_multibytes.size()); |
|---|
| | | for (size_t w = 0; w < word_multibytes.size(); w++) { |
|---|
| | | word[w] = uint8_t(word_multibytes[w]); |
|---|
| | | } |
|---|
| | | |
|---|
| | | vocab.token_to_id[word] = i; |
|---|
| | | vocab.id_to_token[i] = word; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for the big tensors, we have the option to store the data in 16-bit |
|---|
| | | // floats or quantized in order to save memory and also to speed up the |
|---|
| | | // computation |
|---|
| | | ggml_type wtype = ggml_ftype_to_ggml_type((ggml_ftype)(model.hparams.ftype)); |
|---|
| | | if (wtype == GGML_TYPE_COUNT) { |
|---|
| | | fprintf(stderr, "%s: invalid model file '%s' (bad ftype value %d)\n", __func__, fname.c_str(), |
|---|
| | | model.hparams.ftype); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto & ctx = model.ctx; |
|---|
| | | |
|---|
| | | size_t ctx_size = 0; |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | const size_t n_ctx = hparams.n_ctx; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const size_t n_embd = hparams.d_model; |
|---|
| | | const size_t n_layer = hparams.n_layers; |
|---|
| | | const size_t n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | ctx_size += ggml_row_size(wtype, n_embd * n_vocab); // wte_weight |
|---|
| | | ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // norm_f_weight |
|---|
| | | |
|---|
| | | ctx_size += n_layer * (ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_1_weight |
|---|
| | | |
|---|
| | | ctx_size += n_layer * (ggml_row_size(wtype, 3 * n_embd * n_embd)); // attn_Wqkv_weight |
|---|
| | | ctx_size += n_layer * (ggml_row_size(wtype, n_embd * n_embd)); // attn_out_proj_weight |
|---|
| | | |
|---|
| | | ctx_size += n_layer * (ggml_row_size(GGML_TYPE_F32, n_embd)); // ln_2_weight |
|---|
| | | |
|---|
| | | ctx_size += n_layer * (ggml_row_size(wtype, 4 * n_embd * n_embd)); // mlp_mlp_up_weight |
|---|
| | | ctx_size += n_layer * (ggml_row_size(wtype, 4 * n_embd * n_embd)); // mlp_mlp_down_weight |
|---|
| | | |
|---|
| | | ctx_size += n_ctx * n_layer * ggml_row_size(GGML_TYPE_F16, n_embd); // memory_k |
|---|
| | | ctx_size += n_ctx * n_layer * ggml_row_size(GGML_TYPE_F16, n_embd); // memory_v |
|---|
| | | |
|---|
| | | ctx_size += (1 + 6 * n_layer) * 512; // object overhead |
|---|
| | | |
|---|
| | | printf("%s: ggml ctx size = %6.2f MB\n", __func__, ctx_size / (1024.0 * 1024.0)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // create the ggml context |
|---|
| | | { |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ ctx_size, |
|---|
| | | /*.mem_buffer =*/ NULL, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | model.ctx = ggml_init(params); |
|---|
| | | if (!model.ctx) { |
|---|
| | | fprintf(stderr, "%s: ggml_init() failed\n", __func__); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // prepare memory for the weights |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const size_t n_embd = hparams.d_model; |
|---|
| | | const size_t n_layer = hparams.n_layers; |
|---|
| | | const size_t n_vocab = hparams.n_vocab; |
|---|
| | | |
|---|
| | | model.layers.resize(n_layer); |
|---|
| | | |
|---|
| | | model.wte_weight = ggml_new_tensor_2d(ctx, wtype, n_embd, n_vocab); |
|---|
| | | model.norm_f_weight = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["transformer.wte.weight"] = model.wte_weight; |
|---|
| | | model.tensors["transformer.norm_f.weight"] = model.norm_f_weight; |
|---|
| | | |
|---|
| | | for (int i = 0; i < (int) n_layer; ++i) { |
|---|
| | | auto & layer = model.layers[i]; |
|---|
| | | |
|---|
| | | layer.norm_1_weight = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.c_attn_wqkv_weight = ggml_new_tensor_2d(ctx, wtype, n_embd, 3 * n_embd); |
|---|
| | | layer.c_attn_out_proj_weight = ggml_new_tensor_2d(ctx, wtype, n_embd, n_embd); |
|---|
| | | layer.norm_2_weight = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd); |
|---|
| | | layer.ffn_up_proj = ggml_new_tensor_2d(ctx, wtype, n_embd, 4 * n_embd); |
|---|
| | | layer.ffn_down_proj = ggml_new_tensor_2d(ctx, wtype, 4 * n_embd, n_embd); |
|---|
| | | |
|---|
| | | // map by name |
|---|
| | | model.tensors["transformer.blocks." + std::to_string(i) + ".norm_1.weight"] = layer.norm_1_weight; |
|---|
| | | model.tensors["transformer.blocks." + std::to_string(i) + ".attn.Wqkv.weight"] = layer.c_attn_wqkv_weight; |
|---|
| | | model.tensors["transformer.blocks." + std::to_string(i) + ".attn.out_proj.weight"] = layer.c_attn_out_proj_weight; |
|---|
| | | model.tensors["transformer.blocks." + std::to_string(i) + ".norm_2.weight"] = layer.norm_2_weight; |
|---|
| | | model.tensors["transformer.blocks." + std::to_string(i) + ".ffn.up_proj.weight"] = layer.ffn_up_proj; |
|---|
| | | model.tensors["transformer.blocks." + std::to_string(i) + ".ffn.down_proj.weight"] = layer.ffn_down_proj; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // key + value memory |
|---|
| | | { |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const size_t n_embd = hparams.d_model; |
|---|
| | | const size_t n_layer = hparams.n_layers; |
|---|
| | | |
|---|
| | | const int64_t n_mem = n_layer * n_ctx; |
|---|
| | | const int64_t n_elements = n_embd * n_mem; |
|---|
| | | |
|---|
| | | model.memory_k = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements); |
|---|
| | | model.memory_v = ggml_new_tensor_1d(ctx, GGML_TYPE_F16, n_elements); |
|---|
| | | |
|---|
| | | const size_t memory_size = ggml_nbytes(model.memory_k) + ggml_nbytes(model.memory_v); |
|---|
| | | |
|---|
| | | printf("%s: memory_size = %8.2f MB, n_mem = %" PRId64 "\n", __func__, memory_size / 1024.0 / 1024.0, n_mem); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // load weights |
|---|
| | | { |
|---|
| | | int n_tensors = 0; |
|---|
| | | size_t total_size = 0; |
|---|
| | | |
|---|
| | | printf("%s: ", __func__); |
|---|
| | | |
|---|
| | | while (true) { |
|---|
| | | int32_t n_dims; |
|---|
| | | int32_t length; |
|---|
| | | int32_t ttype; |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(&n_dims), sizeof(n_dims)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&length), sizeof(length)); |
|---|
| | | fin.read(reinterpret_cast<char *>(&ttype), sizeof(ttype)); |
|---|
| | | |
|---|
| | | if (fin.eof()) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int32_t nelements = 1; |
|---|
| | | int32_t ne[2] = {1, 1}; |
|---|
| | | for (int i = 0; i < n_dims; ++i) { |
|---|
| | | fin.read(reinterpret_cast<char *>(&ne[i]), sizeof(ne[i])); |
|---|
| | | nelements *= ne[i]; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::string name(length, 0); |
|---|
| | | fin.read(&name[0], length); |
|---|
| | | |
|---|
| | | if (model.tensors.find(name) == model.tensors.end()) { |
|---|
| | | fprintf(stderr, "%s: unknown tensor '%s' in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | auto tensor = model.tensors[name]; |
|---|
| | | if (ggml_nelements(tensor) != nelements) { |
|---|
| | | fprintf(stderr, "%s: tensor '%s' has wrong size in model file\n", __func__, name.c_str()); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1]) { |
|---|
| | | fprintf(stderr, |
|---|
| | | "%s: tensor '%s' has wrong shape in model file: got [%5d, " |
|---|
| | | "%5d], expected [%5d, %5d]\n", |
|---|
| | | __func__, name.c_str(), (int)tensor->ne[0], (int)tensor->ne[1], ne[0], ne[1]); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // for debugging |
|---|
| | | if (0) { |
|---|
| | | printf("%24s - [%5d, %5d], type = %6s, %6.2f MB, %9zu bytes\n", name.c_str(), ne[0], ne[1], |
|---|
| | | ggml_type_name(ggml_type(ttype)), ggml_nbytes(tensor) / 1024.0 / 1024.0, ggml_nbytes(tensor)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | const size_t bpe = ggml_type_size(ggml_type(ttype)); |
|---|
| | | |
|---|
| | | if ((nelements * bpe) / ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) { |
|---|
| | | fprintf(stderr, |
|---|
| | | "%s: tensor '%s' has wrong size in model file: got %zu, " |
|---|
| | | "expected %zu\n", |
|---|
| | | __func__, name.c_str(), ggml_nbytes(tensor), nelements * bpe); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.read(reinterpret_cast<char *>(tensor->data), ggml_nbytes(tensor)); |
|---|
| | | |
|---|
| | | total_size += ggml_nbytes(tensor); |
|---|
| | | if (++n_tensors % 8 == 0) { |
|---|
| | | printf("."); |
|---|
| | | fflush(stdout); |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf(" done\n"); |
|---|
| | | |
|---|
| | | printf("%s: model size = %8.2f MB / num tensors = %d\n", __func__, total_size / 1024.0 / 1024.0, n_tensors); |
|---|
| | | } |
|---|
| | | |
|---|
| | | fin.close(); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // evaluate the transformer |
|---|
| | | // |
|---|
| | | // - model: the model |
|---|
| | | // - n_threads: number of threads to use |
|---|
| | | // - n_past: the context size so far |
|---|
| | | // - embd_inp: the embeddings of the tokens in the context |
|---|
| | | // - embd_w: the predicted logits for the next token |
|---|
| | | // |
|---|
| | | bool mpt_eval(const mpt_model & model, const int n_threads, const int n_past, |
|---|
| | | const std::vector<gpt_vocab::id> & embd_inp, std::vector<float> & embd_w, bool logits_all, size_t & mem_per_token) { |
|---|
| | | const int N = embd_inp.size(); |
|---|
| | | |
|---|
| | | const auto & hparams = model.hparams; |
|---|
| | | |
|---|
| | | const int n_embd = hparams.d_model; |
|---|
| | | const int n_layer = hparams.n_layers; |
|---|
| | | const int n_head = hparams.n_heads; |
|---|
| | | const int n_vocab = hparams.n_vocab; |
|---|
| | | const int n_ctx = hparams.n_ctx; |
|---|
| | | const float eps = 1e-5f; |
|---|
| | | |
|---|
| | | static size_t buf_size = 256u * 1024 * 1024; |
|---|
| | | static void * buf = malloc(buf_size); |
|---|
| | | |
|---|
| | | // use 2 scratch buffers |
|---|
| | | // TODO: very hacky solution - reimplement in a more elegant way |
|---|
| | | static size_t scr0_size = 256u*1024*1024; |
|---|
| | | static void * scr0 = malloc(scr0_size); |
|---|
| | | |
|---|
| | | static size_t scr1_size = 256u*1024*1024; |
|---|
| | | static void * scr1 = malloc(scr1_size); |
|---|
| | | |
|---|
| | | if (mem_per_token > 0 && mem_per_token * N > buf_size) { |
|---|
| | | const size_t buf_size_new = 1.1 * (mem_per_token * N); // add 10% to account for ggml object overhead |
|---|
| | | // printf("\n%s: reallocating buffer from %zu to %zu bytes\n", __func__, |
|---|
| | | // buf_size, buf_size_new); |
|---|
| | | |
|---|
| | | // reallocate |
|---|
| | | buf_size = buf_size_new; |
|---|
| | | buf = realloc(buf, buf_size); |
|---|
| | | if (buf == nullptr) { |
|---|
| | | fprintf(stderr, "%s: failed to allocate %zu bytes\n", __func__, buf_size); |
|---|
| | | return false; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_init_params params = { |
|---|
| | | /*.mem_size =*/ buf_size, |
|---|
| | | /*.mem_buffer =*/ buf, |
|---|
| | | /*.no_alloc =*/ false, |
|---|
| | | }; |
|---|
| | | |
|---|
| | | struct ggml_context * ctx0 = ggml_init(params); |
|---|
| | | struct ggml_cgraph * gf = ggml_new_graph(ctx0); |
|---|
| | | |
|---|
| | | struct ggml_tensor * embd = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N); |
|---|
| | | memcpy(embd->data, embd_inp.data(), N * ggml_element_size(embd)); |
|---|
| | | |
|---|
| | | struct ggml_tensor * inpL = ggml_get_rows(ctx0, model.wte_weight, embd); |
|---|
| | | |
|---|
| | | for (int il = 0; il < n_layer; ++il) { |
|---|
| | | |
|---|
| | | struct ggml_tensor * cur; |
|---|
| | | |
|---|
| | | ggml_set_scratch(ctx0, { 0, scr0_size, scr0, }); |
|---|
| | | |
|---|
| | | // a = self.ln_1(x) |
|---|
| | | { |
|---|
| | | cur = ggml_norm(ctx0, inpL, eps); |
|---|
| | | |
|---|
| | | cur = ggml_mul(ctx0, ggml_repeat(ctx0, model.layers[il].norm_1_weight, cur), cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // self-attention |
|---|
| | | // b, _, past_key_value = self.attn(a, past_key_value=past_key_value, |
|---|
| | | // attn_bias=attn_bias, attention_mask=attention_mask, |
|---|
| | | // is_causal=is_causal) |
|---|
| | | { |
|---|
| | | // compute QKV |
|---|
| | | cur = ggml_mul_mat(ctx0, model.layers[il].c_attn_wqkv_weight, cur); |
|---|
| | | |
|---|
| | | if (model.hparams.clip_qkv > 0.0f) { |
|---|
| | | cur = ggml_clamp(ctx0, cur, -model.hparams.clip_qkv, model.hparams.clip_qkv); |
|---|
| | | } |
|---|
| | | |
|---|
| | | struct ggml_tensor * Qcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 0 * sizeof(float) * n_embd); |
|---|
| | | struct ggml_tensor * Kcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 1 * sizeof(float) * n_embd); |
|---|
| | | struct ggml_tensor * Vcur = ggml_view_2d(ctx0, cur, n_embd, N, cur->nb[1], 2 * sizeof(float) * n_embd); |
|---|
| | | |
|---|
| | | // store key and value to memory |
|---|
| | | { |
|---|
| | | struct ggml_tensor * k = |
|---|
| | | ggml_view_1d(ctx0, model.memory_k, N * n_embd, |
|---|
| | | (ggml_element_size(model.memory_k) * n_embd) * (il * n_ctx + n_past)); |
|---|
| | | struct ggml_tensor * v = |
|---|
| | | ggml_view_1d(ctx0, model.memory_v, N * n_embd, |
|---|
| | | (ggml_element_size(model.memory_v) * n_embd) * (il * n_ctx + n_past)); |
|---|
| | | |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k)); |
|---|
| | | ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v)); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // Q = Qcur.contiguous().view(n_embd/n_head, n_head, N).permute(0, |
|---|
| | | // 2, 1, 3) [64, N, 12] |
|---|
| | | struct ggml_tensor * Q = ggml_permute( |
|---|
| | | ctx0, ggml_cpy(ctx0, Qcur, ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_embd / n_head, n_head, N)), 0, 2, |
|---|
| | | 1, 3); |
|---|
| | | |
|---|
| | | // K = Kmem.view(n_embd/n_head, n_head, n_past + N).permute(0, 2, 1, |
|---|
| | | // 3) [64, n_past + N, 12] |
|---|
| | | struct ggml_tensor * K = |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_k, (n_past + N) * n_embd, |
|---|
| | | il * n_ctx * ggml_element_size(model.memory_k) * n_embd), |
|---|
| | | n_embd / n_head, n_head, n_past + N), |
|---|
| | | 0, 2, 1, 3); |
|---|
| | | // K * Q |
|---|
| | | struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q); |
|---|
| | | |
|---|
| | | // KQ_scaled = KQ / sqrt(n_embd/n_head) |
|---|
| | | struct ggml_tensor * KQ_scaled = |
|---|
| | | ggml_scale(ctx0, KQ, 1.0f / sqrt(float(n_embd) / n_head)); |
|---|
| | | |
|---|
| | | struct ggml_tensor * KQ_scaled_alibi = |
|---|
| | | ggml_alibi(ctx0, KQ_scaled, n_past, n_head, model.hparams.alibi_bias_max); |
|---|
| | | |
|---|
| | | // KQ_masked = mask_past(KQ_scaled) |
|---|
| | | struct ggml_tensor * KQ_masked = ggml_diag_mask_inf(ctx0, KQ_scaled_alibi, n_past); |
|---|
| | | |
|---|
| | | // KQ = soft_max(KQ_masked) |
|---|
| | | struct ggml_tensor * KQ_soft_max = ggml_soft_max(ctx0, KQ_masked); |
|---|
| | | |
|---|
| | | // V_trans = Vmem.view(n_embd/n_head, n_head, n_past + N).permute(1, |
|---|
| | | // 2, 0, 3).contiguous() [n_past + N, 64, 12] |
|---|
| | | struct ggml_tensor * V_trans = ggml_cpy( |
|---|
| | | ctx0, |
|---|
| | | ggml_permute(ctx0, |
|---|
| | | ggml_reshape_3d(ctx0, |
|---|
| | | ggml_view_1d(ctx0, model.memory_v, (n_past + N) * n_embd, |
|---|
| | | il * n_ctx * ggml_element_size(model.memory_v) * n_embd), |
|---|
| | | n_embd / n_head, n_head, n_past + N), |
|---|
| | | 1, 2, 0, 3), |
|---|
| | | ggml_new_tensor_3d(ctx0, model.memory_v->type, n_past + N, n_embd / n_head, n_head)); |
|---|
| | | |
|---|
| | | // KQV = transpose(V) * KQ_soft_max |
|---|
| | | struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V_trans, KQ_soft_max); |
|---|
| | | |
|---|
| | | // KQV_merged = KQV.permute(0, 2, 1, 3) |
|---|
| | | struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3); |
|---|
| | | |
|---|
| | | // cur = KQV_merged.contiguous().view(n_embd, N) |
|---|
| | | cur = ggml_cpy(ctx0, KQV_merged, ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, N)); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | { cur = ggml_mul_mat(ctx0, model.layers[il].c_attn_out_proj_weight, cur); } |
|---|
| | | } |
|---|
| | | |
|---|
| | | inpL = ggml_add(ctx0, inpL, cur); |
|---|
| | | |
|---|
| | | ggml_set_scratch(ctx0, { 0, scr1_size, scr1, }); |
|---|
| | | |
|---|
| | | // m = self.ln_2(x) |
|---|
| | | { |
|---|
| | | cur = ggml_norm(ctx0, inpL, eps); |
|---|
| | | |
|---|
| | | cur = ggml_mul(ctx0, ggml_repeat(ctx0, model.layers[il].norm_2_weight, cur), cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // n = self.mlp(m) |
|---|
| | | { |
|---|
| | | |
|---|
| | | cur = ggml_mul_mat(ctx0, model.layers[il].ffn_up_proj, cur); |
|---|
| | | |
|---|
| | | // GELU activation |
|---|
| | | cur = ggml_gelu(ctx0, cur); |
|---|
| | | |
|---|
| | | // projection |
|---|
| | | // cur = proj_w*cur + proj_b |
|---|
| | | cur = ggml_mul_mat(ctx0, model.layers[il].ffn_down_proj, cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // x = x + n |
|---|
| | | inpL = ggml_add(ctx0, inpL, cur); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_set_scratch(ctx0, { 0, scr0_size, scr0, }); |
|---|
| | | |
|---|
| | | // norm |
|---|
| | | { |
|---|
| | | inpL = ggml_norm(ctx0, inpL, eps); |
|---|
| | | // inpL = ln_f_g*inpL |
|---|
| | | inpL = ggml_mul(ctx0, ggml_repeat(ctx0, model.norm_f_weight, inpL), inpL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_set_scratch(ctx0, { 0, 0, nullptr, }); |
|---|
| | | |
|---|
| | | // output embedding weight tied to input embedding |
|---|
| | | inpL = ggml_mul_mat(ctx0, model.wte_weight, inpL); |
|---|
| | | |
|---|
| | | // logits -> probs |
|---|
| | | // inpL = ggml_soft_max(ctx0, inpL); |
|---|
| | | |
|---|
| | | // run the computation |
|---|
| | | ggml_build_forward_expand(gf, inpL); |
|---|
| | | ggml_graph_compute_with_ctx(ctx0, gf, n_threads); |
|---|
| | | |
|---|
| | | // std::cout << "Qcur" << std::endl; |
|---|
| | | // print_tensor(Qcur); |
|---|
| | | |
|---|
| | | // if (n_past%100 == 0) { |
|---|
| | | // ggml_graph_print(&gf); |
|---|
| | | // ggml_graph_dump_dot(&gf, NULL, "mpt-model.dot"); |
|---|
| | | // } |
|---|
| | | |
|---|
| | | if (logits_all) { |
|---|
| | | // return result for all tokens |
|---|
| | | embd_w.resize(n_vocab *N); |
|---|
| | | memcpy(embd_w.data(), (float *)ggml_get_data(inpL) , sizeof(float) * n_vocab * N); |
|---|
| | | } else { |
|---|
| | | // return result for just the last token |
|---|
| | | embd_w.resize(n_vocab); |
|---|
| | | memcpy(embd_w.data(), (float *)ggml_get_data(inpL) + (n_vocab * (N - 1)), sizeof(float) * n_vocab); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (mem_per_token == 0) { |
|---|
| | | mem_per_token = ggml_used_mem(ctx0) / N; |
|---|
| | | } |
|---|
| | | // printf("used_mem = %zu\n", ggml_used_mem(ctx0)); |
|---|
| | | |
|---|
| | | ggml_free(ctx0); |
|---|
| | | |
|---|
| | | return true; |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::vector<float> softmax(const std::vector<float> & logits) { |
|---|
| | | std::vector<float> probs(logits.size()); |
|---|
| | | float max_logit = logits[0]; |
|---|
| | | for (float v : logits) max_logit = std::max(max_logit, v); |
|---|
| | | double sum_exp = 0.0; |
|---|
| | | for (size_t i = 0; i < logits.size(); i++) { |
|---|
| | | // Subtract the maximum logit value from the current logit value for numerical stability |
|---|
| | | const float logit = logits[i] - max_logit; |
|---|
| | | const float exp_logit = expf(logit); |
|---|
| | | sum_exp += exp_logit; |
|---|
| | | probs[i] = exp_logit; |
|---|
| | | } |
|---|
| | | for (size_t i = 0; i < probs.size(); i++) probs[i] /= sum_exp; |
|---|
| | | return probs; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int perplexity(const mpt_params & params) { |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("%s: n_threads = %d\n", __func__, params.n_threads); |
|---|
| | | printf("%s: n_batch = %d\n", __func__, params.n_batch); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, params.n_ctx); |
|---|
| | | printf("\n"); |
|---|
| | | |
|---|
| | | int64_t t_load_us = 0; |
|---|
| | | |
|---|
| | | gpt_vocab vocab; |
|---|
| | | mpt_model model; |
|---|
| | | |
|---|
| | | model.hparams.n_ctx = params.n_ctx; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!mpt_model_load(params.model, model, vocab)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int64_t t_predict_us = 0; |
|---|
| | | |
|---|
| | | std::vector<float> logits; |
|---|
| | | |
|---|
| | | // tokenize the prompt |
|---|
| | | std::vector<int> embd_inp = ::gpt_tokenize(vocab, params.prompt); |
|---|
| | | |
|---|
| | | printf("%s: number of tokens in prompt = %zu\n", __func__, embd_inp.size()); |
|---|
| | | |
|---|
| | | // determine the required inference memory per token: |
|---|
| | | size_t mem_per_token = 0; |
|---|
| | | mpt_eval(model, params.n_threads, 0, {0, 1, 2, 3}, logits, false, mem_per_token); |
|---|
| | | |
|---|
| | | int count = 0; |
|---|
| | | |
|---|
| | | const int n_chunk = embd_inp.size() / params.n_ctx; |
|---|
| | | |
|---|
| | | const int n_vocab = model.hparams.n_vocab; |
|---|
| | | const int n_batch = params.n_batch; |
|---|
| | | |
|---|
| | | double nll = 0.0; |
|---|
| | | fprintf(stderr, "%s: calculating perplexity over %d chunks, batch_size=%d\n", __func__, n_chunk, n_batch); |
|---|
| | | |
|---|
| | | for (int i = 0; i < n_chunk; ++i) { |
|---|
| | | |
|---|
| | | const int start = i * params.n_ctx; |
|---|
| | | const int end = start + params.n_ctx; |
|---|
| | | |
|---|
| | | const int num_batches = (params.n_ctx + n_batch - 1) / n_batch; |
|---|
| | | |
|---|
| | | std::vector<float> logits; |
|---|
| | | |
|---|
| | | const auto t_start = std::chrono::high_resolution_clock::now(); |
|---|
| | | |
|---|
| | | for (int j = 0; j < num_batches; ++j) { |
|---|
| | | |
|---|
| | | const int batch_start = start + j * n_batch; |
|---|
| | | const int batch_size = std::min(end - batch_start, n_batch); |
|---|
| | | |
|---|
| | | std::vector<gpt_vocab::id> embd; |
|---|
| | | |
|---|
| | | for(int p=0;p<batch_size;p++) { |
|---|
| | | embd.push_back( embd_inp[batch_start+p] ); |
|---|
| | | } |
|---|
| | | |
|---|
| | | std::vector<float> batch_logits;// = llama_get_logits(ctx); |
|---|
| | | |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!mpt_eval(model, params.n_threads, j * batch_size, embd, batch_logits, true, mem_per_token)) { |
|---|
| | | printf("%s: failed to evaluate model\n", __func__); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_predict_us += ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | logits.insert(logits.end(), batch_logits.data(), batch_logits.data() + batch_size * n_vocab); |
|---|
| | | |
|---|
| | | } |
|---|
| | | |
|---|
| | | const auto t_end = std::chrono::high_resolution_clock::now(); |
|---|
| | | |
|---|
| | | if (i == 0) { |
|---|
| | | const float t_total = std::chrono::duration<float>(t_end - t_start).count(); |
|---|
| | | fprintf(stderr, "%s: %.2f seconds per pass - ETA ", __func__, t_total); |
|---|
| | | int total_seconds = (int)(t_total * n_chunk); |
|---|
| | | if (total_seconds >= 60*60) { |
|---|
| | | fprintf(stderr, "%d hours ", total_seconds / (60*60)); |
|---|
| | | total_seconds = total_seconds % (60*60); |
|---|
| | | } |
|---|
| | | fprintf(stderr, "%d minutes\n", total_seconds / 60); |
|---|
| | | |
|---|
| | | printf("\nChunk\tPPL cumulative\tPPL chunk\n"); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // We get the logits for all the tokens in the context window (params.n_ctx) |
|---|
| | | // from llama_eval above. Now, based on https://huggingface.co/docs/transformers/perplexity, |
|---|
| | | // calculate the perplexity over the last half of the window (so the model always has |
|---|
| | | // some context to predict the token). |
|---|
| | | // |
|---|
| | | // We rely on the fact that attention in the forward pass only looks at previous |
|---|
| | | // tokens here, so the logits returned for each token are an accurate representation |
|---|
| | | // of what the model would have predicted at that point. |
|---|
| | | // |
|---|
| | | // Example, we have a context window of 512, we will compute perplexity for each of the |
|---|
| | | // last 256 tokens. Then, we split the input up into context window size chunks to |
|---|
| | | // process the entire prompt. |
|---|
| | | |
|---|
| | | double nllchunk = 0.0; |
|---|
| | | int countchunk = 0; |
|---|
| | | |
|---|
| | | for (int j = std::min(512, params.n_ctx / 2); j < params.n_ctx - 1; ++j) { |
|---|
| | | // Calculate probability of next token, given the previous ones. |
|---|
| | | const std::vector<float> tok_logits( |
|---|
| | | logits.begin() + (j + 0) * n_vocab, |
|---|
| | | logits.begin() + (j + 1) * n_vocab); |
|---|
| | | |
|---|
| | | const float prob = softmax(tok_logits)[embd_inp[ start+ j + 1]]; |
|---|
| | | |
|---|
| | | nllchunk += -std::log(prob); |
|---|
| | | ++countchunk; |
|---|
| | | } |
|---|
| | | |
|---|
| | | nll += nllchunk; |
|---|
| | | count += countchunk; |
|---|
| | | |
|---|
| | | // perplexity is e^(average negative log-likelihood) |
|---|
| | | printf("%d\t%.8lf\t%.8lf\n", i + 1, std::exp(nll / count), std::exp(nllchunk/countchunk) ); |
|---|
| | | fflush(stdout); |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n\n"); |
|---|
| | | printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token); |
|---|
| | | printf("%s: load time = %8.2f ms\n", __func__, t_load_us / 1000.0f); |
|---|
| | | printf("%s: eval time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us / 1000.0f, t_predict_us / 1000.0f / (n_chunk * params.n_ctx)); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us) / 1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| | | |
|---|
| | | int main(int argc, char ** argv) { |
|---|
| | | mpt_params params; |
|---|
| | | |
|---|
| | | if (mpt_params_parse(argc, argv, params) == false) { |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.perplexity) { |
|---|
| | | return perplexity(params); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_time_init(); |
|---|
| | | |
|---|
| | | const int64_t t_main_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (params.seed < 0) { |
|---|
| | | params.seed = time(NULL); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.n_predict < 0) { |
|---|
| | | params.n_predict = 0; |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("%s: seed = %d\n", __func__, params.seed); |
|---|
| | | printf("%s: n_threads = %d\n", __func__, params.n_threads); |
|---|
| | | printf("%s: n_batch = %d\n", __func__, params.n_batch); |
|---|
| | | printf("%s: n_ctx = %d\n", __func__, params.n_ctx); |
|---|
| | | printf("%s: n_predict = %d\n\n", __func__, params.n_predict); |
|---|
| | | |
|---|
| | | std::mt19937 rng(params.seed); |
|---|
| | | if (params.prompt.empty()) { |
|---|
| | | params.prompt = gpt_random_prompt(rng); |
|---|
| | | } |
|---|
| | | |
|---|
| | | int64_t t_load_us = 0; |
|---|
| | | |
|---|
| | | gpt_vocab vocab; |
|---|
| | | mpt_model model; |
|---|
| | | |
|---|
| | | model.hparams.n_ctx = params.n_ctx; |
|---|
| | | |
|---|
| | | // load the model |
|---|
| | | { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!mpt_model_load(params.model, model, vocab)) { |
|---|
| | | fprintf(stderr, "%s: failed to load model from '%s'\n", __func__, params.model.c_str()); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_load_us = ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | test_gpt_tokenizer(vocab, params.token_test); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.top_k == 0) { |
|---|
| | | params.top_k = model.hparams.n_vocab; |
|---|
| | | } |
|---|
| | | |
|---|
| | | if (params.repeat_last_n == -1) { |
|---|
| | | params.repeat_last_n = params.n_ctx; |
|---|
| | | } |
|---|
| | | |
|---|
| | | printf("\n"); |
|---|
| | | printf("%s: temp = %.3f\n", __func__, params.temp); |
|---|
| | | printf("%s: top_k = %d\n", __func__, params.top_k); |
|---|
| | | printf("%s: top_p = %.3f\n", __func__, params.top_p); |
|---|
| | | printf("%s: repeat_last_n = %d\n", __func__, params.repeat_last_n); |
|---|
| | | printf("%s: repeat_penalty = %.3f\n", __func__, params.repeat_penalty); |
|---|
| | | |
|---|
| | | int64_t t_sample_us = 0; |
|---|
| | | int64_t t_predict_us = 0; |
|---|
| | | |
|---|
| | | std::vector<int32_t> last_n_tokens(params.n_ctx); |
|---|
| | | std::fill(last_n_tokens.begin(), last_n_tokens.end(), 0); |
|---|
| | | |
|---|
| | | // tokenize the prompt |
|---|
| | | std::vector<int> embd_inp = ::gpt_tokenize(vocab, params.prompt); |
|---|
| | | |
|---|
| | | printf("\n"); |
|---|
| | | printf("%s: number of tokens in prompt = %zu\n", __func__, embd_inp.size()); |
|---|
| | | |
|---|
| | | for (size_t i = 0; i < embd_inp.size(); i++) { |
|---|
| | | printf("%s: token[%zu] = %6d\n", __func__, i, embd_inp[i]); |
|---|
| | | } |
|---|
| | | printf("\n"); |
|---|
| | | |
|---|
| | | std::vector<gpt_vocab::id> embd; |
|---|
| | | std::vector<float> logits; |
|---|
| | | |
|---|
| | | // determine the required inference memory per token: |
|---|
| | | size_t mem_per_token = 0; |
|---|
| | | mpt_eval(model, params.n_threads, 0, {0, 1, 2, 3}, logits, false, mem_per_token); |
|---|
| | | |
|---|
| | | int n_past = 0; |
|---|
| | | int n_consumed = 0; |
|---|
| | | int n_sampled = 0; |
|---|
| | | |
|---|
| | | while (n_sampled < params.n_predict) { |
|---|
| | | // predict |
|---|
| | | if (embd.size() > 0) { |
|---|
| | | const int64_t t_start_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | if (!mpt_eval(model, params.n_threads, n_past, embd, logits, false, mem_per_token)) { |
|---|
| | | printf("%s: failed to predict\n", __func__); |
|---|
| | | return 1; |
|---|
| | | } |
|---|
| | | |
|---|
| | | t_predict_us += ggml_time_us() - t_start_us; |
|---|
| | | |
|---|
| | | n_past += embd.size(); |
|---|
| | | embd.clear(); |
|---|
| | | } |
|---|
| | | |
|---|
| | | if ((int)embd_inp.size() <= n_consumed) { |
|---|
| | | // sample next token |
|---|
| | | |
|---|
| | | const int top_k = params.top_k; |
|---|
| | | const float top_p = params.top_p; |
|---|
| | | const float temp = params.temp; |
|---|
| | | const int repeat_last_n = params.repeat_last_n; |
|---|
| | | const float repeat_penalty = params.repeat_penalty; |
|---|
| | | |
|---|
| | | gpt_vocab::id id = 0; |
|---|
| | | |
|---|
| | | { |
|---|
| | | const int64_t t_start_sample_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | id = gpt_sample_top_k_top_p_repeat(vocab, logits.data() + (logits.size() - model.hparams.n_vocab), last_n_tokens.data(), last_n_tokens.size(), top_k, top_p, temp, repeat_last_n, repeat_penalty, rng); |
|---|
| | | |
|---|
| | | last_n_tokens.erase(last_n_tokens.begin()); |
|---|
| | | last_n_tokens.push_back(id); |
|---|
| | | |
|---|
| | | t_sample_us += ggml_time_us() - t_start_sample_us; |
|---|
| | | } |
|---|
| | | |
|---|
| | | // add it to the context |
|---|
| | | embd.push_back(id); |
|---|
| | | ++n_sampled; |
|---|
| | | |
|---|
| | | } else { |
|---|
| | | // if here, it means we are still processing the input prompt |
|---|
| | | while ((int) embd_inp.size() > n_consumed) { |
|---|
| | | embd.push_back(embd_inp[n_consumed]); |
|---|
| | | |
|---|
| | | last_n_tokens.erase(last_n_tokens.begin()); |
|---|
| | | last_n_tokens.push_back(embd_inp[n_consumed]); |
|---|
| | | |
|---|
| | | ++n_consumed; |
|---|
| | | if ((int) embd.size() >= params.n_batch) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // display text |
|---|
| | | for (auto id : embd) { |
|---|
| | | printf("%s", vocab.id_to_token[id].c_str()); |
|---|
| | | } |
|---|
| | | fflush(stdout); |
|---|
| | | |
|---|
| | | // end of text token |
|---|
| | | if (embd.back() == 0) { |
|---|
| | | break; |
|---|
| | | } |
|---|
| | | } |
|---|
| | | |
|---|
| | | // report timing |
|---|
| | | { |
|---|
| | | const int64_t t_main_end_us = ggml_time_us(); |
|---|
| | | |
|---|
| | | printf("\n\n\n"); |
|---|
| | | printf("%s: sampled tokens = %8d\n", __func__, n_sampled); |
|---|
| | | printf("%s: mem per token = %8zu bytes\n", __func__, mem_per_token); |
|---|
| | | printf("%s: load time = %8.2f ms\n", __func__, t_load_us / 1000.0f); |
|---|
| | | printf("%s: sample time = %8.2f ms / %.2f ms per token\n", __func__, t_sample_us / 1000.0f, t_sample_us / 1000.0f / n_sampled); |
|---|
| | | printf("%s: eval time = %8.2f ms / %.2f ms per token\n", __func__, t_predict_us / 1000.0f, t_predict_us / 1000.0f / n_past); |
|---|
| | | printf("%s: total time = %8.2f ms\n", __func__, (t_main_end_us - t_main_start_us) / 1000.0f); |
|---|
| | | } |
|---|
| | | |
|---|
| | | ggml_free(model.ctx); |
|---|
| | | |
|---|
| | | return 0; |
|---|
| | | } |
|---|
| ggml/examples/mpt/quantize.cpp
ggml/examples/prompts/dolly-v2.txt
ggml/examples/prompts/gpt-2-chinese.txt
ggml/examples/prompts/gpt-2.txt
ggml/examples/prompts/gpt-j.txt
ggml/examples/prompts/gpt-neox-japanese.txt
ggml/examples/prompts/gpt-neox.txt
ggml/examples/prompts/polyglot-ko.txt
ggml/examples/prompts/replit.txt
ggml/examples/prompts/starcoder.txt
ggml/examples/prompts/test-cases.txt
ggml/examples/prompts/tokenize_huggingface.py
ggml/examples/prompts/whisper.txt
ggml/examples/python/README.md
ggml/examples/python/api.h
ggml/examples/python/example_add_quant.py
ggml/examples/python/example_test_all_quants.py
ggml/examples/python/ggml/__init__.py
ggml/examples/python/ggml/__init__.pyi
ggml/examples/python/ggml/cffi.py
ggml/examples/python/ggml/ffi/__init__.pyi
ggml/examples/python/ggml/utils.py
ggml/examples/python/regenerate.py
ggml/examples/python/stubs.py
ggml/examples/python/test_tensor.py
ggml/examples/replit/CMakeLists.txt
ggml/examples/replit/convert-h5-to-ggml.py
ggml/examples/replit/main.cpp
ggml/examples/replit/quantize.cpp
ggml/examples/sam/CMakeLists.txt
ggml/examples/sam/README.md
ggml/examples/sam/convert-pth-to-ggml.py
ggml/examples/sam/example.jpg
ggml/examples/sam/main.cpp
ggml/examples/starcoder/CMakeLists.txt
ggml/examples/starcoder/README.md
ggml/examples/starcoder/convert-hf-to-ggml.py
ggml/examples/starcoder/main.cpp
ggml/examples/starcoder/quantize.cpp
ggml/examples/stb_image.h
ggml/examples/stb_image_write.h
ggml/examples/whisper/CMakeLists.txt
ggml/examples/whisper/README.md
ggml/examples/whisper/convert-pt-to-ggml.py
ggml/examples/whisper/main.cpp
ggml/examples/whisper/quantize.cpp
ggml/examples/whisper/whisper.cpp
ggml/examples/whisper/whisper.h
ggml/examples/yolo/CMakeLists.txt
ggml/examples/yolo/README.md
ggml/examples/yolo/convert-yolov3-tiny.py
ggml/examples/yolo/data/coco.names
ggml/examples/yolo/data/labels/100_0.png
ggml/examples/yolo/data/labels/100_1.png
ggml/examples/yolo/data/labels/100_2.png
ggml/examples/yolo/data/labels/100_3.png
ggml/examples/yolo/data/labels/100_4.png
ggml/examples/yolo/data/labels/100_5.png
ggml/examples/yolo/data/labels/100_6.png
ggml/examples/yolo/data/labels/100_7.png
ggml/examples/yolo/data/labels/101_0.png
ggml/examples/yolo/data/labels/101_1.png
ggml/examples/yolo/data/labels/101_2.png
ggml/examples/yolo/data/labels/101_3.png
ggml/examples/yolo/data/labels/101_4.png
ggml/examples/yolo/data/labels/101_5.png
ggml/examples/yolo/data/labels/101_6.png
ggml/examples/yolo/data/labels/101_7.png
ggml/examples/yolo/data/labels/102_0.png
ggml/examples/yolo/data/labels/102_1.png
ggml/examples/yolo/data/labels/102_2.png
ggml/examples/yolo/data/labels/102_3.png
ggml/examples/yolo/data/labels/102_4.png
ggml/examples/yolo/data/labels/102_5.png
ggml/examples/yolo/data/labels/102_6.png
ggml/examples/yolo/data/labels/102_7.png
ggml/examples/yolo/data/labels/103_0.png
ggml/examples/yolo/data/labels/103_1.png
ggml/examples/yolo/data/labels/103_2.png
ggml/examples/yolo/data/labels/103_3.png
ggml/examples/yolo/data/labels/103_4.png
ggml/examples/yolo/data/labels/103_5.png
ggml/examples/yolo/data/labels/103_6.png
ggml/examples/yolo/data/labels/103_7.png
ggml/examples/yolo/data/labels/104_0.png
ggml/examples/yolo/data/labels/104_1.png
ggml/examples/yolo/data/labels/104_2.png
ggml/examples/yolo/data/labels/104_3.png
ggml/examples/yolo/data/labels/104_4.png
ggml/examples/yolo/data/labels/104_5.png
ggml/examples/yolo/data/labels/104_6.png
ggml/examples/yolo/data/labels/104_7.png
ggml/examples/yolo/data/labels/105_0.png
ggml/examples/yolo/data/labels/105_1.png
ggml/examples/yolo/data/labels/105_2.png
ggml/examples/yolo/data/labels/105_3.png
ggml/examples/yolo/data/labels/105_4.png
ggml/examples/yolo/data/labels/105_5.png
ggml/examples/yolo/data/labels/105_6.png
ggml/examples/yolo/data/labels/105_7.png
ggml/examples/yolo/data/labels/106_0.png
ggml/examples/yolo/data/labels/106_1.png
ggml/examples/yolo/data/labels/106_2.png
ggml/examples/yolo/data/labels/106_3.png
ggml/examples/yolo/data/labels/106_4.png
ggml/examples/yolo/data/labels/106_5.png
ggml/examples/yolo/data/labels/106_6.png
ggml/examples/yolo/data/labels/106_7.png
ggml/examples/yolo/data/labels/107_0.png
ggml/examples/yolo/data/labels/107_1.png
ggml/examples/yolo/data/labels/107_2.png
ggml/examples/yolo/data/labels/107_3.png
ggml/examples/yolo/data/labels/107_4.png
ggml/examples/yolo/data/labels/107_5.png
ggml/examples/yolo/data/labels/107_6.png
ggml/examples/yolo/data/labels/107_7.png
ggml/examples/yolo/data/labels/108_0.png
ggml/examples/yolo/data/labels/108_1.png
ggml/examples/yolo/data/labels/108_2.png
ggml/examples/yolo/data/labels/108_3.png
ggml/examples/yolo/data/labels/108_4.png
ggml/examples/yolo/data/labels/108_5.png
ggml/examples/yolo/data/labels/108_6.png
ggml/examples/yolo/data/labels/108_7.png
ggml/examples/yolo/data/labels/109_0.png
ggml/examples/yolo/data/labels/109_1.png
ggml/examples/yolo/data/labels/109_2.png
ggml/examples/yolo/data/labels/109_3.png
ggml/examples/yolo/data/labels/109_4.png
ggml/examples/yolo/data/labels/109_5.png
ggml/examples/yolo/data/labels/109_6.png
ggml/examples/yolo/data/labels/109_7.png
ggml/examples/yolo/data/labels/110_0.png
ggml/examples/yolo/data/labels/110_1.png
ggml/examples/yolo/data/labels/110_2.png
ggml/examples/yolo/data/labels/110_3.png
ggml/examples/yolo/data/labels/110_4.png
ggml/examples/yolo/data/labels/110_5.png
ggml/examples/yolo/data/labels/110_6.png
ggml/examples/yolo/data/labels/110_7.png
ggml/examples/yolo/data/labels/111_0.png
ggml/examples/yolo/data/labels/111_1.png
ggml/examples/yolo/data/labels/111_2.png
ggml/examples/yolo/data/labels/111_3.png
ggml/examples/yolo/data/labels/111_4.png
ggml/examples/yolo/data/labels/111_5.png
ggml/examples/yolo/data/labels/111_6.png
ggml/examples/yolo/data/labels/111_7.png
ggml/examples/yolo/data/labels/112_0.png
ggml/examples/yolo/data/labels/112_1.png
ggml/examples/yolo/data/labels/112_2.png
ggml/examples/yolo/data/labels/112_3.png
ggml/examples/yolo/data/labels/112_4.png
ggml/examples/yolo/data/labels/112_5.png
ggml/examples/yolo/data/labels/112_6.png
ggml/examples/yolo/data/labels/112_7.png
ggml/examples/yolo/data/labels/113_0.png
ggml/examples/yolo/data/labels/113_1.png
ggml/examples/yolo/data/labels/113_2.png
ggml/examples/yolo/data/labels/113_3.png
ggml/examples/yolo/data/labels/113_4.png
ggml/examples/yolo/data/labels/113_5.png
ggml/examples/yolo/data/labels/113_6.png
ggml/examples/yolo/data/labels/113_7.png
ggml/examples/yolo/data/labels/114_0.png
ggml/examples/yolo/data/labels/114_1.png
ggml/examples/yolo/data/labels/114_2.png
ggml/examples/yolo/data/labels/114_3.png
ggml/examples/yolo/data/labels/114_4.png
ggml/examples/yolo/data/labels/114_5.png
ggml/examples/yolo/data/labels/114_6.png
ggml/examples/yolo/data/labels/114_7.png
ggml/examples/yolo/data/labels/115_0.png
ggml/examples/yolo/data/labels/115_1.png
ggml/examples/yolo/data/labels/115_2.png
ggml/examples/yolo/data/labels/115_3.png
ggml/examples/yolo/data/labels/115_4.png
ggml/examples/yolo/data/labels/115_5.png
ggml/examples/yolo/data/labels/115_6.png
ggml/examples/yolo/data/labels/115_7.png
ggml/examples/yolo/data/labels/116_0.png
ggml/examples/yolo/data/labels/116_1.png
ggml/examples/yolo/data/labels/116_2.png
ggml/examples/yolo/data/labels/116_3.png
ggml/examples/yolo/data/labels/116_4.png
ggml/examples/yolo/data/labels/116_5.png
ggml/examples/yolo/data/labels/116_6.png
ggml/examples/yolo/data/labels/116_7.png
ggml/examples/yolo/data/labels/117_0.png
ggml/examples/yolo/data/labels/117_1.png
ggml/examples/yolo/data/labels/117_2.png
ggml/examples/yolo/data/labels/117_3.png
ggml/examples/yolo/data/labels/117_4.png
ggml/examples/yolo/data/labels/117_5.png
ggml/examples/yolo/data/labels/117_6.png
ggml/examples/yolo/data/labels/117_7.png
ggml/examples/yolo/data/labels/118_0.png
ggml/examples/yolo/data/labels/118_1.png
ggml/examples/yolo/data/labels/118_2.png
ggml/examples/yolo/data/labels/118_3.png
ggml/examples/yolo/data/labels/118_4.png
ggml/examples/yolo/data/labels/118_5.png
ggml/examples/yolo/data/labels/118_6.png
ggml/examples/yolo/data/labels/118_7.png
ggml/examples/yolo/data/labels/119_0.png
ggml/examples/yolo/data/labels/119_1.png
ggml/examples/yolo/data/labels/119_2.png
ggml/examples/yolo/data/labels/119_3.png
ggml/examples/yolo/data/labels/119_4.png
ggml/examples/yolo/data/labels/119_5.png
ggml/examples/yolo/data/labels/119_6.png
ggml/examples/yolo/data/labels/119_7.png
ggml/examples/yolo/data/labels/120_0.png
ggml/examples/yolo/data/labels/120_1.png
ggml/examples/yolo/data/labels/120_2.png
ggml/examples/yolo/data/labels/120_3.png
ggml/examples/yolo/data/labels/120_4.png
ggml/examples/yolo/data/labels/120_5.png
ggml/examples/yolo/data/labels/120_6.png
ggml/examples/yolo/data/labels/120_7.png
ggml/examples/yolo/data/labels/121_0.png
ggml/examples/yolo/data/labels/121_1.png
ggml/examples/yolo/data/labels/121_2.png
ggml/examples/yolo/data/labels/121_3.png
ggml/examples/yolo/data/labels/121_4.png
ggml/examples/yolo/data/labels/121_5.png
ggml/examples/yolo/data/labels/121_6.png
ggml/examples/yolo/data/labels/121_7.png
ggml/examples/yolo/data/labels/122_0.png
ggml/examples/yolo/data/labels/122_1.png
ggml/examples/yolo/data/labels/122_2.png
ggml/examples/yolo/data/labels/122_3.png
ggml/examples/yolo/data/labels/122_4.png
ggml/examples/yolo/data/labels/122_5.png
ggml/examples/yolo/data/labels/122_6.png
ggml/examples/yolo/data/labels/122_7.png
ggml/examples/yolo/data/labels/123_0.png
ggml/examples/yolo/data/labels/123_1.png
ggml/examples/yolo/data/labels/123_2.png
ggml/examples/yolo/data/labels/123_3.png
ggml/examples/yolo/data/labels/123_4.png
ggml/examples/yolo/data/labels/123_5.png
ggml/examples/yolo/data/labels/123_6.png
ggml/examples/yolo/data/labels/123_7.png
ggml/examples/yolo/data/labels/124_0.png
ggml/examples/yolo/data/labels/124_1.png
ggml/examples/yolo/data/labels/124_2.png
ggml/examples/yolo/data/labels/124_3.png
ggml/examples/yolo/data/labels/124_4.png
ggml/examples/yolo/data/labels/124_5.png
ggml/examples/yolo/data/labels/124_6.png
ggml/examples/yolo/data/labels/124_7.png
ggml/examples/yolo/data/labels/125_0.png
ggml/examples/yolo/data/labels/125_1.png
ggml/examples/yolo/data/labels/125_2.png
ggml/examples/yolo/data/labels/125_3.png
ggml/examples/yolo/data/labels/125_4.png
ggml/examples/yolo/data/labels/125_5.png
ggml/examples/yolo/data/labels/125_6.png
ggml/examples/yolo/data/labels/125_7.png
ggml/examples/yolo/data/labels/126_0.png
ggml/examples/yolo/data/labels/126_1.png
ggml/examples/yolo/data/labels/126_2.png
ggml/examples/yolo/data/labels/126_3.png
ggml/examples/yolo/data/labels/126_4.png
ggml/examples/yolo/data/labels/126_5.png
ggml/examples/yolo/data/labels/126_6.png
ggml/examples/yolo/data/labels/126_7.png
ggml/examples/yolo/data/labels/32_0.png
ggml/examples/yolo/data/labels/32_1.png
ggml/examples/yolo/data/labels/32_2.png
ggml/examples/yolo/data/labels/32_3.png
ggml/examples/yolo/data/labels/32_4.png
ggml/examples/yolo/data/labels/32_5.png
ggml/examples/yolo/data/labels/32_6.png
ggml/examples/yolo/data/labels/32_7.png
ggml/examples/yolo/data/labels/33_0.png
ggml/examples/yolo/data/labels/33_1.png
ggml/examples/yolo/data/labels/33_2.png
ggml/examples/yolo/data/labels/33_3.png
ggml/examples/yolo/data/labels/33_4.png
ggml/examples/yolo/data/labels/33_5.png
ggml/examples/yolo/data/labels/33_6.png
ggml/examples/yolo/data/labels/33_7.png
ggml/examples/yolo/data/labels/34_0.png
ggml/examples/yolo/data/labels/34_1.png
ggml/examples/yolo/data/labels/34_2.png
ggml/examples/yolo/data/labels/34_3.png
ggml/examples/yolo/data/labels/34_4.png
ggml/examples/yolo/data/labels/34_5.png
ggml/examples/yolo/data/labels/34_6.png
ggml/examples/yolo/data/labels/34_7.png
ggml/examples/yolo/data/labels/35_0.png
ggml/examples/yolo/data/labels/35_1.png
ggml/examples/yolo/data/labels/35_2.png
ggml/examples/yolo/data/labels/35_3.png
ggml/examples/yolo/data/labels/35_4.png
ggml/examples/yolo/data/labels/35_5.png
ggml/examples/yolo/data/labels/35_6.png
ggml/examples/yolo/data/labels/35_7.png
ggml/examples/yolo/data/labels/36_0.png
ggml/examples/yolo/data/labels/36_1.png
ggml/examples/yolo/data/labels/36_2.png
ggml/examples/yolo/data/labels/36_3.png
ggml/examples/yolo/data/labels/36_4.png
ggml/examples/yolo/data/labels/36_5.png
ggml/examples/yolo/data/labels/36_6.png
ggml/examples/yolo/data/labels/36_7.png
ggml/examples/yolo/data/labels/37_0.png
ggml/examples/yolo/data/labels/37_1.png
ggml/examples/yolo/data/labels/37_2.png
ggml/examples/yolo/data/labels/37_3.png
ggml/examples/yolo/data/labels/37_4.png
ggml/examples/yolo/data/labels/37_5.png
ggml/examples/yolo/data/labels/37_6.png
ggml/examples/yolo/data/labels/37_7.png
ggml/examples/yolo/data/labels/38_0.png
ggml/examples/yolo/data/labels/38_1.png
ggml/examples/yolo/data/labels/38_2.png
ggml/examples/yolo/data/labels/38_3.png
ggml/examples/yolo/data/labels/38_4.png
ggml/examples/yolo/data/labels/38_5.png
ggml/examples/yolo/data/labels/38_6.png
ggml/examples/yolo/data/labels/38_7.png
ggml/examples/yolo/data/labels/39_0.png
ggml/examples/yolo/data/labels/39_1.png
ggml/examples/yolo/data/labels/39_2.png
ggml/examples/yolo/data/labels/39_3.png
ggml/examples/yolo/data/labels/39_4.png
ggml/examples/yolo/data/labels/39_5.png
ggml/examples/yolo/data/labels/39_6.png
ggml/examples/yolo/data/labels/39_7.png
ggml/examples/yolo/data/labels/40_0.png
ggml/examples/yolo/data/labels/40_1.png
ggml/examples/yolo/data/labels/40_2.png
ggml/examples/yolo/data/labels/40_3.png
ggml/examples/yolo/data/labels/40_4.png
ggml/examples/yolo/data/labels/40_5.png
ggml/examples/yolo/data/labels/40_6.png
ggml/examples/yolo/data/labels/40_7.png
ggml/examples/yolo/data/labels/41_0.png
ggml/examples/yolo/data/labels/41_1.png
ggml/examples/yolo/data/labels/41_2.png
ggml/examples/yolo/data/labels/41_3.png
ggml/examples/yolo/data/labels/41_4.png
ggml/examples/yolo/data/labels/41_5.png
ggml/examples/yolo/data/labels/41_6.png
ggml/examples/yolo/data/labels/41_7.png
ggml/examples/yolo/data/labels/42_0.png
ggml/examples/yolo/data/labels/42_1.png
ggml/examples/yolo/data/labels/42_2.png
ggml/examples/yolo/data/labels/42_3.png
ggml/examples/yolo/data/labels/42_4.png
ggml/examples/yolo/data/labels/42_5.png
ggml/examples/yolo/data/labels/42_6.png
ggml/examples/yolo/data/labels/42_7.png
ggml/examples/yolo/data/labels/43_0.png
ggml/examples/yolo/data/labels/43_1.png
ggml/examples/yolo/data/labels/43_2.png
ggml/examples/yolo/data/labels/43_3.png
ggml/examples/yolo/data/labels/43_4.png
ggml/examples/yolo/data/labels/43_5.png
ggml/examples/yolo/data/labels/43_6.png
ggml/examples/yolo/data/labels/43_7.png
ggml/examples/yolo/data/labels/44_0.png
ggml/examples/yolo/data/labels/44_1.png
ggml/examples/yolo/data/labels/44_2.png
ggml/examples/yolo/data/labels/44_3.png
ggml/examples/yolo/data/labels/44_4.png
ggml/examples/yolo/data/labels/44_5.png
ggml/examples/yolo/data/labels/44_6.png
ggml/examples/yolo/data/labels/44_7.png
ggml/examples/yolo/data/labels/45_0.png
ggml/examples/yolo/data/labels/45_1.png
ggml/examples/yolo/data/labels/45_2.png
ggml/examples/yolo/data/labels/45_3.png
ggml/examples/yolo/data/labels/45_4.png
ggml/examples/yolo/data/labels/45_5.png
ggml/examples/yolo/data/labels/45_6.png
ggml/examples/yolo/data/labels/45_7.png
ggml/examples/yolo/data/labels/46_0.png
ggml/examples/yolo/data/labels/46_1.png
ggml/examples/yolo/data/labels/46_2.png
ggml/examples/yolo/data/labels/46_3.png
ggml/examples/yolo/data/labels/46_4.png
ggml/examples/yolo/data/labels/46_5.png
ggml/examples/yolo/data/labels/46_6.png
ggml/examples/yolo/data/labels/46_7.png
ggml/examples/yolo/data/labels/47_0.png
ggml/examples/yolo/data/labels/47_1.png
ggml/examples/yolo/data/labels/47_2.png
ggml/examples/yolo/data/labels/47_3.png
ggml/examples/yolo/data/labels/47_4.png
ggml/examples/yolo/data/labels/47_5.png
ggml/examples/yolo/data/labels/47_6.png
ggml/examples/yolo/data/labels/47_7.png
ggml/examples/yolo/data/labels/48_0.png
ggml/examples/yolo/data/labels/48_1.png
ggml/examples/yolo/data/labels/48_2.png
ggml/examples/yolo/data/labels/48_3.png
ggml/examples/yolo/data/labels/48_4.png
ggml/examples/yolo/data/labels/48_5.png
ggml/examples/yolo/data/labels/48_6.png
ggml/examples/yolo/data/labels/48_7.png
ggml/examples/yolo/data/labels/49_0.png
ggml/examples/yolo/data/labels/49_1.png
ggml/examples/yolo/data/labels/49_2.png
ggml/examples/yolo/data/labels/49_3.png
ggml/examples/yolo/data/labels/49_4.png
ggml/examples/yolo/data/labels/49_5.png
ggml/examples/yolo/data/labels/49_6.png
ggml/examples/yolo/data/labels/49_7.png
ggml/examples/yolo/data/labels/50_0.png
ggml/examples/yolo/data/labels/50_1.png
ggml/examples/yolo/data/labels/50_2.png
ggml/examples/yolo/data/labels/50_3.png
ggml/examples/yolo/data/labels/50_4.png
ggml/examples/yolo/data/labels/50_5.png
ggml/examples/yolo/data/labels/50_6.png
ggml/examples/yolo/data/labels/50_7.png
ggml/examples/yolo/data/labels/51_0.png
ggml/examples/yolo/data/labels/51_1.png
ggml/examples/yolo/data/labels/51_2.png
ggml/examples/yolo/data/labels/51_3.png
ggml/examples/yolo/data/labels/51_4.png
ggml/examples/yolo/data/labels/51_5.png
ggml/examples/yolo/data/labels/51_6.png
ggml/examples/yolo/data/labels/51_7.png
ggml/examples/yolo/data/labels/52_0.png
ggml/examples/yolo/data/labels/52_1.png
ggml/examples/yolo/data/labels/52_2.png
ggml/examples/yolo/data/labels/52_3.png
ggml/examples/yolo/data/labels/52_4.png
ggml/examples/yolo/data/labels/52_5.png
ggml/examples/yolo/data/labels/52_6.png
ggml/examples/yolo/data/labels/52_7.png
ggml/examples/yolo/data/labels/53_0.png
ggml/examples/yolo/data/labels/53_1.png
ggml/examples/yolo/data/labels/53_2.png
ggml/examples/yolo/data/labels/53_3.png
ggml/examples/yolo/data/labels/53_4.png
ggml/examples/yolo/data/labels/53_5.png
ggml/examples/yolo/data/labels/53_6.png
ggml/examples/yolo/data/labels/53_7.png
ggml/examples/yolo/data/labels/54_0.png
ggml/examples/yolo/data/labels/54_1.png
ggml/examples/yolo/data/labels/54_2.png
ggml/examples/yolo/data/labels/54_3.png
ggml/examples/yolo/data/labels/54_4.png
ggml/examples/yolo/data/labels/54_5.png
ggml/examples/yolo/data/labels/54_6.png
ggml/examples/yolo/data/labels/54_7.png
ggml/examples/yolo/data/labels/55_0.png
ggml/examples/yolo/data/labels/55_1.png
ggml/examples/yolo/data/labels/55_2.png
ggml/examples/yolo/data/labels/55_3.png
ggml/examples/yolo/data/labels/55_4.png
ggml/examples/yolo/data/labels/55_5.png
ggml/examples/yolo/data/labels/55_6.png
ggml/examples/yolo/data/labels/55_7.png
ggml/examples/yolo/data/labels/56_0.png
ggml/examples/yolo/data/labels/56_1.png
ggml/examples/yolo/data/labels/56_2.png
ggml/examples/yolo/data/labels/56_3.png
ggml/examples/yolo/data/labels/56_4.png
ggml/examples/yolo/data/labels/56_5.png
ggml/examples/yolo/data/labels/56_6.png
ggml/examples/yolo/data/labels/56_7.png
ggml/examples/yolo/data/labels/57_0.png
ggml/examples/yolo/data/labels/57_1.png
ggml/examples/yolo/data/labels/57_2.png
ggml/examples/yolo/data/labels/57_3.png
ggml/examples/yolo/data/labels/57_4.png
ggml/examples/yolo/data/labels/57_5.png
ggml/examples/yolo/data/labels/57_6.png
ggml/examples/yolo/data/labels/57_7.png
ggml/examples/yolo/data/labels/58_0.png
ggml/examples/yolo/data/labels/58_1.png
ggml/examples/yolo/data/labels/58_2.png
ggml/examples/yolo/data/labels/58_3.png
ggml/examples/yolo/data/labels/58_4.png
ggml/examples/yolo/data/labels/58_5.png
ggml/examples/yolo/data/labels/58_6.png
ggml/examples/yolo/data/labels/58_7.png
ggml/examples/yolo/data/labels/59_0.png
ggml/examples/yolo/data/labels/59_1.png
ggml/examples/yolo/data/labels/59_2.png
ggml/examples/yolo/data/labels/59_3.png
ggml/examples/yolo/data/labels/59_4.png
ggml/examples/yolo/data/labels/59_5.png
ggml/examples/yolo/data/labels/59_6.png
ggml/examples/yolo/data/labels/59_7.png
ggml/examples/yolo/data/labels/60_0.png
ggml/examples/yolo/data/labels/60_1.png
ggml/examples/yolo/data/labels/60_2.png
ggml/examples/yolo/data/labels/60_3.png
ggml/examples/yolo/data/labels/60_4.png
ggml/examples/yolo/data/labels/60_5.png
ggml/examples/yolo/data/labels/60_6.png
ggml/examples/yolo/data/labels/60_7.png
ggml/examples/yolo/data/labels/61_0.png
ggml/examples/yolo/data/labels/61_1.png
ggml/examples/yolo/data/labels/61_2.png
ggml/examples/yolo/data/labels/61_3.png
ggml/examples/yolo/data/labels/61_4.png
ggml/examples/yolo/data/labels/61_5.png
ggml/examples/yolo/data/labels/61_6.png
ggml/examples/yolo/data/labels/61_7.png
ggml/examples/yolo/data/labels/62_0.png
ggml/examples/yolo/data/labels/62_1.png
ggml/examples/yolo/data/labels/62_2.png
ggml/examples/yolo/data/labels/62_3.png
ggml/examples/yolo/data/labels/62_4.png
ggml/examples/yolo/data/labels/62_5.png
ggml/examples/yolo/data/labels/62_6.png
ggml/examples/yolo/data/labels/62_7.png
ggml/examples/yolo/data/labels/63_0.png
ggml/examples/yolo/data/labels/63_1.png
ggml/examples/yolo/data/labels/63_2.png
ggml/examples/yolo/data/labels/63_3.png
ggml/examples/yolo/data/labels/63_4.png
ggml/examples/yolo/data/labels/63_5.png
ggml/examples/yolo/data/labels/63_6.png
ggml/examples/yolo/data/labels/63_7.png
ggml/examples/yolo/data/labels/64_0.png
ggml/examples/yolo/data/labels/64_1.png
ggml/examples/yolo/data/labels/64_2.png
ggml/examples/yolo/data/labels/64_3.png
ggml/examples/yolo/data/labels/64_4.png
ggml/examples/yolo/data/labels/64_5.png
ggml/examples/yolo/data/labels/64_6.png
ggml/examples/yolo/data/labels/64_7.png
ggml/examples/yolo/data/labels/65_0.png
ggml/examples/yolo/data/labels/65_1.png
ggml/examples/yolo/data/labels/65_2.png
ggml/examples/yolo/data/labels/65_3.png
ggml/examples/yolo/data/labels/65_4.png
ggml/examples/yolo/data/labels/65_5.png
ggml/examples/yolo/data/labels/65_6.png
ggml/examples/yolo/data/labels/65_7.png
ggml/examples/yolo/data/labels/66_0.png
ggml/examples/yolo/data/labels/66_1.png
ggml/examples/yolo/data/labels/66_2.png
ggml/examples/yolo/data/labels/66_3.png
ggml/examples/yolo/data/labels/66_4.png
ggml/examples/yolo/data/labels/66_5.png
ggml/examples/yolo/data/labels/66_6.png
ggml/examples/yolo/data/labels/66_7.png
ggml/examples/yolo/data/labels/67_0.png
ggml/examples/yolo/data/labels/67_1.png
ggml/examples/yolo/data/labels/67_2.png
ggml/examples/yolo/data/labels/67_3.png
ggml/examples/yolo/data/labels/67_4.png
ggml/examples/yolo/data/labels/67_5.png
ggml/examples/yolo/data/labels/67_6.png
ggml/examples/yolo/data/labels/67_7.png
ggml/examples/yolo/data/labels/68_0.png
ggml/examples/yolo/data/labels/68_1.png
ggml/examples/yolo/data/labels/68_2.png
ggml/examples/yolo/data/labels/68_3.png
ggml/examples/yolo/data/labels/68_4.png
ggml/examples/yolo/data/labels/68_5.png
ggml/examples/yolo/data/labels/68_6.png
ggml/examples/yolo/data/labels/68_7.png
ggml/examples/yolo/data/labels/69_0.png
ggml/examples/yolo/data/labels/69_1.png
ggml/examples/yolo/data/labels/69_2.png
ggml/examples/yolo/data/labels/69_3.png
ggml/examples/yolo/data/labels/69_4.png
ggml/examples/yolo/data/labels/69_5.png
ggml/examples/yolo/data/labels/69_6.png
ggml/examples/yolo/data/labels/69_7.png
ggml/examples/yolo/data/labels/70_0.png
ggml/examples/yolo/data/labels/70_1.png
ggml/examples/yolo/data/labels/70_2.png
ggml/examples/yolo/data/labels/70_3.png
ggml/examples/yolo/data/labels/70_4.png
ggml/examples/yolo/data/labels/70_5.png
ggml/examples/yolo/data/labels/70_6.png
ggml/examples/yolo/data/labels/70_7.png
ggml/examples/yolo/data/labels/71_0.png
ggml/examples/yolo/data/labels/71_1.png
ggml/examples/yolo/data/labels/71_2.png
ggml/examples/yolo/data/labels/71_3.png
ggml/examples/yolo/data/labels/71_4.png
ggml/examples/yolo/data/labels/71_5.png
ggml/examples/yolo/data/labels/71_6.png
ggml/examples/yolo/data/labels/71_7.png
ggml/examples/yolo/data/labels/72_0.png
ggml/examples/yolo/data/labels/72_1.png
ggml/examples/yolo/data/labels/72_2.png
ggml/examples/yolo/data/labels/72_3.png
ggml/examples/yolo/data/labels/72_4.png
ggml/examples/yolo/data/labels/72_5.png
ggml/examples/yolo/data/labels/72_6.png
ggml/examples/yolo/data/labels/72_7.png
ggml/examples/yolo/data/labels/73_0.png
ggml/examples/yolo/data/labels/73_1.png
ggml/examples/yolo/data/labels/73_2.png
ggml/examples/yolo/data/labels/73_3.png
ggml/examples/yolo/data/labels/73_4.png
ggml/examples/yolo/data/labels/73_5.png
ggml/examples/yolo/data/labels/73_6.png
ggml/examples/yolo/data/labels/73_7.png
ggml/examples/yolo/data/labels/74_0.png
ggml/examples/yolo/data/labels/74_1.png
ggml/examples/yolo/data/labels/74_2.png
ggml/examples/yolo/data/labels/74_3.png
ggml/examples/yolo/data/labels/74_4.png
ggml/examples/yolo/data/labels/74_5.png
ggml/examples/yolo/data/labels/74_6.png
ggml/examples/yolo/data/labels/74_7.png
ggml/examples/yolo/data/labels/75_0.png
ggml/examples/yolo/data/labels/75_1.png
ggml/examples/yolo/data/labels/75_2.png
ggml/examples/yolo/data/labels/75_3.png
ggml/examples/yolo/data/labels/75_4.png
ggml/examples/yolo/data/labels/75_5.png
ggml/examples/yolo/data/labels/75_6.png
ggml/examples/yolo/data/labels/75_7.png
ggml/examples/yolo/data/labels/76_0.png
ggml/examples/yolo/data/labels/76_1.png
ggml/examples/yolo/data/labels/76_2.png
ggml/examples/yolo/data/labels/76_3.png
ggml/examples/yolo/data/labels/76_4.png
ggml/examples/yolo/data/labels/76_5.png
ggml/examples/yolo/data/labels/76_6.png
ggml/examples/yolo/data/labels/76_7.png
ggml/examples/yolo/data/labels/77_0.png
ggml/examples/yolo/data/labels/77_1.png
ggml/examples/yolo/data/labels/77_2.png
ggml/examples/yolo/data/labels/77_3.png
ggml/examples/yolo/data/labels/77_4.png
ggml/examples/yolo/data/labels/77_5.png
ggml/examples/yolo/data/labels/77_6.png
ggml/examples/yolo/data/labels/77_7.png
ggml/examples/yolo/data/labels/78_0.png
ggml/examples/yolo/data/labels/78_1.png
ggml/examples/yolo/data/labels/78_2.png
ggml/examples/yolo/data/labels/78_3.png
ggml/examples/yolo/data/labels/78_4.png
ggml/examples/yolo/data/labels/78_5.png
ggml/examples/yolo/data/labels/78_6.png
ggml/examples/yolo/data/labels/78_7.png
ggml/examples/yolo/data/labels/79_0.png
ggml/examples/yolo/data/labels/79_1.png
ggml/examples/yolo/data/labels/79_2.png
ggml/examples/yolo/data/labels/79_3.png
ggml/examples/yolo/data/labels/79_4.png
ggml/examples/yolo/data/labels/79_5.png
ggml/examples/yolo/data/labels/79_6.png
ggml/examples/yolo/data/labels/79_7.png
ggml/examples/yolo/data/labels/80_0.png
ggml/examples/yolo/data/labels/80_1.png
ggml/examples/yolo/data/labels/80_2.png
ggml/examples/yolo/data/labels/80_3.png
ggml/examples/yolo/data/labels/80_4.png
ggml/examples/yolo/data/labels/80_5.png
ggml/examples/yolo/data/labels/80_6.png
ggml/examples/yolo/data/labels/80_7.png
ggml/examples/yolo/data/labels/81_0.png
ggml/examples/yolo/data/labels/81_1.png
ggml/examples/yolo/data/labels/81_2.png
ggml/examples/yolo/data/labels/81_3.png
ggml/examples/yolo/data/labels/81_4.png
ggml/examples/yolo/data/labels/81_5.png
ggml/examples/yolo/data/labels/81_6.png
ggml/examples/yolo/data/labels/81_7.png
ggml/examples/yolo/data/labels/82_0.png
ggml/examples/yolo/data/labels/82_1.png
ggml/examples/yolo/data/labels/82_2.png
ggml/examples/yolo/data/labels/82_3.png
ggml/examples/yolo/data/labels/82_4.png
ggml/examples/yolo/data/labels/82_5.png
ggml/examples/yolo/data/labels/82_6.png
ggml/examples/yolo/data/labels/82_7.png
ggml/examples/yolo/data/labels/83_0.png
ggml/examples/yolo/data/labels/83_1.png
ggml/examples/yolo/data/labels/83_2.png
ggml/examples/yolo/data/labels/83_3.png
ggml/examples/yolo/data/labels/83_4.png
ggml/examples/yolo/data/labels/83_5.png
ggml/examples/yolo/data/labels/83_6.png
ggml/examples/yolo/data/labels/83_7.png
ggml/examples/yolo/data/labels/84_0.png
ggml/examples/yolo/data/labels/84_1.png
ggml/examples/yolo/data/labels/84_2.png
ggml/examples/yolo/data/labels/84_3.png
ggml/examples/yolo/data/labels/84_4.png
ggml/examples/yolo/data/labels/84_5.png
ggml/examples/yolo/data/labels/84_6.png
ggml/examples/yolo/data/labels/84_7.png
ggml/examples/yolo/data/labels/85_0.png
ggml/examples/yolo/data/labels/85_1.png
ggml/examples/yolo/data/labels/85_2.png
ggml/examples/yolo/data/labels/85_3.png
ggml/examples/yolo/data/labels/85_4.png
ggml/examples/yolo/data/labels/85_5.png
ggml/examples/yolo/data/labels/85_6.png
ggml/examples/yolo/data/labels/85_7.png
ggml/examples/yolo/data/labels/86_0.png
ggml/examples/yolo/data/labels/86_1.png
ggml/examples/yolo/data/labels/86_2.png
ggml/examples/yolo/data/labels/86_3.png
ggml/examples/yolo/data/labels/86_4.png
ggml/examples/yolo/data/labels/86_5.png
ggml/examples/yolo/data/labels/86_6.png
ggml/examples/yolo/data/labels/86_7.png
ggml/examples/yolo/data/labels/87_0.png
ggml/examples/yolo/data/labels/87_1.png
ggml/examples/yolo/data/labels/87_2.png
ggml/examples/yolo/data/labels/87_3.png
ggml/examples/yolo/data/labels/87_4.png
ggml/examples/yolo/data/labels/87_5.png
ggml/examples/yolo/data/labels/87_6.png
ggml/examples/yolo/data/labels/87_7.png
ggml/examples/yolo/data/labels/88_0.png
ggml/examples/yolo/data/labels/88_1.png
ggml/examples/yolo/data/labels/88_2.png
ggml/examples/yolo/data/labels/88_3.png
ggml/examples/yolo/data/labels/88_4.png
ggml/examples/yolo/data/labels/88_5.png
ggml/examples/yolo/data/labels/88_6.png
ggml/examples/yolo/data/labels/88_7.png
ggml/examples/yolo/data/labels/89_0.png
ggml/examples/yolo/data/labels/89_1.png
ggml/examples/yolo/data/labels/89_2.png
ggml/examples/yolo/data/labels/89_3.png
ggml/examples/yolo/data/labels/89_4.png
ggml/examples/yolo/data/labels/89_5.png
ggml/examples/yolo/data/labels/89_6.png
ggml/examples/yolo/data/labels/89_7.png
ggml/examples/yolo/data/labels/90_0.png
ggml/examples/yolo/data/labels/90_1.png
ggml/examples/yolo/data/labels/90_2.png
ggml/examples/yolo/data/labels/90_3.png
ggml/examples/yolo/data/labels/90_4.png
ggml/examples/yolo/data/labels/90_5.png
ggml/examples/yolo/data/labels/90_6.png
ggml/examples/yolo/data/labels/90_7.png
ggml/examples/yolo/data/labels/91_0.png
ggml/examples/yolo/data/labels/91_1.png
ggml/examples/yolo/data/labels/91_2.png
ggml/examples/yolo/data/labels/91_3.png
ggml/examples/yolo/data/labels/91_4.png
ggml/examples/yolo/data/labels/91_5.png
ggml/examples/yolo/data/labels/91_6.png
ggml/examples/yolo/data/labels/91_7.png
ggml/examples/yolo/data/labels/92_0.png
ggml/examples/yolo/data/labels/92_1.png
ggml/examples/yolo/data/labels/92_2.png
ggml/examples/yolo/data/labels/92_3.png
ggml/examples/yolo/data/labels/92_4.png
ggml/examples/yolo/data/labels/92_5.png
ggml/examples/yolo/data/labels/92_6.png
ggml/examples/yolo/data/labels/92_7.png
ggml/examples/yolo/data/labels/93_0.png
ggml/examples/yolo/data/labels/93_1.png
ggml/examples/yolo/data/labels/93_2.png
ggml/examples/yolo/data/labels/93_3.png
ggml/examples/yolo/data/labels/93_4.png
ggml/examples/yolo/data/labels/93_5.png
ggml/examples/yolo/data/labels/93_6.png
ggml/examples/yolo/data/labels/93_7.png
ggml/examples/yolo/data/labels/94_0.png
ggml/examples/yolo/data/labels/94_1.png
ggml/examples/yolo/data/labels/94_2.png
ggml/examples/yolo/data/labels/94_3.png
ggml/examples/yolo/data/labels/94_4.png
ggml/examples/yolo/data/labels/94_5.png
ggml/examples/yolo/data/labels/94_6.png
ggml/examples/yolo/data/labels/94_7.png
ggml/examples/yolo/data/labels/95_0.png
ggml/examples/yolo/data/labels/95_1.png
ggml/examples/yolo/data/labels/95_2.png
ggml/examples/yolo/data/labels/95_3.png
ggml/examples/yolo/data/labels/95_4.png
ggml/examples/yolo/data/labels/95_5.png
ggml/examples/yolo/data/labels/95_6.png
ggml/examples/yolo/data/labels/95_7.png
ggml/examples/yolo/data/labels/96_0.png
ggml/examples/yolo/data/labels/96_1.png
ggml/examples/yolo/data/labels/96_2.png
ggml/examples/yolo/data/labels/96_3.png
ggml/examples/yolo/data/labels/96_4.png
ggml/examples/yolo/data/labels/96_5.png
ggml/examples/yolo/data/labels/96_6.png
ggml/examples/yolo/data/labels/96_7.png
ggml/examples/yolo/data/labels/97_0.png
ggml/examples/yolo/data/labels/97_1.png
ggml/examples/yolo/data/labels/97_2.png
ggml/examples/yolo/data/labels/97_3.png
ggml/examples/yolo/data/labels/97_4.png
ggml/examples/yolo/data/labels/97_5.png
ggml/examples/yolo/data/labels/97_6.png
ggml/examples/yolo/data/labels/97_7.png
ggml/examples/yolo/data/labels/98_0.png
ggml/examples/yolo/data/labels/98_1.png
ggml/examples/yolo/data/labels/98_2.png
ggml/examples/yolo/data/labels/98_3.png
ggml/examples/yolo/data/labels/98_4.png
ggml/examples/yolo/data/labels/98_5.png
ggml/examples/yolo/data/labels/98_6.png
ggml/examples/yolo/data/labels/98_7.png
ggml/examples/yolo/data/labels/99_0.png
ggml/examples/yolo/data/labels/99_1.png
ggml/examples/yolo/data/labels/99_2.png
ggml/examples/yolo/data/labels/99_3.png
ggml/examples/yolo/data/labels/99_4.png
ggml/examples/yolo/data/labels/99_5.png
ggml/examples/yolo/data/labels/99_6.png
ggml/examples/yolo/data/labels/99_7.png
ggml/examples/yolo/yolo-image.cpp
ggml/examples/yolo/yolo-image.h
ggml/examples/yolo/yolov3-tiny.cpp
ggml/ggml.pc.in
ggml/include/ggml/ggml-alloc.h
ggml/include/ggml/ggml-backend.h
ggml/include/ggml/ggml.h
ggml/requirements.txt
ggml/scripts/sync-llama-am.sh
ggml/scripts/sync-llama.last
ggml/scripts/sync-llama.sh
ggml/scripts/sync-whisper-am.sh
ggml/scripts/sync-whisper.last
ggml/scripts/sync-whisper.sh
ggml/src/CMakeLists.txt
ggml/src/ggml-alloc.c
ggml/src/ggml-backend-impl.h
ggml/src/ggml-backend.c
ggml/src/ggml-cuda.cu
ggml/src/ggml-cuda.h
ggml/src/ggml-impl.h
ggml/src/ggml-metal.h
ggml/src/ggml-metal.m
ggml/src/ggml-metal.metal
ggml/src/ggml-opencl.cpp
ggml/src/ggml-opencl.h
ggml/src/ggml-quants.c
ggml/src/ggml-quants.h
ggml/src/ggml.c
ggml/tests/CMakeLists.txt
ggml/tests/test-backend-buffer.cpp
ggml/tests/test-backend-ops.cpp
ggml/tests/test-blas0.c
ggml/tests/test-conv-transpose.c
ggml/tests/test-conv1d.cpp
ggml/tests/test-conv2d.cpp
ggml/tests/test-customop.c
ggml/tests/test-dup.c
ggml/tests/test-grad0.cpp
ggml/tests/test-mul-mat.cpp
ggml/tests/test-mul-mat0.c
ggml/tests/test-mul-mat1.c
ggml/tests/test-mul-mat2.c
ggml/tests/test-opt.cpp
ggml/tests/test-pool.c
ggml/tests/test-quantize-fns.cpp
ggml/tests/test-quantize-perf.cpp
ggml/tests/test-rel-pos.c
ggml/tests/test-svd0.c
ggml/tests/test-vec0.c
ggml/tests/test-vec1.c
ggml/tests/test-vec2.c
ggml/tests/test-xpos.c
ggml/tests/test0.c
ggml/tests/test0.zig
ggml/tests/test1.c
ggml/tests/test1.zig
ggml/tests/test2.c
ggml/tests/test2.zig
ggml/tests/test3.c
ggml/tests/test3.zig
ggml_extend.hpp
lora.hpp
model.cpp
model.h
preprocessing.hpp
rng.hpp
rng_philox.hpp
stable-diffusion.cpp
stable-diffusion.h
tae.hpp
thirdparty/CMakeLists.txt
thirdparty/README.md
thirdparty/json.hpp
thirdparty/miniz.h
thirdparty/stb_image.h
thirdparty/stb_image_write.h
thirdparty/zip.c
thirdparty/zip.h
unet.hpp
upscaler.cpp
util.cpp
util.h
vae.hpp
vocab.hpp |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
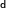{kind=link}
{kind=link}
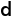{kind=link}
{kind=link}
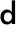{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
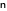{kind=link}
{kind=link}
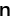{kind=link}
{kind=link}
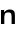{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
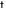{kind=link}
{kind=link}
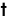{kind=link}
{kind=link}
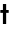{kind=link}
{kind=link}
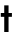{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
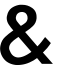{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
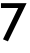{kind=link}
{kind=link}
{kind=link}
{kind=link}
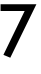{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}